
Khai thác sức mạnh của GPU để dễ dàng tăng tốc các quy trình làm việc Khoa học dữ liệu (data science), Học máy (machine learning) và AI của bạn.
Thực thi toàn bộ quy trình làm việc Khoa học dữ liệu với sự hỗ trợ xử lý của GPU tốc độ cao, nạp dữ liệu song song, can thiệp dữ liệu (data manipulation) và học máy nhằm tạo ra các quy trình Khoa học dữ liệu toàn diện nhanh hơn gấp 50 lần!
Tại sao lại là RAPIDS?

Khoa học dữ liệu và Học máy là phân khúc điện toán lớn nhất thế giới. Chỉ những cải tiến nhỏ nhặt về độ chính xác của các mô hình phân tích có thể giúp mang lại hàng tỷ đô la giá trị quy đổi. Để xây dựng các mô hình tốt nhất, các nhà Khoa học dữ liệu đã làm việc cật lực để đào tạo, đánh giá, lặp lại và đào tạo lại để có những kết quả chính xác cao và các mô hình hoạt động hiệu quả.
Với RAPIDS, các quy trình mất nhiều ngày chỉ mất vài phút, giúp việc xây dựng và triển khai các mô hình tạo ra giá trị trở nên dễ dàng và nhanh chóng hơn. Với NVIDIA LaunchPad, bạn có thể thực hành với các bài lab RAPIDS và với NVIDIA AI Enterprise, chúng có thể hỗ trợ doanh nghiệp của bạn trên tất cả mọi khía cạnh của các dự án AI.
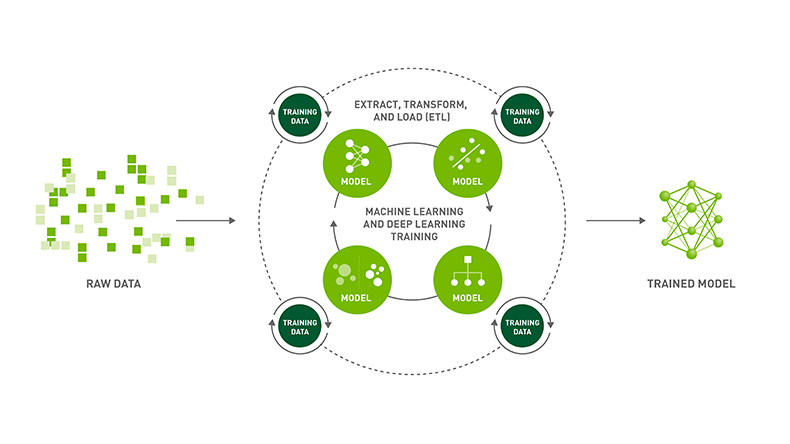
Quy trình làm việc có nhiều lần lặp lại của việc chuyển đổi Dữ liệu thô thành Dữ liệu đào tạo, dữ liệu này được đưa vào nhiều tổ hợp thuật toán, trải qua quá trình điều chỉnh siêu tham số để tìm ra các tổ hợp mô hình, tham số mô hình và tính năng dữ liệu phù hợp để có hiệu suất và độ chính xác tối ưu.
Xây dựng hệ sinh thái hiệu suất cao
RAPIDS là một bộ thư viện phần mềm nguồn mở và API để thực thi các quy trình Khoa học dữ liệu hoàn toàn trên các GPU – và có thể giảm thời gian đào tạo từ vài ngày xuống còn vài phút. Được xây dựng trên NVIDIA CUDA-X AI, RAPIDS kết hợp nhiều năm phát triển về đồ họa, học máy, học sâu, điện toán hiệu năng cao (HPC),…

Thời gian thực thi nhanh hơn
Với Khoa học dữ liệu, nhiều điện toán hơn cho phép bạn gặt hái được thông tin hữu ích nhanh hơn. RAPIDS tận dụng NVIDIA CUDA để tăng tốc quy trình làm việc của bạn bằng việc chạy toàn bộ các bước đào tạo về Khoa học dữ liệu trên GPU. Điều này có thể giảm thời gian đào tạo mô hình của bạn từ vài ngày xuống còn vài phút.

Sử dụng các công cụ tương tự
Bằng việc loại bỏ sự phức tạp khi làm việc với GPU và thậm chí cả các giao thức giao tiếp đằng sau trong kiến trúc trung tâm dữ liệu, RAPIDS tạo ra một cách đơn giản để hoàn thành Khoa học dữ liệu. Khi ngày càng có nhiều nhà Khoa học dữ liệu sử dụng Python và các ngôn ngữ cấp cao khác, việc cung cấp khả năng tăng tốc mà không cần thay đổi code là điều cần thiết để cải thiện nhanh chóng thời gian phát triển.

Chạy ở bất cứ đâu theo quy mô
RAPIDS có thể chạy ở mọi nơi – đám mây hoặc tại chỗ. Bạn có thể dễ dàng mở rộng quy mô từ máy trạm sang máy chủ nhiều GPU đến các cụm nhiều node, cũng như triển khai nó trong sản xuất với Dask, Spark, MLFlow và Kubernetes.

Khoa học dữ liệu sẵn sàng cho doanh nghiệp
Tiếp cận đến hỗ trợ đáng tin cậy thường rất quan trọng đối với các tổ chức sử dụng Khoa học dữ liệu cho những mission-critical insights. Hỗ trợ Doanh nghiệp NVIDIA toàn cầu khả dụng với NVIDIA AI Enterprise, bộ phần mềm AI đầu cuối và bao gồm thời gian phản hồi được đảm bảo, thông báo bảo mật ưu tiên, cập nhật thường xuyên và quyền tiếp cận với các chuyên gia AI của NVIDIA.
Hiệu suất nhanh như chớp trên Big Data
Những kết quả cho thấy GPU giúp tiết kiệm thời gian và chi phí đáng kể cho các vấn đề phân tích Big Data theo quy mô nhỏ và lớn. Sử dụng các API quen thuộc như Pandas và Dask, ở quy mô 10TB, RAPIDS hoạt động trên GPU nhanh hơn tới 20 lần so với mức cơ bản của CPU hàng đầu. Chỉ sử dụng 16 NVIDIA DGX A100 để đạt được hiệu suất của 350 máy chủ dựa trên CPU, giải pháp của NVIDIA tiết kiệm chi phí hơn gấp 7 lần trong khi vẫn mang lại hiệu suất ở cấp độ HPC.

Truy cập dữ liệu nhanh hơn, di chuyển dữ liệu ít hơn
Các tác vụ xử lý dữ liệu phổ biến có nhiều bước (data pipelines) thứ mà Hadoop không thể xử lý hiệu quả. Apache Spark đã giải quyết vấn đề này bằng cách giữ tất cả dữ liệu trong bộ nhớ hệ thống, điều này cho phép các data pipelines phức tạp và linh hoạt hơn, nhưng lại gây ra các nút thắt cổ chai mới. Việc phân tích thậm chí vài trăm GB dữ liệu có thể mất hàng giờ nếu không muốn nói là vài ngày trên các cụm Spark với hàng trăm node CPU.
Để khai thác tiềm năng thực sự của Khoa học dữ liệu, GPU hẳn nhiên phải là trung tâm của thiết kế trung tâm dữ liệu, bao gồm 5 yếu tố sau: Compute, Networking, Storage, Deployment và Software. Nhìn chung, quy trình làm việc Khoa học dữ liệu từ đầu đến cuối trên GPU nhanh hơn 10 lần so với trên CPU.
Sự tiến hóa trong lĩnh vực xử lý dữ liệu

RAPIDS ở mọi nơi
RAPIDS cung cấp một nền tảng cho hệ sinh thái Khoa học dữ liệu hiệu suất cao mới và hạ thấp rào cản gia nhập cho các thư viện mới thông qua khả năng tương tác. Tích hợp với các framework Khoa học dữ liệu hàng đầu như Apache Spark, cuPY, Dask và Numba, cũng như nhiều framework Học sâu, chẳng hạn như PyTorch, TensorFlow và Apache MxNet, giúp mở rộng việc áp dụng và khuyến khích tích hợp với các framework khác. Bạn có thể tìm thấy RAPIDS và các framework tương quan trong NGC catalog.
-
Featured Projects

dask-sql là một engine SQL phân tán bằng Python, thực hiện ETL theo quy mô với RAPIDS để tăng tốc GPU.

Được xây dựng trên RAPIDS, NVTabular tăng tốc kỹ thuật và tiền xử lý tính năng cho các hệ thống gợi ý (recommender systems) trên GPU.


Được tích hợp với RAPIDS, Plotly Dash cho phép phân tích dữ liệu trực quan tương tác, thời gian thực của những bộ dữ liệu nhiều gigabyte ngay cả trên một GPU đơn.

Trình tăng tốc RAPIDS cho Apache Spark cung cấp một bộ plug-ins cho Apache Spark tận dụng GPU để tăng tốc xử lý thông qua phần mềm RAPIDS và UCX.
-
Contributors









-
Adopters















-
Open Source







Công nghệ cốt lõi
RAPIDS dựa vào các nguyên mẫu CUDA để tối ưu hóa điện toán ở cấp độ thấp nhưng cho thấy tính song song của GPU và băng thông bộ nhớ cao thông qua các giao diện Python thân thiện với người dùng. RAPIDS hỗ trợ các quy trình làm việc Khoa học dữ liệu từ đầu đến cuối, từ tải dữ liệu và tiền xử lý cho đến Học máy, phân tích biểu đồ và trực quan hóa (visualization). Đó là một stack Python đầy đủ chức năng mở rộng quy mô cho các trường hợp sử dụng Big Data của doanh nghiệp.

Tải dữ liệu và tiền xử lý
Các tính năng tải dữ liệu, tiền xử lý và ETL của RAPIDS được xây dựng trên Apache Arrow để tải, nối, tổng hợp, lọc và thao tác dữ liệu, tất cả đều có trong một API giống như Pandas, quen thuộc với các nhà khoa học dữ liệu. Người dùng có thể mong đợi tốc độ tăng tốc thông thường từ 10 lần trở lên.

Học máy
Các thuật toán Học máy và nguyên hàm toán học của RAPIDS tuân theo một API giống như scikit-learn quen thuộc. Các công cụ phổ biến như XGBoost, Random Forest và nhiều công cụ khác được hỗ trợ cho cả triển khai single-GPU và trung tâm dữ liệu lớn. Đối với các bộ dữ liệu lớn, các triển khai dựa trên GPU này có thể hoàn thành nhanh hơn 10-50 lần so với các triển khai CPU tương đương của chúng.

Phân tích đồ thị
Các thuật toán đồ thị của RAPIDS như PageRank và các chức năng như NetworkX sử dụng hiệu quả tính song song to lớn của GPU để tăng tốc độ phân tích các đồ thị lớn hơn 1000 lần. Khám phá lên đến 200 triệu cạnh trên một GPU NVIDIA A100 Tensor Core đơn lẻ và mở rộng quy mô lên hàng tỷ cạnh trên các cụm NVIDIA DGX A100.

Trực quan hoá
Các tính năng trực quan hóa của RAPIDS hỗ trợ lọc chéo (cross-filtering) được tăng tốc bởi GPU. Lấy cảm hứng từ phiên bản JavaScript của bản gốc, nó cho phép lọc đa chiều tương tác và siêu nhanh của hơn 100 triệu bộ dữ liệu dạng bảng.

Tích hợp Deep Learning
Mặc dù Deep Learning có hiệu quả trong các lĩnh vực như Thị giác máy tính, xử lý ngôn ngữ tự nhiên và hệ thống gợi ý, nhưng ở một số lĩnh vực thì việc sử dụng nó vẫn chưa phổ biến. Các bài toán về dữ liệu dạng bảng, bao gồm các cột của các biến phân loại và liên tục, thường sử dụng các kỹ thuật như XGBoost, tăng cường độ dốc hoặc mô hình tuyến tính.
RAPIDS chuẩn hóa quá trình tiền xử lý dữ liệu dạng bảng trên GPU và cung cấp chuyển giao dữ liệu liền mạch trực tiếp tới bất kỳ framework nào hỗ trợ DLPack như PyTorch, TensorFlow và MxNet. Những tích hợp này mở ra những cơ hội mới để tạo ra các quy trình làm việc phong phú, ngay cả những quy trình trước đây không hợp lý như cung cấp các tính năng mới được tạo từ các framework Deep Learning trở lại các thuật toán Machine Learning.
Trung tâm dữ liệu hiện đại cho Khoa học dữ liệu
Có 5 thành phần chính để xây dựng các trung tâm dữ liệu được tối ưu hóa cho AI trong doanh nghiệp. Chìa khóa của thiết kế là đặt các GPU ở trung tâm.

Compute
Với hiệu năng tính toán vượt trội, các hệ thống có GPU NVIDIA là khối xây dựng (building block) tính toán cốt lõi cho các trung tâm dữ liệu AI. Các hệ thống NVIDIA DGX mang lại hiệu suất AI đột phá và có thể thay thế, trung bình 50 máy chủ dual-socket. Đây là bước đầu tiên để cung cấp cho các nhà Khoa học dữ liệu những công cụ mạnh mẽ nhất trong ngành để khám phá dữ liệu.

Software
Bằng việc loại bỏ sự phức tạp khi làm việc với GPU và các giao thức truyền thông đằng sau trong kiến trúc trung tâm dữ liệu, RAPIDS tạo ra một cách đơn giản để hoàn thành Khoa học dữ liệu. Khi ngày càng có nhiều nhà khoa học dữ liệu sử dụng Python và các ngôn ngữ cấp cao khác, việc cung cấp khả năng tăng tốc mà không cần thay đổi code là điều cần thiết để cải thiện nhanh chóng thời gian phát triển.

Networking
Truy cập bộ nhớ trực tiếp từ xa (RDMA) trong bộ điều khiển giao diện mạng (NIC) NVIDIA Mellanox, NCCL2 (thư viện giao tiếp chung NVIDIA) và OpenUCX (một framework giao tiếp điểm-điểm nguồn mở) đã dẫn đến những cải tiến to lớn về tốc độ đào tạo. Với RDMA cho phép các GPU giao tiếp trực tiếp với nhau qua các node với tốc độ lên tới 100Gb/s, chúng có thể mở rộng trên nhiều node và hoạt động như thể chúng đang ở trên một máy chủ lớn.

Deployment
Doanh nghiệp đang chuyển sang các container Kubernetes và Docker để triển khai các quy trình theo quy mô. Việc kết hợp các ứng dụng được container hoá với Kubernetes cho phép doanh nghiệp thay đổi mức độ ưu tiên đối với nhiệm vụ nào là quan trọng nhất và bổ sung khả năng phục hồi, độ tin cậy và khả năng mở rộng cho các trung tâm dữ liệu AI.

Storage
GPUDirect Storage cho phép cả NVMe và NVMe over Fabric (NVMe-oF) đọc và ghi dữ liệu trực tiếp vào GPU, bỏ qua CPU và bộ nhớ hệ thống. Điều này giải phóng CPU và bộ nhớ hệ thống cho các tác vụ khác, đồng thời cấp cho mỗi GPU quyền truy cập vào các phần dữ liệu lớn hơn với băng thông lớn hơn tới 50%.
Cam kết của chúng tôi đối với Khoa học dữ liệu nguồn mở
NVIDIA cam kết đơn giản hóa, thống nhất và tăng tốc Khoa học dữ liệu cho cộng đồng nguồn mở. Bằng cách tối ưu hóa toàn bộ stack – từ phần cứng đến phần mềm – và bằng cách loại bỏ thắt cổ chai cho Khoa học dữ liệu lặp lại, NVIDIA đang giúp các nhà Khoa học dữ liệu ở khắp mọi nơi làm được nhiều việc hơn bao giờ hết với chi phí ít hơn. Việc này mang lại nhiều giá trị hơn cho các doanh nghiệp từ nguồn tài nguyên quý giá nhất của họ: dữ liệu và các nhà Khoa học dữ liệu. Là phần mềm nguồn mở Apache 2.0, RAPIDS tập hợp một hệ sinh thái trên các GPU.
Theo NVIDIA
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?