Inference (suy luận) là workload quan trọng trong các ứng dụng của Trí tuệ Nhân tạo. Inference giúp xử lý các tác vụ phân loại, nhận dạng và dự đoán trong thời gian thực trên dữ liệu đầu vào. Nó là một tập hợp các giải pháp công nghệ phần cứng và phần mềm, bao gồm các GPU (Graphics Processing Unit) mạnh mẽ và các thư viện phần mềm liên quan như cuDNN (CUDA Deep Neural Network) và TensorRT, giúp tăng tốc quá trình suy luận trên mạng neural. Nền tảng này bao gồm các thành phần sau:
• Inference Server: Máy chủ suy luận AI hiệu suất cao hỗ trợ nhiều khuôn khổ AI phổ biến.
• Bộ công cụ TensorRT: Giúp tối ưu hóa hiệu suất của các mô hình AI cho GPU
• NVIDIA NGC: Kho lưu trữ các mô hình AI được đào tạo sẵn và tối ưu hóa cho GPU NVIDIA.
Inference AI giúp các doanh nghiệp:
• Tăng tốc độ triển khai các ứng dụng AI.
• Cải thiện hiệu suất của các mô hình AI.
• Giảm chi phí vận hành các ứng dụng AI.
Các ứng dụng của Inference AI bao gồm:
• Xử lý ảnh và video: Inference AI có thể được sử dụng để phát hiện đối tượng, nhận dạng khuôn mặt, phát hiện hành vi và xử lý hình ảnh và video trong thời gian thực. Các ứng dụng bao gồm giám sát an ninh, xe tự lái, quét mã vạch và nhận dạng biển số xe.
• Xử lý ngôn ngữ tự nhiên (NLP): Inference AI cũng có thể được áp dụng trong các ứng dụng NLP như dịch máy, tổng hợp tiếng nói, phân loại văn bản và trả lời tự động.
• Quy mô và tối ưu hóa mô hình AI: Inference AI cung cấp các công cụ để quy mô và tối ưu hóa mô hình AI, giúp tăng tốc suy luận và giảm độ trễ.
• Ứng dụng trong y tế: Inference AI có thể được sử dụng để phân tích hình ảnh y tế như siêu âm, MRI và X-quang, hỗ trợ các bác sĩ trong việc chẩn đoán và điều trị bệnh.
• Phát hiện gian lận và bảo mật: Inference AI cũng có thể được sử dụng để phát hiện gian lận và các hành vi đáng ngờ trong các hệ thống thanh toán trực tuyến và các ứng dụng bảo mật khác.
Quá trình suy luận trong trí tuệ nhân tạo (AI) bao gồm các bước chính sau:
- Thu thập dữ liệu: Bước này bao gồm việc thu thập các dữ liệu đầu vào từ các nguồn khác nhau, như cơ sở dữ liệu, tệp văn bản, hình ảnh, âm thanh, hoặc dữ liệu từ cảm biến.
- Tiền xử lý dữ liệu: Dữ liệu thu thập được có thể không hoàn hảo và cần phải được tiền xử lý để loại bỏ nhiễu, chuẩn hóa, hoặc mã hóa thành định dạng phù hợp cho các mô hình suy luận.
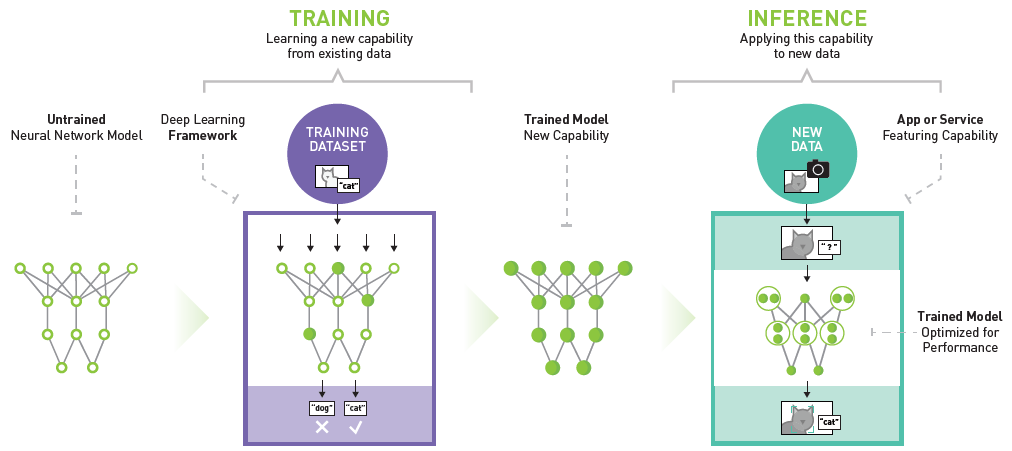
- Xây dựng mô hình suy luận: Ở bước này, các mô hình máy học hoặc mạng nơ-ron được xây dựng và huấn luyện trên dữ liệu tiền xử lý để có khả năng suy luận và đưa ra dự đoán.
- Suy luận và đưa ra dự đoán: Khi mô hình đã được huấn luyện, nó có thể được sử dụng để suy luận trên dữ liệu mới và đưa ra các dự đoán hoặc quyết định.
Frameworks phổ biến được sử dụng cho quá trình suy luận AI hiện nay bao gồm:
- TensorFlow: TensorFlow là một thư viện mã nguồn mở phổ biến được phát triển bởi Google, chủ yếu được sử dụng để xây dựng và huấn luyện các mô hình máy học và mạng nơ-ron. Nó cung cấp các API linh hoạt cho việc triển khai và suy luận mô hình trên nhiều nền tảng.
- PyTorch: PyTorch là một thư viện mã nguồn mở được phát triển bởi Facebook, được sử dụng rộng rãi cho việc xây dựng mạng nơ-ron và mô hình máy học. Nó cung cấp một giao diện dễ sử dụng và có tính linh hoạt cao, cho phép người dùng dễ dàng xây dựng và huấn luyện các mô hình phức tạp.
- ONNX (Open Neural Network Exchange): ONNX là một định dạng mô hình mã nguồn mở được phát triển bởi Microsoft, Facebook và AWS, cho phép chuyển đổi giữa các framework máy học khác nhau như TensorFlow, PyTorch, và MXNet một cách dễ dàng.
- TensorRT: TensorRT là một nền tảng tối ưu hóa và triển khai được phát triển bởi NVIDIA, giúp tối ưu hóa và triển khai các mô hình máy học trên các thiết bị với GPU của NVIDIA để đạt hiệu suất cao và thời gian suy luận thấp.
- Scikit-learn: Một thư viện Python phổ biến cho học máy và khoa học dữ liệu. Nó cung cấp nhiều thuật toán học máy được cài đặt sẵn có thể được sử dụng cho các nhiệm vụ như phân loại, hồi quy và cụm.
- Keras: Một thư viện Python cấp cao cho mạng nơ-ron nhân tạo. Nó được xây dựng trên TensorFlow và PyTorch, giúp việc tạo và đào tạo mạng nơ-ron trở nên dễ dàng hơn.
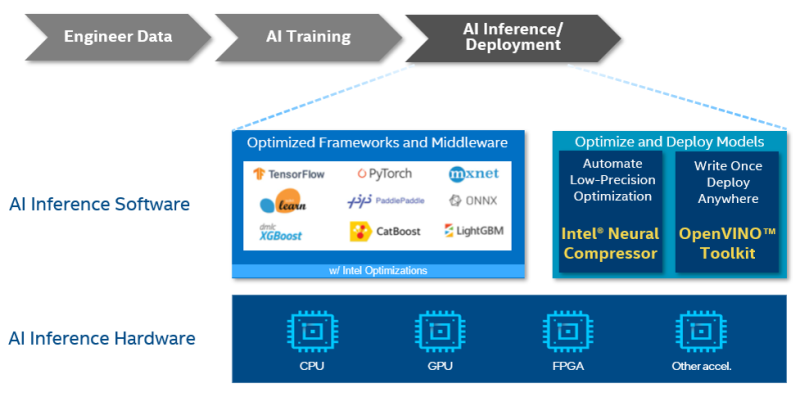
Ngoài các frameworks này, còn có nhiều công cụ và thư viện khác có thể hữu ích cho quá trình suy luận AI. Một số công cụ phổ biến bao gồm:
- Jupyter Notebook: Một môi trường tương tác để phát triển và chạy mã Python.
- Google Colab: Một dịch vụ miễn phí cho phép bạn chạy mã Python trong đám mây.
- Kaggle: Một cộng đồng trực tuyến cho các nhà khoa học dữ liệu và các nhà phát triển AI.
Chọn máy chủ phù hợp để triển khai suy luận AI:
Để triển khai và vận hành tối ưu cho hệ thống suy luận AI, các doanh nghiệp cần trang bị các máy chủ phù hợp với các GPU chuyên dụng đáp ứng khả năng suy luận AI ở môi trường production. Những máy chủ GPU được thiết kế để đảm đương vai trò workload dành cho suy luận có thể được triển khai ở biên hoặc trong trung tâm dữ liệu.
Mỗi vị trí máy chủ có các yêu cầu về thiết kế, cấu hình và phù hợp với môi trường riêng
- Các máy chủ của Trung tâm dữ liệu được xác thực về hiệu suất và khả năng mở rộng quy mô trên nhiều khối lượng công việc khoa học dữ liệu và lý tưởng cho việc suy luận của trung tâm dữ liệu.
- Hệ thống Enterprise Edge được thiết kế để triển khai trong các môi trường được kiểm soát, chẳng hạn như văn phòng hỗ trợ của một cửa hàng bán lẻ. Các hệ thống thuộc danh mục này được thử nghiệm trong môi trường giống như trung tâm dữ liệu.
- Hệ thống Industrial Edge được thiết kế cho môi trường công nghiệp hoặc khắc nghiệt, chẳng hạn như sàn nhà máy hoặc trạm gốc tháp điện thoại di động.
Hiểu được cách hoạt động của suy luận AI, sau đây là các nhu cầu tính toán cụ thể để thực hiện tác vụ này nhanh nhất và hiệu quả nhất.
- GPU NVIDIA
- Cấu hình CPU, bộ nhớ và mạng mang lại hiệu suất tối ưu
- Khả năng bảo mật và quản lý từ xa
| Resource | AI training in the data center | AI inferencing at the edge |
| CPU | Fastest CPUs with high core count | Lower-power CPUs |
| GPU | Fastest GPUs with most memory, more GPUs per system | Lower-power GPU, or larger GPU with MIG, one or two GPUs per system |
| Memory | Large memory size | Average memory size |
| Storage | High bandwidth NVMe flash drive, one per CPU | Average bandwidth, lowest-latency NVMe flash drive, one per system |
| Network | Highest bandwidth network adapter, Ethernet or InfiniBand, one per GPU pair | Average bandwidth network adapter, Ethernet, one per system |
| PCIe System | Devices balanced across PCIe topology; PCIe switch for multi-GPU, multi-NIC deployments | Devices balanced across PCIe topology; PCIe switch not required |
Hiện nay Nhất Tiến Chung đang cung cấp những loại máy chủ GPU đã được xác thực bởi NVIDIA (NVIDIA-certified Systems) cho việc triển khai hệ thống suy luận AI. Chúng tôi xin gợi ý một số cấu hình tiêu biểu như sau:
Máy chủ Supermicro SYS-120C-TN10R
 |
|
| Form factor | 1U rackmount |
| Processor Support | • Dual sockets P+ (LGA-4189) 3rd Gen Intel® Xeon® Scalable processors • Up to 40C/80T; Up to 60MB Cache per CPU |
| Memory Slots & Capacity | 16 DIMMs up to 6TB 3DS ECC DDR4-3200: LRDIMM/RDIMM/Intel® Intel® DCPMM |
| GPU Support | • Up to 2 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | 10x 2.5″ hot-swap hybrid NVMe/SATA/SAS drive bays |
| Network Interface | Dual AIOM (OCP 3.0) slots with NCSI for networking, 1 dedicated IPMI LAN |
| Power Supply | 860W redundant Platinum level 100-240Vac and 200-240 Vdc power supplies |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Máy chủ HPE DL360 Gen 10+
 |
|
| Form factor | 1U rackmount |
| Processor Support | Up to two 3rd Generation Intel Xeon Scalable processors, with up to 40 cores per processor |
| Memory Slots & Capacity | • 32 DDR4 DIMM slots, supports 3200 MT/s HPE DDR4 Smart Memory up to 8.0 TB |
| GPU Support | • Up to 3 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | 8 SFF with options for aditional 2 SFF drive bays: 12G x1 SAS/SATA, 24G x4 Tri-Mode or 16G x4 NVMe 4 LFF |
| Network Interface | Broadcom BCM57416 Ethernet 10Gb 2-port BASE-T OCP3 Adapter for HPE |
| Power Supply | • HPE 500W • HPE 800W • HPE 1600W • HPE 1800W-2200W |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Máy chủ Dell R650
 |
|
| Form factor | 1U rackmount |
| Processor Support | Up to two 3rd Generation Intel Xeon Scalable processors, with up to 40 cores per processor |
| Memory Slots & Capacity | • 32 DDR4 DIMM slots, supports RDIMM 2 TB max or LRDIMM 8 TB max, speeds up to 3200 MT/s • Up to 16 Intel Persistent Memory 200 series (BPS) slots, 12 TB max • Supports registered ECC DDR4 DIMMs only |
| GPU Support | • Up to 3 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | Front bays: • Up to 10 x 2.5-inch SAS/SATA/NVMe (HDD/SSD) max 153 TB • Up to 4 x 3.5-inch SAS/SATA (HDD/SSD) max 64 TB • Up to 8 x 2.5-inch SAS/SATA/NVMe (HDD/SSD) max 122.8 TB Rear bays: • Up to 2 x 2.5-inch SAS/SATA/NVMe (HDD/SSD) max 30.7 TB |
| Network Interface | 2 x 1 GbE LOM, 1 x OCP 3.0 |
| Power Supply | • 800 W Platinum AC/240 Mixed Mode • 1100 W Titanium AC/240 Mixed Mode • 1400 W Platinum AC/240 Mixed Mode |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Máy chủ Supermicro SYS-121C-TN10R
 |
|
| Form factor | 1U rackmount |
| Processor Support | • Dual sockets E (LGA-4677) 5th and 4th Gen Intel® Xeon® Scalable processors • Up to 32C/64T; Up to 82.5MB Cache per CPU |
| Memory Slots & Capacity | 16 DIMMs up to 4TB 3DS ECC DDR5-5600: RDIMM |
| GPU Support | • Up to 2 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | 10x 2.5″ hot-swap hybrid NVMe/SATA/SAS drive baysNetwork Interface |
| Network Interface | Dual AIOM (OCP 3.0) slots with NCSI for networking, 1 dedicated IPMI LAN |
| Power Supply | 860W redundant Platinum level 100-240Vac and 200-240 Vdc power supplies |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Máy chủ HPE DL360 Gen 11
|
|
| Form factor | 1U rackmount |
| Processor Support | • Dual sockets E (LGA-4677) 5th and 4th Gen Intel® Xeon® Scalable processors, up to 64 cores |
| Memory Slots & Capacity | • 32 DDR4 DIMM slots, supports 5600 MT/s HPE DDR5 Smart Memory, up to 8.0 TB |
| GPU Support | • Up to 4 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | 8 SFF Basic Carrier (BC) drive bays: − 24G x1 NVMe/SAS (TriMode) U.3 (PCIe4.0) or − 24G x4 NVMe/SAS (TriMode) U.3 (PCIe4.0) |
| Network Interface | Broadcom BCM57416 Ethernet 10Gb 2-port BASE-T OCP3 Adapter for HPE |
| Power Supply | • HPE 500W • HPE 800W • HPE 1600W |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Máy chủ Dell R660
|
|
| Form factor | 1U rackmount |
| Processor Support | Up to two 4th Generation Intel Xeon Scalable processors, with up to 56 cores and optional Intel® QuickAssist Technology |
| Memory Slots & Capacity | • 32 DDR5 DIMM slots, supports RDIMM 8 TB max, speeds up to 4800 MT/s • Supports registered ECC DDR5 DIMMs only |
| GPU Support | • Up to 2 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | Front bays: • Up to 10 x 2.5-inch, SAS/SATA/NVMe (HDD/SSD) max 153.6 TB • Up to 8 x 2.5-inch, SAS/SATA/NVMe, (HDD/SSD) max 122.88 TB Rear bays: • Up to 2 x 2.5-inch, SAS/SATA/NVMe, max 30.72 TB |
| Network Interface | 2 x 1 GbE LOM card (optional), 1 x OCP card 3.0 (optional) |
| Power Supply | • 1800W Titanium 200—240 VAC or 240 HVDC, hot swap with full redundant • 1400W Platinum 100—240 VAC or 240 HVDC, hot swap with full redundant • 1100W Titanium 100—240 VAC or 240 HVDC, hot swap with full redundant |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Máy chủ Supermicro AS-1114CS-TNR
 |
|
| Form factor | 1U rackmount |
| Processor Support | • Single AMD EPYC™ 7002/7003 Series Processor • Up to 64 Cores |
| Memory Slots & Capacity | 16 DIMMs up to 4TB 3DS ECC DDR4-3200: LRDIMM/RDIMM |
| GPU Support | • Up to 2 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | 10x 2.5″ hot-swap hybrid NVMe/SATA/SAS drive bays |
| Network Interface | Dual AIOM (OCP 3.0) slots with NCSI for networking, 1 dedicated IPMI LAN |
| Power Supply | 860W redundant Platinum level 100-240Vac and 200-240 Vdc power supplies |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Máy chủ Supermicro AS-1115CS-TNR
 |
|
| Form factor | 1U rackmount |
| Processor Support | • Single 4th Generation AMD EPYC™ 9004 Series Processors • Up to 128C/256T |
| Memory Slots & Capacity | 12 DIMMs Up to 3TB 4800MT/s ECC DDR5 RDIMM |
| GPU Support | • Up to 2 single-width GPU(s) • NVIDIA PCIe: L4 • NVIDIA PCIe: A2 |
| Storage | 10x 2.5″ hot-swap hybrid NVMe/SATA/SAS drive bays |
| Network Interface | Dual AIOM (OCP 3.0) slots with NCSI for networking, 1 dedicated IPMI LAN |
| Power Supply | 860W redundant Platinum level 100-240Vac and 200-240 Vdc power supplies |
| Frameworks Supported | • TensorFlow • PyTorch • TensorRT • Triton Inference Server • CUDA • RAPIDS • Clara Train • NVIDIA TAO • NVIDIA Riva • NVIDIA NGC |
Với những cấu hình máy chủ GPU dành cho Suy luận AI trên, Nhất Tiến Chung có thể hỗ trợ các doanh nghiệp xây dựng những hệ thống Suy luận AI tại trung tâm dữ liệu, tại các văn phòng chi nhánh hay tại biên để tối ưu hóa hiệu quả suy luận AI cho từng doanh nghiệp với những lựa chọn máy chủ linh hoạt và tối ưu chi phí.
Để biết thêm thông tin chi tiết, vui lòng liên hệ đội ngũ Nhất Tiến Chung để được tư vấn cụ thể hơn về hệ thống suy luận AI cho doanh nghiệp của bạn:
![]() Đội ngũ của Nhất Tiến Chung sẵn sàng tư vấn giải pháp, chạy BOM, báo giá mọi nhu cầu CNTT của Quý doanh nghiệp. Vui lòng liên hệ:
Đội ngũ của Nhất Tiến Chung sẵn sàng tư vấn giải pháp, chạy BOM, báo giá mọi nhu cầu CNTT của Quý doanh nghiệp. Vui lòng liên hệ:
Hotline: 1900 558879 #2
Email: presales@nhattienchung.vn
 supermicro/">Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
supermicro/">Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Với kinh nghiệm làm nhà phân phối chính thức máy chủ Supermicro từ năm 2005, Nhất Tiến Chung (NTC) tiên phong đem đến các giải pháp hạ tầng CNTT dựa trên danh mục phần cứng đa dạng và tối ưu chi phí đầu tư nhất từ Supermicro. Các máy chủ GPU và máy chủ lưu trữ hiệu năng cao chuyên dụng cho AI, Deep Learning, cấu hình tùy biến theo nhu cầu, được nhiều đối tác lựa chọn cho dự án của mình. Vui lòng liên hệ để được tư vấn giải pháp, hoàn toàn miễn phí.
Bạn muốn trở thành đối tác bán hàng Supermicro của NTC?
Bài viết liên quan
- Computex 2025: Supermicro phô diễn hạ tầng AI và Cloud
- Hơn 20 mẫu máy chủ Supermicro được tối ưu hóa cho dòng GPU mới NVIDIA RTX PRO 6000 Blackwell hiện đã sẵn sàng nhận đặt hàng
- Supermicro giới thiệu các máy chủ và giải pháp trung tâm dữ liệu mới nhất tại COMPUTEX 2025
- NVIDIA Dynamo – Thư viện nguồn mở tăng tốc và mở rộng các mô hình lý luận AI
- Đánh giá máy chủ 2U Supermicro SYS-222H-TN Intel Xeon 6
- Tìm hiểu tại sao triển khai on-premises có thể giúp vượt qua 6 thách thức quan trọng của AI