
Các mô hình học sâu (Deep Learning) hiện đại có memory footprint lớn. Nhiều GPU không đủ VRAM để đào tạo chúng. Trong bài này, chúng tôi xác định GPU nào có thể đào tạo các network tiên tiến nhất mà không gây ra lỗi bộ nhớ. Chúng tôi cũng đo điểm benchmark hiệu suất đào tạo của mỗi GPU.
Tóm tắt
Các GPU sau có thể đào tạo tất cả các mô hình ngôn ngữ và hình ảnh hiện tại, kể từ tháng 2 năm 2020:
- RTX 8000: 48 GB VRAM, ~$5,500.
- RTX 6000: 24 GB VRAM, ~$4,000.
- Titan RTX: 24 GB VRAM, ~$2,500.
Các GPU sau có thể đào tạo hầu hết (nhưng không phải tất cả) các mô hình hiện tại:

- RTX 2080 Ti: 11 GB VRAM, ~$1,150. *
- GTX 1080 Ti: 11 GB VRAM, ~$800 refurbished. *
- RTX 2080: 8 GB VRAM, ~$720. *
- RTX 2070: 8 GB VRAM, ~$500. *
GPU sau không phù hợp để đào tạo các mô hình hiện tại:
- RTX 2060: VRAM 6 GB, ~ $ 359.
* Việc đào tạo trên các GPU này đòi hỏi kích thước lô nhỏ, do đó, độ chính xác của mô hình thấp hơn.
Mô hình hình ảnh (Image model)
Kích thước lô tối đa trước khi hết bộ nhớ
| Mô hình / GPU | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
|---|---|---|---|---|---|---|---|---|
| NasNet Lớn | 4 | số 8 | số 8 | số 8 | số 8 | 32 | 32 | 64 |
| DeepLabv3 | 2 | 2 | 2 | 4 | 4 | số 8 | số 8 | 16 |
| Yolo v3 | 2 | 4 | 4 | 4 | 4 | số 8 | số 8 | 16 |
| Pix2Pix HD | 0 * | 0 * | 0 * | 0 * | 0 * | 1 | 1 | 2 |
| StyleGAN | 1 | 1 | 1 | 4 | 4 | số 8 | số 8 | 16 |
| MaskRCNN | 1 | 2 | 2 | 2 | 2 | số 8 | số 8 | 16 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Hiệu suất, được đo bằng hình ảnh được xử lý mỗi giây
| Mô hình / GPU | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
|---|---|---|---|---|---|---|---|---|
| NasNet Large | 7.3 | 9,2 | 10.9 | 10.1 | 12.9 | 16.3 | 13,9 | 15.6 |
| DeepLabv3 | 4,4 | 4,82 | 5,8 | 5,43 | 7.6 | 9,01 | 8,02 | 9,12 |
| Yolo v3 | 7,8 | 9,15 | 11,08 | 11,03 | 14,12 | 14,22 | 12.8 | 14,22 |
| Pix2Pix HD | 0,0 * | 0,0 * | 0,0 * | 0,0 * | 0,0 * | 0,73 | 0,71 | 0,71 |
| StyleGAN | 1,92 | 2,25 | 2.6 | 2,97 | 4,22 | 4,94 | 4,25 | 4,96 |
| MaskRCNN | 2,85 | 3,33 | 4.36 | 4,42 | 5.22 | 6,3 | 5,54 | 5,84 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Mô hình ngôn ngữ (Language model)
Kích thước lô tối đa trước khi hết bộ nhớ
| Mô hình / GPU | Đơn vị | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
|---|---|---|---|---|---|---|---|---|---|
| Transformer Big | Token | 0 * | 2000 | 2000 | 4000 | 4000 | 8000 | 8000 | 16000 |
| Conv. Seq2Seq | Token | 0 * | 2000 | 2000 | 3584 | 3584 | 8000 | 8000 | 16000 |
| unsupMT | Token | 0 * | 500 | 500 | 1000 | 1000 | 4000 | 4000 | 8000 |
| Cơ sở BERT | Sequence | số 8 | 16 | 16 | 32 | 32 | 64 | 64 | 128 |
| BERT Finetune | Sequence | 1 | 6 | 6 | 6 | 6 | 24 | 24 | 48 |
| MT-DNN | Sequence | 0 * | 1 | 1 | 2 | 2 | 4 | 4 | số 8 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Hiệu suất
| Mô hình / GPU | Các đơn vị | 2060 | 2070 | 2080 | 1080 Ti | 2080 Ti | Titan RTX | RTX 6000 | RTX 8000 |
|---|---|---|---|---|---|---|---|---|---|
| Transformer Big | Words/sec | 0 * | 4597 | 6317 | 6207 | 7780 | 8498 | 7407 | 7507 |
| Conv. Seq2Seq | Words/sec | 0 * | 7721 | 9950 | 5870 | 15671 | 21180 | 20500 | 22450 |
| unsupMT | Words/sec | 0 * | 1010 | 1212 | 1824 | 2025 | 3850 | 3725 | 3735 |
| BERT Base | Ex./sec | 34 | 47 | 58 | 60 | 83 | 102 | 98 | 94 |
| BERT Finetue | Ex./sec | 7 | 15 | 18 | 17 | 22 | 30 | 29 | 27 |
| MT-DNN | Ex./sec | 0 * | 3 | 4 | số 8 | 9 | 18 | 18 | 28 |
* GPU không có đủ bộ nhớ để chạy mô hình.
Kết quả được chuẩn hóa bởi Quadro RTX 8000

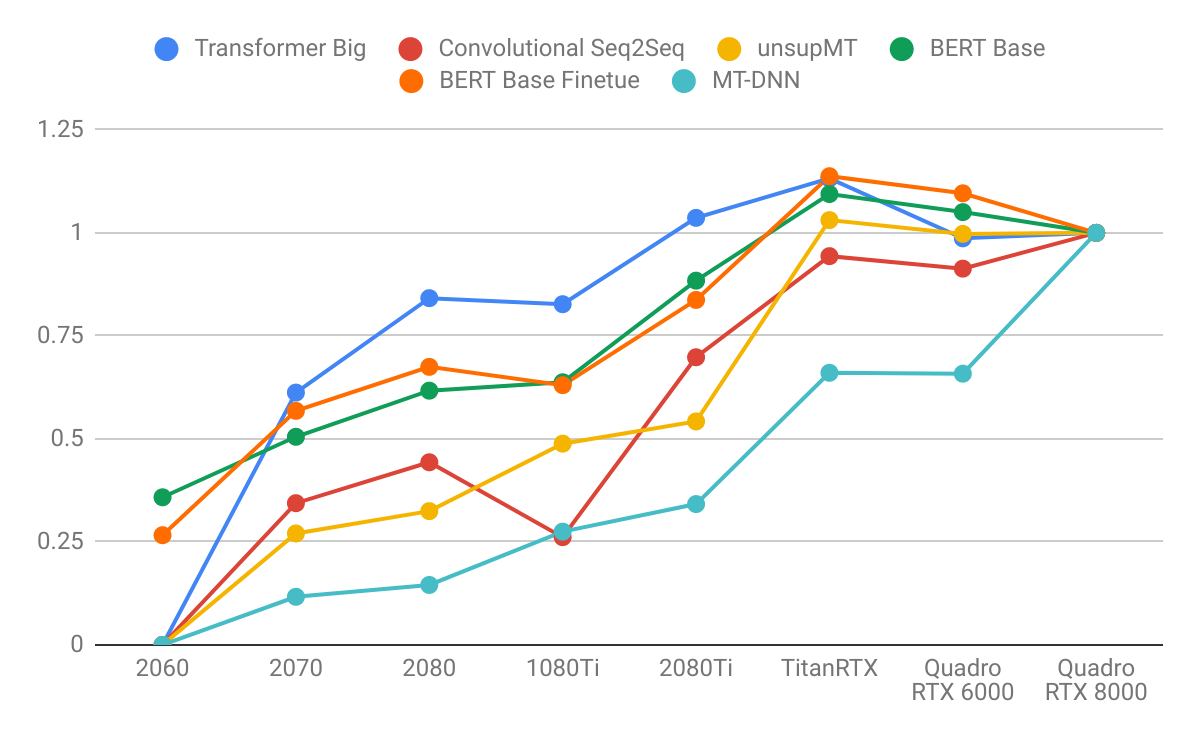 Hình 2. Thông lượng đào tạo được chuẩn hóa theo Quadro RTX 8000. Trái: Image model. Phải: Language model.
Hình 2. Thông lượng đào tạo được chuẩn hóa theo Quadro RTX 8000. Trái: Image model. Phải: Language model.
Kết luận
- Các mô hình ngôn ngữ được hưởng lợi nhiều hơn từ bộ nhớ GPU lớn hơn các mô hình hình ảnh. Lưu ý cách sơ đồ bên phải dốc hơn bên trái. Điều này chỉ ra rằng các mô hình ngôn ngữ bị ràng buộc nhiều bộ nhớ hơn và các mô hình hình ảnh bị giới hạn tính toán nhiều hơn.
- GPU có VRAM cao hơn có hiệu suất tốt hơn vì sử dụng kích thước lô lớn hơn giúp bão hòa các lõi CUDA.
- GPU có VRAM cao hơn cho phép kích thước lô lớn hơn tương ứng. Tính toán ngược phong bì mang lại kết quả hợp lý: GPU có VRAM 24 GB có thể phù hợp với lô lớn hơn ~ 3x so với GPU có 8 GB VRAM.
- Các mô hình ngôn ngữ chiếm bộ nhớ không cân xứng cho các chuỗi dài vì sự chú ý là bậc hai đối với độ dài chuỗi.
Khuyến nghị về GPU
- RTX 2060 (6 GB): nếu bạn muốn khám phá việc học sâu trong thời gian rảnh rỗi.
- RTX 2070 hoặc 2080 (8 GB): nếu bạn nghiêm túc về việc học sâu, nhưng ngân sách GPU của bạn là 600-800 đô la. Tám GB VRAM có thể phù hợp với phần lớn các mô hình.
- RTX 2080 Ti (11 GB): nếu bạn nghiêm túc về việc học sâu và ngân sách GPU của bạn là ~ 1.200 đô la. RTX 2080 Ti nhanh hơn ~ 40% so với RTX 2080.
- Titan RTX và Quadro RTX 6000 (24 GB): nếu bạn đang làm việc trên các mô hình SOTA rộng rãi, nhưng không có ngân sách cho việc chứng minh trong tương lai có sẵn với RTX 8000.
- Quadro RTX 8000 (48 GB): bạn đang đầu tư vào tương lai và thậm chí có thể đủ may mắn để nghiên cứu học tập sâu SOTA vào năm 2020.
Chú thích
Image Models
| Model | Task | Dataset | Image Size | Repo |
|---|---|---|---|---|
| NasNet Large | Image Classification | ImageNet | 331×331 | Github |
| DeepLabv3 | Image Segmentation | PASCAL VOC | 513×513 | GitHub |
| Yolo v3 | Object Detection | MSCOCO | 608×608 | GitHub |
| Pix2Pix HD | Image Stylization | CityScape | 2048×1024 | GitHub |
| StyleGAN | Image Generation | FFHQ | 1024×1024 | GitHub |
| MaskRCNN | Instance Segmentation | MSCOCO | 800×1333 | GitHub |
Language Models
| Model | Task | Dataset | Repo |
|---|---|---|---|
| Transformer Big | Supervised machine translation | WMT16_en_de | GitHub |
| Conv. Seq2Seq | Supervised machine translation | WMT14_en_de | GitHub |
| unsupMT | Unsupervised machine translation | NewsCrawl | GitHub |
| BERT Base | Language modeling | enwik8 | GitHub |
| BERT Finetune | Question and answer | SQUAD 1.1 | GitHub |
| MT-DNN | GLUE | GLUE | GitHub |
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent