
Các bài test tiêu chuẩn ngành cho thấy các hệ thống dựa trên NVIDIA Hopper chạy phần mềm TensorRT-LLM sẽ cung cấp nền tảng mạnh mẽ nhất thế giới đối với Generative AI.
NVIDIA đã cung cấp nền tảng nhanh nhất thế giới trong các bài test tiêu chuẩn ngành về khả năng suy luận (inference) đối với Generative AI.
Trong các điểm chuẩn MLPerf mới nhất, NVIDIA TensorRT-LLM (phần mềm giúp tăng tốc và đơn giản hóa tác vụ suy luận phức tạp trên các mô hình LLM) đã tăng hiệu suất của những GPU kiến trúc NVIDIA Hopper trên GPT-J LLM gần gấp 3 lần so với kết quả của họ chỉ sáu tháng trước.
Tốc độ tăng tốc ấn tượng thể hiện sức mạnh của nền tảng chip, hệ thống và phần mềm toàn diện của NVIDIA trong việc xử lý các yêu cầu khắt khe khi chạy Generative AI.
Các công ty hàng đầu đang sử dụng TensorRT-LLM để tối ưu hóa mô hình của họ. Và NVIDIA NIM – một tập hợp các microservice suy luận bao gồm các engine suy luận như TensorRT-LLM — giúp các doanh nghiệp triển khai nền tảng suy luận của NVIDIA dễ dàng hơn bao giờ hết.
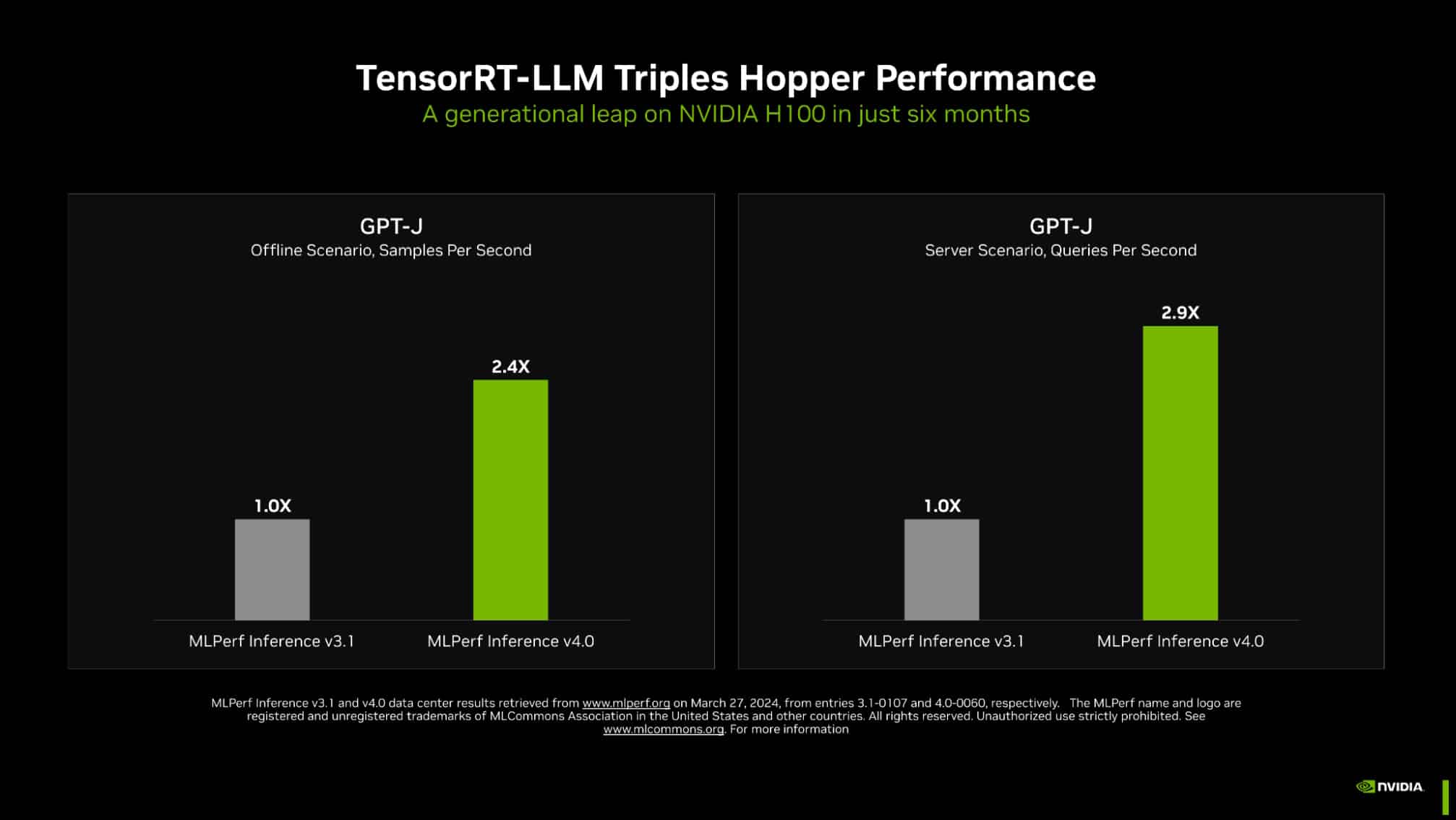
Nâng cao tiêu chuẩn về Generative AI
TensorRT-LLM chạy trên NVIDIA H200 Tensor Core – những GPU Hopper mới nhất, được tăng cường bộ nhớ, mang lại hiệu suất chạy suy luận nhanh nhất trong bài test lớn nhất của MLPerf về GenAI cho đến nay.
Điểm chuẩn mới sử dụng phiên bản lớn nhất của Llama 2, một mô hình ngôn ngữ lớn hiện đại chứa 70 tỷ tham số. Mô hình này lớn hơn gấp 10 lần so với GPT-J LLM lần đầu tiên được sử dụng trong các điểm chuẩn vào tháng 9.
GPU H200 được tăng cường bộ nhớ, trong lần ra mắt MLPerf, đã sử dụng TensorRT-LLM để tạo ra tới 31.000 tokens/giây, một kỷ lục trên điểm chuẩn Llama 2 của MLPerf.
Những kết quả của H200 bao gồm mức tăng lên tới 14% từ giải pháp tản nhiệt tùy chỉnh. Đó là một ví dụ về những cải tiến ngoài khả năng làm mát không khí tiêu chuẩn mà các nhà xây dựng hệ thống đang áp dụng cho thiết kế NVIDIA MGX của họ để đưa hiệu suất của GPU Hopper lên những tầm cao mới.
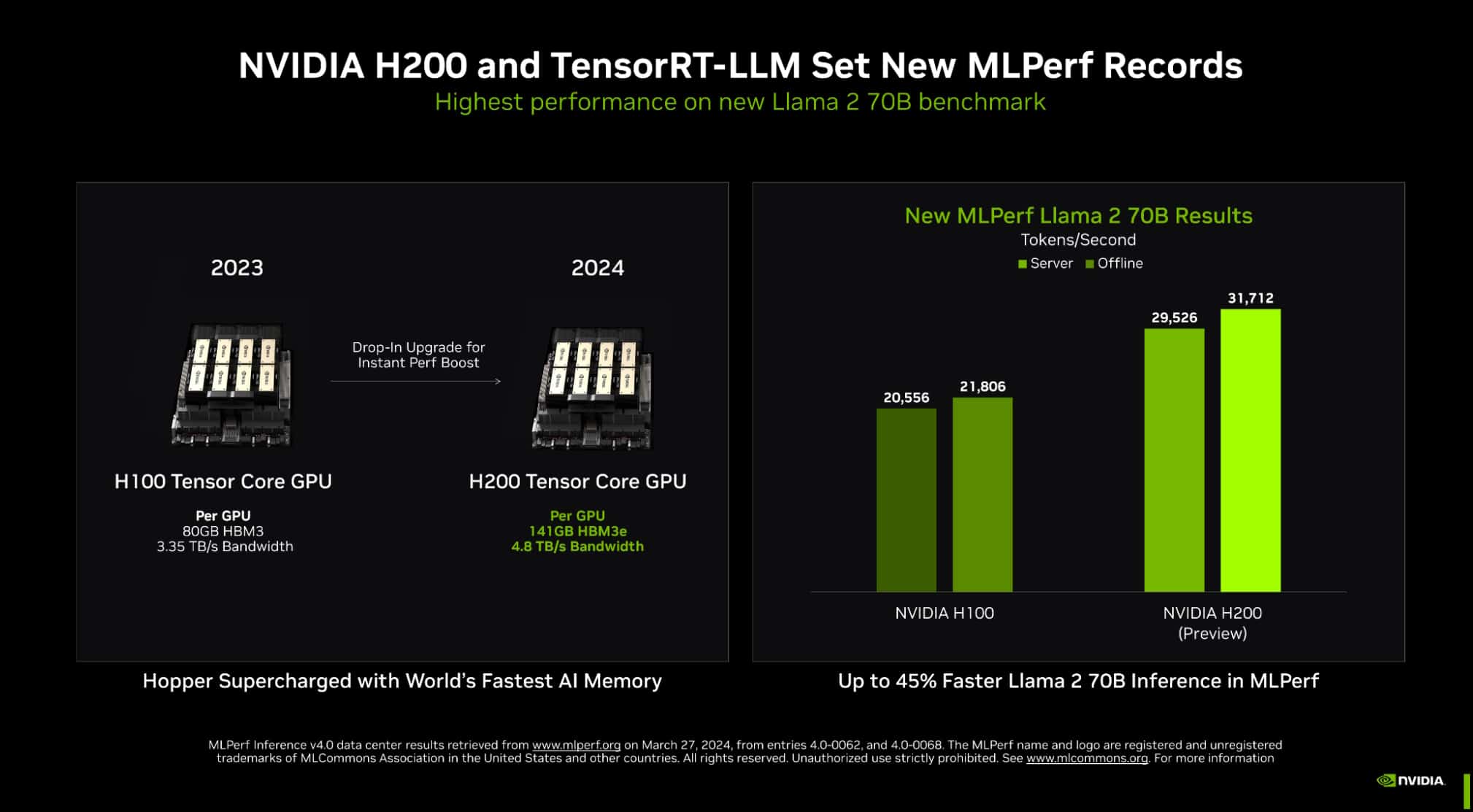
Tăng cường bộ nhớ cho NVIDIA Hopper GPU
NVIDIA đang chuẩn bị GPU H200 cho khách hàng hôm nay và giao hàng vào quý hai. Chúng sẽ sớm được cung cấp bởi gần 20 nhà xây dựng hệ thống và nhà cung cấp dịch vụ đám mây hàng đầu.
GPU H200 với 141GB HBM3e chạy ở tốc độ 4,8TB/s. Bộ nhớ tăng thêm 76% và nhanh hơn 43% so với GPU H100. Các bộ tăng tốc này cắm vào cùng bo mạch và hệ thống cũng như sử dụng phần mềm giống như GPU H100.
Với bộ nhớ HBM3e, một GPU H200 có thể chạy toàn bộ mô hình Llama 2 70B với thông lượng cao nhất, đơn giản hóa và tăng tốc độ suy luận.
GH200 có nhiều bộ nhớ hơn
Thậm chí còn có nhiều bộ nhớ hơn với 624GB fast memory, bao gồm 144GB HBM3e – được tích hợp trong NVIDIA GH200 Superchip, kết hợp trên một mô-đun GPU kiến trúc Hopper và CPU NVIDIA Grace tiết kiệm điện. NVIDIA GPU là những bộ tăng tốc đầu tiên sử dụng công nghệ bộ nhớ HBM3e.
Với băng thông bộ nhớ gần 5 TB/giây, GH200 Superchip mang lại hiệu năng vượt trội, cả trên các bài test MLPerf sử dụng nhiều bộ nhớ như các hệ thống khuyến nghị (recommender systems).
Càn quét mọi thử nghiệm MLPerf
Trên cơ sở per-accelerator, GPU Hopper đã vượt qua mọi bài kiểm tra về suy luận AI trong round mới nhất của điểm chuẩn ngành MLPerf.
Các điểm chuẩn bao gồm các tác vụ và kịch bản AI phổ biến nhất hiện nay, bao gồm GenAI, hệ thống khuyến nghị, xử lý ngôn ngữ tự nhiên, giọng nói và thị giác máy tính. NVIDIA là công ty duy nhất gửi những kết quả về mọi workload trong round mới nhất và mọi round kể từ khi điểm benchmark suy luận trung tâm dữ liệu của MLPerf bắt đầu vào tháng 10 năm 2020.
Hiệu suất tăng liên tục đồng nghĩa với việc giảm chi phí suy luận, một phần công việc hàng ngày chiếm tỷ trọng lớn và ngày càng tăng đối với hàng triệu GPU NVIDIA được triển khai trên toàn thế giới.
Thúc đẩy những gì có thể
Vượt qua ranh giới của những gì có thể, NVIDIA đã trình diễn ba kỹ thuật đổi mới trong một phần đặc biệt của điểm chuẩn được gọi là open division, được tạo ra để thử nghiệm các phương pháp AI tiên tiến.
Các kỹ sư của NVIDIA đã sử dụng một kỹ thuật gọi là structured sparsity – một cách giảm tính toán, lần đầu tiên được giới thiệu với những GPU NVIDIA A100 Tensor Core – để tăng tốc độ suy luận lên tới 33% với Llama 2.
Thử nghiệm open division thứ hai cho thấy tốc độ suy luận tăng lên tới 40% bằng cách sử dụng pruning, một cách đơn giản hóa mô hình AI – trong trường hợp này là một LLM – để tăng thông lượng suy luận.
Cuối cùng, một tính năng tối ưu hóa có tên DeepCache đã giảm bớt phép toán cần thiết để suy luận với mô hình Stable Diffusion XL, tăng tốc hiệu suất lên tới 74%.
Tất cả các kết quả này đều được chạy trên NVIDIA H100 GPU.
Nguồn đáng tin cậy cho người dùng
Các bài test của MLPerf rất minh bạch và khách quan nên người dùng có thể dựa vào những kết quả này để đưa ra quyết định mua hàng sáng suốt.
Các đối tác của NVIDIA tham gia MLPerf vì họ biết đây là công cụ có giá trị để khách hàng đánh giá các hệ thống và dịch vụ AI. Các đối tác gửi kết quả trên nền tảng NVIDIA AI trong round này bao gồm ASUS, Cisco, Dell Technologies, Fujitsu, GIGABYTE, Google, Hewlett Packard Enterprise, Lenovo, Microsoft Azure, Oracle, QCT, Supermicro, VMware (mới được Broadcom mua lại) và Wiwynn.
Tất cả phần mềm NVIDIA sử dụng trong các thử nghiệm đều có sẵn trong kho MLPerf. Những tối ưu hóa này liên tục được tổng hợp thành các container có sẵn trên NGC, trung tâm phần mềm của NVIDIA dành cho các ứng dụng GPU, cũng như NVIDIA AI Enterprise – một nền tảng an toàn, được hỗ trợ bao gồm các microservice suy luận NIM.
Điều quan trọng tiếp theo
Các trường hợp sử dụng, kích thước mô hình và bộ dữ liệu cho GenAI tiếp tục mở rộng. Đó là lý do MLPerf tiếp tục phát triển, bổ sung các thử nghiệm thực tế với các model phổ biến như Llama 2 70B và Stable Diffusion XL.
Theo kịp sự bùng nổ về kích thước mô hình LLM, người sáng lập và Giám đốc điều hành NVIDIA Jensen Huang đã công bố vào tuần trước tại GTC rằng những GPU kiến trúc NVIDIA Blackwell sẽ mang lại mức hiệu suất mới cần thiết cho các mô hình AI nhiều nghìn tỷ tham số.
Suy luận cho các mô hình ngôn ngữ lớn là điều khó khăn, đòi hỏi cả chuyên môn lẫn kiến trúc full-stack mà NVIDIA đã trình diễn trên MLPerf với GPU kiến trúc Hopper và TensorRT-LLM. Còn nhiều điều nữa sẽ đến.
NVIDIA Blog
Bài viết liên quan
- NVIDIA RTX PRO Blackwell Series: Bước nhảy vượt cấp về hiệu hăng GPU
- So sánh các thế hệ GPU Tensor Core đầu bảng của NVIDIA: B200, B100, H200, H100, A100
- Từ “Sáng tạo” Đến “Hành động”: Khám phá sự khác biệt giữa Generative AI và Agentic AI
- Mở rộng quy mô cho hạ tầng GenAI on-premise
- Hơn 20 mẫu máy chủ Supermicro được tối ưu hóa cho dòng GPU mới NVIDIA RTX PRO 6000 Blackwell hiện đã sẵn sàng nhận đặt hàng
- Khi AI và Đồ họa hội tụ: GPU NVIDIA Blackwell PRO tăng tốc cho các ứng dụng AI thế hệ mới