
NVIDIA H200 NVL là một dòng GPU (Bộ xử lý đồ họa) mạnh mẽ được thiết kế đặc biệt cho các tác vụ trí tuệ nhân tạo (AI) tạo sinh và điện toán hiệu năng cao (HPC). Nó được xem là một trong những GPU xử lý AI hàng đầu thế giới, mang đến những cải tiến đáng kể về bộ nhớ và băng thông so với các thế hệ trước. Đây được xem là giải pháp hàng đầu cho các tổ chức và doanh nghiệp có nhu cầu cao về năng lực tính toán cho AI và HPC, giúp đẩy nhanh quá trình nghiên cứu, phát triển và triển khai các ứng dụng tiên tiến.
Bài viết này nêu bật những cải tiến của mẫu GPU PCIe NVIDIA H200 NVL, các khuyến nghị về cấu hình máy chủ và thành phần mạng tối ưu cũng như các biện pháp tốt nhất để triển khai ở quy mô lớn dựa trên Kiến trúc tham chiếu dành cho doanh nghiệp (NVIDIA Enterprise Reference Architectures – Enterprise RA) của NVIDIA .
NVIDIA H200 NVL tăng tốc AI cho các máy chủ doanh nghiệp thông dụng
NVIDIA H200 NVL là nền tảng để phát triển và triển khai tải xử lý AI và HPC, từ các tác nhân AI cho dịch vụ khách hàng và nhận dạng lỗ hổng đến phát hiện gian lận tài chính, nghiên cứu y tế và phân tích địa chấn. NVIDIA H200 NVL cung cấp khả năng tăng tốc AI cho các máy chủ doanh nghiệp thông dụng với tốc độ suy luận mô hình ngôn ngữ lớn (LLM) nhanh hơn tới 1,7 lần và hiệu suất cao hơn 1,3 lần trên các ứng dụng HPC so với H100 NVL. Những cải tiến đằng sau H200 NVL được trình bày chi tiết trong các phần sau.
Bộ nhớ được nâng cấp
H200 NVL sử dụng cùng kiến trúc với H100 NVL. Nhưng H200 NVL được hưởng lợi từ việc nâng cấp đáng kể về băng thông bộ nhớ và dung lượng với 141 GB HBM3e, tăng 1,5 lần về dung lượng và 1,4 lần về băng thông so với H100 NVL.
Những cải tiến này giúp cho các mô hình lớn hơn có thể vừa với GPU và dữ liệu di chuyển vào và ra khỏi bộ nhớ nhanh hơn, giúp tạo ra thông lượng cao hơn và nhiều token hơn mỗi giây. Do bộ nhớ lớn hơn, bạn cũng có thể tạo các phân vùng GPU đa phiên bản (MIG) lớn hơn để chạy nhiều tải xử lý riêng biệt trong cùng một GPU.
Khả năng của thế hệ NVLink mới
H200 NVL hỗ trợ kết nối NVLink 4 chiều mới, cung cấp băng thông lên tới 1,8 TB/giây và bộ nhớ HBM3e kết hợp là 564 GB—cung cấp bộ nhớ gấp 3 lần so với H100 NVL trong cấu hình NVLink 2 chiều.
Ngoài ra, H200 NVL hỗ trợ ghép nối với cầu nối NVLink 2 chiều, cung cấp băng thông kết nối GPU-to-GPU 900 GB/giây—tăng 50% so với H100 NVL và nhanh hơn 7 lần so với PCIe Gen5.
| Tính năng | NVIDIA H100 NVL | NVIDIA H200 NVL | Cải tiến |
| Ký ức | 94GB HBM3 | 141GB HBM3e | Công suất 1,5x |
| Băng thông bộ nhớ | 3,35 TB/giây | 4,8 TB/giây | Nhanh hơn 1,4 lần |
| NVLink tối đa (BW) | 2 chiều (600 GB/giây) | 4 chiều (1,8 TB/giây) | Nhanh hơn 3 lần |
| Bộ nhớ tối đa | 188GB | 564GB | Lớn hơn 3 lần |
Bảng 1. So sánh thông số kỹ thuật giữa H100 NVL và H200 NVL
Sản phẩm bao gồm NVIDIA AI Enterprise
H200 NVL bao gồm giấy phép đăng ký 5 năm cho NVIDIA AI Enterprise . Nền tảng phần mềm thuần đám mây này cung cấp một bộ công cụ, framework, SDK và microservice NVIDIA NIM toàn diện để chuẩn hóa quá trình phát triển và triển khai các ứng dụng AI cấp doanh nghiệp.
