
Các bộ tăng tốc và kết nối mạng mới nhất cải thiện hiệu suất cho các mô phỏng nâng cao, AI, điện toán lượng tử, phân tích dữ liệu…
Điện toán lượng tử, Nghiên cứu chế tạo thuốc, Năng lượng dung hợp, Điện toán khoa học và Mô phỏng dựa trên vật lý sẵn sàng thực hiện những bước tiến khổng lồ trên các lĩnh vực mang lại lợi ích cho nhân loại khi những tiến bộ trong điện toán tăng tốc và AI thúc đẩy những đột phá lớn tiếp theo của thế giới.
NVIDIA đã công bố tại GTC vào tháng 3 nền tảng NVIDIA Blackwell, nền tảng này hứa hẹn thúc đẩy AI tạo sinh trên các mô hình ngôn ngữ lớn (LLM) nghìn tỷ tham số với chi phí và mức tiêu thụ năng lượng thấp hơn tới 25 lần so với kiến trúc NVIDIA Hopper.
Blackwell có tác động mạnh mẽ đến tải xử lý AI và khả năng công nghệ của nó cũng có thể giúp mang lại những khám phá trên tất cả các loại ứng dụng điện toán khoa học, bao gồm cả mô phỏng số truyền thống.
Bằng cách giảm chi phí năng lượng, điện toán tăng tốc và AI thúc đẩy điện toán bền vững . Nhiều ứng dụng điện toán khoa học đã được hưởng lợi. Thời tiết có thể được mô phỏng với chi phí thấp hơn 200 lần và tiêu thụ ít năng lượng hơn 300 lần, trong khi mô phỏng phiên bản số hóa có chi phí thấp hơn 65 lần và mức tiêu thụ năng lượng ít hơn 58 lần so với các hệ thống dựa trên CPU truyền thống và các hệ thống khác.
Tăng tốc các mô phỏng tính toán khoa học với Blackwell
Điện toán khoa học và mô phỏng dựa trên vật lý thường dựa vào những gì được gọi là định dạng có độ chính xác kép hoặc FP64 (dấu phẩy động) để giải quyết vấn đề. GPU Blackwell mang lại hiệu suất FP64 và FP32 FMA (kết hợp nhân-cộng) cao hơn 30% so với Hopper.
Mô phỏng dựa trên vật lý rất quan trọng đối với việc thiết kế và phát triển sản phẩm. Từ máy bay và xe lửa đến cầu đường giao thông, chip silicon và dược phẩm – việc thử nghiệm và cải tiến sản phẩm trong mô phỏng giúp các nhà nghiên cứu và nhà phát triển tiết kiệm hàng tỷ đô la.
Ngày nay, các mạch tích hợp dành riêng cho ứng dụng (ASIC) được thiết kế hầu như chỉ có trên CPU trong một quy trình làm việc dài và phức tạp, bao gồm phân tích tương tự để xác định điện áp và dòng điện.
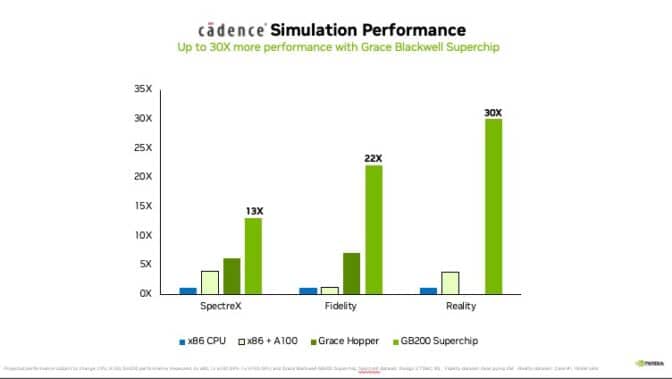
Nhưng điều đó đang thay đổi. Trình mô phỏng Cadence SpectreX là một ví dụ về bộ giải thiết kế mạch tương tự. Mô phỏng mạch SpectreX được dự đoán sẽ chạy nhanh hơn 13 lần trên Siêu chip GB200 Grace Blackwell — kết nối GPU Blackwell và CPU Grace — so với trên CPU truyền thống.
Ngoài ra, động lực học chất lỏng tính toán được tăng tốc bằng GPU, hay CFD, đã trở thành một công cụ quan trọng. Các kỹ sư và nhà thiết kế thiết bị sử dụng nó để dự đoán hành vi của thiết kế. Cadence Fidelity chạy các mô phỏng CFD được dự kiến sẽ chạy nhanh hơn gấp 22 lần trên hệ thống GB200 so với trên các hệ thống chạy bằng CPU truyền thống. Với khả năng mở rộng song song và bộ nhớ 30TB trên mỗi rack GB200 NVL72, bạn có thể ghi lại các chi tiết luồng nhiều hơn bao giờ hết.
Trong một ứng dụng khác, phần mềm phiên bản số hóa của Cadence Reality có thể được sử dụng để tạo bản sao ảo của trung tâm dữ liệu vật lý, bao gồm tất cả các thành phần của nó – máy chủ, hệ thống làm mát và nguồn điện. Mô hình ảo như vậy cho phép các kỹ sư thử nghiệm các cấu hình và kịch bản khác nhau trước khi triển khai chúng trong thế giới thực, tiết kiệm thời gian và chi phí.
Phép thuật của Cadence Reality xảy ra từ các thuật toán dựa trên vật lý có thể mô phỏng mức độ ảnh hưởng của nhiệt, luồng không khí và việc sử dụng năng lượng đến các trung tâm dữ liệu. Điều này giúp các kỹ sư và nhà điều hành trung tâm dữ liệu quản lý năng lực hiệu quả hơn, dự đoán các vấn đề vận hành tiềm ẩn và đưa ra quyết định sáng suốt để tối ưu hóa cách bố trí và vận hành trung tâm dữ liệu nhằm nâng cao hiệu quả và sử dụng năng lực. Với GPU Blackwell, những mô phỏng này dự kiến sẽ chạy nhanh hơn tới 30 lần so với CPU, mang lại các mốc thời gian được tăng tốc và hiệu quả sử dụng năng lượng cao hơn.
AI cho điện toán khoa học
Các bộ tăng tốc và kết nối mạng Blackwell mới sẽ mang lại bước nhảy vọt về hiệu suất cho mô phỏng nâng cao.
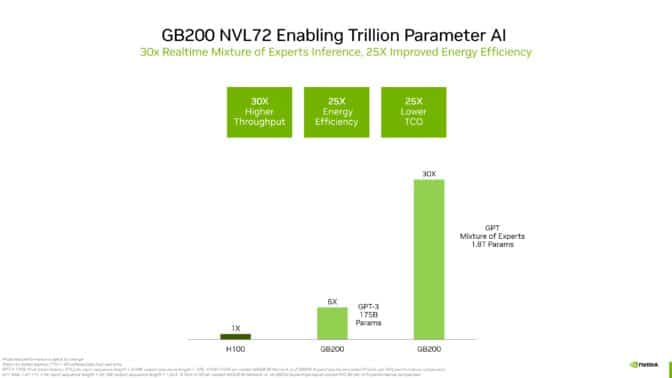
NVIDIA GB200 khởi đầu một kỷ nguyên mới cho điện toán hiệu năng cao (HPC). Kiến trúc của nó có transformer engine thế hệ thứ hai được tối ưu hóa để tăng tốc tải xử lý suy luận cho LLM.
Điều này giúp tăng tốc gấp 30 lần đối với các ứng dụng sử dụng nhiều tài nguyên như mô hình GPT-MoE (hỗn hợp transformer engine được huấn luyện trước tổng quát) 1,8 nghìn tỷ thông số so với thế hệ H100, mở ra những khả năng mới cho HPC. Bằng cách cho phép LLM xử lý và giải mã lượng lớn dữ liệu khoa học, các ứng dụng HPC có thể sớm đạt được những hiểu biết có giá trị giúp tăng tốc khám phá khoa học.
Phòng thí nghiệm quốc gia Sandia đang xây dựng một LLM copilot để lập trình song song. AI truyền thống có thể tạo mã điện toán nối tiếp cơ bản một cách hiệu quả, nhưng khi nói đến mã điện toán song song cho các ứng dụng HPC, LLM có thể gặp khó khăn. Các nhà nghiên cứu của Sandia đang trực tiếp giải quyết vấn đề này bằng một dự án đầy tham vọng – tự động tạo mã song song trong Kokkos, một ngôn ngữ lập trình chuyên dụng được thiết kế bởi nhiều phòng thí nghiệm quốc gia để chạy các tác vụ trên hàng chục nghìn bộ xử lý trong các siêu máy tính mạnh nhất thế giới.
Sandia đang sử dụng một kỹ thuật AI được gọi là thế hệ tăng cường truy xuất hoặc RAG, kết hợp khả năng truy xuất thông tin với các mô hình tạo ngôn ngữ. Nhóm đang tạo cơ sở dữ liệu Kokkos và tích hợp nó với các mô hình AI bằng RAG.
Kết quả ban đầu đầy hứa hẹn. Các phương pháp tiếp cận RAG khác nhau từ Sandia đã chứng minh mã Kokkos được tạo tự động cho các ứng dụng điện toán song song. Bằng cách vượt qua các rào cản trong việc tạo mã song song dựa trên AI, Sandia đặt mục tiêu mở ra các khả năng mới trong HPC trên các cơ sở siêu máy tính hàng đầu trên toàn thế giới. Các ví dụ khác bao gồm nghiên cứu năng lượng tái tạo, khoa học khí hậu và khám phá thuốc.
Thúc đẩy những tiến bộ của điện toán lượng tử
Điện toán lượng tử mở ra chuyến du hành bằng cỗ máy thời gian cho năng lượng nhiệt hạch, nghiên cứu khí hậu, khám phá thuốc và nhiều lĩnh vực khác. Vì vậy, các nhà nghiên cứu đang nỗ lực mô phỏng các máy tính lượng tử trong tương lai trên các hệ thống và phần mềm dựa trên GPU NVIDIA để phát triển và thử nghiệm các thuật toán lượng tử nhanh hơn bao giờ hết.
Nền tảng NVIDIA CUDA-Q cho phép vừa mô phỏng máy tính lượng tử vừa phát triển ứng dụng lai với mô hình lập trình thống nhất cho CPU, GPU và QPU (đơn vị xử lý lượng tử) hoạt động cùng nhau.
CUDA-Q đang tăng tốc mô phỏng trong quy trình hóa học cho BASF, vật lý hạt nhân và năng lượng cao cho Stony Brook và hóa học lượng tử cho NERSC.
Kiến trúc NVIDIA Blackwell sẽ giúp thúc đẩy mô phỏng lượng tử lên tầm cao mới. Việc sử dụng công nghệ kết nối đa nút NVIDIA NVLink mới nhất giúp truyền dữ liệu nhanh hơn nhằm tăng tốc lợi ích cho mô phỏng lượng tử.
Tăng tốc phân tích dữ liệu cho những đột phá khoa học
Xử lý dữ liệu bằng RAPIDS là phổ biến cho tính toán khoa học. Blackwell giới thiệu một công cụ giải nén phần cứng để giải nén dữ liệu nén và tăng tốc độ phân tích trong RAPIDS.
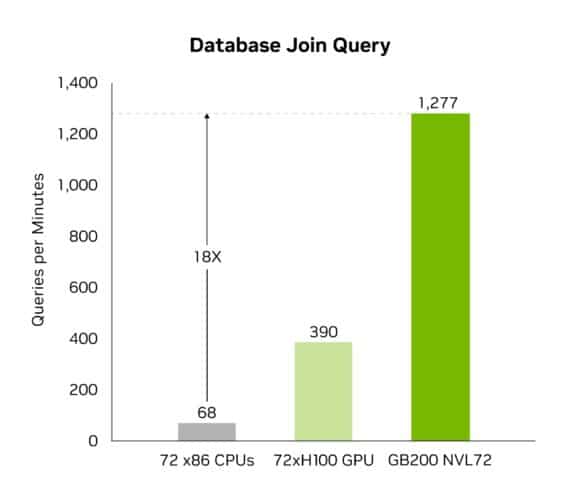
Công cụ giải nén cung cấp các cải tiến hiệu suất lên tới 800GB/giây và cho phép Grace Blackwell hoạt động nhanh hơn 18 lần so với CPU — trên Sapphire Rapids — và nhanh hơn 6 lần so với GPU NVIDIA H100 Tensor Core cho điểm benchmark truy vấn.
Tăng tốc truyền dữ liệu với băng thông bộ nhớ cao 8TB/giây và kết nối NVLink Chip-to-Chip (C2C) tốc độ cao của CPU Grace, công cụ này tăng tốc toàn bộ quá trình truy vấn cơ sở dữ liệu. Mang lại hiệu suất vượt trội trong các ứng dụng khoa học dữ liệu và phân tích dữ liệu, Blackwell tăng tốc độ hiểu biết về dữ liệu và giảm chi phí.
Thúc đẩy hiệu suất cực cao cho tính toán khoa học với mạng NVIDIA
Nền tảng mạng NVIDIA Quantum-X800 InfiniBand cung cấp thông lượng cao nhất cho hạ tầng máy tính khoa học.
Nó bao gồm các bộ chuyển mạch NVIDIA Quantum Q3400 và Q3200 cũng như NVIDIA ConnectX-8 SuperNIC, cùng nhau đạt được băng thông gấp đôi thế hệ trước. Nền tảng Q3400 cung cấp dung lượng băng thông cao hơn 5 lần và tốc độ điện toán trong mạng 14,4 Tflops với giao thức tổng hợp và giảm thiểu phân cấp có thể mở rộng của NVIDIA (SHARPv4), mang lại mức tăng gấp 9 lần so với thế hệ trước.
Bước nhảy vọt về hiệu suất và hiệu quả sử dụng năng lượng giúp giảm đáng kể thời gian hoàn thành tải xử lý và mức tiêu thụ năng lượng cho tính toán khoa học.
Tìm hiểu thêm về NVIDIA Blackwell.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi là đối tác NPN cấp Elite (2022) chính thức của NVIDIA cho các hệ thống DGX (DGX A100, DGX Station A100) và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi là đối tác NPN cấp Elite (2022) chính thức của NVIDIA cho các hệ thống DGX (DGX A100, DGX Station A100) và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- So sánh các GPU Tensor Core của NVIDIA: B200, B100, H200, H100, A100
- NVIDIA giới thiệu nền tảng microservice Metropolis để chạy ứng dụng Edge AI trên Jetson
- Phát triển ứng dụng AI tại biên với NVIDIA Jetson AGX Orin & Developer Kit
- Giải mã hiệu suất AI trên PC và Workstation RTX AI
- Nvidia “thần tốc” công bố thế hệ chip AI tiếp theo
- Bài phát biểu mở màn của NVIDIA tại Computex 2024 có gì?