
Vì sao các mô hình nghìn tỷ tham số lại thu hút sự chú ý?
Mô hình trí tuệ nhân tạo (AI) với hàng nghìn tỷ tham số đang nhận được sự quan tâm ngày càng lớn. Điều này bắt nguồn từ tiềm năng vượt trội của chúng trong các lĩnh vực:
- Xử lý ngôn ngữ tự nhiên: Dịch thuật, trả lời câu hỏi, tóm tắt văn bản và cải thiện độ trôi chảy.
- Hiểu bối cảnh dài hạn và khả năng đàm thoại: Mô hình có thể nắm bắt ngữ cảnh rộng hơn trong các cuộc hội thoại.
- Ứng dụng đa phương thức: Kết hợp ngôn ngữ, thị giác và giọng nói.
- Ứng dụng sáng tạo: Kể chuyện, sáng tác thơ, tạo code.
- Ứng dụng khoa học: Dự đoán cấu trúc protein và nghiên cứu bào chế thuốc.
- Cá nhân hóa: Phát triển tính cách riêng biệt và ghi nhớ ngữ cảnh người dùng.
Mặc dù lợi ích của mô hình nghìn tỷ tham số rất hứa hẹn, việc huấn luyện và triển khai chúng tốn kém tài nguyên tính toán và chi phí. Do đó, các hệ thống điện toán hiệu quả, tiết kiệm chi phí và năng lượng, được thiết kế để suy luận theo thời gian thực là điều cần thiết cho việc triển khai rộng rãi. NVIDIA GB200 NVL72 chính là một hệ thống đáp ứng được yêu cầu này.

Mô hình Mixture of Experts (MoE) là một ví dụ điển hình. Chúng phân tán khối lượng tính toán giữa nhiều chuyên gia, đồng thời huấn luyện trên hàng nghìn GPU bằng cách sử dụng song song mô hình (model parallelism) và song song đường ống (pipeline parallelism), giúp hệ thống hoạt động hiệu quả hơn.
Tuy nhiên, để vượt qua những thách thức kỹ thuật, các cụm GPU cần đạt đến một cấp độ song song tính toán mới, bộ nhớ tốc độ cao và giao tiếp hiệu suất cao. Kiến trúc rack-scale NVIDIA GB200 NVL72 chính là giải pháp, chi tiết sẽ được đề cập trong bài viết tiếp theo.
Thiết kế rack-scale cho siêu máy tính AI exascale
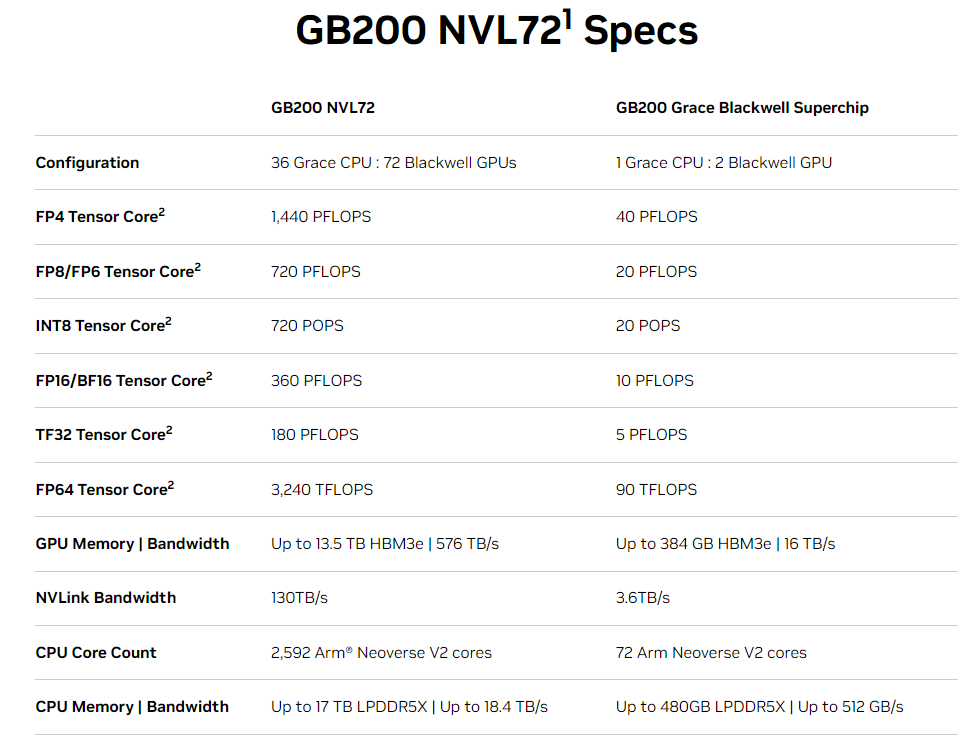
Trái tim của GB200 NVL72 là NVIDIA GB200 Grace Blackwell Superchip. Nó kết nối hai GPU NVIDIA Blackwell Tensor Core hiệu suất cao và CPU NVIDIA Grace với giao diện NVLink-Chip-to-Chip (C2C) cung cấp băng thông hai chiều 900 GB/giây. Nhờ NVLink-C2C, các ứng dụng có thể truy cập thống nhất vào một không gian bộ nhớ. Điều này giúp đơn giản hóa lập trình và hỗ trợ nhu cầu bộ nhớ lớn hơn của các mô hình ngôn ngữ lớn (LLMs) nghìn tỷ tham số, mô hình transformer cho các tác vụ đa phương thức, mô hình cho mô phỏng quy mô lớn và mô hình tổng hợp cho dữ liệu 3D.
Khay tính toán GB200 dựa trên thiết kế NVIDIA MGX mới. Nó chứa hai CPU Grace và bốn GPU Blackwell. GB200 có tấm lạnh và kết nối cho làm mát bằng chất lỏng, hỗ trợ PCIe gen 6 cho mạng tốc độ cao và đầu nối NVLink cho hộp cáp NVLink. Khay tính toán GB200 cung cấp hiệu suất AI 80 petaflop và bộ nhớ nhanh 1.7 TB.

Những vấn đề lớn nhất đòi hỏi phải có đủ số lượng GPU Blackwell đột phá để hoạt động song song hiệu quả, do đó, chúng phải giao tiếp với băng thông cao, độ trễ thấp và luôn bận rộn.
Hệ thống quy mô giá GB200 NVL72 hỗ trợ hiệu quả mô hình song song cho 18 nút điện toán sử dụng Hệ thống chuyển mạch NVIDIA NVLink với chín khay chuyển đổi NVLink và hộp cáp kết nối GPU và bộ chuyển mạch.
NVIDIA GB200 NVL36 và NVL72
NVIDIA GB200 là nền tảng tính toán mới hỗ trợ kết nối 36 hoặc 72 GPU trong cùng một hệ thống NVLink. Mỗi giá đỡ chứa 18 nút tính toán được thiết kế dựa trên NVIDIA MGX và hệ thống chuyển mạch NVLink.
DGX SuperPOD cung cấp hai tùy chọn cấu hình:
- GB200 NVL36: Mỗi giá đỡ chứa 36 GPU, tương ứng với 18 nút tính toán đơn lẻ GB200.
- GB200 NVL72: Mỗi giá đỡ chứa 72 GPU, tương ứng với 18 nút tính toán kép GB200 (hoặc tổng 576 GPU trên 2 giá đỡ với 18 nút tính toán đơn lẻ GB200).
Điểm nổi bật của GB200 NVL72 là khả năng kết nối nhiều GPU với mật độ cao sử dụng hộp cáp đồng, giúp đơn giản hóa vận hành hệ thống. Ngoài ra, hệ thống làm mát bằng chất lỏng giúp giảm thiểu 25 lần chi phí và năng lượng tiêu thụ.

Fifth-generation NVLink and NVLink Switch System
NVIDIA GB200 NVL72 giới thiệu NVLink thế hệ thứ năm, kết nối lên đến 576 GPU trong một miền NVLink với tổng băng thông hơn 1 PB/s và 240 TB bộ nhớ nhanh. Mỗi khay chuyển mạch NVLink cung cấp 144 cổng NVLink ở 100 GB, vì vậy chín chuyển mạch kết nối đầy đủ mỗi trong 18 cổng NVLink trên mỗi trong số 72 GPU Blackwell.
Sự tiến bộ đột phá với 1.8 TB/s của thông lượng song hướng trên mỗi GPU là hơn 14 lần băng thông của PCIe Gen5, cung cấp giao tiếp tốc độ cao không gián đoạn cho các mô hình lớn phức tạp nhất hiện nay.

NVLink qua các thế hệ
Sự đổi mới hàng đầu trong ngành của NVIDIA về SerDes tốc độ cao, tiết kiệm năng lượng thúc đẩy sự tiến bộ của giao tiếp GPU-to-GPU, bắt đầu từ việc giới thiệu NVLink để tăng tốc giao tiếp đa GPU ở tốc độ cao. Băng thông GPU-to-GPU của NVLink là 1.8 TB/s, gấp 14 lần băng thông của PCIe.
NVLink thế hệ thứ năm nhanh gấp 12 lần so với thế hệ đầu tiên ở 160 GB/s, được giới thiệu vào năm 2014. Giao tiếp GPU-to-GPU của NVLink đã đóng một vai trò quan trọng trong việc mở rộng hiệu suất đa GPU trong lĩnh vực Trí tuệ Nhân tạo và Tính toán cao hiệu suất.
Sự tiến bộ về băng thông GPU kết hợp với sự mở rộng mũi tên của miền NVLink đã tăng tổng băng thông của một miền NVLink lên tới 900 lần kể từ năm 2014, lên đến 1 PB/s cho một miền NVLink 576 GPU Blackwell.
Hiệu suất và các tình huống sử dụng thực tế
Khả năng tính toán và truyền thông của GB200 NVL72 vượt xa mọi nền tảng trước đây, giúp biến những thách thức lớn trong lĩnh vực AI và HPC trở thành những bài toán thực tế.
Huấn luyện AI
GB200 tích hợp bộ máy Transformer thế hệ thứ hai nhanh hơn với độ chính xác FP8. So với cùng số lượng GPU NVIDIA H100, hệ thống 32k GB200 NVL72 cho phép huấn luyện các mô hình ngôn ngữ lớn như GPT-MoE-1.8T nhanh hơn 4 lần.
Suy luận AI
GB200 mang đến các tính năng tân tiến và bộ máy Transformer thế hệ thứ hai, giúp tăng tốc các tác vụ suy luận LLM. So với thế hệ H100 trước đó, GB200 cung cấp tốc độ nhanh hơn 30 lần cho các ứng dụng đòi hỏi nhiều tài nguyên như GPT-MoE 1.8T. Thành tựu này đạt được nhờ thế hệ Tensor Core mới, hỗ trợ độ chính xác FP4 cùng nhiều lợi thế đi kèm với NVLink thế hệ thứ năm.
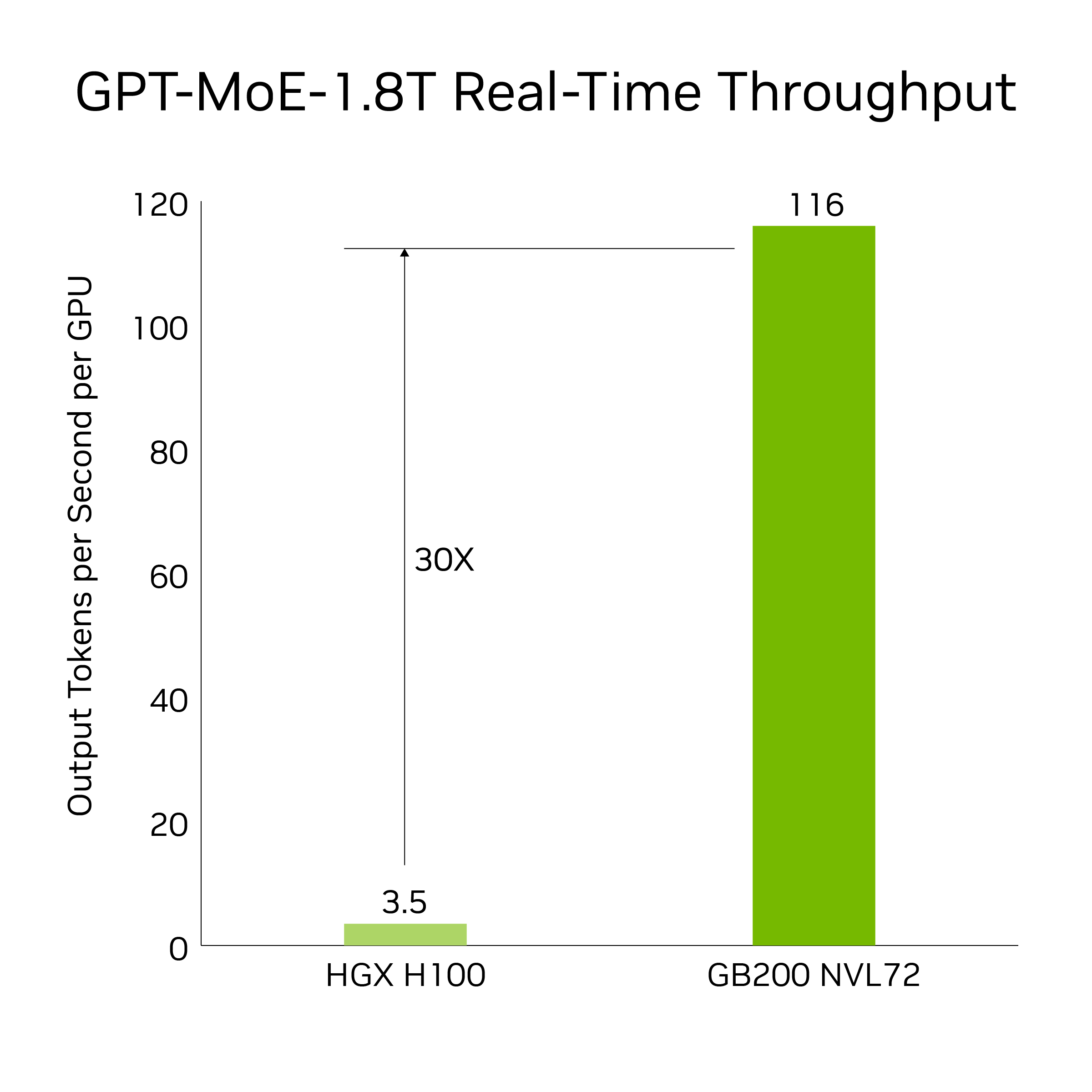
Lưu ý: Kết quả dựa trên độ trễ token-to-token = 50 ms; độ trễ token đầu tiên tính theo thời gian thực = 5,000 ms; độ dài chuỗi đầu vào = 32,768; độ dài chuỗi đầu ra = 1,024 output, so sánh hiệu suất trên mỗi GPU của 8 hệ thống HGX H100 tám hướng làm mát bằng khí (tổng 64 GPU NVIDIA Hopper) với mạng InfiniBand so với 18 Superchip GB200 làm mát bằng chất lỏng (NVL36). Hiệu suất dự kiến có thể thay đổi.
Tốc độ nhanh hơn 30 lần này là khi so sánh 64 GPU NVIDIA Hopper được mở rộng qua NVLink 8 hướng và InfiniBand với 32 GPU Blackwell trong GB200 NVL72 sử dụng GPT-MoE-1.8T.
Xử lý Dữ liệu
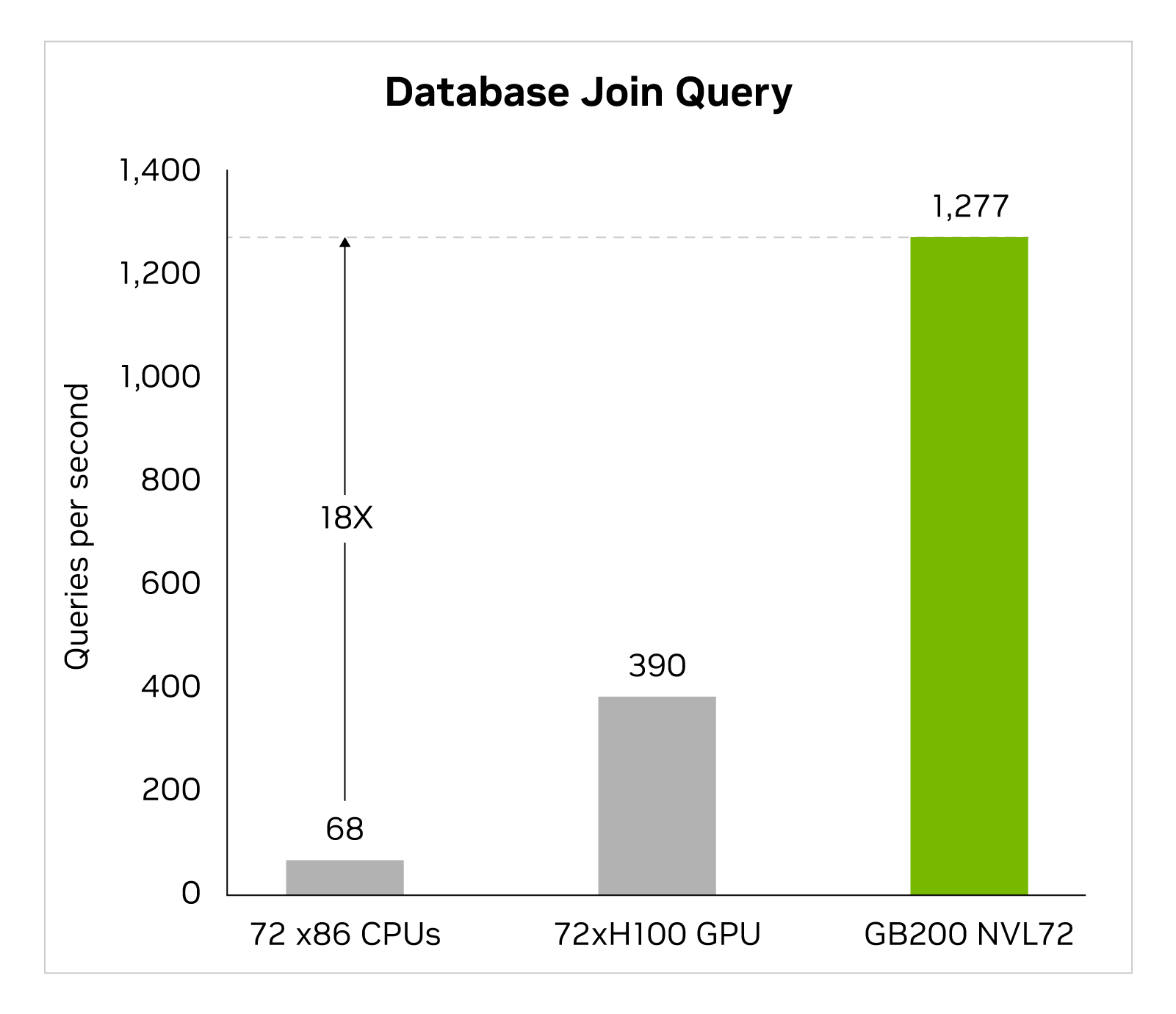
Phân tích dữ liệu lớn giúp các tổ chức mở khóa những hiểu biết và đưa ra quyết định thông minh hơn. Các tổ chức liên tục tạo ra dữ liệu ở quy mô lớn và phụ thuộc vào các kỹ thuật nén khác nhau để giảm thiểu các chướng ngại về băng thông và tiết kiệm chi phí lưu trữ. Để xử lý các bộ dữ liệu này một cách hiệu quả trên GPU, kiến trúc Blackwell giới thiệu một động cơ giải nén phần cứng có thể giải nén dữ liệu nén một cách tự nhiên ở quy mô và tăng tốc độ toàn bộ quy trình phân tích dữ liệu từ đầu đến cuối. Động cơ giải nén này tự natively hỗ trợ việc giải nén dữ liệu được nén bằng các định dạng nén LZ4, Deflate và Snappy.
Động cơ giải nén tăng tốc các hoạt động lõi bộ nhớ. Nó cung cấp hiệu suất lên đến 800 GB/s và cho phép Grace Blackwell thực hiện nhanh hơn 18 lần so với CPUs (Sapphire Rapids) và nhanh hơn 6 lần so với GPU Tensor Core NVIDIA H100 cho các chỉ số truy vấn.
Với băng thông bộ nhớ cao tốc độ lên đến 8 TB/s và kết nối NVlink-Chip-to-Chip (C2C) tốc độ cao của Grace CPU, động cơ tăng tốc toàn bộ quy trình truy vấn cơ sở dữ liệu. Điều này dẫn đến hiệu suất hàng đầu trong tất cả các trường hợp sử dụng phân tích dữ liệu và khoa học dữ liệu. Điều này cho phép các tổ chức có được thông tin chuyên sâu một cách nhanh chóng đồng thời giảm chi phí.
Mô phỏng dựa trên vật lý
Mô phỏng dựa trên vật lý vẫn là trụ cột chính trong thiết kế và phát triển sản phẩm. Từ máy bay và tàu hỏa đến cầu cống, vi mạch silic và thậm chí là dược phẩm, việc kiểm tra và cải tiến sản phẩm thông qua mô phỏng tiết kiệm hàng tỷ đô la.
Vi mạch tích hợp cụ thể cho ứng dụng được thiết kế gần như hoàn toàn trên CPU trong một quy trình làm việc dài và phức tạp, bao gồm phân tích tương tự để xác định điện áp và dòng điện. Trình mô phỏng Cadence SpectreX là một ví dụ về trình giải. Hình dưới đây cho thấy SpectreX chạy nhanh gấp 13 lần trên GB200 so với CPU x86.
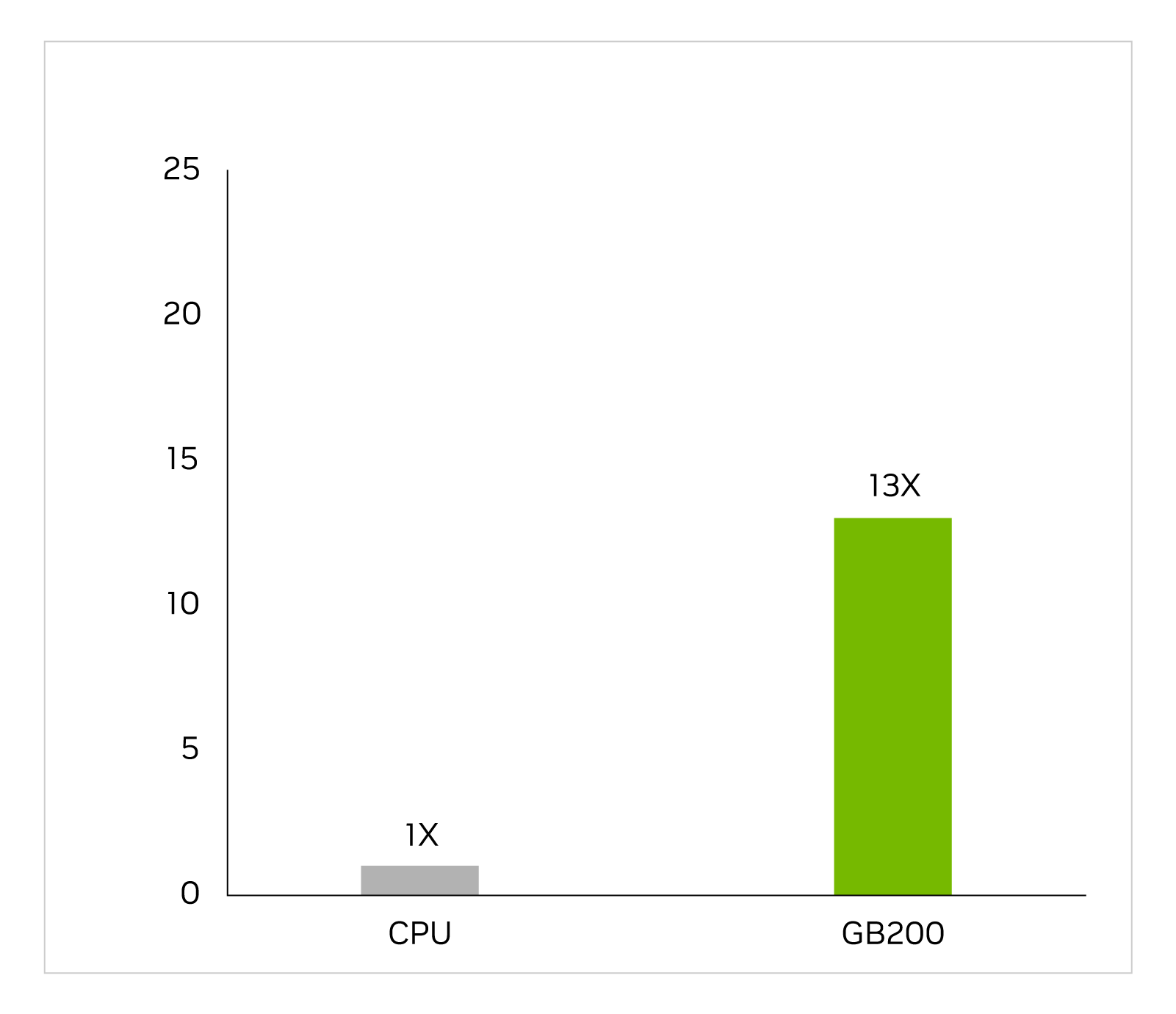
Cadence SpectreX (bộ giải mạch Spice) | CPU: 16 nhân AMD Milan 75F3 tập dữ liệu: Thiết kế KeithC TSMC N5 | Dự đoán hiệu suất cho GB200 có thể thay đổi
Trong hai năm qua, ngành công nghiệp ngày càng chuyển hướng đến mô phỏng động lực học tính toán được tăng tốc bằng GPU (CFD) là một công cụ chính. Kỹ sư và nhà thiết kế thiết bị sử dụng nó để nghiên cứu và dự đoán hành vi của thiết kế của họ. Cadence Fidelity, một bộ giải mô phỏng eddy lớn (LES), chạy mô phỏng nhanh gấp đến 22 lần trên GB200 so với CPU x86.
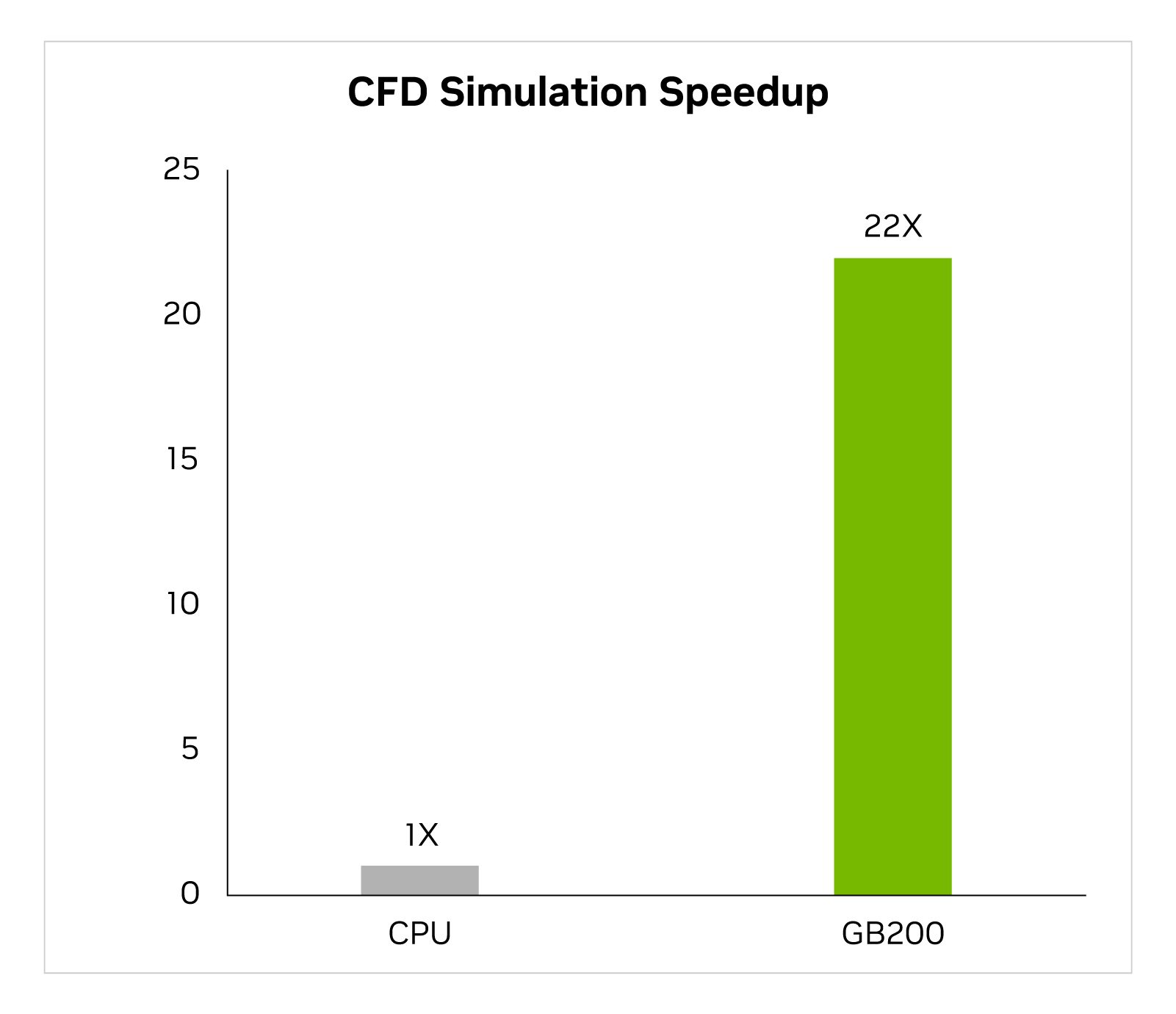
Cadence Fidelity (LES CFD Solver) | CPU: 16 nhân AMD Milan 75F3 Tập dữ liệu: GearPump 2M cell | Dự đoán hiệu suất cho GB200 có thể thay đổi
Chúng tôi mong chờ khám phá các khả năng của Cadence Fidelity trên GB200 NVL72. Với khả năng tăng cường song song và 30 TB bộ nhớ trên mỗi rack, chúng tôi nhằm bắt capture các chi tiết dòng chảy chưa từng được ghi lại trước đây.
Tóm tắt
Để tổng kết, chúng ta đã xem xét về thiết kế tỷ lệ rack GB200 NVL72 và, đặc biệt, hiểu về khả năng đặc biệt của nó để kết nối 72 GPU Blackwell qua một miền NVIDIA NVLink duy nhất. Điều này giảm thiểu chi phí giao tiếp mà ta thường gặp khi mở rộng qua các mạng truyền thống. Như một kết quả, suy luận thời gian thực cho một mô hình MoE LLM với 1.8T tham số trở nên khả thi và việc huấn luyện mô hình đó nhanh gấp 4 lần.

Hoạt động của 72 GPU Blackwell kết nối qua NVLink với 30 TB bộ nhớ thống nhất qua một mạng tính toán 130 TB/s tạo ra một siêu máy tính Trí tuệ Nhân tạo exaFLOP trong một rack duy nhất. Đó chính là NVIDIA GB200 NVL72.
→ Để biết thêm thông tin, hãy xem lại bài phát biểu quan trọng của GTC 24 tại đây: https://thegioimaychu.vn/blog/ai-hpc/tom-tat-buoi-keynote-cua-nvidia-gtc-2024-p19257/
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale