
Những gì tôi cần để chạy các mô hình text-to-image mới nhất? Liệu có thể dùng các card gaming để thực hiện công việc này? Hay phải cần đến một chiếc GPU A100 cao cấp? Nếu hệ thống chỉ có một CPU thì sao? Đây là những câu hỏi thường xuyên gặp phải khi khách hàng có nhu cầu về ứng dụng AI hay GPU server/workstation nói chung.
Để làm sáng tỏ những câu hỏi này, chúng tôi đã tiến hành một bài kiểm tra điểm hiệu suất (benchmark) trên các GPU và CPU khác nhau trên phần mềm Stable Diffusion. Và dưới đây là tóm tắt kết quả ghi nhận được:
Nhiều GPU phổ thông có thể thực hiện công việc tốt, vì Stable Diffusion chỉ cần khoảng 5 giây với 5GB VRAM để chạy. Khi nói đến tốc độ để xuất một hình ảnh duy nhất, GPU Ampere mạnh nhất (A100) chỉ nhanh hơn 3080 khoảng 33% (hoặc 1.85 giây). Bằng cách tăng kích thước batch tới mức tối đa, A100 có thể cung cấp thông lượng inference gấp 2.5 lần so với 3080. Bài kiểm tra của chúng tôi sử dụng một câu lệnh văn bản làm đầu vào và xuất ra một hình ảnh có độ phân giải 512×512. Chúng tôi sử dụng thư viện mô hình từ diffusers của Huggingface và phân tích hiệu suất inference liên quan đến tốc độ, tiêu thụ bộ nhớ, thông lượng, và chất lượng của hình ảnh xuất ra. Chúng tôi xem xét cách các lựa chọn khác nhau về phần cứng (mô hình GPU, GPU so với CPU) và phần mềm (độ chính xác nửa/half-precision, pytorch so với onnxruntime) ảnh hưởng đến hiệu suất inference.
Stable Diffusion là gì?
Stable Diffusion là một phần mềm trí tuệ nhân tạo được phát triển bởi công ty Stability AI và được ra mắt công khai vào năm 2022. Phần mềm này cho phép chuyển đổi văn bản thành hình ảnh chi tiết, được gọi là chuyển đổi từ văn bản sang hình ảnh (text-to-image). Ngoài ra, nó cũng có thể áp dụng cho nhiều nhiệm vụ khác như “dịch” hình ảnh sang hình ảnh, điền hình ảnh, mở rộng hình ảnh.

Mặc dù Stable Diffusion không có giao diện người dùng thân thiện như một số công cụ tạo hình ảnh trí tuệ nhân tạo khác, tuy nhiên, bạn hoàn toàn có thể sử dụng miễn phí phần mềm này trên máy tính cá nhân của bạn.
Để có cơ sở tham khảo, chúng tôi sẽ cung cấp kết quả kiểm tra hiệu suất cho các GPU sau đây: A100 80GB PCIe, RTX3090, RTXA5500, RTXA6000, RTX3080, RTX8000. Vui lòng xem thêm phần “Tái hiện các thí nghiệm” để biết chi tiết về việc chạy các thí nghiệm này trong môi trường của bạn.
Cuối cùng nhưng không kém phần quan trọng, chúng tôi hào hứng chờ đón sự phát triển nhanh chóng từ cộng đồng. Ví dụ, “sliced attention” trick có thể giảm chi phí VRAM xuống “chỉ còn 3.2 GB” với một chút đánh đổi khoảng 10% tốc độ inference chậm hơn. Chúng tôi cũng trông đợi thử nghiệm ONNX runtime với các thiết bị CUDA khi nó trở nên ổn định hơn trong tương lai gần.
Tốc độ
Hình dưới đây thể hiện tốc độ inference khi sử dụng phần cứng và độ chính xác khác nhau để tạo ra một hình ảnh duy nhất bằng cách sử dụng câu lệnh văn bản (tùy ý): “một bức ảnh về một phi hành gia cưỡi ngựa trên sao Hỏa”.
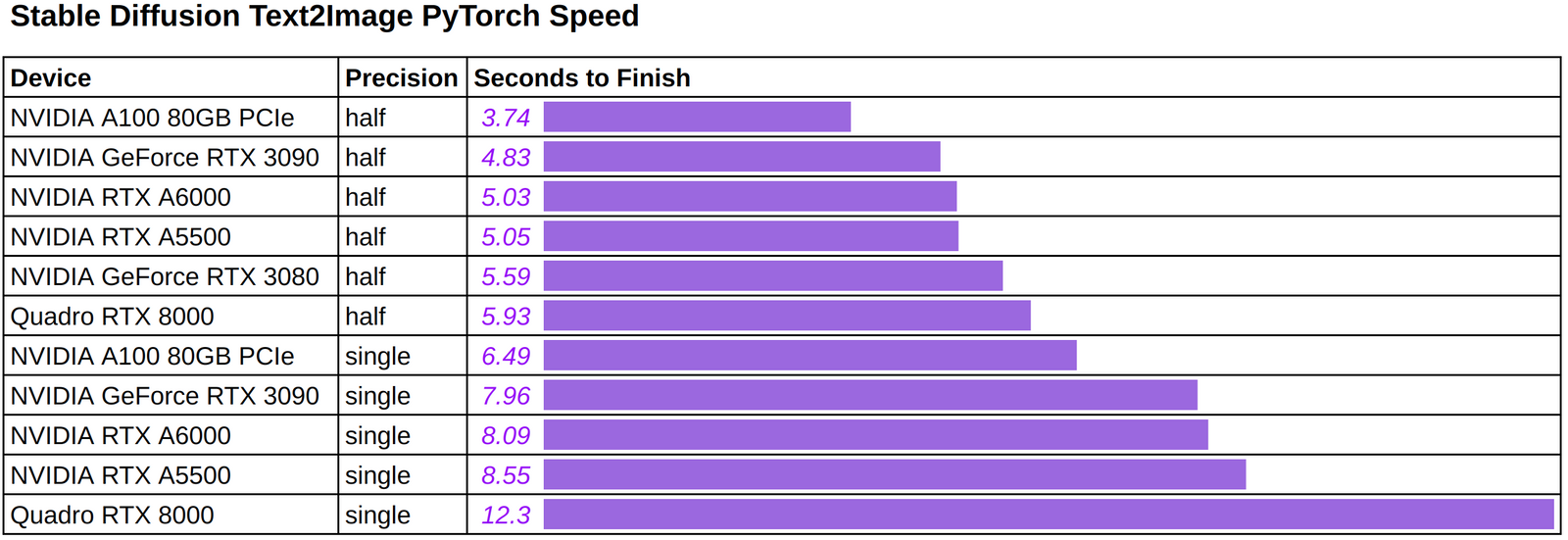
Chúng tôi nhận thấy rằng:
Thời gian để tạo ra một hình ảnh đầu ra duy nhất dao động từ 3,74 đến 5,59 giây trên các GPU Ampere được thử nghiệm, bao gồm cả card 3080 dành cho người tiêu dùng và card A100 80GB cao cấp. Độ chính xác nửa giảm thời gian khoảng 40% cho các GPU Ampere, và 52% cho thế hệ trước GPU RTX8000. Chúng tôi tin rằng các GPU Ampere có một sự tăng tốc tương đối “nhỏ” từ độ chính xác nửa do sử dụng TF32. Đối với những đọc giả không quen thuộc với TF32, đây là một định dạng 19 bit đã được sử dụng như dạng dữ liệu chính xác đơn mặc định trên GPU Ampere cho các nền tảng học sâu chính như PyTorch và TensorFlow. Một người có thể mong đợi tốc độ tăng của độ chính xác nửa so với FP32 sẽ lớn hơn vì nó là một định dạng 32 bit thực sự.
Chúng tôi chạy các công việc inference tương tự này trên các thiết bị CPU để so sánh hiệu suất được quan sát trên các thiết bị GPU.
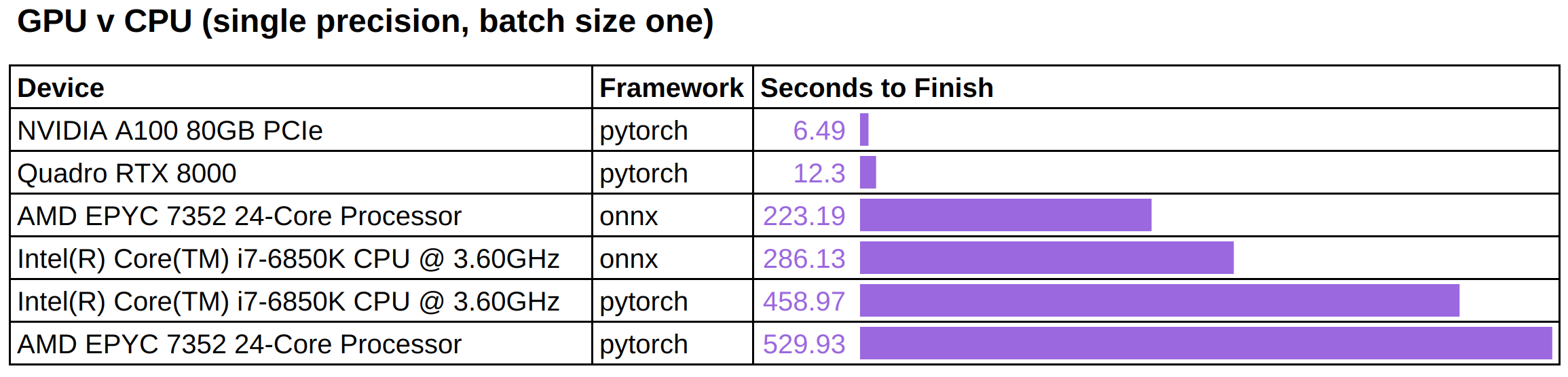
Chúng tôi lưu ý rằng:
GPU nhanh hơn đáng kể – từ một đến hai bậc lượng tử phụ thuộc vào độ chính xác. onnxruntime có thể giảm thời gian inference trên CPU khoảng 40% đến 50%, tùy thuộc vào loại CPU.
Lưu ý rằng, hiện tại ONNX runtime chưa có hỗ trợ backend CUDA ổn định cho Hugging Face diffusers, và chúng tôi cũng không quan sát được tăng tốc ý nghĩa trong các thử nghiệm ban đầu với CUDAExecutionProvider. Chúng tôi rất mong đợi thực hiện một bài kiểm tra tỉ mỉ hơn khi ONNX runtime trở nên tối ưu hơn cho stable diffusion.
Bộ nhớ
Chúng tôi cũng đo lường tiêu thụ bộ nhớ khi thực hiện inference cho Stable Diffusion.
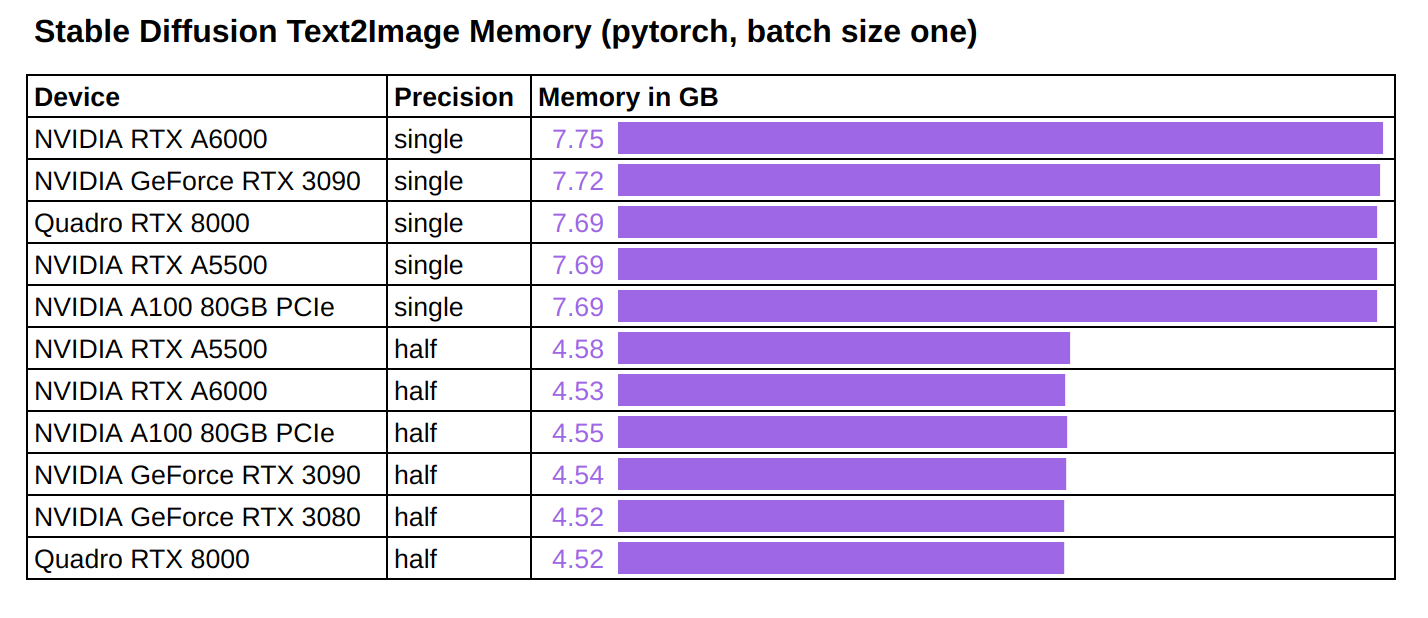
Sử dụng bộ nhớ được quan sát là nhất quán trên tất cả các GPU được thử nghiệm:
Cần khoảng 7.7 GB bộ nhớ GPU để chạy inference đơn chính xác với kích thước batch là một. Cần khoảng 4.5 GB bộ nhớ GPU để chạy inference nửa chính xác với kích thước batch là một.
Thống kê về Hiệu năng
Cho đến nay, chúng tôi đã đo lường tốc độ xử lý một đầu vào duy nhất, điều quan trọng đối với các ứng dụng trực tuyến không dung nạp bất kỳ độ trễ nào. Tuy nhiên, một số ứng dụng (ngoại tuyến) có thể tập trung vào “thông lượng”, đo lường tổng dung lượng dữ liệu xử lý trong một khoảng thời gian cố định.
Bài kiểm tra thông lượng của chúng tôi đẩy kích thước batch tới tối đa cho mỗi GPU và đo lường số hình ảnh chúng có thể xử lý trong một phút. Lý do để tối đa hóa kích thước batch là để giữ cho tensor cores bận rộn để tính toán có thể chiếm ưu thế trong tải công việc, tránh bất kỳ hạn chế phi tính toán nào và tối đa hóa thông lượng.
Chúng tôi thực hiện một loạt thí nghiệm thông lượng trong pytorch với half-precision và sử dụng kích thước batch tối đa có thể sử dụng cho mỗi GPU:
Chúng tôi nhận thấy:
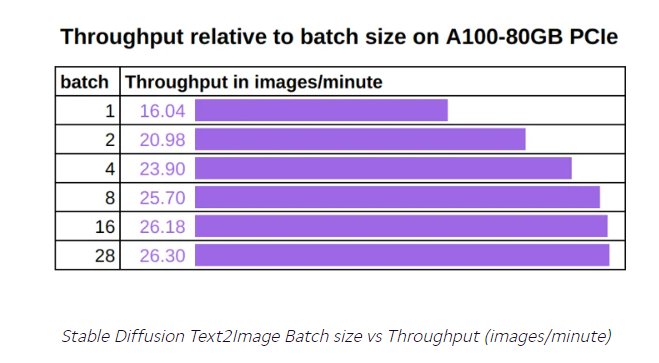
Một lần nữa, A100 80GB là tốt nhất và có thông lượng cao nhất. Sự chênh lệch về thông lượng giữa A100 80GB và các card khác có thể được giải thích bởi kích thước batch tối đa lớn hơn có thể sử dụng trên card này. Một ví dụ cụ thể, biểu đồ dưới đây cho thấy cách thông lượng của A100 80GB tăng lên 64% khi chúng tôi thay đổi kích thước batch từ một lên 28 (lớn nhất mà không gây lỗi “out of memory”). Điều thú vị là sự gia tăng không phải tuyến tính và làm phẳng khi kích thước batch đạt đến một giá trị nhất định, lúc đó các tensor core trên GPU đã bị bão hòa và bất kỳ dữ liệu mới nào trong bộ nhớ GPU sẽ phải được xếp hàng trước khi có nguồn tài nguyên tính toán riêng của chúng.
Độ chính xác/Precision
Chúng tôi tò mò xem liệu half-precision có làm giảm chất lượng của hình ảnh xuất ra hay không. Để kiểm tra điều này, chúng tôi đã giữ nguyên câu lệnh văn bản cũng như đầu vào “latents” và đưa chúng vào mô hình chính xác đơn và mô hình chính xác nửa. Chúng tôi chạy inference 100 lần với số bước tăng lên. Kết quả đầu ra của cả hai mô hình, cũng như bản đồ khác biệt của chúng, được lưu lại cho mỗi lần chạy.

Quan sát của chúng tôi là có sự khác biệt rõ ràng giữa single-precision output và haft-precision output, đặc biệt là ở các bước đầu tiên. Sự khác biệt thường giảm đi khi số bước tăng lên, nhưng không hẳn là hoàn toàn biến mất.
Thú vị là, sự khác biệt như vậy không nhất thiết đồng nghĩa với việc xuất hiện lỗi ở half-precision output. Ví dụ, trong bước 70, hình ảnh dưới đây cho thấy chính xác nửa không tạo ra lỗi nửa chính xác trong đầu ra chính xác đơn (một chân phía trước bổ sung):

→ Để biết thêm thông tin về các GPU của NVIDIA, hãy truy cập: https://thegioimaychu.vn/linh-kien-may-chu/gpu-card-may-chu
→ Để biết thêm thông tin về danh mục giải pháp NVIDIA của Supermicro, hãy truy cập: https://thegioimaychu.vn/solution/nvidia-hpc/
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?