VAST Data gần đây đã công bố VAST Data Platform, một giải pháp mới dựa trên các cấu trúc ban đầu của Universal Storage. Nền tảng này cung cấp những gì và nó đại diện cho vị thế thị trường nào đối với VAST Data?
VAST Data ra mắt vào năm 2019 với kiến trúc scale-out mới cho dữ liệu phi cấu trúc, khai thác các tính năng của bộ nhớ flash QLC NAND và bộ nhớ dài hạn giá rẻ. Thiết kế này, được gọi là DASE hay Disaggregated Shared Everything, về cơ bản là kho lưu trữ dạng key-value cực lớn cho các khối thông tin vật lý trong đó dữ liệu và metadata tồn tại ở mức ngang hàng nhau.

Bạn có thể tìm hiểu thêm về Universal Storage, hiện được gọi là VAST DataStore, trong hai podcast này.
- Giới thiệu về Dữ liệu VAST (Phần I) với Howard Marks
- Giới thiệu về Dữ liệu VAST (Phần II) với Howard Marks
Chiến lược tiếp thị ban đầu giải quyết các vấn đề về kinh tế của lưu trữ và đặc biệt là loại bỏ ổ cứng.
Theo thời gian, thông điệp đó đã phát triển khi mục tiêu ban đầu của việc đặt tên công ty là “VAST Data” (và không phải “VAST Storage”) tiếp tục xuất hiện. Chúng tôi đã ghi lại một số suy nghĩ trong bài đăng trên blog vào cuối tháng 11 năm 2021 (xem tại đây), trong đó suy nghĩ ban đầu tập trung vào công nghệ mới và cách công nghệ này có thể cải thiện Universal Storage.
Data Processing – Xử lí dữ liệu
Một lĩnh vực mà bài đăng trên blog năm 2021 đã đề cập đến là ý tưởng về xử lý phân tán, cụ thể là mức độ xử lý tự động bắt nguồn từ việc chỉ cần tiếp nhận nội dung mới. Đây là chủ đề mà chúng tôi đã nhắc lại nhiều lần, ví dụ, trong phần bình luận cuối bài đăng này nói về WEKA Data Platform, bài đăng này nói về S3 Object Lambda, và, podcast này và bài đăng trên blog này thảo luận về Hammerspace.
Giá trị của một hệ thống tự vận hành là rất dễ thấy. Hãy tưởng tượng một cơ sở dữ liệu hồ sơ y tế, ví dụ như X-quang, nơi các thuật toán AI sẽ xử lý dữ liệu đầu vào. Các thuật toán đó có thể được tinh chỉnh để cải thiện việc thu thập dữ liệu hiện tại nhưng cũng có thể xử lý lại dữ liệu lịch sử để xác định các bất thường bị bỏ sót. Khả năng trong nhiều ngành công nghiệp là vô tận.
Data Catalog – Danh mục dữ liệu
Vào tháng 2 năm 2023, VAST Data đã công bố VAST Data Catalog. Tính năng này tạo thành nền tảng cho khả năng mở rộng metadata, tạo ra một hệ thống cung cấp metadata có thể mở rộng cho từng phần nội dung được thu thập. Metadata có thể được truy vấn bằng các biểu thức theo kiểu SQL, tương tự như các tính năng của Amazon Athena.
Một kho metadata có thể tìm kiếm hiệu quả là một tính năng mạnh mẽ để mở rộng giá trị của nội dung dữ liệu. Chúng ta đều biết rằng việc tạo và lưu trữ một lượng lớn dữ liệu dễ dàng như thế nào, chỉ vài năm sau mới phải vật lộn để nhớ chính xác dữ liệu đó đại diện cho điều gì. Người dùng cuối không thể gắn thẻ dữ liệu theo cách thủ công theo bất kỳ cách thực tế nào, vì vậy cần có các công cụ và quy trình tự động.
Database – Cơ sở dữ liệu
Hãy tưởng tượng việc mở rộng Data Catalog để lưu trữ nội dung phức tạp hơn dưới dạng cơ sở dữ liệu đầy đủ tính năng bằng cách sử dụng các nguyên tắc cơ bản của Data Catalog làm công cụ truy vấn. Đây chính là những gì VAST Data đã cung cấp với DataStore. Không giống như các cơ sở dữ liệu OLTP truyền thống, dữ liệu được lưu trữ theo định dạng cột hiệu quả hơn, tạo điều kiện cho các truy vấn dữ liệu lớn và tốc độ cao. Việc triển khai VAST DataBase lưu trữ dữ liệu theo cách tương tự như Apache Parquet nhưng với độ chi tiết tốt hơn nhiều.
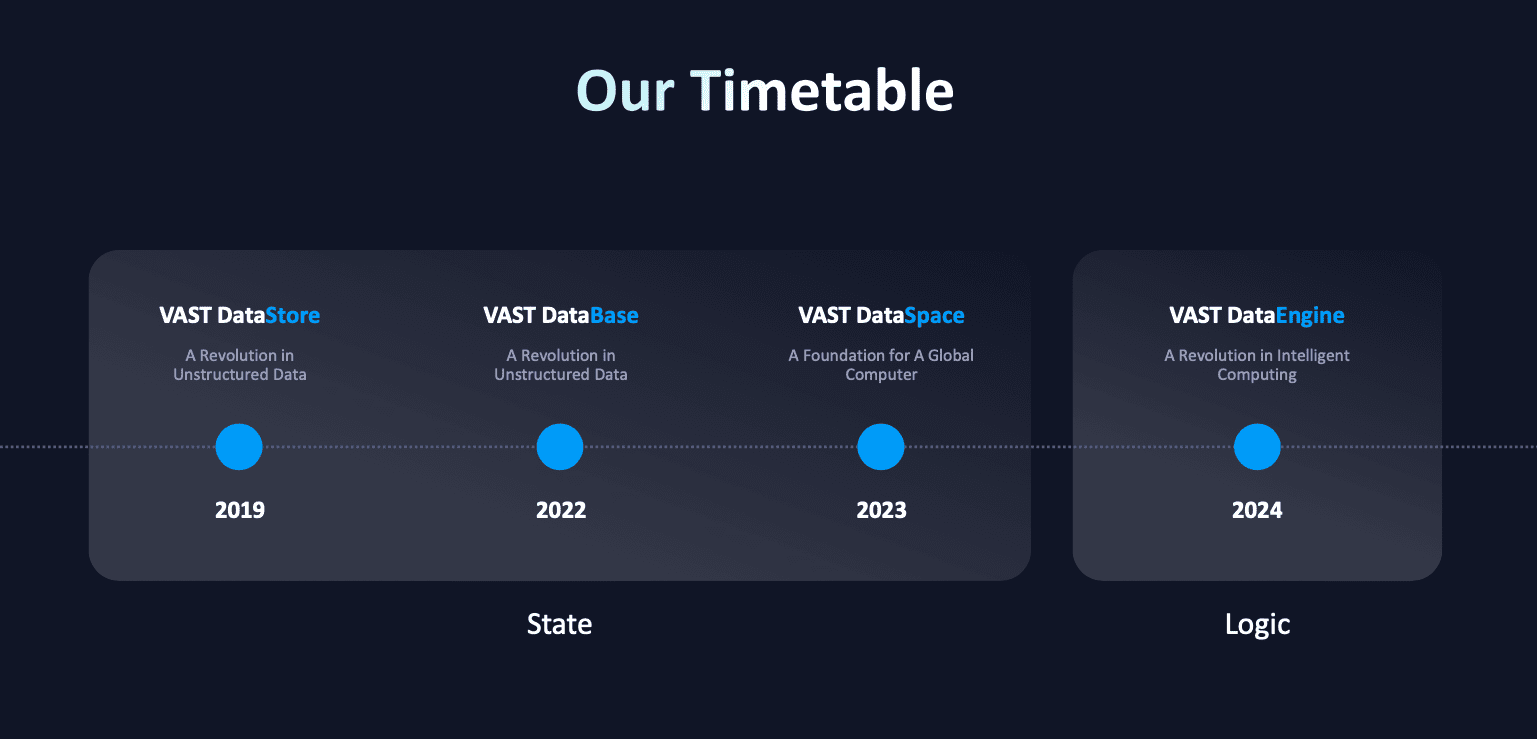
Kiến trúc cơ bản của VAST DataStore cho phép thêm dữ liệu vào VAST DataBase một cách hiệu quả và cho phép xử lý dữ liệu trong tương lai hiệu quả tương đương.
DataEngine – Bộ máy dữ liệu
Kết hợp tất cả các thành phần lại với nhau sẽ là VAST DataEngine, một tập hợp các ‘event trigger’ và các ‘function’ tương tự như AWS Lambda. Sau đó, khách hàng của VAST có thể xây dựng quy trình làm việc vào nền tảng, cung cấp mức độ tự động hóa mà chúng tôi đã đề cập. Một số ví dụ tích hợp đơn giản về các chức năng bao gồm thu thập metadata, phát hiện PII và phát hiện ransomware. Phần lớn chức năng sẽ đến từ khách hàng, chủ sở hữu dữ liệu, những người biết cách họ muốn xử lý dữ liệu khi dữ liệu đi vào nền tảng. Chúng ta sẽ tìm hiểu thêm về điều này sau.
Góc nhìn Kiến trúc
Còn nhiều điều cần tìm hiểu về DataPlatform mới hơn những gì chúng tôi đã đề cập trong bài đăng trên blog ngắn này. Tuy nhiên, điều rõ ràng là có một hướng đi cho VAST Data đưa công ty này thoát khỏi thế giới lưu trữ và cạnh tranh trực tiếp hơn với những công ty như Snowflake và Databricks. VAST Data đang xây dựng một hệ sinh thái trong đó giải pháp phần cứng cơ bản được thiết kế để cung cấp cách sử dụng công nghệ tốt nhất và hiệu quả nhất để thúc đẩy hiệu suất và khả năng mở rộng.
Nếu chúng ta nhìn vào nền tảng kinh doanh của Snowflake, công ty có mô hình tính phí dựa trên credits và dung lượng lưu trữ. Xử lý bên trong hạ tầng được tính phí theo giây, phù hợp với cấu trúc chi phí của dịch vụ đám mây mà giải pháp chạy trên đó. Truy vấn càng lớn và càng quy mô thì chi phí cho khách hàng càng lớn.
VAST Data cung cấp một giải pháp thay thế, nơi khách hàng có thể mua giấy phép cho nền tảng và sau đó phát triển hạ tầng theo thời gian, bao gồm cả thành phần xử lý. Công ty hy vọng rằng kiến trúc DASE cơ bản sẽ cung cấp sự khác biệt về chi phí và hiệu suất so với việc sử dụng giải pháp dựa trên đám mây.
Khi các doanh nghiệp chuyển đổi theo hướng sử dụng nhiều hơn công nghệ AI và phân tích, chi phí cho các truy vấn “nếu-như” và các quy trình BAU tương đương sẽ trở thành một phần ngày càng tăng trong cơ sở chi phí IT và chi phí kinh doanh nói chung.
Tuy nhiên, chúng tôi cho rằng tối ưu hóa chi phí và hiệu quả chỉ là một phần của câu chuyện. VAST hiện đang nói về DataSpace, nhiều cluster được cấu hình để chia sẻ dữ liệu toàn cục. Khía cạnh này của công nghệ có thể là yếu tố khác biệt về mặt kỹ thuật đối với nhiều doanh nghiệp. Nó giới thiệu khả năng lưu trữ và xử lý dữ liệu theo cách thức liên hợp nhau (federated), với các VAST Cloud instance lưu trữ dữ liệu trên dịch vụ đám mây và cung cấp quyền truy cập vào GPU dựa trên đám mây.
Thiết kế kiểu liên hợp này cung cấp khả năng tối ưu hóa chi phí, mở rộng quy mô nhanh chóng, xử lý dữ liệu tại biên và duy trì quyền sở hữu dữ liệu trong các trung tâm dữ liệu riêng tư. Điều này làm cho VAST Data Platform trở thành một nền tảng thực sự để xử lý dữ liệu, với kiến trúc độc đáo khó có thể sao chép trong dịch vụ đám mây hoặc chỉ on-premise.
Theo Architecting.it
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi hiện là đối tác phân phối giải pháp nền tảng dữ liệu doanh nghiệp VAST Data chuyên cho AI, Deep Learning.
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi hiện là đối tác phân phối giải pháp nền tảng dữ liệu doanh nghiệp VAST Data chuyên cho AI, Deep Learning.
Chúng tôi cũng là nhà phân phối chính thức của NVIDIA cho các hệ thống điện toán hiệu năng cao dựa trên GPU như siêu máy tính Trí tuệ Nhân tạo NVIDIA DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh xử lý của các dòng GPU Data Center tối tân nhất, cùng hệ thống lưu trữ dựa trên VAST Data và mạng tốc độ cao từ Mellanox (thuộc NVIDIA).
Bạn muốn trở thành đối tác bán hàng VAST của NTC?
Bài viết liên quan
- Chạy ảo hóa Proxmox trên hệ thống lưu trữ hợp nhất EonStor GS của Infortrend
- U.2 SSD: “Chiến binh” hiệu năng cao ẩn mình trong thế giới lưu trữ doanh nghiệp
- Giải pháp tích hợp AI vào hệ thống lưu trữ dữ liệu doanh nghiệp: Tương lai đã đến!
- Giải pháp lưu trữ của Infortrend: Cách mạng hóa Quản lý Dữ liệu Y tế
- Cập nhật danh mục lưu trữ của Infortrend: Từ AI đến Hạ tầng Doanh nghiệp
- Sự bùng lên của lưu trữ S3/RDMA: Hiện đại hóa việc truy cập dữ liệu cho AI