
Với sự thay đổi nhanh chóng của công nghệ, các tổ chức trong hầu hết mọi ngành công nghiệp đều nhận ra rằng dữ liệu mang lại giá trị to lớn. Hiện nay, các kỹ thuật trích xuất thông tin hữu ích từ dữ liệu tiếp tục phát triển. Khi giá trị của việc chuyển đổi dữ liệu thành thông tin hữu ích trở nên ngày càng rõ ràng, nhu cầu thu thập và xử lý dữ liệu càng gia tăng.
Dữ liệu càng chi tiết và toàn diện, càng nhiều xu hướng có thể được xác định và sử dụng vào lợi ích của mình. Sự phong phú về dữ liệu này cải thiện việc đào tạo mô hình trí tuệ nhân tạo (AI) và nâng cao hiệu suất kinh doanh. Đó là lý do tại sao các công ty đang chuyển hướng đến máy chủ Supermicro® sử dụng bộ xử lý AMD EPYC™ để khai thác tiềm năng của các ứng dụng và công việc yêu cầu lượng dữ liệu lớn:
Phân Tích Dữ Liệu Lớn (Big Data Analytics): Các tổ chức bán lẻ nhận thức được rằng họ có thể tận dụng các xu hướng và sở thích của khách hàng bằng cách thu thập và lưu giữ dữ liệu về mỗi giao dịch. Các ngành công nghiệp nặng có thể duy trì và thay thế thiết bị dựa trên dữ liệu về hiệu suất. Ví dụ, động cơ phản lực có thể được bảo dưỡng hiệu quả hơn khi mọi khía cạnh của hoạt động được giám sát từ dầu tiêu thụ đến nhiệt độ đốt cháy.
Trí Tuệ Nhân Tạo (Artificial Intelligence): Giá trị của video thực tế trên đường là không thể so sánh được khi phát triển và đào tạo xe tự lái. Khi thu thập và giữ lại, các đoạn phim từ chính các xe có thể được sử dụng để cung cấp thông tin quay lại mô hình để ra quyết định lái xe tinh tế hơn. Trong phát triển thuốc, các kỹ thuật gen học AI được kích hoạt bởi nhiều thông tin về các phân tử có thể được điều chỉnh.

Tính Toán Hiệu Năng Cao (High-Performance Computing): Khi mô phỏng các quy trình tự nhiên và vật lý bằng dữ liệu chuỗi thời gian, càng nhiều dữ liệu càng tốt. Dữ liệu địa chất học nhiều hơn giúp xác định nơi tốt nhất để xác định một mỏ dầu. Dự báo thời tiết và khí hậu có lợi khi mô hình phân tích nhiều khoảng thời gian và ô vuông biểu thị trên bản đồ.
Tự Động Hóa Thiết Kế Điện Tử (Electronic Design Automation): Khi kích thước node quy trình bán dẫn giảm và mạch điện tử trở nên phức tạp hơn, càng cần nhiều dữ liệu hơn để mô phỏng thiết kế và tìm lỗi tiềm ẩn trước khi sản xuất vi mạch mới.
Tự Động Hóa Quy Trình Sản Xuất (Production Process Automation): Giám sát quy trình và quản lý thời gian thực được hưởng lợi từ các khoảng thời gian mẫu dữ liệu ngắn hơn cho dòng chảy, nhiệt độ và áp suất. Việc giữ lại dữ liệu cung cấp một dấu vết kiểm tra và một cách để gỡ lỗi nếu có vấn đề nào xuất hiện trong sản phẩm hoàn thiện.
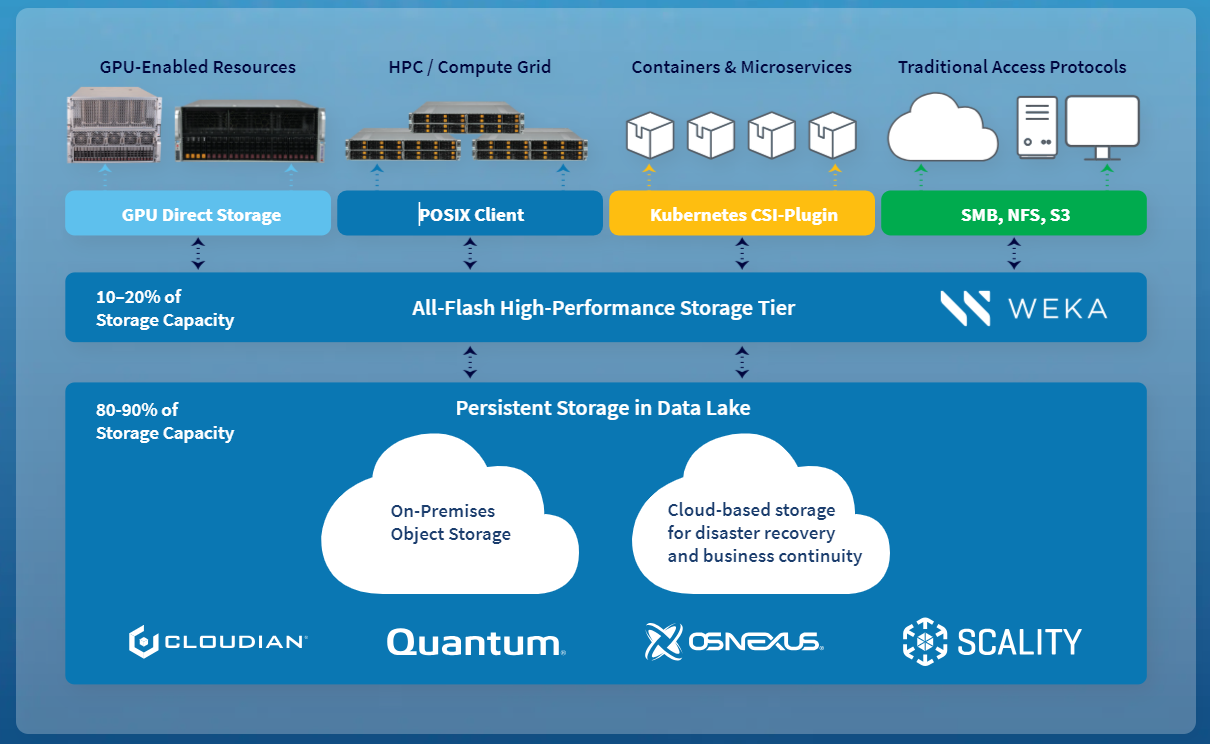
Reference Architecture Overview
Supermicro đã thiết kế một kiến trúc tham chiếu lưu trữ mở rộ để đáp ứng những nhu cầu mà chúng ta đã mô tả trước đó. Kiến trúc này linh hoạt và có khả năng mở rộ, có thể thích ứng với nhiều nhu cầu ứng dụng yêu cầu lưu trữ và mở rộ khi tập dữ liệu mở rộ. Nó bao gồm ba tầng:
• Tầng all-flash: Tầng này lưu trữ dữ liệu hoạt động (dữ liệu cần truy cập và lưu trữ nhanh nhất). Thường chiếm khoảng 10 đến 20 phần trăm tổng dữ liệu của tổ chức và là một bộ nhớ đệm cho tầng ứng dụng.
• Tầng đối tượng: Tầng này cung cấp lưu trữ được tối ưu hóa về dung lượng dành cho dữ liệu không cần thiết ngay lập tức, thường chiếm khoảng 80 đến 90 phần trăm tổng dữ liệu. Trong khi tầng all-flash hoạt động như một bộ nhớ đệm dữ liệu, tầng lưu trữ đối tượng hoạt động như một hồ dữ liệu.
• Tầng ứng dụng: Tầng này bao gồm các hệ thống chạy công việc và tiêu thụ dữ liệu. Trong ví dụ triển khai mà chúng ta sẽ mô tả ở phần tiếp theo, chúng ta sử dụng máy chủ 8-GPU của Supermicro với bộ xử lý AMD EPYC để hỗ trợ việc đào tạo máy học.

Kiến trúc máy chủ được thiết kế với sự linh hoạt, cho phép mở rộ các tầng khác nhau theo nhu cầu cụ thể của khách hàng. Các tầng lưu trữ có thể được điều chỉnh để cân bằng hiệu suất và dung lượng, và các máy chủ Supermicro khác nhau có thể được sử dụng để đáp ứng yêu cầu về chi phí. Kiến trúc mạng được xây dựng trên các kết cấu InfiniBand® 400 Gb/s, hỗ trợ các tính năng giao thức như Remote DMA (RDMA) và NVMe over Fabrics (NVMeOF).
Kiến trúc phần mềm cũng được thiết kế với sự linh hoạt, cho phép triển khai trên nhiều sản phẩm cho tầng lưu trữ đối tượng, phục vụ sở thích của các tổ chức khác nhau. Ví dụ, các tổ chức giáo dục và các phòng thí nghiệm chính phủ thường hướng đến phần mềm nguồn mở, trong khi các tổ chức doanh nghiệp thường ưa chuộng phần mềm thương mại có mô hình hỗ trợ được xác định rõ.
Tầng All-Flash
Trung tâm của giải pháp, tầng All-Flash, giữ dữ liệu đang được ứng dụng sử dụng. Thông thường chiếm khoảng 10 đến 20 phần trăm tổng dữ liệu, tầng này sử dụng máy chủ lưu trữ All-Flash để lưu trữ dữ liệu trên hệ thống tệp phân tán và mở rộ đến một loạt các máy khách. Nó cũng có khả năng điều phối chuyển dữ liệu đến tầng lưu trữ đối tượng và vào đám mây.
Việc sử dụng máy chủ được tối ưu hóa cho lưu trữ – thay vì các thiết bị đặc biệt đắt tiền hơn – cho phép tỷ lệ tuyến tính, nơi băng thông tăng lên cùng với khả năng lưu trữ thêm dữ liệu khi thêm máy chủ vào cụm. Ngoài hỗ trợ cơ bản cho hệ thống tệp, phần mềm hỗ trợ tầng này phải cung cấp tính chất linh hoạt để giữ vững trước sự cố, để một máy chủ có thể gặp sự cố mà không ảnh hưởng đến việc cung cấp dịch vụ hoặc dẫn đến mất dữ liệu.
Cụm lưu trữ trong tầng này cần được kết nối với mạng lưới có băng thông cao nhất có sẵn, hoặc là 400 GbE hoặc InfiniBand 400 Gb/s, để duy trì độ trễ thấp nhất có thể.

Tầng Đối Tượng
Tầng All-Flash hoạt động như bộ nhớ đệm cho dữ liệu được sử dụng tích cực nhất trong tổ chức. Tuy nhiên, với nhiều doanh nghiệp yêu cầu dữ liệu mật độ cao, dữ liệu không thể chỉ đơn giản bị xóa khi không còn được sử dụng thường xuyên. Nó vẫn giữ giá trị, và cần được giữ lại trên lưu trữ được tối ưu hóa cho dung lượng và độ bền thay vì hiệu suất, giảm chi phí đối với 80 đến 90 phần trăm dữ liệu thuộc loại này. Các máy chủ để hỗ trợ nhiệm vụ này có mật độ ổ đĩa cao, và chúng có yêu cầu băng thông và IOPS thấp so với tầng lưu trữ đối tượng. Tương tự, yêu cầu về mạng lưới được giảm nhẹ, và 100 GbE là một lựa chọn kinh tế cân bằng giữa chi phí và hiệu suất cho nhu cầu lưu trữ đối tượng.
Lý tưởng, phần mềm quản lý tầng này cần cung cấp một kho lưu trữ nội dung có thể tìm kiếm cho dữ liệu không cấu trúc, nơi nó tham gia vào không gian tên toàn cầu được cung cấp bởi tầng All-Flash. Nó cần tập trung vào việc bảo vệ dữ liệu khỏi mất mát do sự cố phần cứng và cả từ các mối đe doạ bao gồm ransomware hoặc thậm chí xóa tình cờ. Nó cần quản lý việc chuyển tầng lưu trữ, để có thể di chuyển dữ liệu đến lưu trữ dựa trên đám mây khi được chỉ đạo bởi các chính sách vòng đời dữ liệu.
Phần mềm cần cung cấp nhiều khả năng giống như tầng All-Flash, nhưng cần tập trung vào quản lý vòng đời lưu trữ. Nó cần mở rộng mà không gây gián đoạn và tiếp tục hoạt động mà không mất dữ liệu thông qua sự cố của bất kỳ thành phần nào trong tầng. Nhưng nó cũng phải bảo vệ và bảo tồn dữ liệu thông qua bảo vệ dữ liệu erasure coding, phiên bản, sao chép từ xa, khóa đối tượng, giảm mối đe doạ, và triển khai các chính sách lưu giữ và di chuyển dữ liệu trong vòng đời.

Tầng Ứng Dụng
Tầng ứng dụng, nơi các công việc đòi hỏi lượng dữ liệu lớn đặt chỗ, kết nối trực tiếp với tầng All-Flash. Kết nối này được thực hiện thông qua liên kết InfiniBand 400 Gb/s, đảm bảo hiệu suất cao và độ trễ thấp.
• Đối với các công việc đòi hỏi tăng tốc GPU, tầng All-Flash hỗ trợ các giao thức NVIDIA® GPUDirect™ để truyền dữ liệu trực tiếp từ bộ nhớ lưu trữ đến bộ nhớ GPU.
• Đối với các ứng dụng HPC sử dụng số lượng lõi cao trong bộ xử lý AMD EPYC, hỗ trợ các giao thức tệp tiêu chuẩn.
• Đối với các ứng dụng đòi hỏi lượng dữ liệu lớn triển khai bằng cách sử dụng phương pháp cloud-native bao gồm containers và microservices, giao thức truy cập ưa thích thường là Kubernetes Container Storage Interface (CSI).
• Đối với truy cập từ các máy trạm thông thường, các giao thức chia sẻ hệ thống tệp được sử dụng, bao gồm Server Message Block (SMB), Network File System (NFS) và Amazon S3.
Tầng ứng dụng sử dụng InfiniBand 400 Gb/s để truy cập lưu trữ trong tầng All-Flash. Mạng lưới Ethernet riêng biệt của trung tâm dữ liệu được sử dụng cho quản lý “in-band” của các ứng dụng xử lý dữ liệu.
Reference Architecture at Work
Rất nhiều khách hàng đang sử dụng Kiến trúc Lưu trữ của Supermicro cho các ứng dụng bao gồm học máy cho lái xe tự động, nghiên cứu y sinh học và cơ sở dữ liệu truyền thông xã hội. Không nơi nào đòi hỏi cao hơn là trong lĩnh vực học máy. Việc huấn luyện mô hình trên dữ liệu hình ảnh, video và ngôn ngữ một cách hiệu quả đòi hỏi một luồng dữ liệu liên tục để cung cấp cho các mảng tăng tố GPU. Supermicro cung cấp một bộ máy chủ đa dạng có thể đáp ứng kiến trúc lưu trữ để đáp ứng một loạt các yêu cầu về dung lượng và hiệu suất, cũng như máy chủ chứa nhiều GPU để hỗ trợ các ứng dụng khách hàng đòi hỏi nhất.
Supermicro hợp tác chặt chẽ với các tổ chức để cẩn thận xác định kích thước và cấu hình kiến trúc và cơ sở hạ tầng cho trường hợp sử dụng của họ. Kiến trúc tham chiếu mô tả dưới đây đóng vai trò như một ví dụ được thử nghiệm, xác thực và triển khai để đào tạo máy học. Giải pháp có thể mở rộng lên và giảm xuống tùy thuộc vào nhu cầu của khách hàng và có thể được xây dựng với một hoặc hai tầng lưu trữ.

Tầng all-flash là trái tim của kiến trúc lưu trữ, với yêu cầu hiệu suất cao được đáp ứng thông qua các máy chủ lưu trữ mới nhất chạy nền tảng dữ liệu Weka.
Tầng đối tượng cung cấp lưu trữ đối tượng tùy chọn. Trong kiến trúc tham chiếu, tầng đối tượng được quản lý bởi Phần mềm Lưu trữ Đối tượng Quantum ActiveScale. Bộ nhớ dữ liệu lưu trữ hiệu quả với độ bền dữ liệu, khả năng truy cập và bảo mật cực kỳ cao.
Tầng ứng dụng được xây dựng để chạy các công việc máy học đòi hỏi nhiều năng lực, trong đó phần lớn công việc được thực hiện trên các tăng tố GPU.
Delivering Business Advantage
Lựa chọn hỗ trợ các ứng dụng đòi hỏi lượng dữ liệu lớn với kiến trúc lưu trữ mở rộng từ Supermicro là một quyết định chiến lược kinh doanh có thể mang lại lợi ích trong nhiều năm tới.
Giữ Dữ Liệu Tại Nơi
Quyết định đầu tiên là giữ dữ liệu tại nơi với sự kiểm soát tuyệt đối về nơi dữ liệu được lưu trữ. Tiếp theo là xác định một thiết kế cơ sở hạ tầng với băng thông đủ và độ trễ thấp để đáp ứng yêu cầu của ứng dụng. Tình trạng liên tục của doanh nghiệp cũng là một yếu tố quan trọng. Mọi tổ chức đều có thể gặp sự cố và mất dữ liệu do thiên tai, lỗi người sử dụng và tấn công mạng.
Bao gồm các thực hành sao chép dữ liệu trong kế hoạch khôi phục thiên tai có thể giúp giảm thiểu thời gian chết và duy trì liên tục kinh doanh. Có nhiều lựa chọn sao chép dữ liệu, như sao chép tại chỗ và sao chép đến đám mây hoặc các địa điểm từ xa. Đây thường là cách tiếp cận có chi phí hiệu quả nhất, vì giá lưu trữ dựa trên đám mây và băng thông để truy cập nó có thể là quá mức.
Chọn Kiến Trúc Lưu Trữ Mở Rộng Của Supermicro
Tiếp theo là quyết định chọn kiến trúc tham chiếu mở rộng của Supermicro. Supermicro nổi tiếng với việc cung cấp một bộ máy chủ đa dạng được tối ưu hóa cho mọi công việc. Vì vậy, liệu có cần sự mật độ GPU cao nhất để tăng tốc học máy hoặc mật độ lõi bộ xử lý AMD EPYC cao nhất cho tầng ứng dụng, Supermicro đều cung cấp máy chủ được tối ưu hóa để đáp ứng nhu cầu cụ thể. Việc chọn Supermicro mang lại sự linh hoạt. Khi nhu cầu thay đổi, tổ chức có thể sử dụng cùng một kiến trúc lưu trữ để cung cấp năng lượng cho các ứng dụng khác nhau đòi hỏi dữ liệu, biết rằng có sẵn một loạt các lựa chọn cho các ứng dụng.

Cấu Hình Tầng Lưu Trữ Cho Các Công Việc
Kiến trúc tham chiếu lưu trữ mở rộng được thiết kế với băng thông cao và độ trễ thấp, và được thử nghiệm và xác nhận để đạt được hiệu suất tối ưu. Supermicro điều chỉnh cấu hình máy chủ Petascale để cung cấp luồng dữ liệu tối ưu qua NVIDIA ConnectX-7 SmartNICs và trang bị máy chủ GPU trong tầng ứng dụng với các giao diện phù hợp để đảm bảo luồng dữ liệu không bị gián đoạn.
Với phương pháp xây dựng độc đáo của Supermicro, dung lượng, hiệu suất và chi phí có thể được cân bằng để cung cấp một giải pháp đáp ứng nhu cầu ứng dụng trong các hạn chế ngân sách. Ví dụ, tổ chức có thể sử dụng máy chủ Supermicro Petascale 1U và 2U hiệu suất cao trong tầng all-flash hoặc chọn lưu trữ NVMe U.2 truyền thống cho một giải pháp kinh tế. Tương tự, máy chủ Supermicro SuperStorage cung cấp bốn nền tảng lưu trữ đối tượng khác nhau, cung cấp dung lượng và hiệu suất tối đa trong không gian tối thiểu cho lưu trữ dữ liệu bền vững kinh tế.
Làm cho Ứng Dụng Hiệu Quả
Kiến trúc tham chiếu này, kết hợp với máy chủ Supermicro, được thiết kế để tối đa hóa hiệu suất ứng dụng. Bởi vì mỗi tổ chức có một bộ yêu cầu độc đáo, đội ngũ kỹ sư của Supermicro sẵn sàng hỗ trợ kích thước, thiết kế và triển khai một phiên bản được tối ưu hóa của kiến trúc lưu trữ mở rộng, đáp ứng yêu cầu về hiệu suất và dung lượng và giúp đảm bảo rằng doanh nghiệp luôn ở phía trước của xu hướng.
Get Started
Kiến trúc Lưu trữ Mở Rộng của Supermicro cung cấp nền tảng để biến dữ liệu thành những hiểu biết có thể thực hiện được. Khi triển khai cùng với các máy chủ Supermicro sử dụng bộ xử lý AMD EPYC, kiến trúc này có thể giúp tổ chức thu thập và xử lý dữ liệu để đạt được kết quả kinh doanh tốt hơn. Để biết thêm thông tin, hãy truy cập supermicro.com và các liên kết dưới đây hoặc liên hệ với chúng tôi tại đây
• Máy chủ rack Supermicro, máy chủ GPU và máy chủ lưu trữ
• Phần mềm Weka Data Platform
• Phần mềm Lưu trữ Đối tượng Quantum ActiveScale
• Bộ chuyển đổi NVIDIA ConnectX-7
→ Để tìm hiểu thêm về toàn bộ dòng máy chủ Supermicro dựa trên AMD, hãy truy cập: https://thegioimaychu.vn/server/supermicro/
→ Để tìm hiểu thêm giải pháp của Supermicro dành cho AI/HPC, hãy truy cập: https://thegioimaychu.vn/solution/ai/
 Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Với kinh nghiệm làm nhà phân phối chính thức máy chủ Supermicro từ năm 2005, Nhất Tiến Chung (NTC) tiên phong đem đến các giải pháp hạ tầng CNTT dựa trên danh mục phần cứng đa dạng và tối ưu chi phí đầu tư nhất từ Supermicro. Các máy chủ GPU và máy chủ lưu trữ hiệu năng cao chuyên dụng cho AI, Deep Learning, cấu hình tùy biến theo nhu cầu, được nhiều đối tác lựa chọn cho dự án của mình. Vui lòng liên hệ để được tư vấn giải pháp, hoàn toàn miễn phí.
Bạn muốn trở thành đối tác bán hàng Supermicro của NTC?
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- Hướng dẫn triển khai máy chủ GPU tại chỗ trong các phòng máy doanh nghiệp
- NVIDIA ConnectX-8 SuperNIC: Đột phá kiến trúc hạ tầng AI với PCIe Gen6
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- NVIDIA: Công nghệ Silicon Photonics và Co-Packaged Optics – Thay đổi cuộc chơi trong kỷ nguyên AI và HPC