
Trong kỷ nguyên của Trí tuệ nhân tạo (AI) và Điện toán Hiệu năng cao (HPC) hiện nay, hiệu suất của mạng không chỉ là yếu tố hỗ trợ mà đã trở thành một phần cốt lõi của hệ thống tính toán. NVIDIA thông qua việc mua lại Mellanox Technologies vào năm 2019, đã củng cố vị thế dẫn đầu của mình bằng cách cung cấp một hệ sinh thái mạng toàn diện, tối ưu hóa từ giao tiếp bên trong một máy chủ đến kết nối giữa hàng nghìn máy chủ trong một siêu máy tính.
1. Tổng quan về Hệ sinh thái Nvidia Networking
NVIDIA đã mua lại Mellanox Technologies với giá 6.9 tỷ USD vào năm 2019, với tầm nhìn về một trung tâm dữ liệu thế hệ mới hoạt động như một siêu máy tính khổng lồ. Việc sáp nhập này nhằm mục đích kết hợp sự vượt trội của NVIDIA trong lĩnh vực GPU với chuyên môn của Mellanox về các công nghệ kết nối hiệu suất cao, tạo ra một giải pháp end-to-end cho HPC, AI và Big Data. Mục tiêu chính là tối ưu hóa toàn bộ ngăn xếp tính toán, từ GPU đến các bộ phận kết nối, nhằm giải quyết các thách thức về di chuyển dữ liệu trong các khối lượng công việc đòi hỏi khắt khe nhất.
Hệ sinh thái này bao gồm hai trụ cột công nghệ chính:
- NVLink: Được thiết kế cho giao tiếp GPU-to-GPU siêu tốc độ cao trong phạm vi một máy chủ hoặc một Node duy nhất.
- InfiniBand: Là giao thức mạng tiêu chuẩn ngành dùng để kết nối nhiều máy chủ, hệ thống lưu trữ và các thiết bị khác trong các cụm lớn và trung tâm dữ liệu.
2. Sơ bộ về Công nghệ NVLink: Giải pháp Kết nối “Nội bộ hiệu suất cao”

NVLink là một giao thức kết nối điểm tới điểm (point-to-point) do NVIDIA phát triển, được thiết kế để khắc phục những hạn chế về băng thông của giao tiếp PCI Express truyền thống trong các hệ thống đa GPU. NVLink tạo ra một đường dẫn trực tiếp, tốc độ cao giữa các GPU, cho phép chúng chia sẻ dữ liệu và truy cập bộ nhớ của nhau một cách hiệu quả hơn, bỏ qua sự can thiệp của CPU.
2.1. Cách thức hoạt động và Kiến trúc:
- Giao tiếp trực tiếp GPU-to-GPU: NVLink cho phép các GPU giao tiếp trực tiếp với nhau mà không cần đi qua CPU hoặc bus PCIe, giảm đáng kể độ trễ và tăng thông lượng. Điều này đặc biệt quan trọng trong các tác vụ AI và HPC yêu cầu sự phối hợp chặt chẽ giữa các GPU.
- Kiến trúc liên kết: GPU không chỉ có một mà có nhiều đường kết nối vật lý (physical links) sử dụng công nghệ NVLink, mỗi liên kết bao gồm nhiều cặp differential pairs tốc độ cao. Các liên kết này có thể được cấu hình thành nhiều topology khác nhau như ring (vòng), mesh (lưới), hoặc hybrid cube-mesh thông qua NVSwitch.
- NVSwitch: Để mở rộng khả năng kết nối giữa nhiều GPU (lên đến 8 GPU trong một hệ thống DGX A100, hoặc 256 GPU trong một DGX SuperPOD), NVIDIA sử dụng NVSwitch. NVSwitch là một bộ chuyển mạch (switch) chuyên dụng cho NVLink, cho phép tất cả các GPU trong hệ thống giao tiếp với nhau theo mô hình kết nối đầy đủ (all-to-all), tối ưu hóa cho các tác vụ tính toán song song lớn. Ví dụ, NVSwitch thế hệ thứ ba trên A100 có 64 cổng, cung cấp tổng thông lượng Full-duplex 6.4 TB/s.
- Bộ nhớ hợp nhất (Unified Memory) và Tính nhất quán bộ nhớ đệm (Cache Coherence): NVLink hỗ trợ kiến trúc bộ nhớ hợp nhất, cho phép các GPU truy cập vào cùng một không gian địa chỉ bộ nhớ. Hơn nữa, nó duy trì tính nhất quán của bộ nhớ đệm giữa các GPU, đơn giản hóa việc lập trình và đảm bảo dữ liệu luôn được đồng bộ.
2.2. Lợi ích:
- Thông lượng siêu cao và Độ trễ cực thấp: NVLink cung cấp thông lượng cao hơn nhiều lần so với PCIe, ví dụ NVLink 4.0 cung cấp tới 900 GB/s thông lượng Full-duplex cho một GPU (gấp khoảng 7 lần PCIe Gen 5 x16 cho GPU), và độ trễ ở mức nano/giây.
- Tăng tốc độ xử lý: Giảm thời gian di chuyển dữ liệu giữa các GPU, từ đó tăng tốc độ đào tạo mô hình AI, mô phỏng khoa học và các khối lượng công việc tính toán chuyên sâu khác.
- Chia sẻ bộ nhớ hiệu quả: Cho phép các GPU truy cập trực tiếp vào bộ nhớ của nhau, loại bỏ sự cần thiết của việc sao chép dữ liệu qua CPU, tiết kiệm tài nguyên và thời gian.
- Khả năng mở rộng trong Server (máy chủ): Với NVSwitch, NVLink cho phép xây dựng các hệ thống đa GPU mạnh mẽ, có khả năng mở rộng hiệu suất tính toán lên đến hàng chục petaFLOPS trong một Server (máy chủ) duy nhất.
2.3. Các trường hợp sử dụng điển hình:
- Đào tạo Học sâu (Deep Learning Training): Đặc biệt cho các mô hình AI lớn và phức tạp yêu cầu sự hợp tác chặt chẽ giữa nhiều GPU để xử lý các tập dữ liệu khổng lồ.
- Mô phỏng Khoa học quy mô lớn: Các ứng dụng vật lý, hóa học, khí tượng, sinh học yêu cầu tính toán song song và truyền dữ liệu nhanh chóng giữa các bộ xử lý.
- Phân tích Dữ liệu lớn (Big Data Analytics): Tăng tốc các tác vụ phân tích trong bộ nhớ, xử lý đồ thị và học máy trên các tập dữ liệu lớn.
- Nền tảng NVIDIA DGX: Các hệ thống DGX của NVIDIA là minh chứng điển hình cho việc tận dụng NVLink và NVSwitch để tạo ra các siêu máy tính AI mạnh mẽ.
2.4. Thông số kỹ thuật quan trọng của NVLink:
| Phiên bản NVLink | Băng thông một chiều (Simplex bandwidth) / một liên kết | Tổng thông lượng Full-duplex / GPU | Khả năng trao đổi dữ liệu hai chiều tốc độ cao của NVSwitch | GPU hỗ trợ điển hình |
| NVLink 3.0 | 25 GB/s (ước tính) | 600 GB/s (12 liên kết trên A100) | 4.8 TB/s (6 NVSwitch) | Ampere (A100) |
| NVLink 4.0 | 50 GB/s | 900 GB/s (18 liên kết trên H100) | 3.6 TB/s (6 NVSwitch) | Hopper (H100) |
| NVLink 5.0 | 100 GB/s | 1.8 TB/s (18 liên kết trên B200) | 14.4 TB/s (8 NVSwitch) | Blackwell (B200) |
(Để xem bảng thông số đầy đủ của tất cả các thế hệ NVLink, vui lòng tham khảo Phụ lục.)
3. Tìm hiểu về Công nghệ InfiniBand: Xương sống cho các Cụm lớn và Trung tâm dữ liệu

InfiniBand là một kiến trúc truyền thông hiệu năng cao, độ trễ thấp, và thông lượng cao, được thiết kế đặc biệt cho các ứng dụng điện toán đòi hỏi khắt khe nhất. Nó đóng vai trò là xương sống kết nối hàng nghìn server trong các siêu máy tính, trung tâm dữ liệu và các cụm AI quy mô lớn.
3.1. Nguyên lý hoạt động và Kiến trúc:
- Kiến trúc chuyển mạch Fabric (Switched Fabric): InfiniBand sử dụng kiến trúc chuyển mạch điểm-điểm (point-to-point switching), nơi mỗi thiết bị (chẳng hạn như máy chủ hoặc GPU) được kết nối trực tiếp với một switch InfiniBand. Điều này khác biệt với các mạng truyền thống chia sẻ băng thông, đảm bảo cung cấp băng thông riêng biệt cho mỗi kết nối, giúp tránh tình trạng tắc nghẽn và tối ưu hóa hiệu suất.
- Truy cập bộ nhớ trực tiếp từ xa (RDMA – Remote Direct Memory Access): Đây là tính năng nổi bật nhất của InfiniBand. RDMA cho phép dữ liệu được truyền trực tiếp giữa bộ nhớ của hai thiết bị (ví dụ: giữa hai HCA hoặc giữa HCA và GPU) mà không cần sự can thiệp của CPU, hệ điều hành hay bộ nhớ cache. Điều này giúp giảm đáng kể độ trễ, giải phóng CPU để thực hiện các tác vụ tính toán chính.
- Kiến trúc phân lớp: Giống như mô hình OSI, InfiniBand có kiến trúc phân lớp, bao gồm lớp vật lý, lớp liên kết dữ liệu, lớp mạng và lớp vận chuyển. Điều này cho phép sự linh hoạt và khả năng mở rộng.
- Host Channel Adapters (HCAs): Là các card mạng chuyên dụng được cài đặt trên máy chủ hoặc thiết bị lưu trữ, cung cấp giao diện giữa máy chủ và mạng InfiniBand. HCAs thực hiện việc giảm tải (offload) các tác vụ giao tiếp khỏi CPU, bao gồm cả RDMA.
- InfiniBand Switches: Là các thiết bị trung tâm tạo nên fabric InfiniBand. Chúng cung cấp khả năng chuyển mạch tốc độ cao, hỗ trợ các topology mạng linh hoạt như fat-tree (phổ biến nhất trong HPC), mesh, và torus.
3.2. Ưu điểm:
- Thông lượng cực cao và Độ trễ cực thấp: InfiniBand cung cấp thông lượng hàng trăm gigabit mỗi giây và độ trễ dưới micro giây, điều này là cực kỳ quan trọng cho các ứng dụng song song và phân tán.
- Giảm tải CPU (CPU Offloading): Với RDMA, InfiniBand giảm tải các tác vụ giao tiếp phức tạp khỏi CPU, giải phóng tài nguyên CPU để xử lý các tác vụ tính toán chính.
- Kiểm soát tắc nghẽn (Congestion Control) và Định tuyến thích ứng (Adaptive Routing): InfiniBand bao gồm các cơ chế quản lý tắc nghẽn và định tuyến thích ứng tiên tiến để duy trì hiệu suất ổn định ngay cả trong các môi trường có lưu lượng truy cập cao.
- Khả năng mở rộng linh hoạt: InfiniBand fabric có thể dễ dàng mở rộng từ vài chục đến hàng chục nghìn Server mà vẫn duy trì hiệu suất cao và độ trễ thấp.
- Độ tin cậy cao: Hỗ trợ các tính năng như chuyển đổi dự phòng liên kết (link fail-over) và kiểm soát lỗi mạnh mẽ.
3.3. Các ứng dụng chính:
- Điện toán Hiệu năng cao (HPC): InfiniBand là công nghệ mạng chiếm ưu thế trong danh sách TOP500 siêu máy tính toàn cầu, hỗ trợ các mô phỏng khoa học, phân tích dữ liệu lớn và tính toán phân tán.
- Cụm AI/Học máy: Cần thiết cho việc đào tạo các mô hình AI quy mô lớn, nơi cần di chuyển lượng lớn dữ liệu giữa các GPU.
- Hệ thống lưu trữ phân tán: Đặc biệt là các hệ thống lưu trữ flash dựa trên NVMe-oF (NVMe over Fabrics) tận dụng InfiniBand để đạt được hiệu suất I/O cực cao.
- Cơ sở dữ liệu trong bộ nhớ và Phân tích thời gian thực: Các ứng dụng yêu cầu truy cập dữ liệu cực nhanh và độ trễ thấp.
3.4. Thông số kỹ thuật quan trọng của InfiniBand:
| Tên chuẩn (Ký hiệu) | Tốc độ / làn (Gbit/s) | Tổng thông lượng Full-duplex (4x link) | Tổng thông lượng Full-duplex (8x link) | Tổng thông lượng Full-duplex (12x link) |
| EDR (Enhanced Data Rate) | 25.78125 | 100 Gbit/s | 200 Gbit/s | 300 Gbit/s |
| HDR (High Data Rate) | 50 | 200 Gbit/s | 400 Gbit/s | 600 Gbit/s |
| NDR (Next Data Rate) | 100 | 400 Gbit/s | 800 Gbit/s | 1200 Gbit/s |
| XDR (Extreme Data Rate) | 200 | 800 Gbit/s | 1600 Gbit/s | 2400 Gbit/s |
| GDR (Giga Data Rate) | 400 | 1600 Gbit/s | 3200 Gbit/s | 4800 Gbit/s |
(Để xem bảng thông số đầy đủ của tất cả các thế hệ InfiniBand, vui lòng tham khảo Phụ lục.)
4. Sự Bổ sung và Tích hợp: Một Hệ thống Mạng Toàn diện
NVLink và InfiniBand không phải là các công nghệ cạnh tranh mà là các thành phần bổ sung cho nhau trong một hệ sinh thái mạnh mẽ, được thiết kế để tối ưu hóa hiệu suất của các hệ thống tính toán hiệu năng cao từ cấp độ chip đến cấp độ trung tâm dữ liệu. Chúng hoạt động ở các cấp độ khác nhau của kiến trúc hệ thống để đảm bảo luồng dữ liệu thông suốt và hiệu quả nhất.
Sơ đồ sẽ minh họa rõ ràng vị trí của từng công nghệ trong hệ thống:
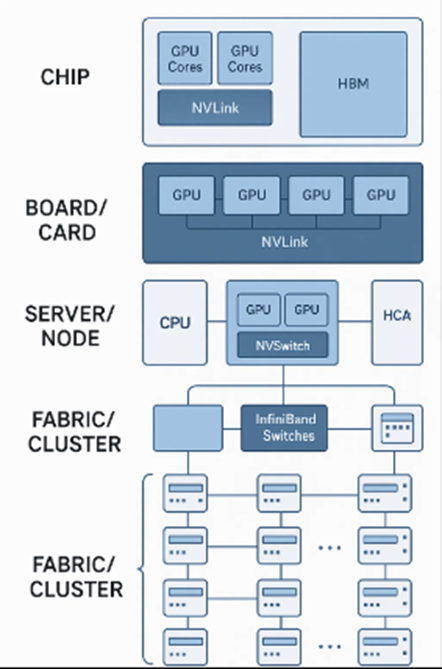
- Tầng Chip: Các nhân GPU, bộ nhớ HBM và các khối IP NVLink/NVLink-C2C bên trong chip.
- Tầng Board/Card: Cách các GPU trên một card hoặc board (ví dụ: NVIDIA HGX) được kết nối với nhau thông qua NVLink và NVSwitch.
- Tầng Server/Node: Một máy chủ hoàn chỉnh, bao gồm CPU, các GPU (kết nối qua NVLink/NVSwitch), và các Host Channel Adapters (HCAs) kết nối với mạng bên ngoài.
- Tầng Fabric/Cluster: Cách hàng trăm/nghìn server được kết nối với nhau thông qua InfiniBand Switches để tạo thành một cụm siêu máy tính hoặc trung tâm dữ liệu lớn.
4.1. Khi nào sử dụng từng công nghệ:
- NVLink: Là lựa chọn tối ưu cho giao tiếp nội bộ Server (intra-node), tức là giữa các GPU trong cùng một máy chủ vật lý. Nó cung cấp băng thông và độ trễ cao nhất có thể cho các tác vụ tính toán song song chặt chẽ, nơi các GPU cần truy cập bộ nhớ và dữ liệu của nhau một cách liên tục và nhanh chóng.
- InfiniBand: Là giải pháp vượt trội cho giao tiếp giữa các Server với nhau (inter-node), kết nối các máy chủ, hệ thống lưu trữ và thiết bị khác trên quy mô cụm hoặc trung tâm dữ liệu. Nó được thiết kế để mở rộng hiệu suất và khả năng của các ứng dụng phân tán lên hàng trăm hoặc hàng nghìn Server.
4.2. Tích hợp và Kiến trúc Hybrid:
Nhiều kiến trúc HPC và AI hiện đại sử dụng cách tiếp cận hybrid. Các GPU trong một máy chủ được kết nối chặt chẽ bằng NVLink (thường thông qua NVSwitch), tạo thành một “siêu GPU” ảo mạnh mẽ. Sau đó, các máy chủ này được kết nối với nhau thông qua InfiniBand, tạo thành một cụm siêu máy tính lớn. Sự kết hợp này đảm bảo rằng cả giao tiếp nội bộ Server và giao tiếp giữa các Server đều đạt được hiệu suất tối đa, tối ưu hóa toàn bộ luồng dữ liệu và tính toán.
5. Phân tích Kỹ thuật chuyên sâu
5.1. NVLink – Đi sâu vào Kiến trúc và Giao tiếp:
- Lớp Vật lý: NVLink sử dụng các cặp differential pairs để truyền tín hiệu tốc độ cao. Mỗi “liên kết” NVLink là một tập hợp các làn (lanes) ví dụ trên GPU H100, mỗi GPU có 18 liên kết NVLink 4.0, mỗi liên kết có 2 cặp differential pairs, cung cấp tổng cộng 36 cặp differential pairs. Tín hiệu được truyền qua giao thức NRZ (Non-Return-to-Zero) hoặc PAM4 (Pulse-Amplitude Modulation 4-level) ở các thế hệ mới hơn để đạt mật độ bit cao hơn trên mỗi chu kỳ xung nhịp.
- NVSwitch – Fabric Nâng cao: NVSwitch không chỉ là một bộ chuyển mạch đơn thuần mà là một chip phức tạp cho phép tạo ra các topology kết nối toàn diện (full-mesh/all-to-all) giữa hàng chục hoặc hàng trăm GPU. Ví dụ, mỗi NVSwitch trên hệ thống DGX H100 có 64 cổng, mỗi cổng cung cấp 100 GB/s thông lượng Full-duplex cho phép 8 GPU H100 kết nối với tổng thông lượng 3.6 TB/s. NVSwitch tích hợp các bộ đệm lớn và logic điều khiển luồng tiên tiến để đảm bảo giao tiếp không tắc nghẽn và độ trễ thấp.
- Unified Memory và Cache Coherency: Với NVLink, GPU có thể truy cập bộ nhớ của nhau một cách trực tiếp và duy trì tính nhất quán bộ nhớ đệm (cache coherence), đây là một tính năng cực kỳ phức tạp và mạnh mẽ. Điều này cho phép các thuật toán phân tán hoạt động hiệu quả hơn, vì dữ liệu có thể được truy cập và sửa đổi bởi bất kỳ GPU nào trong hệ thống mà không cần sao chép tường minh hay đồng bộ hóa thủ công qua CPU, giúp loại bỏ nút thắt cổ chai PCI Express.
- NVLink-C2C (Chip-to-Chip Interconnect): Một sự phát triển mới của NVLink, được sử dụng để kết nối các chip trong cùng một gói (package), điển hình là trong NVIDIA Grace Hopper Superchip. NVLink-C2C cho phép CPU (Grace) và GPU (Hopper) hoạt động như một thực thể tính toán duy nhất, chia sẻ bộ nhớ và giao tiếp với thông lượng lên đến 900 GB/s, vượt xa bất kỳ giao diện CPU-GPU truyền thống nào.
5.2. InfiniBand – Chi tiết về Hoạt động và Tối ưu hóa:
- Lớp Giao tiếp: InfiniBand bao gồm các lớp vật lý, liên kết dữ liệu, mạng và vận chuyển. Lớp liên kết dữ liệu quản lý các khung (frames) dữ liệu và kiểm soát lỗi. Lớp mạng cung cấp định tuyến. Lớp vận chuyển chịu trách nhiệm cung cấp các dịch vụ như Reliable Connected, Reliable Datagram, Unreliable Connected, và Unreliable Datagram, đảm bảo độ tin cậy và hiệu suất cho các loại ứng dụng khác nhau.
- RDMA (Remote Direct Memory Access): RDMA là cơ chế cho phép một thiết bị trực tiếp ghi hoặc đọc dữ liệu vào bộ nhớ của một thiết bị từ xa mà không cần CPU của thiết bị đích tham gia. Điều này đạt được thông qua việc sử dụng các Work Queue (WQ) và Completion Queue (CQ) trên HCA. Khi một ứng dụng yêu cầu RDMA, HCA sẽ xử lý toàn bộ quá trình, bao gồm truy cập bộ nhớ, điều khiển luồng, và kiểm tra lỗi, hoàn toàn giảm tải (offload) công việc khỏi CPU. Điều này dẫn đến độ trễ cực thấp (micro giây) và thông lượng cao, vì không có chu kỳ CPU hoặc hoạt động hệ điều hành nào bị lãng phí.
- In-Network Computing và SHARP (Scalable Hierarchical Aggregation and Reduction Protocol): NVIDIA/Mellanox đã tích hợp khả năng tính toán trong mạng vào các switch InfiniBand của mình, ví dụ với công nghệ SHARP. SHARP cho phép các phép tính tổng hợp và giảm dữ liệu (ví dụ: tính tổng SUM, tìm giá trị lớn nhất/nhỏ nhất MAX/MIN, hoặc kiểm tra điều kiện logic AND/OR) được thực hiện trực tiếp trên switch. Điều này có nghĩa là thay vì phải gửi toàn bộ dữ liệu thô về CPU để xử lý, switch sẽ tự thực hiện các phép tính này, giúp giảm đáng kể lượng dữ liệu cần truyền tải và tăng tốc độ xử lý tổng thể. Đặc biệt có lợi cho các thuật toán học sâu và HPC sử dụng các phép toán collective communication (ví dụ: All-reduce), giúp giảm đáng kể thời gian đồng bộ hóa và tăng hiệu quả tính toán.
- Quản lý tắc nghẽn (Congestion Management): InfiniBand sử dụng các thuật toán quản lý tắc nghẽn tinh vi để ngăn chặn và giảm thiểu sự tắc nghẽn mạng. Các switch và HCA có thể phát hiện tắc nghẽn và điều chỉnh tốc độ gửi dữ liệu, đảm bảo hiệu suất ổn định và công bằng cho tất cả các luồng dữ liệu.
- Chất lượng dịch vụ (QoS): InfiniBand hỗ trợ QoS, cho phép ưu tiên các loại lưu lượng truy cập khác nhau. Điều này quan trọng trong các môi trường đa người dùng hoặc đa ứng dụng, nơi một số khối lượng công việc có thể nhạy cảm hơn với độ trễ hoặc cần băng thông được đảm bảo.
5.3. NVIDIA DPU và Nền tảng DOCA:.

DPU (Data Processing Unit) là một loại bộ xử lý mới, nằm giữa CPU và GPU, được thiết kế để xử lý các tác vụ cơ sở hạ tầng của trung tâm dữ liệu. Dòng sản phẩm BlueField DPU của NVIDIA có khả năng giảm tải (offload), tăng tốc (accelerate) và cô lập (isolate) các dịch vụ hạ tầng như mạng, lưu trữ và bảo mật. Điều này giải phóng CPU để tập trung vào các khối lượng công việc ứng dụng cốt lõi (như AI/HPC). DOCA là một SDK (Software Development Kit) toàn diện cho phép các nhà phát triển xây dựng và triển khai các ứng dụng chạy trên DPU, khai thác tối đa khả năng của BlueField, bao gồm DOCA Flow cho khả năng xử lý gói dữ liệu tốc độ cao. BlueField DPU tích hợp các bộ điều hợp InfiniBand/Ethernet hiệu năng cao (ví dụ: ConnectX-7 trên BlueField-3), giúp nó trở thành một phần không thể thiếu của fabric mạng, hiện thực hóa tầm nhìn về một “data center là một đơn vị tính toán”.
5.4. Magnum IO & GPUDirect Storage:

Magnum IO là một bộ phần mềm giúp tăng tốc khả năng I/O của trung tâm dữ liệu cho các ứng dụng AI và HPC. Trong đó, GPUDirect Storage là một công nghệ then chốt cho phép đường dẫn dữ liệu trực tiếp giữa các thiết bị lưu trữ NVMe (thông qua InfiniBand hoặc RoCE) và bộ nhớ GPU, bỏ qua CPU và bộ nhớ hệ thống. Điều này giúp giảm độ trễ I/O, giải phóng CPU, tăng thông lượng dữ liệu, và cải thiện hiệu suất tổng thể cho các ứng dụng ngốn dữ liệu (data-intensive), đảm bảo dữ liệu đến GPU nhanh nhất có thể.
5.5. RoCE so với InfiniBand: Lựa chọn mạng cho trung tâm dữ liệu hiện đại:

Mặc dù InfiniBand là vua của HPC truyền thống, RoCE (RDMA over Converged Ethernet) đang trở nên rất phổ biến trong các trung tâm dữ liệu hyperscale và doanh nghiệp lớn vì khả năng tận dụng cơ sở hạ tầng Ethernet hiện có.
- RoCEv2: Cho phép chạy RDMA trên mạng Ethernet tiêu chuẩn, truyền dữ liệu trực tiếp vào bộ nhớ mà không cần qua CPU, tương tự như InfiniBand.
- Sự khác biệt chính: InfiniBand là một giao thức lớp 2 hoàn chỉnh được thiết kế cho hiệu suất cực cao và quản lý tắc nghẽn tối ưu, yêu cầu phần cứng chuyên dụng. RoCEv2 chạy trên Ethernet tiêu chuẩn (lớp 3) nhưng yêu cầu mạng Ethernet phải được cấu hình đúng cách (ví dụ: RoCE-ready switch, Lossless Ethernet) để đạt hiệu suất tối ưu.
- Tính phù hợp cho Workload: InfiniBand ưu việt hơn cho các cụm HPC và AI quy mô lớn, cực kỳ nhạy cảm với độ trễ. RoCEv2 thích hợp cho các trung tâm dữ liệu đám mây, AI quy mô trung bình, lưu trữ NVMe-oF, nơi chi phí và khả năng tích hợp với hạ tầng Ethernet hiện có là ưu tiên.
NVIDIA cung cấp cả hai giải pháp thông qua các HCA ConnectX đa năng, mang đến sự linh hoạt cho khách hàng.
5.6. Bảo mật và Cách ly trong Fabric của NVIDIA:
Trong môi trường trung tâm dữ liệu hiện đại, đặc biệt là các trung tâm dữ liệu đám mây hoặc multi-tenant, bảo mật và khả năng cách ly là tối quan trọng. NVIDIA đảm bảo an toàn cho dữ liệu và tài nguyên thông qua:
- Inline MACsec: Khả năng mã hóa dữ liệu ở lớp vật lý (data link layer) ngay trên các bộ điều hợp và switch InfiniBand/Ethernet của NVIDIA (ví dụ: trên ConnectX-7 và Quantum-2 switches), đảm bảo dữ liệu được mã hóa khi truyền qua mạng.
- DOCA TIES (Trusted and Isolated Execution Services): Một phần quan trọng của DOCA trên DPU, cho phép tạo ra các môi trường thực thi được bảo mật và cách ly cho từng người thuê hoặc từng ứng dụng, ngăn chặn việc truy cập trái phép.
Các công nghệ này giúp cách ly lưu lượng và tài nguyên giữa các người dùng hoặc ứng dụng khác nhau trên cùng một hạ tầng vật lý.
6. Thành phần Phần cứng và Phần mềm của Mellanox/NVIDIA
Hệ sinh thái này được hỗ trợ bởi một loạt các thành phần phần cứng và phần mềm chuyên dụng:
6.1. Thành phần phần cứng:
- Bộ điều hợp mạng (HCAs – Host Channel Adapters): Dòng sản phẩm NVIDIA Mellanox ConnectX (ví dụ: ConnectX-6, ConnectX-7, ConnectX-8 SuperNIC) là các card PCIe đa năng, hỗ trợ cả InfiniBand và Ethernet (VPI – Virtual Protocol Interconnect). Các HCA này tích hợp khả năng RDMA, offload các tác vụ mạng từ CPU, và hỗ trợ các tốc độ InfiniBand mới nhất (HDR, NDR, XDR).
- Bộ chuyển mạch (Switches):
- NVSwitch: Các chip chuyển mạch chuyên dụng cho NVLink, cho phép tạo ra các liên kết toàn bộ (all-to-all) giữa nhiều GPU trong một hệ thống hoặc giữa các hệ thống DGX.
- InfiniBand Switches: Dòng sản phẩm NVIDIA Quantum (ví dụ: Quantum-2) là các bộ chuyển mạch InfiniBand hiệu suất cao, cung cấp thông lượng NDR (400Gb/s), XDR (800Gb/s) và tích hợp công nghệ In-Network Computing (SHARP) để tăng tốc các phép toán collective.
- Cáp kết nối: Bao gồm cáp quang (AOC – Active Optical Cables) và cáp đồng Direct Attach Copper (DAC) Twinax, được tối ưu hóa cho hiệu suất và khoảng cách truyền dẫn khác nhau. Các module thu phát (transceiver) như QSFP, OSFP được sử dụng để chuyển đổi tín hiệu điện sang quang.
6.2. Thành phần phần mềm:
- NVIDIA Collective Communications Library (NCCL): Một thư viện tối ưu hóa cao cho các phép toán collective communication (ví dụ: all-reduce, broadcast) trên nhiều GPU và nhiều Server. NCCL tự động tận dụng NVLink để giao tiếp trong Server và InfiniBand (với RDMA và các plugin SHARP) để giao tiếp giữa các Server, mang lại hiệu suất tối ưu cho đào tạo học sâu.
- OpenFabrics Enterprise Distribution (OFED): Một bộ phần mềm mã nguồn mở cho Linux, cung cấp API (Application Programming Interface) và driver cho InfiniBand. Nó là nền tảng cho nhiều ứng dụng và thư viện HPC.
- NVIDIA Fabric Manager (FM) và NVLink Subnet Manager (NVLSM): Các công cụ quản lý để cấu hình, giám sát và tối ưu hóa các fabric InfiniBand và NVLink, bao gồm việc quản lý định tuyến và tài nguyên.
- HPC-X: Một bộ công cụ phần mềm toàn diện của NVIDIA, bao gồm các thư viện giao tiếp MPI, SHMEM, PGAS được tối ưu hóa cho InfiniBand, cùng với các gói tăng tốc khác.
- Unified Communication X (UCX): Một framework giao tiếp mã nguồn mở, hiệu suất cao, cung cấp các API cho giao tiếp điểm-điểm và collective trên nhiều loại phần cứng kết nối, bao gồm InfiniBand.
- Unified Collective Communication (UCC): Một framework mã nguồn mở mới hơn, tập trung vào các phép toán collective communication, được xây dựng trên UCX và tận dụng sâu hơn các khả năng In-Network Computing của InfiniBand.
7. Ví dụ Triển khai Thực tế và Hiệu suất Đạt được
Hệ sinh thái Mellanox của NVIDIA là nền tảng cho nhiều siêu máy tính và hệ thống AI hàng đầu thế giới:
- Siêu máy tính Summit (Oak Ridge National Laboratory): Từng là siêu máy tính nhanh nhất thế giới, sử dụng NVIDIA V100 GPU kết nối bằng NVLink trong mỗi server và InfiniBand EDR để kết nối các server lại với nhau, đạt hiệu suất đỉnh 200 petaFLOPS.
- NVIDIA DGX SuperPOD: Các hệ thống DGX SuperPOD (ví dụ: từ DGX A100 đến DGX H100) là minh chứng điển hình cho sự tích hợp này. Mỗi hệ thống DGX sử dụng NVLink (thông qua NVSwitch) để kết nối các GPU bên trong, và nhiều hệ thống DGX được kết nối với nhau bằng InfiniBand HDR hoặc NDR để tạo thành một siêu máy tính AI mạnh mẽ. Điều này cho phép các nhà nghiên cứu đào tạo các mô hình ngôn ngữ lớn (LLM) và các mô hình AI khác trong thời gian ngắn kỷ lục.
- Các Trung tâm dữ liệu Đám mây (Cloud Hyperscalers): Nhiều nhà cung cấp dịch vụ đám mây lớn đang triển khai InfiniBand và RoCE trong các cụm AI và HPC của họ để cung cấp hiệu suất vượt trội cho khách hàng.
- Nghiên cứu Khoa học và Y tế: Các viện nghiên cứu và phòng thí nghiệm sử dụng hệ thống Mellanox/NVIDIA để tăng tốc khám phá thuốc, mô phỏng khí hậu, nghiên cứu vật liệu và phân tích bộ gen.
Lợi ích Hiệu suất: Các triển khai này đã chứng minh những lợi ích đáng kể:
- Giảm thời gian đào tạo: Các mô hình học sâu có thể được đào tạo nhanh hơn hàng chục hoặc hàng trăm lần so với các mạng truyền thống.
- Tăng hiệu quả tính toán: Tối ưu hóa việc sử dụng GPU và CPU bằng cách giảm thời gian chờ đợi dữ liệu.
- Khả năng mở rộng chưa từng có: Cho phép mở rộng quy mô ứng dụng và cụm lên hàng nghìn Server mà vẫn duy trì hiệu suất tuyến tính.
- Đổi mới nhanh hơn: Thúc đẩy nghiên cứu và phát triển trong các lĩnh vực AI và HPC bằng cách cung cấp cơ sở hạ tầng mạnh mẽ.
Kết luận
Hệ sinh thái Nvidia Networking với sự kết hợp mạnh mẽ giữa NVLink và InfiniBand, đã định hình lại cách chúng ta xây dựng và vận hành các hệ thống điện toán hiệu năng cao và AI. NVLink cung cấp hiệu suất vượt trội cho giao tiếp nội bộ Server, trong khi InfiniBand mở rộng khả năng đó ra quy mô cụm và trung tâm dữ liệu. Cùng nhau, chúng tạo nên một hạ tầng mạng thống nhất, cho phép các nhà khoa học, kỹ sư và nhà phát triển giải quyết những thách thức phức tạp nhất của thế giới hiện đại. Sự phát triển liên tục của các chuẩn tốc độ cao hơn và việc tích hợp các tính năng tính toán trong mạng cho thấy NVIDIA đang tiếp tục dẫn đầu trong việc thúc đẩy ranh giới của điện toán và kết nối.
Phụ lục: Thông số kỹ thuật chi tiết của NVLink và InfiniBand
A. Thông số kỹ thuật chi tiết của NVLink:
| Phiên bản NVLink | Băng thông một chiều (Simplex bandwidth) / một liên kết | Tổng thông lượng Full-duplex / GPU | Khả năng trao đổi dữ liệu hai chiều tốc độ cao của NVSwitch | GPU hỗ trợ điển hình |
| NVLink 1.0 | 20 GB/s | 80 GB/s (4 liên kết trên P100) | Chưa hỗ trợ NVSwitch | Pascal (P100) |
| NVLink 2.0 | 25 GB/s | 300 GB/s (12 liên kết trên V100) | 2.4 TB/s (6 NVSwitch) | Volta (V100) |
| NVLink 3.0 | 25 GB/s (thường được gọi là Gen 3) | 600 GB/s (12 liên kết trên A100) | 4.8 TB/s (6 NVSwitch) | Ampere (A100) |
| NVLink 4.0 | 50 GB/s | 900 GB/s (18 liên kết trên H100) | 3.6 TB/s (6 NVSwitch) | Hopper (H100) |
| NVLink-C2C | Không áp dụng (Kết nối nội bộ chip) | 900 GB/s (Grace-Hopper Superchip) | Không áp dụng (Kết nối nội bộ chip) | Grace Hopper |
| NVLink 5.0 | 100 GB/s | 1.8 TB/s (18 liên kết trên B200) | 14.4 TB/s (8 NVSwitch) | Blackwell (B200) |
B. Thông số kỹ thuật chi tiết của InfiniBand:
| Tên chuẩn (Ký hiệu) | Tốc độ / làn (Gbit/s) | Tổng thông lượng Full-duplex (4x link) | Tổng thông lượng Full-duplex (8x link) | Tổng thông lượng Full-duplex (12x link) |
| SDR (Single Data Rate) | 2.5 | 10 Gbit/s | 20 Gbit/s | 30 Gbit/s |
| DDR (Double Data Rate) | 5 | 20 Gbit/s | 40 Gbit/s | 60 Gbit/s |
| QDR (Quad Data Rate) | 10 | 40 Gbit/s | 80 Gbit/s | 120 Gbit/s |
| FDR10 (Fourteen Data Rate 10) | 10.3125 | 41.25 Gbit/s | 82.5 Gbit/s | 123.75 Gbit/s |
| FDR (Fourteen Data Rate) | 14.0625 | 56.25 Gbit/s | 112.5 Gbit/s | 168.75 Gbit/s |
| EDR (Enhanced Data Rate) | 25.78125 | 100 Gbit/s | 200 Gbit/s | 300 Gbit/s |
| HDR (High Data Rate) | 50 | 200 Gbit/s | 400 Gbit/s | 600 Gbit/s |
| NDR (Next Data Rate) | 100 | 400 Gbit/s | 800 Gbit/s | 1200 Gbit/s |
| XDR (Extreme Data Rate) | 200 | 800 Gbit/s | 1600 Gbit/s | 2400 Gbit/s |
| GDR (Giga Data Rate) | 400 | 1600 Gbit/s | 3200 Gbit/s | 4800 Gbit/s |
Bài viết liên quan
- Fibre Channel (FC): Trục xương sống của hệ thống lưu trữ hiệu suất cao và tin cậy
- Mạng Ethernet: Giới thiệu toàn diện về các chuẩn kết nối
- NVIDIA NVLink Thế hệ thứ 5: Bước nhảy vọt về băng thông cho kỷ nguyên AI nghìn tỷ tham số
- GPU NVIDIA H200 NVL với kiến trúc Hopper nâng tầm ứng dụng AI cho các máy chủ thông dụng
- QNAP QSW-2104-2T-R2: Giải pháp mạng 10GbE tốc độ cao với chi phí hợp lý