
STH – Hôm nay chúng tôi đang trình bày một bản dựng có lẽ là cấu hình học sâu được tìm kiếm nhiều nhất hiện nay. DeepLearning11 có 10 GPU NVIDIA GeForce GTX 1080 Ti 11GB, Mellanox Infiniband và phù hợp với một form factor 4.5U nhỏ gọn. Ngoài ra còn có một sự khác biệt quan trọng giữa hệ thống này và DeepLearning10, bản dựng 8x GTX 1080 Ti của chúng tôi. DeepLearning11 là một thiết kế đơn gốc đã trở nên phổ biến trong cộng đồng học tập sâu.
Tại STH, chúng tôi đang tạo ra các bản dựng tham khảo học tập sâu hơn không chỉ là các bài tập lý thuyết. Những máy này đang được sử dụng bởi nhóm của chúng tôi hoặc khách hàng của chúng tôi. Chúng tôi đã thực hiện một số bản dựng nhỏ hơn bao gồm DeepLearning01 và DeepLearning02 mà chúng tôi đã đăng. Trong khi các bản dựng đó tập trung vào phần giới thiệu, DeepLearning11 là một bản hoàn thiện hoàn toàn khác của series. Chúng tôi biết cấu hình này đã được sử dụng bởi một công ty chuyên về nghiên cứu học tập sâu hàng đầu trên thế giới.

DeepLearning11: Các thành phần
Nếu chúng tôi hỏi NVIDIA có lẽ đã được yêu cầu mua card Tesla hoặc Quadro. NVIDIA đặc biệt yêu cầu các máy chủ OEM không sử dụng card GTX của họ trong các máy chủ. Tất nhiên, điều này đơn giản có nghĩa là các đại lý lắp đặt card trước khi giao chúng cho khách hàng. Là một trang web đánh giá biên tập, chúng tôi có những hạn chế về ngân sách chặt chẽ nên chúng tôi đã mua 10 card NVIDIA GTX 1080 Ti. Mỗi NVIDIA GTX 1080 Ti có bộ nhớ 11GB (tăng từ 8GB trên GTX 1080) và 3584 nhân CUDA (tăng từ 2560 trên GTX 1080.) Sự khác biệt về giá để chúng tôi nâng cấp từ GTX 1080 là khoảng 1.500 USD. Chúng tôi đã mua card từ nhiều nhà cung cấp.

10 chiếc NVIDIA GTX 1080 TI FE Plus Mellanox hàng đầu
Hệ thống của chúng tôi là Supermicro SYS-4028GR-TR2 (SYS-4028GR-TRT2), một trong những hệ thống mật độ GPU cao chủ đạo trên thị trường. Các -TR2 rất có ý nghĩa vì nó là phiên bản gốc duy nhất của chassis và khác biệt so với hệ thống rễ kép -TR DeepLearning10.

DeepLearning11 GTX 1080 Ti Cùng CPU Kết thúc đối diện
Giống như bản dựng DeepLearning10, DeepLearning11 có phần nhô lên, nâng tổng kích thước hệ thống lên tới 4,5U. Bạn có thể đọc thêm về xu hướng này trong Avert Your Eyes của chúng tôi từ Máy chủ Xu hướng Humping đỉnh trong phần Trung tâm dữ liệu .

Supermicro 4028GR-TR / -TR2 Bump cho cáp điện GTX
Phần nhô lên này cho phép chúng tôi sử dụng card NVIDIA GeForce GTX trong hệ thống của chúng tôi với các cổng nguồn đối xứng hàng đầu của chúng.
Chúng tôi đang sử dụng bộ chuyển đổi VPI Mellanox ConnectX-3 Pro hỗ trợ cả 40GbE (mạng phòng thí nghiệm chính) cũng như Infiniband 56Gbps (mạng học sâu) Chúng tôi đã có card trên tay nhưng sử dụng FDR Infiniband với RDMA rất phổ biến với các máy này. Mạng 1GbE / 10GbE đơn giản là không thể cung cấp cho các máy này đủ nhanh. Chúng tôi đã cài đặt bộ chuyển đổi Intel Omni-Path trong phòng thí nghiệm, đây sẽ là kết cấu 100Gbps đầu tiên của chúng tôi trong phòng thí nghiệm.

Mellanox ConnectX-3 Pro
Về CPU và RAM, chúng tôi sử dụng 2 CPU Intel Xeon E5-2628L V4 và RAM DDR4 256GB ECC. Chúng tôi sẽ lưu ý rằng Intel Xeon E5-2650 V4 kép là chip phổ biến cho các hệ thống này. Chúng là bộ xử lý chính cấp thấp nhất hỗ trợ tốc độ QPI 9.6GT / s. Chúng tôi đang sử dụng CPU Intel Xeon E5-2628L V4 do thiết kế root đơn mang lại lợi ích quan trọng khác, không còn lưu lượng QPI liên GPU. Mặc dù chúng tôi đã nghe nói người ta có thể sử dụng một GPU duy nhất để cung cấp năng lượng cho hệ thống, nhưng chúng tôi vẫn đang sử dụng hai GPU để có thêm dung lượng RAM bằng cách sử dụng RDIMM 16GB rẻ tiền của chúng tôi. Các hệ thống này có thể mất tối đa 24x DDR4 LRDIMM cho dung lượng bộ nhớ lớn.
Chúng tôi sẽ sớm thực hiện một phần gốc, nhưng đối với những người học sâu sử dụng các khối xây dựng như NVIDIA nccl , một gốc PCIe phổ biến là rất quan trọng. Đó cũng là một lý do mà nhiều công cụ xây dựng học tập sâu sẽ không chuyển sang số lượng PCIe cao hơn nhưng độ trễ cao hơn / thiết kế hạn chế hơn như AMD EPYC với Infinity Fabric.
Chi phí hệ thống
Xét về sự cố chi phí, đây là những gì bạn có thể thấy nếu bạn đang sử dụng chip Intel E5-2650 V4:
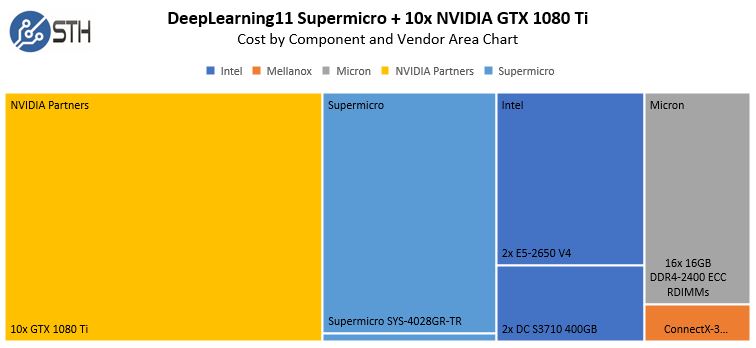
DeepLearning11 Chi phí gần đúng theo Thành phần và Khu vực nhà cung cấp Biểu đồ 1
Phần nổi bật ở đây là tổng chi phí khoảng 16.500 đô la có thời gian hoàn vốn dưới 90 ngày so với các loại đối tượng AWS g2.16xlarge. Chúng tôi sẽ bao gồm chi phí lưu trữ bên dưới để hiển thị cách so sánh trên cơ sở TCO.
So sánh ví dụ về GPU DeepLearning11 10x với DeepLearning10 với GPU 8 x của nó, bạn có thể thấy rằng việc giảm hiệu suất ~ 25% có chi phí tương đối ít về chi phí hệ thống:
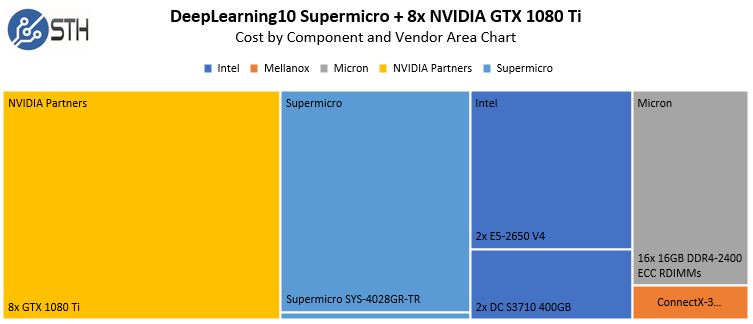
DeepLearning10 Chi phí gần đúng theo nhà cung cấp và biểu đồ khu vực thành phần
Như mọi người có thể tưởng tượng, việc thêm nhiều GPU có nghĩa là phần trên của phần còn lại của hệ thống được khấu hao trên nhiều GPU hơn. Kết quả là, nếu ứng dụng của bạn có quy mô tốt, hãy nhận GPU 10 lần cho mỗi hệ thống.
DeepLearning11: Cân nhắc về môi trường
Hệ thống của chúng tôi có bốn PSU, cần thiết cho cấu hình GPU 10 x. Để kiểm tra điều này, chúng tôi cho phép hệ thống chạy với một mô hình khổng lồ (đối với chúng tôi) trong vài ngày chỉ để xem có bao nhiêu năng lượng đang được sử dụng. Dưới đây là mức tiêu thụ năng lượng của máy chủ GPU 10 x trông như được đo bằng PDU chạy khối lượng công việc GAN hàng chục của chúng tôi:

DeepLearning11 Tiêu thụ năng lượng TF
Khoảng 2600W chắc chắn không tệ. Tùy thuộc vào nơi mô hình được đào tạo, chúng tôi đã thấy mức tiêu thụ năng lượng được duy trì cao hơn trong phạm vi 3.0-3.2kW trên máy này mà không chạm vào giới hạn năng lượng trên GPU.
Bạn sẽ nhận thấy có một đỉnh cực đại 5278W, trong một số lần bẻ khóa mật khẩu, nhiều hơn về điều này trong một đoạn STH trong tương lai. Đỉnh cao trong một vài tuần sử dụng các vấn đề và khuôn khổ khác nhau trong lĩnh vực học tập sâu chỉ dưới 4kW. Sử dụng 4kW làm cơ sở của chúng tôi, chúng tôi có thể tính toán chi phí colocation cho một máy như vậy một cách dễ dàng.
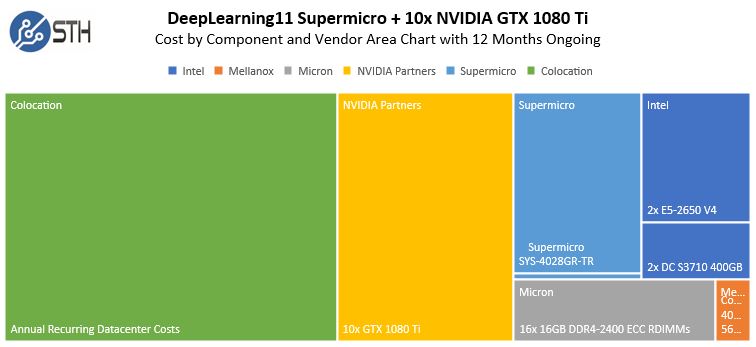
DeepLearning11 Chi phí theo Biểu đồ khu vực thành phần và nhà cung cấp với Colocation
Như bạn có thể thấy, sau 12 tháng, chi phí colocation bắt đầu giảm bớt chi phí phần cứng. Đối với những điều này, chúng tôi đang sử dụng chi phí colocation phòng thí nghiệm trung tâm dữ liệu thực tế của chúng tôi. Nếu bạn muốn xây dựng một mô hình chi phí tương tự, chúng tôi sẵn lòng cung cấp thông tin liên hệ với những người chúng tôi sử dụng để bạn có thể sao chép những điều trên. Đây không phải là những con số lý thuyết, chúng tôi thực sự chi khoảng $ 1k / tháng để chạy hệ thống này trong trung tâm dữ liệu.
So sánh ở trên với DeepLearning10 với GPU 8 x và bạn có thể thấy tác động của việc thêm ~ 500W tính toán bổ sung:
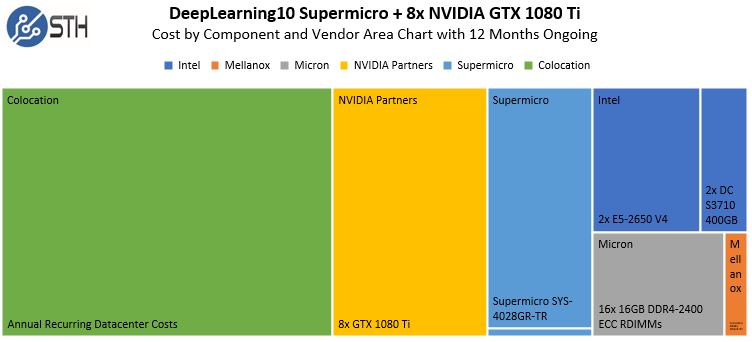
DeepLearning10 Chi phí gần đúng theo nhà cung cấp và khu vực thành phần Biểu đồ 12 tháng đang diễn ra
Thêm GPU bổ sung thêm chi phí vận hành phù hợp với chi phí hệ thống so với DeepLearning10. Bước sang những năm tiếp theo, chi phí colocation sẽ vượt xa chi phí phần cứng.
DeepLearning11: Tác động hiệu suất
Chúng tôi muốn chỉ cho bạn thấy một chút về hiệu suất mà chúng tôi đạt được từ hệ thống mới này. Có một sự khác biệt lớn giữa hệ thống $ 1600 và hệ thống $ 16.000 + vì vậy chúng tôi hy vọng tác động sẽ lớn tương tự. Chúng tôi đã lấy trường hợp thử nghiệm đào tạo hình ảnh Tensorflow Generative Adversarial Network (GAN) mẫu của chúng tôi và chạy nó trên các thẻ đơn sau đó bước lên hệ thống GPU 10 x. Chúng tôi bày tỏ kết quả của chúng tôi về các chu kỳ đào tạo mỗi ngày.
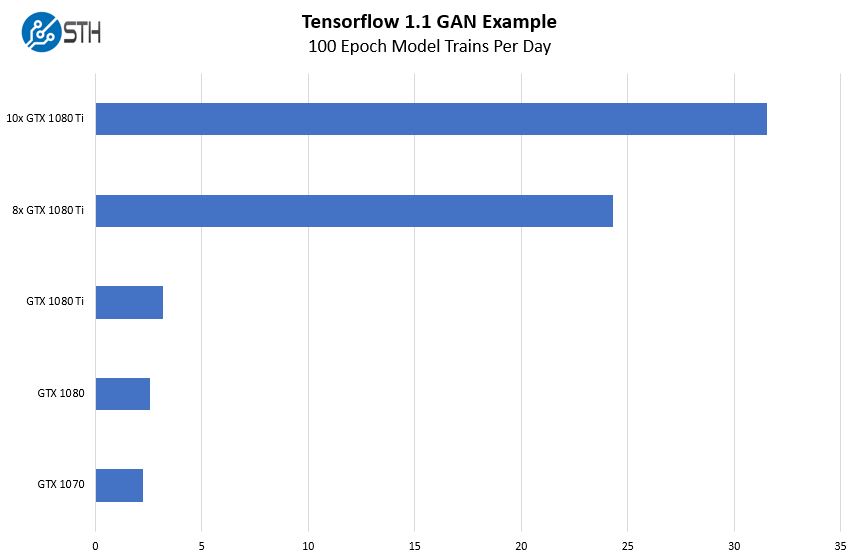
Ví dụ đào tạo GAN DeepLearning11 Tensorflow
Đây là một ví dụ tuyệt vời về cách thêm $ 1400 trở lên vào giá mua của hệ thống mang lại kết quả rõ ràng. Trong khi một NVIDIA GeForce GTX 1080 Ti duy nhất cho phép chúng tôi đào tạo mô hình một lần trong tám giờ, một hộp GPU 10 x cho phép chúng tôi luyện tập trên nhịp lớn hơn hàng giờ. Nếu bạn muốn đạt được tiến bộ trong một ngày làm việc, một hộp lớn hoặc một cụm các hộp lớn sẽ giúp ích.
Lời cuối cùng
Như mọi người có thể tưởng tượng, DeepLearning10 và DeepLearning11 sử dụng rất nhiều sức mạnh. Chỉ riêng hai máy chủ đó là trung bình trên 5kW công suất phù hợp với mức tăng đột biến cao hơn nhiều. Điều đó có ý nghĩa lớn đối với việc lưu trữ khi “khối u” cộng thêm 0,5 RU không đáng kể trong nhiều rack. Hầu hết các rack colocation không thể cung cấp 25kW + năng lượng và làm mát trên mỗi rack để lấp đầy chúng với các máy chủ GPU. Chúng ta thường thấy những máy chủ này được lưu trữ với 2 máy tính GPU trên mỗi rack 30A 208V, vì vậy vấn đề lắp đặt và chỗ trống trở nên quan trọng.
Cuối cùng, chúng tôi muốn có một hệ thống gốc đáng có trong phòng lab và chúng tôi đạt điều đó với DeepLearning11 cùng với GPU NVIDIA GTX 1080 Ti 11GB của nó. Vì chúng tôi chủ trương tăng kích thước GPU trước, sau đó là số GPU trên mỗi máy, sau đó đến nhiều máy, DeepLearning11 vừa là một máy đơn hàng đầu tuyệt vời nhưng cũng là một nền tảng để nhân rộng ra nhiều máy dựa trên thiết kế. Có một số tính năng như GPUDirect sử dụng RDMA rất tốt trên nền tảng này với giả định phần mềm và phần cứng của bạn có thể hỗ trợ chúng. Chúng tôi thực tế bị giới hạn bởi ngân sách vì vậy chúng tôi đã nhận được những card tốt nhất có thể, GTX 1080 Ti.
 Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Với kinh nghiệm làm nhà phân phối chính thức máy chủ Supermicro từ năm 2005, Nhất Tiến Chung (NTC) tiên phong đem đến các giải pháp hạ tầng CNTT dựa trên danh mục phần cứng đa dạng và tối ưu chi phí đầu tư nhất từ Supermicro. Các máy chủ GPU và máy chủ lưu trữ hiệu năng cao chuyên dụng cho AI, Deep Learning, cấu hình tùy biến theo nhu cầu, được nhiều đối tác lựa chọn cho dự án của mình. Vui lòng liên hệ để được tư vấn giải pháp, hoàn toàn miễn phí.
Bạn muốn trở thành đối tác bán hàng Supermicro của NTC?
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- Thử so sánh máy tính DGX Spark và một PC cấu hình cao với GPU RTX 5080
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- NVIDIA hiện đang cung cấp những dòng GPU nào?