Với khả năng truy cập vào các dịch vụ suy luận vi mô NVIDIA NIM và NVIDIA Blueprints, sức mạnh của NVIDIA AI Enterprise cùng với H200 NVL cung cấp con đường nhanh nhất để xây dựng và vận hành các ứng dụng AI tùy biến đồng thời đảm bảo hiệu suất mô hình cao nhất.
Cấu hình được đề xuất cho H200 NVL
Chương trình NVIDIA Enterprise RA gần đây đã được mở rộng để bao gồm H200 NVL. Mỗi NVIDIA Enterprise RA cung cấp các khuyến nghị về phần cứng và phần mềm đầy đủ để xây dựng hạ tầng điện toán tăng tốc an toàn, có khả năng mở rộng, hiệu suất cao và có hướng dẫn chi tiết về cấu hình máy chủ, cụm và mạng tối ưu cho tải xử lý AI hiện đại.
Cốt lõi của mỗi Enterprise RA là một máy chủ NVIDIA-Certified System được tối ưu hóa, tuân theo một mẫu thiết kế theo quy định để đảm bảo hiệu suất tối ưu khi triển khai trong môi trường cụm. Hiện tại có ba loại cấu hình máy chủ mà Enterprise RA được thiết kế: PCIe Optimized 2-4-3, PCIe Optimized 2-8-5 và hệ thống HGX. Đối với các cấu hình PCIe Optimized (ví dụ: 2-8-5), các chữ số tương ứng đề cập đến số lượng socket (CPU), số lượng GPU và số lượng bộ điều hợp mạng.
NVIDIA Enterprise RA dành cho H200 NVL tận dụng cấu hình tham chiếu PCIe Optimized 2-8-5.
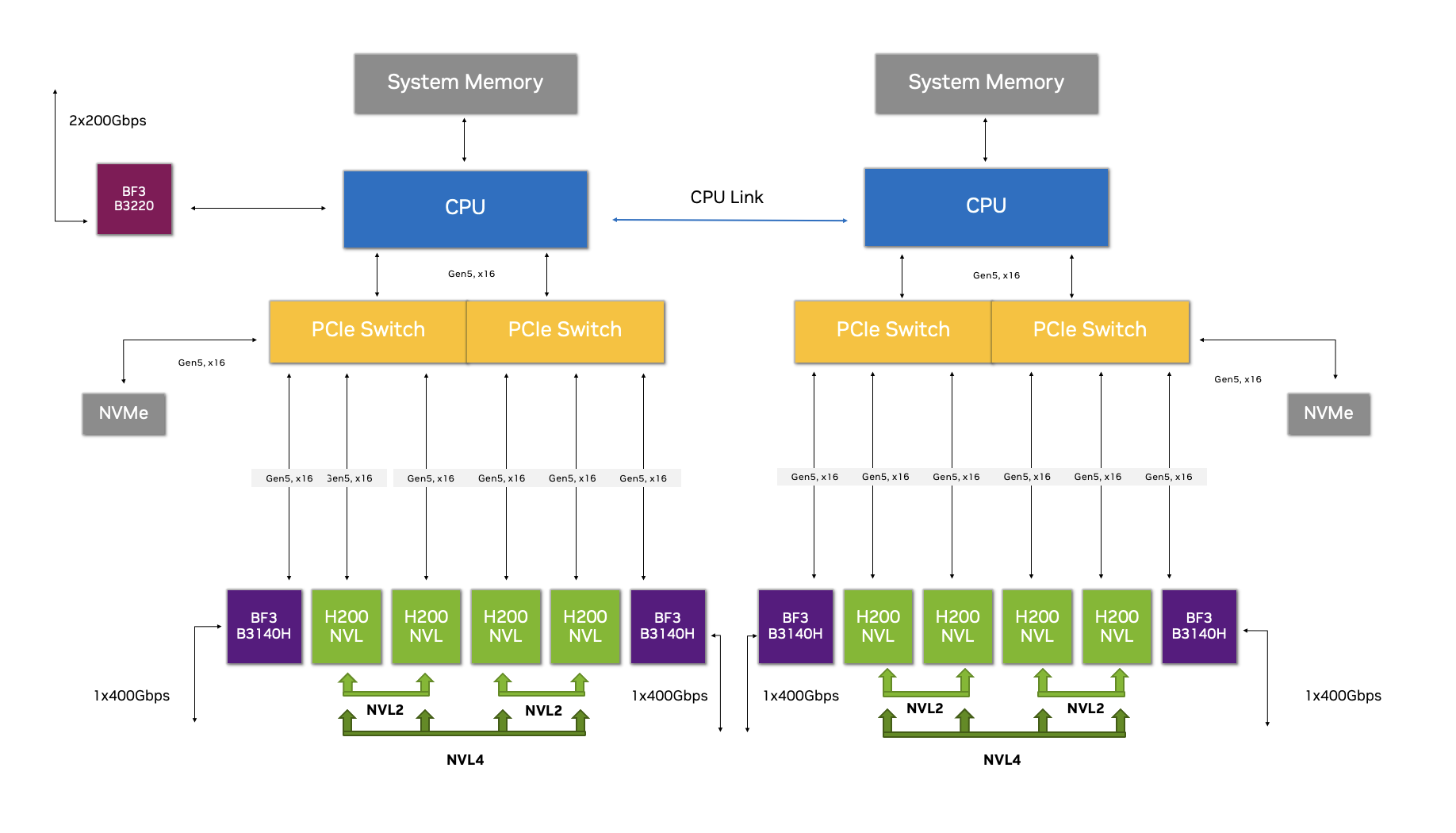 Hình 1. Cấu hình PCIe Optimized 2-8-5 với NVIDIA H200 NVL
Hình 1. Cấu hình PCIe Optimized 2-8-5 với NVIDIA H200 NVL
Cấu hình này có gì đặc biệt?
Cấu hình PCIe Optimized 2-8-5 với H200 NVL giúp giảm độ trễ, yêu cầu ít sử dụng CPU hơn và tăng băng thông mạng cho các hoạt động thời gian thực khi xử lý dữ liệu hiệu quả là điều rất quan trọng. Cấu hình này thực hiện điều đó bằng cách cho phép tạo nhiều đường dẫn truyền dữ liệu để tối đa hóa giao tiếp GPU-to-GPU.
Đường dẫn dữ liệu đầu tiên là NVLink, tạo thành cầu nối kết nối, cho phép giao tiếp tốc độ cao, độ trễ thấp giữa các GPU trong cùng một miền bộ nhớ. Đường dẫn thứ hai là với mạng Ethernet NVIDIA Spectrum-X tốc độ cao, tích hợp RoCE Remote Memory Direct Access (RDMA) để cung cấp đường dẫn giao tiếp hiệu quả, độ trễ thấp giữa các GPU trong cụm.
Một nền tảng có hiệu quả chưa từng có trong việc di chuyển dữ liệu là kết quả của việc kết hợp khả năng NVLink 4 chiều của H200 NVL với cấu hình được tối ưu hóa này. Cho dù thông qua NVLink hay Spectrum-X với RoCE, giao tiếp giữa các GPU trong máy chủ và cụm có thể bỏ qua CPU và bus PCIe — mang lại ít chi phí hơn, thông lượng cao hơn và độ trễ thấp hơn.
NVIDIA GPUDirect cho phép các network adapter và trình điều khiển lưu trữ đọc và ghi trực tiếp vào và ra khỏi bộ nhớ GPU, giảm tải cho CPU. GPUDirect tồn tại như một khái niệm bao trùm cho GPUDirect Storage, GPUDirect Remote Direct Memory Access, GPUDirect Peer to Peer (P2P) và GPUDirect Video — tất cả đều được trình bày thông qua một bộ API toàn diện được thiết kế để giảm độ trễ.
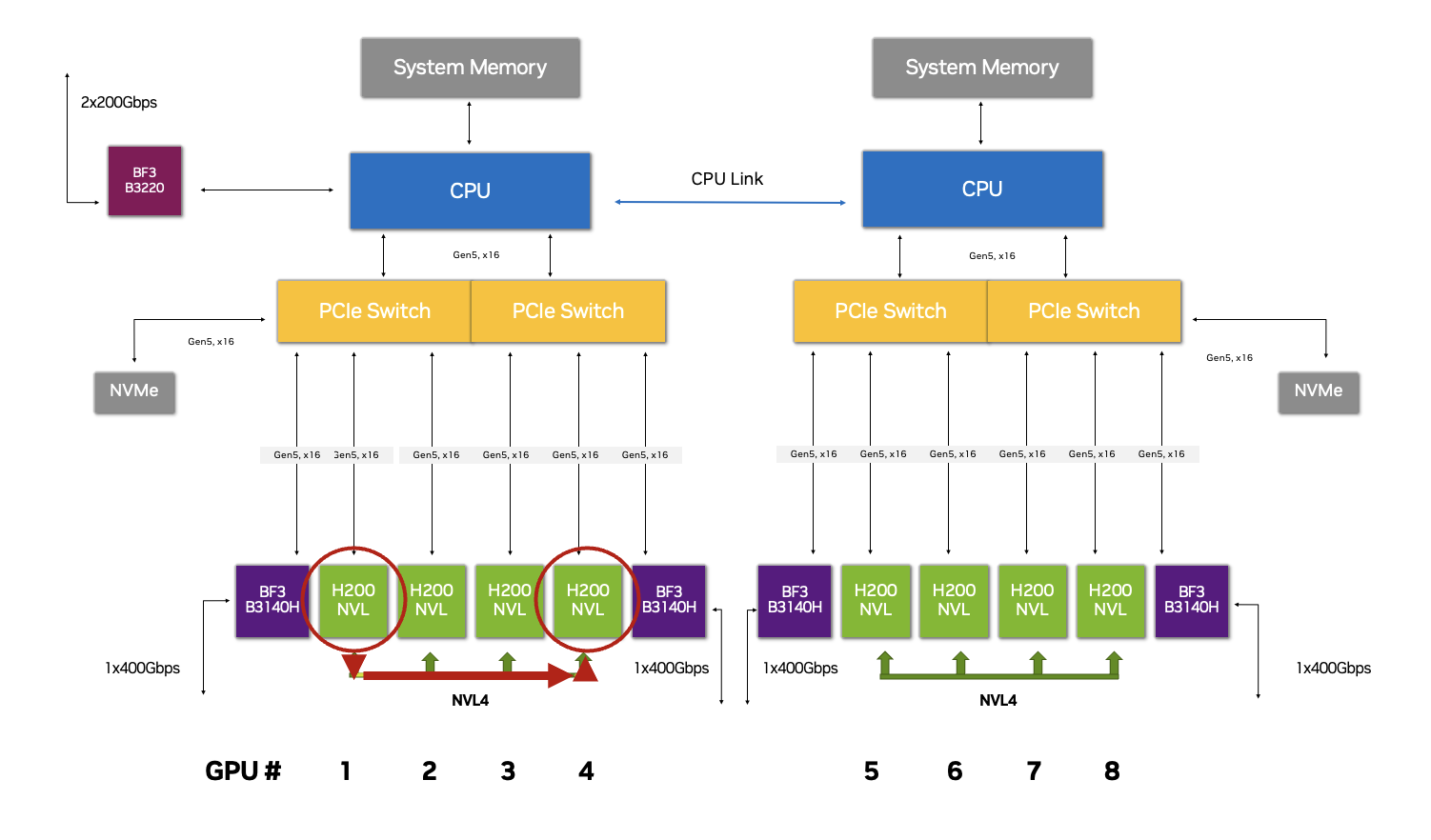 Hình 2. GPU 1 cần giao tiếp với GPU 4 trong cấu hình 2-8-5 này, với dữ liệu truyền qua NVLink
Hình 2. GPU 1 cần giao tiếp với GPU 4 trong cấu hình 2-8-5 này, với dữ liệu truyền qua NVLink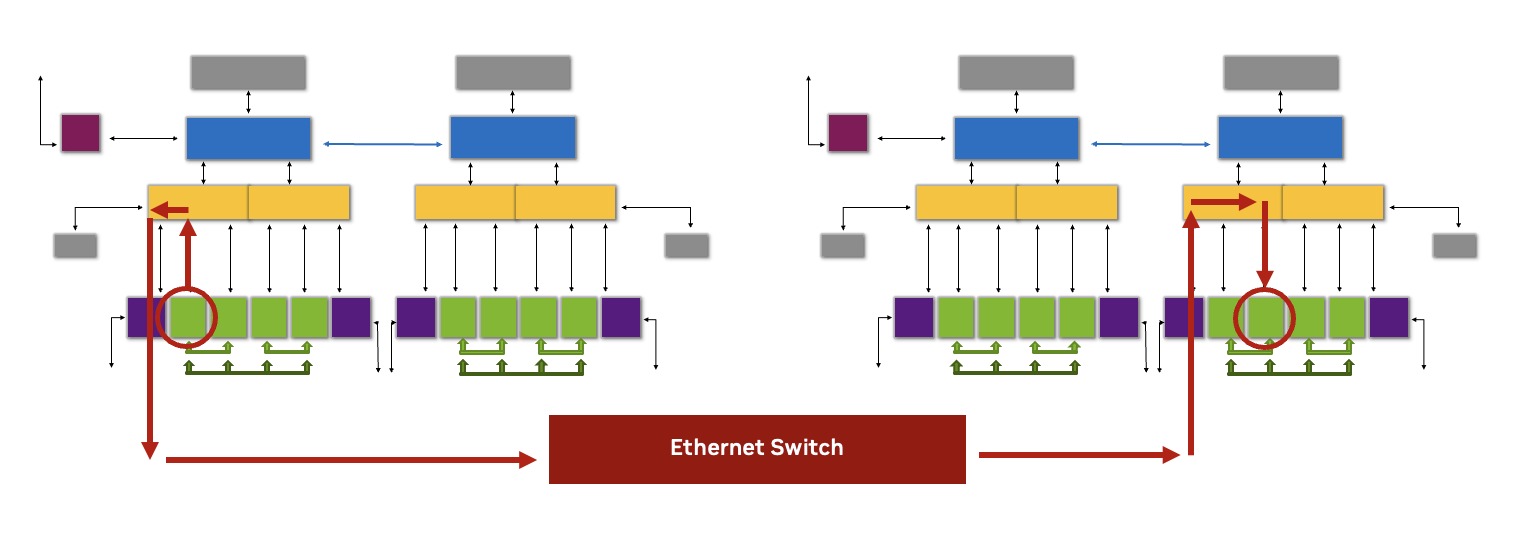 Hình 3. GPU cần giao tiếp với GPU ở một node khác trong cấu hình 2-8-5 này, với việc truyền dữ liệu giữa các GPU tận dụng RoCE thông qua NVIDIA Spectrum Ethernet Switch
Hình 3. GPU cần giao tiếp với GPU ở một node khác trong cấu hình 2-8-5 này, với việc truyền dữ liệu giữa các GPU tận dụng RoCE thông qua NVIDIA Spectrum Ethernet Switch
Tối đa hóa hiệu suất của H200 NVL ở quy mô lớn
Chúng ta đã tìm hiểu về các tính năng của H200 NVL và cấu hình máy chủ tối ưu, phần dưới đây sẽ khám phá các công nghệ bổ sung trong NVIDIA Enterprise RA dành cho H200 NVL mà các doanh nghiệp có thể khai thác để tối đa hóa hiệu suất khi triển khai các hệ thống này trong môi trường cụm.
Mạng Ethernet NVIDIA Spectrum-X dành cho AI
Tận dụng một nền tảng dựa trên RDMA cung cấp các bước nhảy ngắn nhất qua mạng cho các ứng dụng phải giao tiếp qua các máy chủ cụm. Đối với nền tảng mạng tính toán (east-west), Enterprise RA cho H200 NVL bao gồm các khuyến nghị thiết kế dựa trên nền tảng NVIDIA Spectrum-X Ethernet cho AI, bao gồm bộ chuyển mạch Spectrum-4 và BlueField-3 SuperNIC.
Để cung cấp hiệu suất mạng cao nhất, Enterprise RA khuyến nghị sử dụng BlueField-3 SuperNIC chuyên dụng với kết nối 400 gigabit mỗi giây (GB/giây) cho mỗi hai GPU H200 NVL trong cụm. BlueField-3 DPU trong mỗi máy chủ cho phép hỗ trợ RoCE cho mạng lưu trữ và quản lý (north-south).
Thư viện truyền thông tập thể NVIDIA (NCCL)
Enterprise RA cho H200 NVL sử dụng NVIDIA Collective Communications Library (NCCL) để cung cấp khả năng giao tiếp hiệu quả, độ trễ thấp và khả năng mở rộng cho các tải xử lý yêu cầu giao tiếp hiệu quả giữa nhiều GPU, chẳng hạn như AI phân tán, học sâu và điện toán hiệu suất cao (HPC).
Được tối ưu hóa hoàn toàn cho nền tảng điện toán tăng tốc NVIDIA, bộ công cụ phần mềm chuyên dụng này tăng cường giao tiếp giữa nhiều GPU trong một cụm, cung cấp các chức năng được tối ưu hóa cho phép chia sẻ và xử lý dữ liệu hiệu quả. Cho dù trên cùng một máy chủ hay phân phối trên nhiều máy chủ, NCCL đều hoạt động với GPU NVL H200 và công nghệ NVLink để xác định và đánh giá vô số đường dẫn truyền dữ liệu và chọn tuyến đường tối ưu.
Để làm ví dụ, các ứng dụng AI agentic được xây dựng bằng NVIDIA Blueprints sẽ được hưởng lợi đáng kể từ tối ưu hóa NCCL. Các tác nhân AI này bao gồm nhiều microservice NIM được phân bổ trên nhiều GPU, nghĩa là giao tiếp có độ trễ thấp rất quan trọng đối với hiệu suất.
| Công nghệ | Khả năng |
| Spectrum-X (phần cứng và phần mềm) | Giải pháp toàn diện tích hợp cả phần cứng và phần mềm để tối ưu hóa tải xử lý AI. Kết hợp với H200 NVL, Spectrum-X cung cấp khả năng truyền dữ liệu và giao tiếp hiệu quả thông qua Bộ chuyển mạch Ethernet Spectrum-4, BlueField-3 SuperNIC, Bộ phát triển phần mềm Spectrum-X (SDK) và NCCL. |
| NCCL (phần mềm) | NCCL cung cấp các hoạt động truyền thông được tối ưu hóa cho H200 NVL. NCCL có nhận thức về cấu trúc, có thể tối ưu hóa công nghệ kết nối GPU cơ bản như NVLink và được hưởng lợi từ các thiết kế cấu trúc được tối ưu hóa theo đường ray, trong đó NIC được kết nối với các công tắc lá cụ thể. Thư viện tải NCCL là một phần của NCCL và cho phép tải các hoạt động truyền thông tập thể xuống mạng, giảm tải cho CPU và cải thiện hiệu suất. |
| Cầu NVLink (phần cứng) | Công nghệ kết nối tốc độ cao, thế hệ thứ tư được sử dụng trong H200 NVL. NVLink thế hệ thứ tư cung cấp băng thông cao 900 GB/giây cho giao tiếp GPU-to-GPU, cao hơn đáng kể so với kết nối điểm-điểm. |
| Bộ công cụ phát triển phần mềm (SDK) (phần mềm) | Spectrum-X SDK hoạt động với H200 NVL và bao gồm Cumulus Linux, SONiC thuần túy, NetQ và NVIDIA DOCA software frameworks. Các SDK này hoạt động tổng hợp để đảm bảo hiệu suất trên nhiều tải xử lý AI mà không bị suy giảm. |
| GPU trực tiếp RDMA qua Ethernet hội tụ (RoCE) | Giao thức mạng cho phép truyền trực tiếp bộ nhớ sang bộ nhớ giữa các máy chủ và mảng lưu trữ qua mạng Ethernet, bỏ qua sự tham gia của CPU. Độ trễ trong giao tiếp giữa các hệ thống NVL của H200 được giảm nhờ RoCE trong khi NVLink giảm thời gian phản hồi cho giao tiếp GPU trong hệ thống. |
Bảng 2. Các công nghệ mạng chính được khai thác bởi H200 NVL
Xây dựng với NVIDIA H200 NVL
Với hiệu suất cao và khả năng nâng cao, phiên bản mới nhất này của thế hệ NVIDIA Hopper thúc đẩy đáng kể khả năng tăng tốc AI và HPC cấp doanh nghiệp. Các doanh nghiệp sẵn sàng chuyển đổi hạ tầng trung tâm dữ liệu của mình có thể khám phá các nền tảng thế hệ tiếp theo trong nhiều cấu hình khác nhau có H200 NVL thông qua hệ sinh thái đối tác hệ thống toàn cầu của NVIDIA.
NVIDIA Enterprise RA cho H200 NVL hiện đã có sẵn cho các đối tác xây dựng các giải pháp trung tâm dữ liệu có hiệu suất cao, có thể mở rộng. Enterprise RA này giảm độ phức tạp khi thiết kế và triển khai hạ tầng trung tâm dữ liệu bằng cách cung cấp các khuyến nghị thiết kế toàn diện và đã được chứng minh để triển khai H200 NVL ở quy mô lớn.
Tìm hiểu thêm về Kiến trúc tham chiếu dành cho doanh nghiệp của NVIDIA .
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale