
Trên thị trường, có các phiên bản khác nhau về tỷ lệ của bộ thu phát quang so với số lượng GPU và số liệu của các phiên bản khác nhau không nhất quán chủ yếu do số lượng mô-đun quang học cần thiết trong các kiến trúc mạng khác nhau là không giống nhau. Số lượng mô-đun quang thực tế được sử dụng chủ yếu phụ thuộc vào các khía cạnh sau.
1) Mô hình NIC
Chủ yếu bao gồm 6 loại card mạng, ConnectX-200 (100Gb/s, chủ yếu dùng với AXNUMX) chủ yếu dùng module quang là MMA1T00-HS (200G Infiniband HDR QSFP56 SR4 PAM4 850nm 100m) và ConnectX-7 (400Gb/s, chủ yếu dùng với H100).



2) Mô hình chuyển đổi
Mẫu bộ chuyển mạch ConnectX-8 800Gb/s thế hệ tiếp theo chủ yếu bao gồm hai loại bộ chuyển mạch, dòng QM9700 (OSFP 32 cổng (2*400Gb/s), với tổng cộng 64 kênh ở tốc độ truyền 400Gb/s, tổng cộng 51.2 tốc độ thông lượng Tb/giây) và sê-ri QM8700 (QSFP40 56 cổng, với tổng số 40 kênh ở tốc độ 200Gb/giây, tổng tốc độ thông lượng 16Tb/giây).


3) Số lượng đơn vị (Đơn vị có thể mở rộng SU)
Số lượng đơn vị ảnh hưởng đến mức kiến trúc chuyển mạch, chỉ có kiến trúc hai lớp được sử dụng khi số lượng đơn vị nhỏ và kiến trúc ba lớp được sử dụng khi số lượng đơn vị lớn.
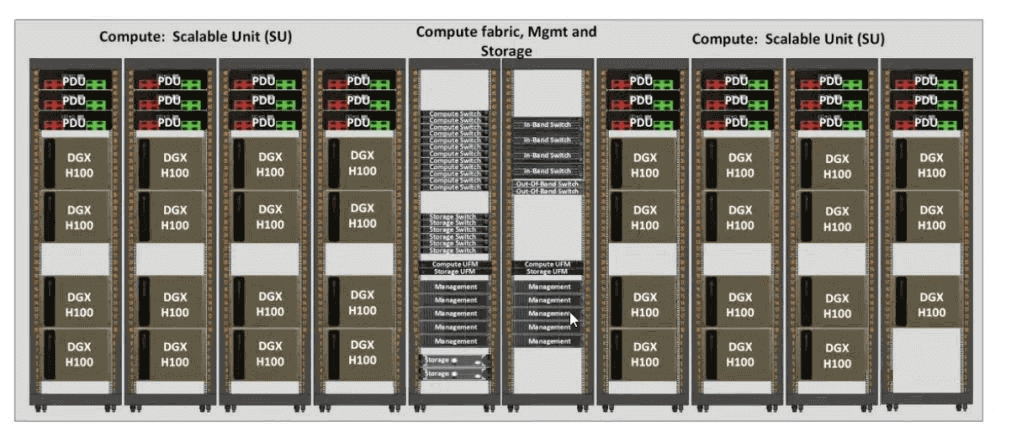
H100 SuperPOD: Mỗi đơn vị bao gồm 32 nút (máy chủ DGX H100) và hỗ trợ tối đa 4 đơn vị để tạo thành một cụm với kiến trúc chuyển mạch hai lớp.
A100 SuperPOD: mỗi đơn vị bao gồm 20 nút (máy chủ DGX A100), hỗ trợ tối đa 7 đơn vị để tạo thành một cụm và hơn 5 đơn vị yêu cầu kiến trúc chuyển mạch ba tầng.
Kết luận:
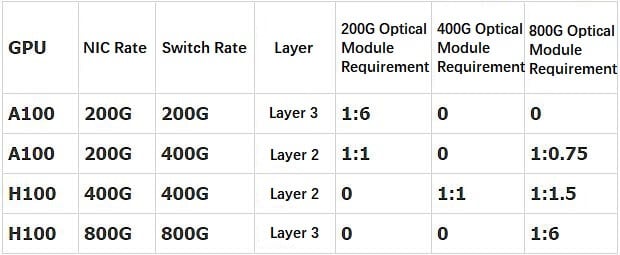
(1) Mạng ba lớp A100+ConnectX6+QM8700: tỷ lệ 1:6, tất cả đều có mô-đun quang 200G QSFP56
(2) Mạng hai lớp A100+ConnectX6+QM9700: bộ thu phát OSFP 1:0.75 800G + mô-đun quang 1:1 200G QSFP56
(3) Mạng hai lớp H100+ConnectX7+QM9700: Mô-đun quang OSFP 1:1.5 800G + Mô-đun quang OSFP 1:1 400G
(4) H100+ConnectX8 (chưa phát hành) + Mạng ba lớp QM9700: tỷ lệ 1:6, tất cả đều có OSFP 800G thu phát
Giả sử rằng 300,000 H100 + 900,000 A100 được xuất xưởng vào năm 2023, thì sẽ tạo ra tổng cộng 3.15 triệu 200G QSP56 + 300,000 400G OSFP + 787,500 800G OSFP, dẫn đến không gian thị trường AI gia tăng là 1.38 tỷ USD.
Giả sử 1.5 triệu chiếc H100 + 1.5 triệu chiếc A100 được xuất xưởng vào năm 2024, tổng cộng sẽ có 750,000 chiếc 200G QSFP56 + 750,000 400G OSFP + 6.75 triệu chiếc 800G OSFP được tạo ra, mang lại không gian thị trường gia tăng là 4.97 tỷ USD cho AI (xấp xỉ bằng tổng của quy mô thị trường mô-đun quang truyền qua kỹ thuật số năm 2021).
Dưới đây là quy trình đo lường chi tiết cho từng tình huống trên.
Tình huống 1: Mạng ba lớp A100+ConnectX6+QM8700.
A100 có tổng cộng tám giao diện điện toán, bốn giao diện bên trái và bốn giao diện bên phải trong hình. Hiện tại, các lô hàng A100 chủ yếu được ghép nối với ConnectX6 để giao tiếp bên ngoài, với tốc độ giao diện là 200Gb/s.
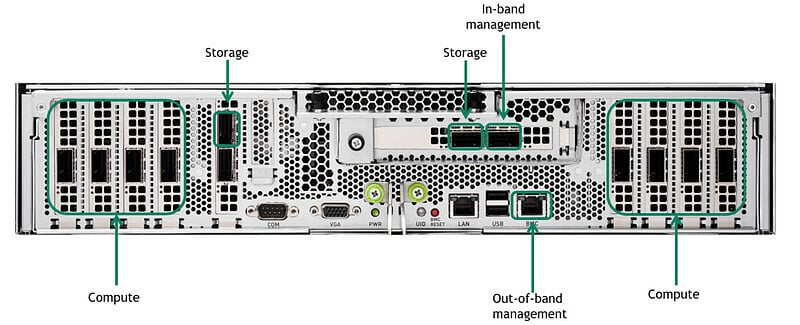
Trong kiến trúc tầng thứ nhất, mỗi nút (Node) có 8 giao diện (Port), mỗi nút được kết nối với 8 công tắc lá (Leaf) và cứ 20 nút tạo thành một đơn vị (SU), như vậy ở tầng thứ nhất có tổng cộng 8 *Cần có công tắc lá SU, cần có cáp (Cable) 8*SU*20 và cần có bộ thu phát quang 2*8*SU*20 200G.
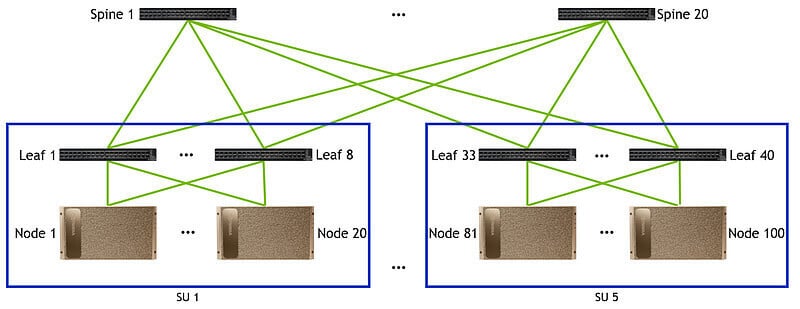
Trong kiến trúc Lớp 2, tốc độ đường lên bằng với tốc độ đường xuống do kiến trúc không chặn. Ở Lớp 1, tổng tốc độ truyền một chiều là 200G*số lượng cáp. Vì Lớp 2 cũng áp dụng tốc độ truyền 200G của một cáp duy nhất nên số lượng cáp ở Lớp 2 phải giống như ở Lớp 1, yêu cầu cáp 8*SU*20 (Cáp) và 2*8*SU*20 bộ thu phát 200G. Số lượng công tắc sườn núi (Cột sống) được yêu cầu là số lượng cáp chia cho số lượng công tắc lá, yêu cầu (8*SU*20)/(8*SU) công tắc sườn núi. Nhưng khi số lượng công tắc lá không đủ lớn, có thể tạo nhiều hơn hai kết nối giữa lá và sườn để tiết kiệm số lượng công tắc sườn (miễn là không vượt quá giới hạn 40 giao diện). Do đó, khi số lượng đơn vị tương ứng là 1/2/4/5, số lượng công tắc sườn cần thiết là 4/10/20/20 và số lượng mô-đun quang học cần thiết tương ứng là 320/640/1280/1600, số lượng công tắc sườn sẽ không tăng theo cùng một tỷ lệ, nhưng số lượng bộ thu phát sẽ tăng theo cùng một tỷ lệ.
Khi số lượng đơn vị đạt 7, lớp thứ ba của kiến trúc được yêu cầu, do kiến trúc không chặn nên số lượng cáp cần thiết cho lớp thứ ba của kiến trúc giống như số lượng của lớp thứ hai.
NVIDIA đề xuất cấu hình SuperPOD: NVIDIA đề xuất 7 đơn vị cho kết nối mạng, cần tăng kiến trúc Lớp 3 và tăng lõi chuyển mạch (Core), đa dạng về số lượng đơn vị khác nhau của từng lớp về số lượng chuyển mạch, số lượng cáp kết nối với hình minh họa.
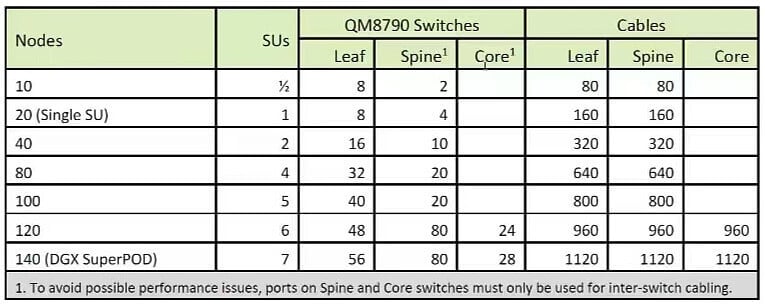
140 máy chủ, tổng cộng 140*8=1120 A100, tổng cộng 56+56+28=140 thiết bị chuyển mạch (QM8790), cáp 1120+1120+1120=3360, mô-đun quang 3360*2=6720 200G QSFP56, Ánh xạ giữa bộ thu phát A100 và 200G QSFP56 là 1120/6720=1:6.
Tình huống 2: Mạng lớp 100 A6+ConnectX9700+QM2
Hiện tại, giải pháp này không có sẵn trong cấu hình được đề xuất, nhưng trong tương lai, ngày càng nhiều A100 có thể chọn kết nối mạng QM9700, điều này sẽ làm giảm số lượng bộ thu phát quang được sử dụng, nhưng mang lại yêu cầu mô-đun quang 800G OSFP. Sự khác biệt lớn nhất là kết nối lớp đầu tiên được chuyển đổi từ 8 bên ngoài cáp 200G đến giao diện QSFP sang OSFP với 2 và 1 đến 4.
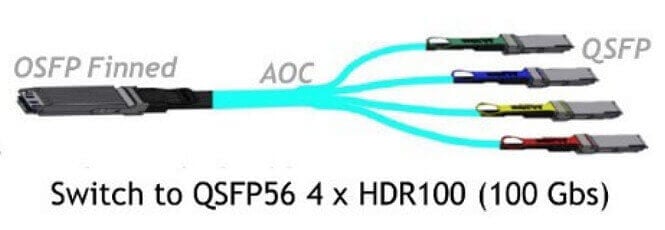
Ở lớp đầu tiên: đối với cụm 7 đơn vị, 140 máy chủ có 140 * 8 = 1120 giao diện, với tổng số 1120/4 = 280 cáp 1 kéo 4 được kết nối bên ngoài, dẫn đến 280 800G OSFP và 1120 200G OSFP56 quang yêu cầu mô-đun. Cần có tổng cộng 12 công tắc QM9700.
Ở Lớp 2: chỉ với các kết nối 800G, cần có 280*2=560 bộ thu phát OSFP 800G, yêu cầu 9 bộ chuyển mạch QM9700.
Do đó, 140 máy chủ và 1120 A100 yêu cầu 12+9=21 bộ chuyển mạch, 560+280=840 mô-đun quang 800G OSFP và 1120 bộ thu phát quang 200G QSFP56.
Ánh xạ giữa mô-đun quang A100 và 800G OSFP là 1120:840 =1:0.75 và ánh xạ giữa mô-đun quang A100 và 200G QSFP56 là 1:1
Tình huống 3: Mạng lớp 100 H7+ConnectX9700+QM2
Điểm đặc biệt của thiết kế H100 là mặc dù card mạng là tám Gpus với tám card mạng 400G nhưng giao diện được hợp nhất thành bốn giao diện 800G, điều này sẽ mang lại một số lượng lớn các yêu cầu mô-đun quang 800G OSFP.
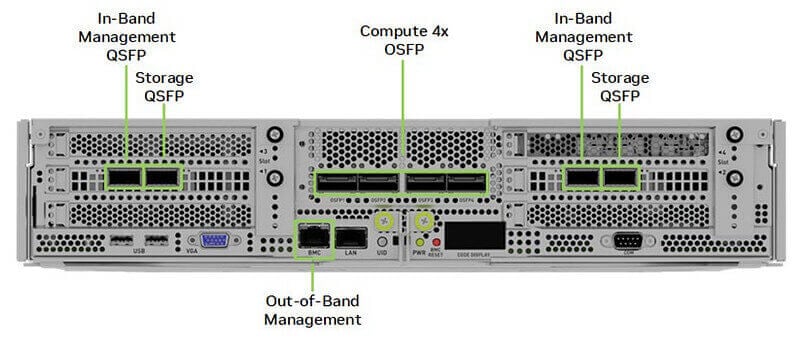
Ở Lớp 1, theo cấu hình khuyến nghị của NVIDIA, nên kết nối một mô-đun quang OSFP [2*400G] 800G với giao diện máy chủ: MMA4Z00-NS (800Gb/s Twin-port OSFP 2x400G SR8 PAM4 850nm 100m DOM Dual MPO-12 MMF) hoặc MMS4X00-NM ( 800Gb/s Twin-port OSFP 2x400G PAM4 1310nm 500m DOM Dual MTP/MPO-12 MMF), qua cổng đôi . ), hai sợi cáp quang (MPO) được kết nối qua cổng đôi và được cắm vào mỗi trong số hai công tắc.

Vì vậy, đối với lớp đầu tiên, một đơn vị chứa 32 máy chủ, một máy chủ được kết nối với 2*4=8 công tắc và SuperPOD bao gồm 4 đơn vị, yêu cầu tổng cộng 4*8=32 công tắc lá được kết nối ở lớp đầu tiên.
NVIDIA đề nghị bạn cần dành riêng một nút cho mục đích quản lý (UFM), do ảnh hưởng hạn chế đến việc sử dụng bộ thu phát quang nên chúng tôi chỉ thực hiện theo 4 đơn vị trong tổng số 128 máy chủ theo cách tính rút gọn.
Ở lớp đầu tiên, có tổng cộng 4*128 = 512 mô-đun quang 800G OSFP và 2*4*128 = 1024 mô-đun quang 400G OSFP: MMA4Z00-NS400 (400G OSFP SR4 PAM4 850nm 30m trên OM3/50m trên OM4 MTP/MPO -12) hoặc NVIDIA MMS4X00-NS400 (400G OSFP DR4 PAM4 1310nm MTP/MPO-12 500m).
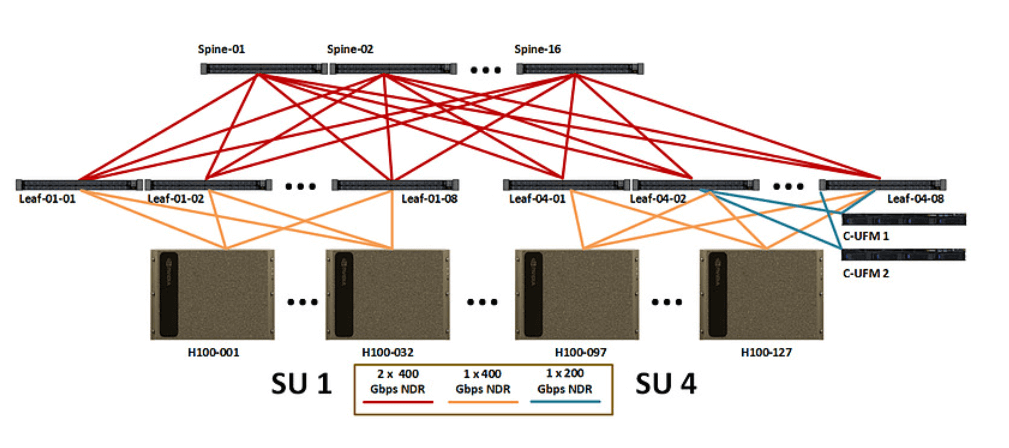
Ở Lớp 2, các công tắc được kết nối trực tiếp với nhau bằng các mô-đun quang 800G và một công tắc lá được kết nối hướng xuống với tốc độ một chiều là 32*400G. Để đảm bảo rằng tốc độ ngược dòng và hạ lưu giống nhau, do đó, kết nối hướng lên yêu cầu tốc độ một chiều 16 * 800G, yêu cầu 16 công tắc sườn, tổng cộng 4 * 8 * 16 * 2 = 1024 bộ thu phát quang 800G.
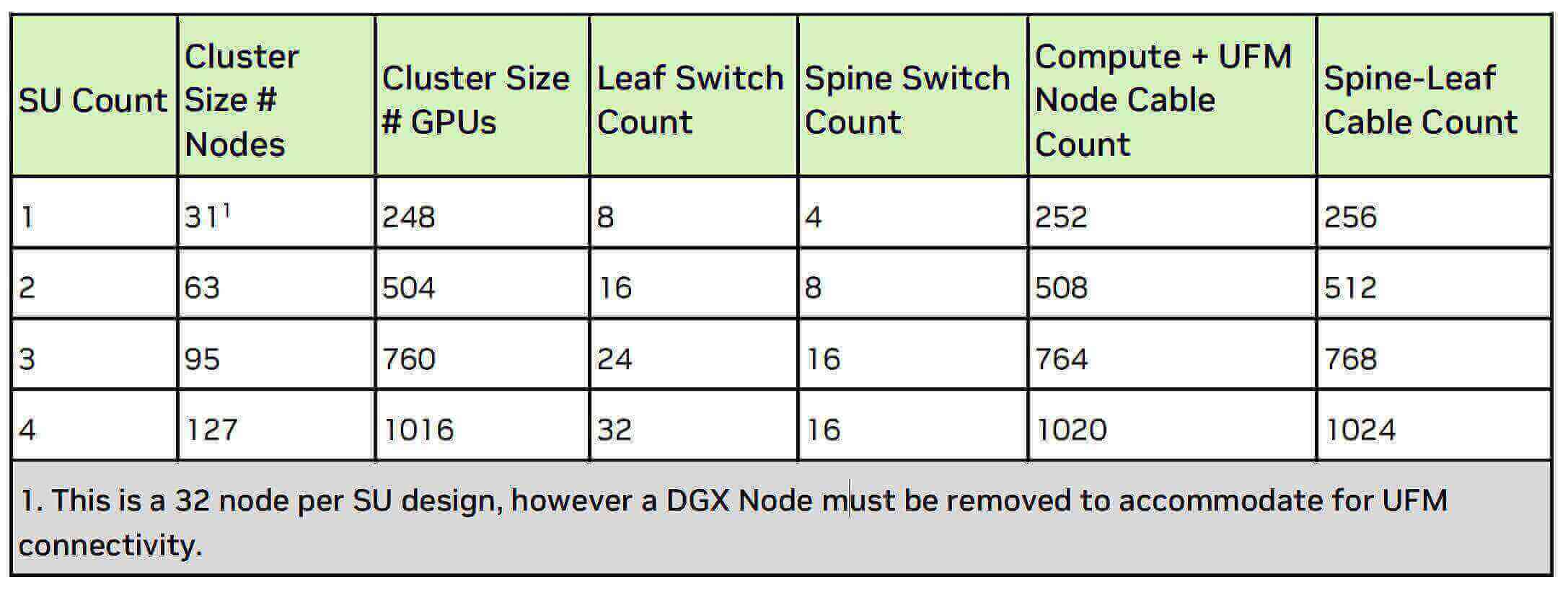
Do đó, theo kiến trúc này, hai lớp cần tổng cộng 512+1024=1536 mô-đun quang 800G OSFP và 1024 bộ thu phát quang 400G OSFP, tổng cộng là 4*32*8=1024 H100. Do đó, ánh xạ giữa GPU và mô-đun quang 800G OSFP là 1024/1536 → 1:1.5 và ánh xạ giữa GPU và mô-đun quang 400G OSFP là 1024/1024 → 1:1.
Tình huống 4: H100+ConnectX8 (chưa phát hành) + Mạng lớp 9700 QM3
Kịch bản này chưa được đưa ra, nhưng giả sử rằng sau khi H100 cũng được nâng cấp lên 800G NIC, các giao diện bên ngoài sẽ được nâng cấp từ 4 giao diện OSFP lên 8 giao diện OSFP. Kết nối giữa mỗi lớp được kết nối với 800G và toàn bộ kiến trúc mạng tương tự như kịch bản đầu tiên, chỉ có mô-đun quang 200G được thay thế bằng mô-đun quang 800G. Do đó, tỷ lệ GPU so với mô-đun quang trong kiến trúc này cũng là 1:6.
Chúng tôi sắp xếp bốn kịch bản trên vào bảng sau.
Giả định rằng 300,000 H100+ 900,000 A100 sẽ được xuất xưởng vào năm 2023, mang lại tổng nhu cầu 3.15 triệu 200G+ 300,000 400G+ 787,500 800G OSFP.
Giả định rằng 1.5 triệu H100+ 1.5 triệu A100 sẽ được xuất xưởng vào năm 2024, mang lại tổng nhu cầu 750,000 200G+ 750,000 400G+ 6.75 triệu 800G OSFP.
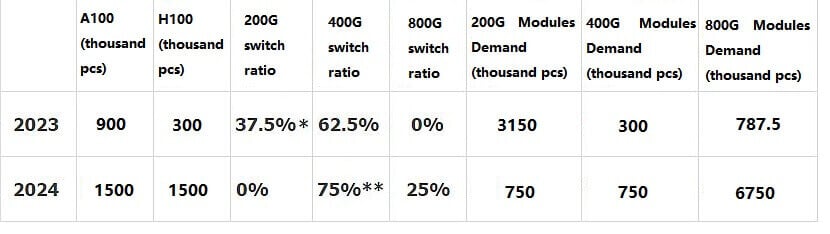
* Một nửa số A100 sử dụng công tắc 200G và một nửa sử dụng công tắc 400G.
** Một nửa số H100 sử dụng công tắc 400G và một nửa sử dụng công tắc 800G.
Các ước tính về số lượng A100 H100 ở trên chỉ là giả định và không thể hiện kỳ vọng trong tương lai.
Theo phép tính đơn giản về mức giá trung bình là 1 USD /GB vào năm 2023 và 0.85 USD /GB vào năm 2024, AI dự kiến sẽ mang lại 13.8/4.97 tỷ đô la Mỹ không gian thị trường gia tăng AI cho các bộ thu phát quang.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale