
NLP là gì và LLM là gì?
Xử lý ngôn ngữ tự nhiên (NLP) là một nhánh của Trí tuệ nhân tạo (AI) cho phép máy móc hiểu và diễn giải ngôn ngữ của con người. Những tiến bộ gần đây trong học sâu đã dẫn đến sự xuất hiện của các mô hình ngôn ngữ lớn (LLM) thể hiện khả năng hiểu ngôn ngữ tự nhiên một cách kỳ diệu đã cách mạng hóa thế giới công nghệ và có tác động đáng kể đến tương lai. Các doanh nghiệp và công ty khởi nghiệp đã chọn đào tạo các LLM này trên phần cứng chuyên dụng của NVIDIA như các hệ thống DGX.
Mô hình ngôn ngữ lớn (LLM) là một loại mô hình ngôn ngữ bao gồm một mạng thần kinh gồm các tham số được đào tạo trên một lượng lớn dữ liệu văn bản không được gắn nhãn. LLM nổi tiếng nhất là series GPT (Generative Pre-training Transformer) của OpenAI, được đào tạo trên hàng tỷ từ, nó chính là nền móng cho mô hình ChatGPT được biết đến nhiều nhất hiện nay. Các ứng dụng khác nhau sử dụng GPT làm nền tảng để xây dựng các chatbot, công cụ tóm tắt nội dung, v.v. Các LLM đã thể hiện hiệu suất vượt trội trong một loạt các nhiệm vụ NLP như dịch ngôn ngữ, trả lời câu hỏi và tạo văn bản. ChatGPT (được đào tạo ban đầu dựa trên GPT-3) và ChatGPT Plus (được đào tạo trên GPT-4) đã tạo ra những làn sóng lớn trong việc đưa AI đến với công chúng và người tiêu dùng.
Việc cho phép máy tính tương tác với thế giới vật chất của chúng ta đã trở thành hiện thực. LLM có nhiều ứng dụng trong các ngành khác nhau như chatbot được cá nhân hóa, tự động hóa dịch vụ khách hàng, phân tích tình cảm và tạo nội dung hoặc thậm chí là viết mã lập trình. Vậy tại sao các tổ chức quy mô lớn này lại chọn NVIDIA DGX? Sự khác biệt giữa DGX và GPU PCIe truyền thống là gì?
NVIDIA DGX/HGX và SXM form factor
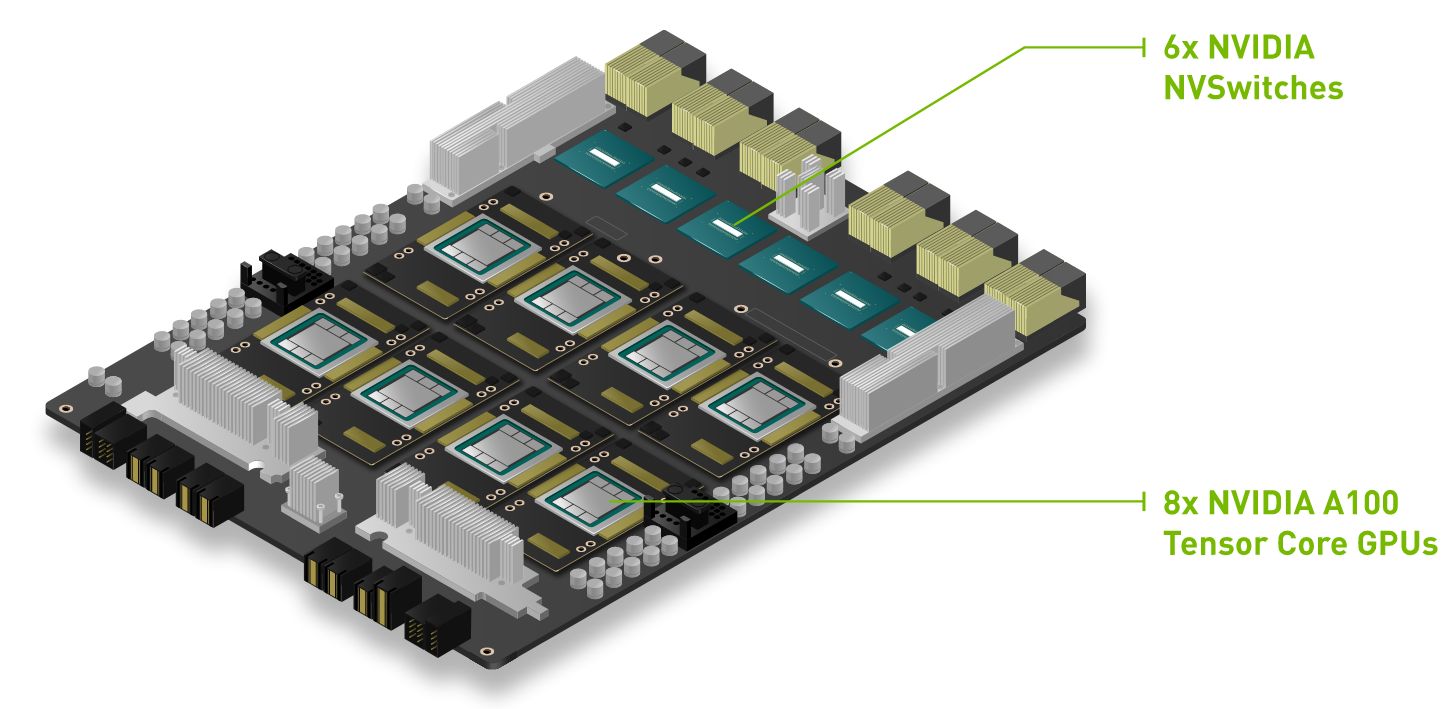
Kiến trúc SXM là một giải pháp socket băng thông cao để kết nối bộ tăng tốc NVIDIA Tensor Core với hệ thống DGX và HGX độc quyền của họ. Đối với mỗi thế hệ GPU NVIDIA Tensor Core (P100, V100, A100 và hiện tại là H100), các bo mạch HGX của hệ thống DGX đi kèm với socket SXM giúp nhận được băng thông cao, cung cấp nguồn điện, v.v. cho các thẻ con GPU phù hợp của chúng.
Các bo mạch hệ thống HGX chuyên dụng kết nối từng GPU trong số 8 GPU qua NVLink cho phép băng thông GPU-GPU cao. Khả năng của NVLink truyền dữ liệu giữa các GPU cực nhanh cho phép chúng hoạt động như một cỗ máy GPU duy nhất, trao đổi dữ liệu mà không cần chuyển qua PCIe hoặc cần giao tiếp với CPU. NVIDIA DGX H100 kết nối 8 SXM5 H100 với băng thông 900 GB/giây trên mỗi GPU thông qua 4 con chip NVLink Switch để có tổng băng thông hai chiều trên 7,2 TB/giây. Mỗi GPU H100 SXM cũng được kết nối với CPU thông qua PCI Express để mọi dữ liệu được tính toán bởi bất kỳ GPU nào trong số 8 GPU đều có thể được chuyển tiếp trở lại CPU. Chúng ta sẽ đi qua các sơ đồ kiến trúc ở phần sau.
NVIDIA H100 – PCIe form factor

Bạn không thể đạt được băng thông có hiệu suất tương tự khi kết nối các card H100 PCIe thông qua cầu nối NVLink (Bridge) mà H100 PCIe hỗ trợ. Các cầu nối này chỉ kết nối các GPU với nhau theo cặp để đạt tốc độ 600 GB/giây hai chiều, thay vì là 900 GB/giây đầy đủ trên bất kỳ GPU nào trong số 8 GPU trong hệ thống.
Nhưng cũng cần lưu ý, NVIDIA H100 PCIe bản thân nó là một GPU cực kỳ mạnh mẽ có thể được triển khai một cách dễ dàng. Chúng có thể dễ dàng được đưa vào trung tâm dữ liệu để nâng cấp hệ thống đáng kể với những thay đổi kiến trúc tối thiểu. Và với H100 NVL, đây là bản mở rộng của H100 PCIe bằng cách ghép đôi hai card với nhau để có tổng cộng 188GB bộ nhớ HBM3 với hiệu suất đã công bố tương đương với H100 SXM5.
→ Khám phá thêm chi tiết về GPU NVIDIA H100
Sự khác biệt giữa H100 SXM và PCIE
Trong ngành công nghiệp trung tâm dữ liệu và AI, NVIDIA DGX được coi là vàng theo đúng nghĩa đen. Máy chủ AI tốt nhất và mạnh nhất. Nổi bật nhất là việc OpenAI đào tạo ChatGPT trên hệ thống NVIDIA DGX của họ. Trên thực tế, OpenAI đã nhận tận tay hệ thống NVIDIA DGX-1 đầu tiên vào năm 2016.
Các tập đoàn lớn đổ xô đến NVIDIA DGX không phải vì nó hot mà vì khả năng mở rộng quy mô của nó. GPU SXM phù hợp hơn cho việc triển khai mở rộng với tám GPU H100 được kết nối hoàn toàn với công nghệ kết nối NVLink và NVSwitch. Trong DGX và HGX, cách 8 GPU SXM kết nối khác với PCIe; mỗi GPU được kết nối với 4 chip NVLink Switch về cơ bản cho phép tất cả các GPU hoạt động như một GPU lớn. Khả năng mở rộng này có thể mở rộng hơn nữa với Hệ thống NVIDIA NVLink Switch để triển khai và kết nối 256 DGX H100, nhằm tạo ra một nhà máy AI được GPU tăng tốc.
Mặt khác, H100 PCIe như có trong H100 NVL, chỉ có các cặp GPU được kết nối thông qua NVLink Bridge. GPU 1 chỉ được kết nối trực tiếp với GPU 2, GPU 3 chỉ được kết nối trực tiếp với GPU 4, v.v. GPU 1 và GPU 8 không được kết nối trực tiếp và do đó chỉ có thể giao tiếp dữ liệu qua các lane PCIe, phải sử dụng đến tài nguyên CPU. Bo mạch hệ thống NVIDIA DGX và HGX có tất cả các GPU SXM được kết nối với nhau thông qua chip NVLink Switch và do đó không bị chậm lại do các hạn chế của bus PCIe khi trao đổi dữ liệu giữa các GPU. Việc gửi dữ liệu trở lại CPU sẽ vẫn diễn ra trên các làn PCIe.
Bằng cách bỏ qua các lane PCI Express khi trao đổi dữ liệu giữa các GPU, GPU SXM H100 tốc độ cao có thể đạt được thông lượng tối đa mà ít bị chậm hơn so với phiên bản PCIe của nó, hoàn hảo để đào tạo các mô hình AI cực lớn có lượng dữ liệu khổng lồ được sử dụng để đào tạo. Vấn đề tiêu thụ năng lượng và form-factor độc quyền là sự đánh đổi để đạt được hiệu suất cao nhất, mà điều đó có thể kéo dài thời gian đào tạo và suy luận. Nhưng khi nói đến việc phát triển các mô hình ngôn ngữ lớn, truyền văn bản cho hàng triệu người đang sử dụng dịch vụ của bạn, hình thức tính toán cao nhất được mong muốn để đảm bảo tính ổn định, tính trôi chảy và độ tin cậy.
Bạn nên chọn gì? H100 SXM hay H100 PCIe?
Nó phụ thuộc vào trường hợp sử dụng của bạn. Mô hình ngôn ngữ lớn và AI sáng tạo (Generative AI) yêu cầu hiệu suất cao. Nhưng số lượng người dùng, khối lượng công việc và cường độ đào tạo đóng vai trò quan trọng trong việc chọn hệ thống phù hợp.
DGX và HGX của NVIDIA H100 là lựa chọn tốt nhất cho các tổ chức có thể tận dụng hiệu suất tính toán thô và không lãng phí bất kỳ thứ gì. Đào tạo, suy luận và vận hành liên tục có thể nhanh chóng giảm tổng chi phí sở hữu khi được sử dụng hết tiềm năng.
NVIDIA DGX có khả năng mở rộng tốt nhất và mang lại hiệu suất không thể sánh được với bất kỳ máy chủ nào khác ở cùng form-factor. Việc liên kết nhiều NVIDIA DGX H100 với Hệ thống NVSwitch có thể mở rộng nhiều DGX H100 thành một cụm SuperPod cho các mô hình cực lớn. NVIDIA DGX H100 có kích thước 8U với cặp vi xử lý 2x Intel Xeon 8480C cho tổng số 112 CPU core. NVIDIA DGX không thể tùy chỉnh và là khối xây dựng cho cơ sở hạ tầng điện toán AI quy mô hoàn chỉnh. Với NVIDIA DGX, khi đào tạo LLM của bạn có thể được mở rộng một cách dễ dàng. Nhiều DGX hơn đồng nghĩa với việc đào tạo nhanh hơn và triển khai mạnh mẽ hơn.
NVIDIA HGX cung cấp hiệu suất GPU tuyệt vời trong một hệ thống duy nhất mở ra tùy chọn để người dùng tùy chỉnh. Nền tảng HGX là nền tảng có thể tùy chỉnh được cung cấp bởi các đối tác chọn lọc (như Supermicro, ASUS,…) để mang lại hiệu suất mà khách hàng mong muốn – CPU, bộ nhớ, bộ lưu trữ, mạng – trong khi vẫn tận dụng cùng một bo mạch hệ thống NVIDIA H100 SXM5 8x (bao gồm tất cả các tính năng NVLink). Các hệ thống này có thể đáp ứng nhu cầu của trung tâm dữ liệu bằng cách chọn NIC của riêng bạn, chọn số Core mong muốn trong CPU và có thể là bộ nhớ bổ sung. NVIDIA HGX tương tự như DGX về khả năng tính toán trong khi vẫn hỗ trợ và phù hợp với nhu cầu đào tạo LLM quy mô lớn của bạn.
Phiên bản NVIDIA H100 PCIe dành cho những người làm việc với khối lượng công việc nhỏ hơn và muốn có sự linh hoạt tối đa trong việc quyết định số lượng GPU trong hệ thống của mình. Những GPU này vẫn tạo ra một “cú đấm thép” khi nói đến hiệu suất. Nó có con số hiệu suất thô thấp hơn một chút nhưng dễ dàng được đưa vào bất kỳ hạ tầng điện toán nào, khiến những chiếc GPU này trở nên hấp dẫn. H100 PCIe cũng được cung cấp ở các form máy chủ nhỏ hơn như 1U và 2U cho các trung tâm dữ liệu có GPU 2x hoặc 4x trong cấu hình CPU đơn hoặc kép để cung cấp sức mạnh tính toán cho việc phát triển các LLM nhỏ hơn. Tỷ lệ CPU trên GPU là 1 trên 1 sẽ tốt cho việc triển khai thiên về khả năng ảo hóa hơn trong suy luận, cũng như vô số ứng dụng khác nhau như phân tích dữ liệu,…
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale