
Giới thiệu
Thế giới Trí tuệ nhân tạo đã bị rung chuyển vào khoảng năm 2012 khi nhóm của Geoffrey Hinton tại Đại học Toronto sử dụng GPU trong quá trình xử lý Mạng nơ-ron nhân tạo – nơi luận án Tiến sĩ của Alex Krizhevsky đã giành chiến thắng trong cuộc thi nhận dạng đối tượng của Imagenet khi sử dụng chúng. Kết quả, như mọi người đều biết, thật đáng kinh ngạc – độ chính xác tăng 15% chỉ sau một đêm so với các kỹ thuật học máy khác, và điều này đã bắt đầu một sự bùng nổ về nghiên cứu và ứng dụng trong thế giới Mạng nơ-ron nhân tạo cho nhiều mục đích khác nhau, đặc biệt là trong lĩnh vực Mạng nơ-ron tích chập (Convolutional Neural Network, CNN), hiện được gọi là Học sâu (Deep Learning).
Mặc dù việc đánh giá đầy đủ lĩnh vực rộng lớn này nằm ngoài phạm vi của bài viết, nhưng một điểm khởi đầu tốt cho người đọc là bài viết về Học sâu trên Wikipedia, trong đó ghi chép lại lịch sử và tình trạng hiện tại của lĩnh vực này. Yoshua Bengio, Geoffrey Hinton và Yann LeCun đã được trao giải Turing Award của ACM vì những đóng góp to lớn của họ cho lĩnh vực này. NVIDIA đã đi đầu trong cuộc cách mạng này kể từ năm 2009 với GPU của họ, nó chính là công nghệ xương sống cho các nỗ lực này.
Khi GPU trở nên mạnh mẽ hơn, vượt xa những tiến bộ trong xử lý CPU, các điểm nghẽn mới xuất hiện trong kiến trúc xử lý, khi đó việc di chuyển dữ liệu giữa bộ nhớ chính (SYSMEM) và bộ nhớ GPU, cũng như việc di chuyển dữ liệu GPU-GPU ngày càng trở thành yếu tố hạn chế khả năng “vắt sức” cho các nhân GPU.
Điều này thúc đẩy sự ra đời của một tập hợp các công nghệ từ NVIDIA sử dụng Remote Direct Memory Access (RDMA) để bỏ qua tổ hợp SYSMEM/CPU nhằm cho phép giao tiếp trực tiếp giữa các GPU trong cùng một máy chủ và với các máy chủ khác, được gọi là GPUDirect. Điều này cho phép nhiều GPU tại một hệ thống đơn hay trên nhiều hệ thống phối hợp nhau trong việc đào tạo các mô hình lớn. Nhưng việc này vẫn để lại hạn chế trong việc di chuyển dữ liệu từ IO subsystem đến tổ hợp GPU, theo truyền thống phải sử dụng SYSMEM làm “bộ đệm phản hồi” (bounce buffer) để đưa dữ liệu vào bộ nhớ GPU.
Sau đó, NVIDIA bắt đầu phát triển một giải pháp mở rộng – GPUDirect Storage (GDS) – để cho phép di chuyển trực tiếp dữ liệu từ hệ thống lưu trữ đến bộ nhớ GPU khi cần thiết, bỏ qua SYSMEM. Một khởi đầu tốt để làm quen với các công nghệ này là các slide trình chiếu tại NVIDIA GTC 2020 dành cho MagnumIO và GPUDirect for Storage. Để biết thêm chi tiết, hãy tìm hiểu tài liệu GPUDirect for Storage Design Guide.
Vậy GPUDirect Storage (GDS) là gì?
Luồng dữ liệu truyền thống từ Bộ lưu trữ đến GPU thường đi qua NIC để đến CPU (thông qua một tổ hợp PCIe Switch trong Hệ thống NVIDIA DGX lớn hơn được xây dựng cho mục đích này) và đến SYSMEM, sau đó dữ liệu được chuyển đến bộ nhớ GPU để xử lý thêm, như thể hiện trong Hình 1. Đây là một hạn chế không cần thiết theo nhiều cách, trừ khi CPU cần xử lý trước một số bước.
Đầu tiên, đây là một bước không cần thiết cho dữ liệu giữa SYSMEM và GPU. Tiếp theo, hoạt động này yêu cầu sử dụng các tài nguyên CPU quý giá có thể được sử dụng cho một số xử lý khác. Cuối cùng, băng thông tổng hợp mà bộ lưu trữ có thể cung cấp cho hệ thống bị giới hạn bởi băng thông SYSMEM-GPU bên trong, thường ít hơn đáng kể so với băng thông mà một hệ thống lưu trữ được thiết kế tốt có thể cung cấp thông qua nhiều NIC trên hệ thống. Ví dụ, trên hệ thống NVIDIA DGX-2, có thể thấy rằng chúng có thể đạt được tối đa khoảng 50GiB/s cho băng thông nội bộ, trong khi 8x100Gb IB NIC có thể cung cấp gần gấp đôi băng thông.
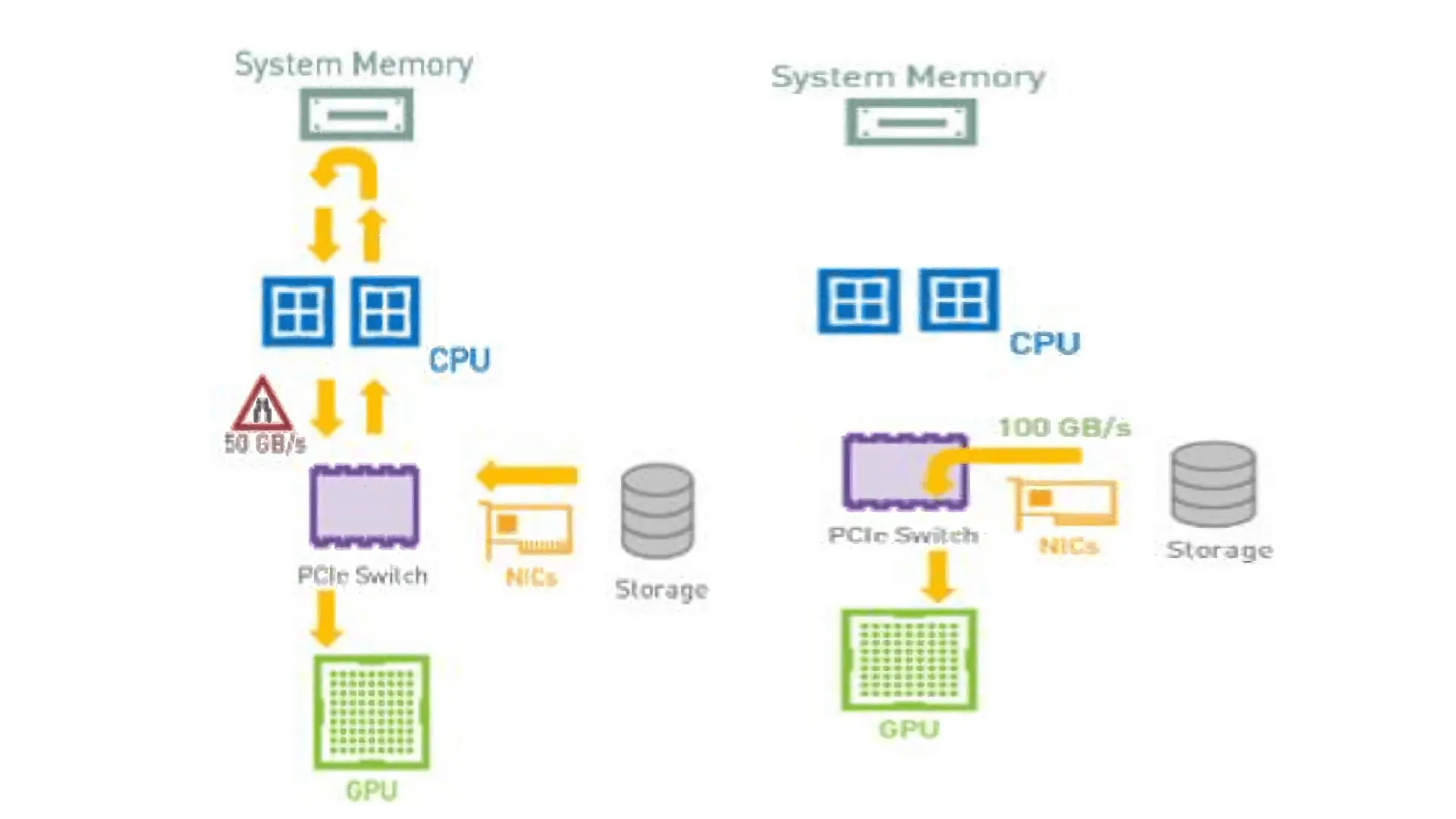
GDS giải quyết vấn đề đó một cách khéo léo, một lần nữa bằng cách khai thác khả năng DMA hoặc RDMA từ bộ lưu trữ. Như Hình 2 cho thấy, nếu hệ thống lưu trữ hỗ trợ (R)DMA, nó có thể được dẫn hướng di chuyển dữ liệu trực tiếp đến địa chỉ Bộ nhớ GPU thay vì địa chỉ bộ nhớ SYSMEM, do đó bỏ qua hoàn toàn tổ hợp CPU/SYSMEM. Điều này cho phép truyền dữ liệu đến hệ thống ở tốc độ gần bằng tốc độ đường truyền, vì nó không còn bị giới hạn bởi băng thông bộ nhớ nội bộ.
Đến với VAST Data
VAST Data là kiến trúc NVMe all-flash hiện đại phá vỡ sự đánh đổi giữa hiệu suất, quy mô và chi phí. Bằng cách sử dụng kết hợp NVMeoF, Storage Class Memory (bộ nhớ dành cho lưu trữ) và công nghệ QLC NAND trong kiến trúc không có bộ nhớ đệm, giải pháp này đã mang lại hiệu suất phá vỡ kỷ lục, khả năng mở rộng siêu tuyến tính và chi phí tiếp cận mức kinh tế của các hệ thống dựa trên ổ cứng HDD. Một cụm VAST Cluster tự trình bày với các hệ thống máy khách thông qua các giao thức chuẩn công nghiệp – NFS, NFS over RDMA, SMB và S3, với sự hỗ trợ cho Kubernetes CSI trong thế giới của kiến trúc container.
Khi VAST bắt đầu làm việc với NVIDIA vào đầu năm 2020, họ đã nhanh chóng nhận ra, cùng với NVIDIA GDS Engineering, rằng VAST Data trở thành một RDMA target cho các hệ thống DGX-2 mà họ đã thử nghiệm. Các kỹ sư NVIDIA GDS đã thử nghiệm với GDS hoạt động trên các hệ thống NFS hỗ trợ RDMA và đã tìm kiếm một hệ thống lưu trữ thương mại hỗ trợ nó. VAST đã thử nghiệm điều này và thật đáng kinh ngạc, VAST NFS over RDMA hoạt động trơn tru với GDS ngay từ đầu – nhóm của VAST đã có kết quả có thể sử dụng được chỉ trong vài giờ mà không cần sửa đổi hệ thống.
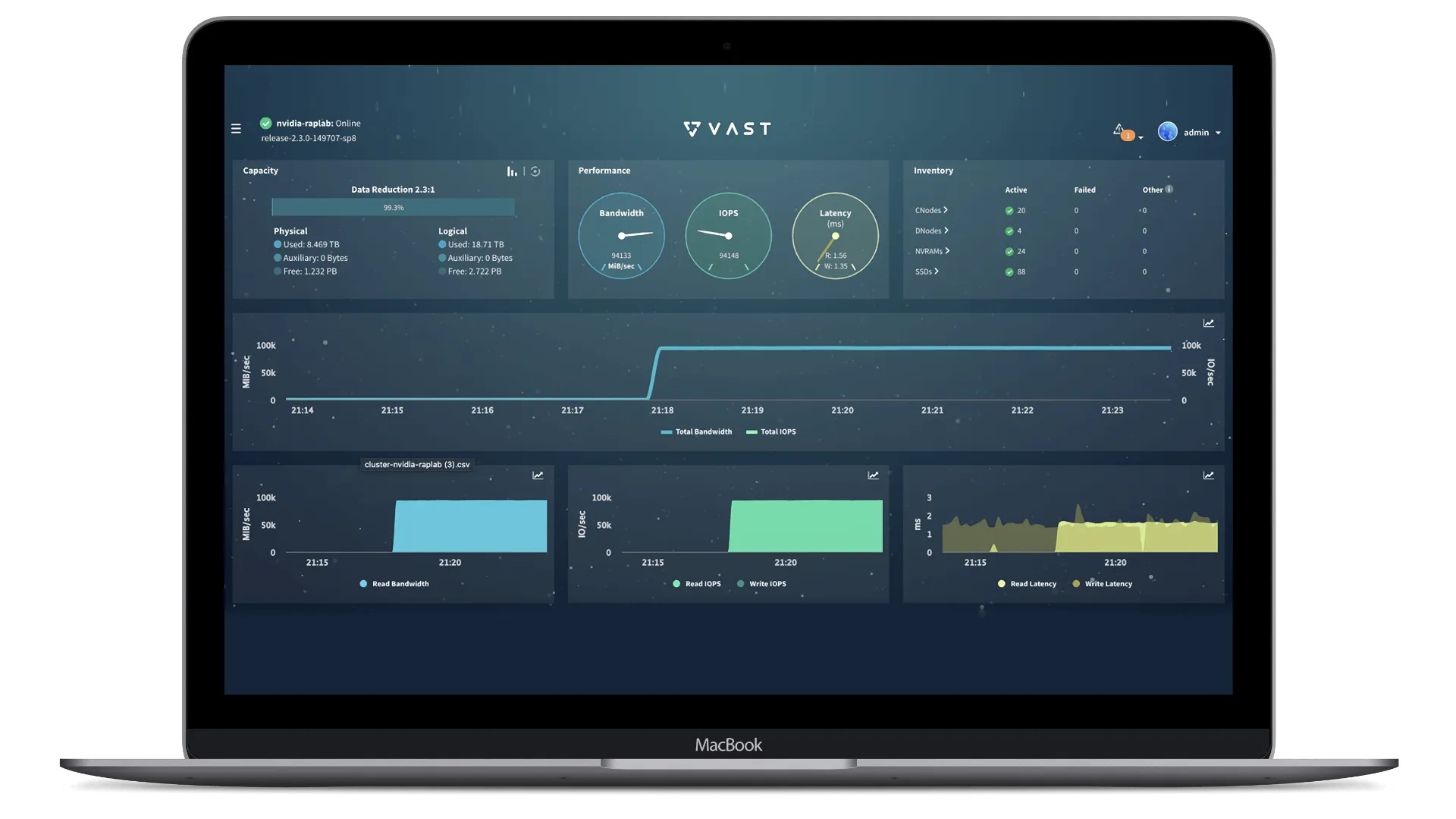
Điều này đã bắt đầu một sự hợp tác hiệu quả cao giữa VAST và với một số hệ thống lớn hơn, họ đã nhanh chóng chứng minh rằng họ có thể bắt kịp băng thông tốc độ đường truyền với hệ thống DGX-2. Được thể hiện bên dưới trong Hình 3 là VAST UI cung cấp dữ liệu cho hệ thống DGX-2 với 8 x 100 Gb HDR100 IB NIC, cung cấp thông lượng 94+ GB/s 1 MB IO Size Read liên tục (với con số ghi nhận cao nhất lên tới 98 GB/s). Một trong những điểm chính cần lưu ý ở đây là thông lượng này được cung cấp thông qua một điểm gắn NFSoRDMA duy nhất đến một hệ thống DGX-2 máy khách duy nhất, điều này chưa từng có đối với NFS.
Có lẽ điều thú vị hơn nữa đó là, trên thực tế, tác dụng của việc bỏ qua CPU/SYSMEM đã gây ấn tượng mạnh mẽ đến việc sử dụng CPU của hệ thống. Hình 4 cho thấy dữ liệu di chuyển đến GPU bằng đường truyền dẫn truyền thống (như thể hiện trong Hình 1) và đạt được không quá 33 GB/s trước khi làm kiệt năng lực CPU. Ngược lại, trong Hình 5, tốc độ truyền dữ liệu đạt gần với băng thông hữu dụng nhưng chỉ sử dụng 15% CPU như kết quả từ htop.

Bước tiếp theo: GDS với DGX A100
Vào giữa năm 2020, NVIDIA đã công bố nền tảng DGX mới dựa trên GPU A100 mang tính cách mạng, một bước tiến vượt bậc của điện toán trí tuệ nhân tạo tại thời điểm đó. Kiến trúc hệ thống sử dụng 8x GPU A100, bộ xử lý AMD Epyc (Rome) và 8 NIC HDR 200 Gb, với băng thông đường truyền lý thuyết là 200 GB/s trên một hệ thống duy nhất – rõ ràng là một sự thay đổi vượt bậc.
Vì GDS vẫn chưa sẵn sàng phổ biến (tính đến thời điểm viết bài này), VAST cũng đã công bố Kiến trúc tham chiếu NVIDIA/VAST chung cho các hệ thống DGX A100 không có GDS. Tất cả các phép đo đều được NVIDIA thực hiện trong phòng thí nghiệm của họ. Bạn đọc muốn tìm hiểu chi tiết nên tải xuống và nghiên cứu thêm trong tài liệu này. Để làm nổi bật một số điểm trong đó, kết quả từ việc chạy MLPerf với 1 đến 4 DGX A100 được hiển thị bên dưới.
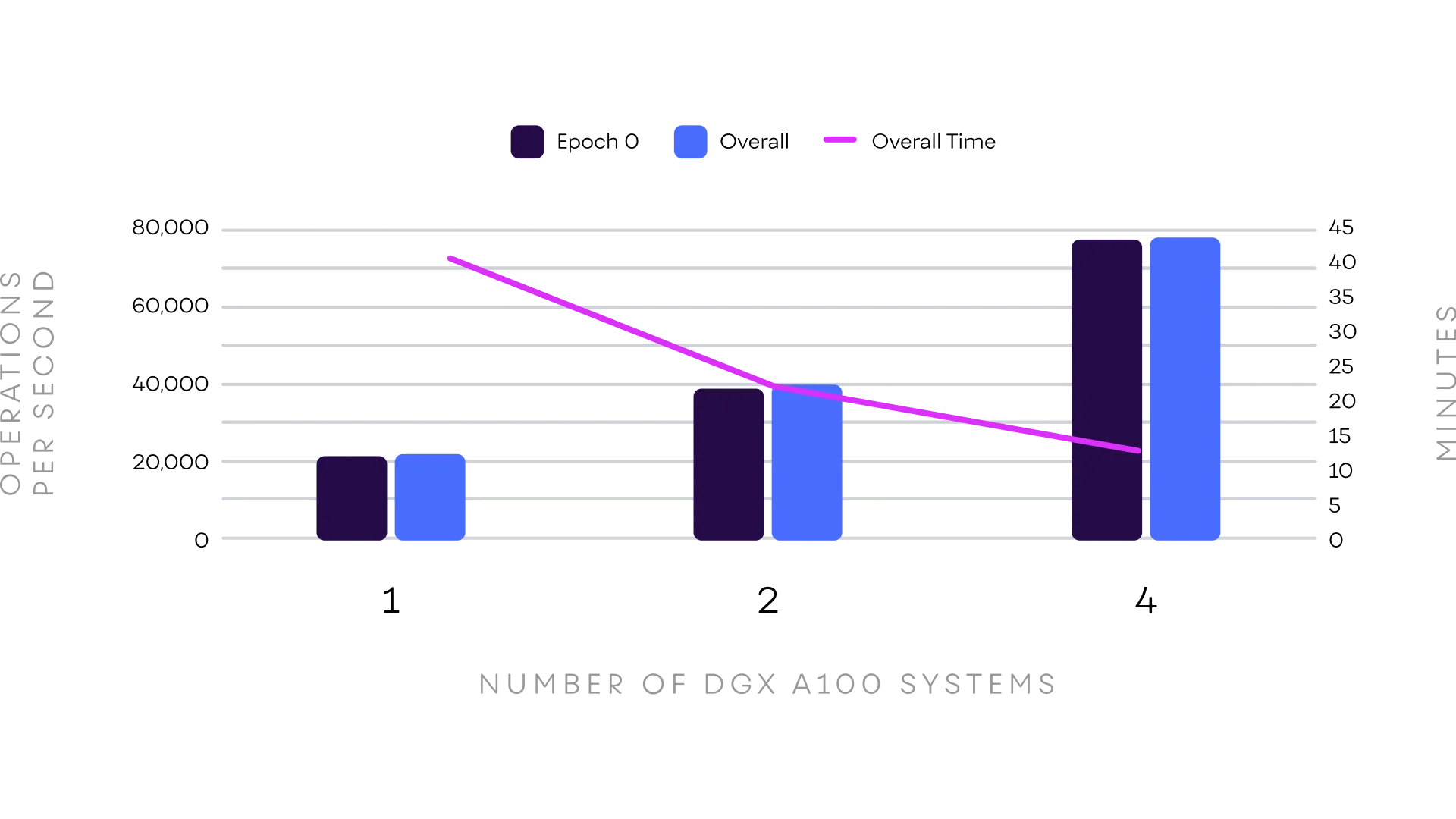
Bài test MLPerf Training (v0.7) kiểm tra điểm benchmark về phân loại hình ảnh Resnet-50 Residual CNN nổi tiếng trên tập dữ liệu Imagenet (thường chạy dưới MXNet, Tensorflow hoặc Pytorch) và kết quả thu được cho thấy tính tuyến tính ấn tượng trong việc mở rộng cũng như số lượng hình ảnh/giây. Tuy nhiên, thậm chí còn ấn tượng hơn là với Epoch 0 (lần đào tạo đầu tiên trên dữ liệu) thường là dữ liệu trực tiếp từ hệ thống lưu trữ, không có gì trong bộ đệm hệ thống file, có sự khác biệt gần bằng không với mức trung bình chung cho tất cả các Epoch. Điều này cho thấy hiệu suất cụm VAST cũng tốt như các epoch tiếp theo khi dữ liệu có thể đến từ bộ nhớ hệ thống! Quay lại GDS trên DGX A100…
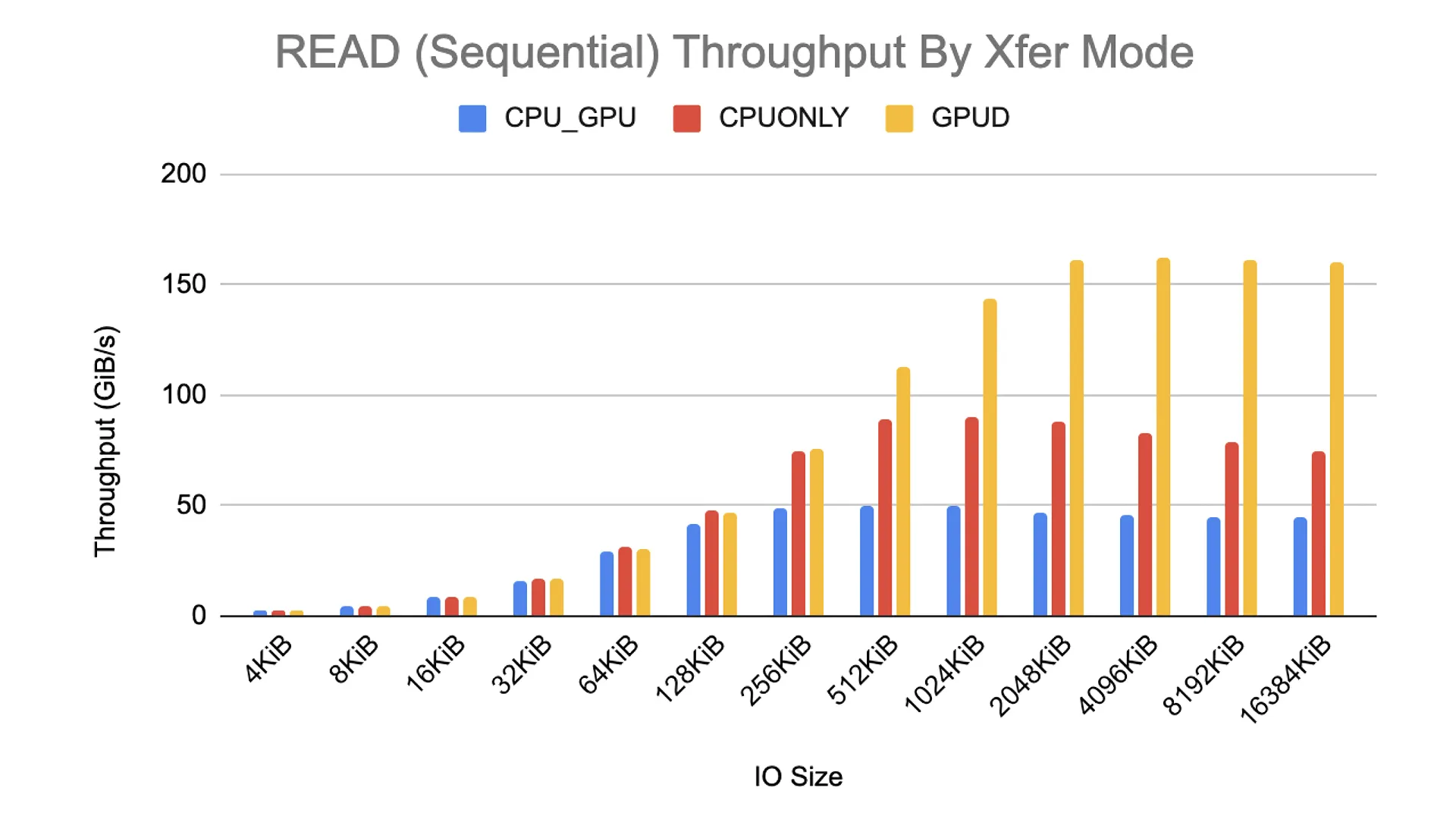
Kết quả không hề thất vọng khi thử nghiệm GDS trên VAST Data Cluster và với máy chủ DGX A100. Nhóm thử nghiệm của VAST đạt được tối đa 162 GiB/s Read Throughput – có vẻ như là mức tối đa mà hệ thống có thể cung cấp, bão hòa hoàn toàn khả năng của hệ thống DGX A100. Các kết quả dưới đây là từ phép đánh giá chuẩn do NVIDIA thực hiện (không phải VAST) và đã được trình bày và công bố tại sự kiện NVIDIA GTC 2020.
VAST Data là một trong số ít nhà cung cấp đã được chọn hỗ trợ GDS chính thức khi NVIDIA ra mắt. Nhiều nỗ lực liên quan đến hệ sinh thái khác cũng đã được thực hiện trong khoản thời gian đó, với sự hỗ trợ cho các API NVIDIA cuFile (cần thiết để khai thác các khả năng của GDS) trong các Deep Learning Framework chính như Tensorflow, PyTorch và MXNet, cũng như khám phá các ứng dụng mới cho công việc này.
Sự quan tâm của cộng đồng học sâu với điều này là rất lớn. Nhiều khách hàng đã từng mua hệ thống DGX rất quan tâm đến giải pháp kết hợp hệ thống đó với nền tảng của VAST, kể cả có hoặc không có GDS, vì VAST Data cung cấp một nền tảng có khả năng mở rộng, hiệu suất cao và tiết kiệm chi phí để làm cơ sở cho tải xử lý Deep Learning của họ.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi hiện là đối tác phân phối giải pháp nền tảng dữ liệu doanh nghiệp VAST Data chuyên cho AI, Deep Learning.
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi hiện là đối tác phân phối giải pháp nền tảng dữ liệu doanh nghiệp VAST Data chuyên cho AI, Deep Learning.
Chúng tôi cũng là nhà phân phối chính thức của NVIDIA cho các hệ thống điện toán hiệu năng cao dựa trên GPU như siêu máy tính Trí tuệ Nhân tạo NVIDIA DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh xử lý của các dòng GPU Data Center tối tân nhất, cùng hệ thống lưu trữ dựa trên VAST Data và mạng tốc độ cao từ Mellanox (thuộc NVIDIA).
Bạn muốn trở thành đối tác bán hàng VAST của NTC?
Bài viết liên quan