
Trí tuệ nhân tạo (AI) đã và đang ảnh hưởng đến nhiều khía cạnh của cuộc sống hàng ngày với sự tiến bộ của các công nghệ AI, cả về phần cứng và phần mềm. AI luôn tiếp tục phát triển, với các sản phẩm mới và hiệu quả hơn được phát hành và nâng cấp. Từ đó, các mô hình AI tiên tiến đang thay đổi cuộc sống của chúng ta một cách nhanh chóng. Cơ sở hạ tầng điện toán tăng tốc đang phát triển với tốc độ chưa từng có trong tất cả các phân khúc thị trường. Cơ sở hạ tầng linh hoạt, mạnh mẽ và có khả năng mở rộng quy mô lớn với GPU thế hệ tiếp theo đang tạo điều kiện cho một chương mới của AI.
Nền tảng hỗ trợ các ứng dụng AI mới này là cơ sở hạ tầng điện toán được tăng tốc tinh vi cung cấp năng lượng cho các hệ thống, bộ lưu trữ và kết nối mạng, tạo ra trải nghiệm người dùng mới ở mọi nơi trên thị trường. Trung tâm của cơ sở hạ tầng là thế hệ GPU mới nhất (phần cứng cốt lõi của nhiều giải pháp AI), nâng cao khả năng triển khai AI và các ứng dụng điện toán hiệu suất cao.


Hợp tác chặt chẽ với NVIDIA, Supermicro cung cấp nhiều lựa chọn hệ thống được NVIDIA chứng nhận nhất, mang lại hiệu suất cải tiến và hiệu suất cao nhất từ các doanh nghiệp nhỏ đến các cụm đào tạo AI thống nhất, quy mô lớn với GPU NVIDIA H100 Tensor Core mới.
GPU NVIDIA H100 Tensor Cores là một bước tiến đáng kể trong quá trình phát triển của GPU. Với hiệu suất gấp tới 30 lần so với GPU NVIDIA A100 hiện tại, các ứng dụng AI sáng tạo trước đây không thể thực hiện được giờ đây sẽ hoạt động hoàn hảo, giảm đáng kể thời gian đào tạo AI. Ngoài ra, các ứng dụng HPC được dự đoán sẽ chạy gấp 7 lần so với các thế hệ trước sử dụng GPU NVIDIA A100

Các hệ thống Supermicro NVIDIA H100 đạt được hiệu suất đào tạo gấp chín lần so với thế hệ trước đối với một số mô hình AI thách thức nhất, cắt giảm thời gian đào tạo một tuần xuống chỉ còn 20 giờ. Các hệ thống Supermicro với GPU H100 PCI-E và HGX H100 mới, cũng như GPU L40 mới được công bố, mang đến kết nối PCI-E Gen5, Mạng NVLink và NVLink thế hệ thứ tư để mở rộng quy mô và thẻ CNX mới hỗ trợ GPUDirect RDMA và Lưu trữ với phần mềm NVIDIA Magnum IO và NVIDIA AI Enterprise.
Supermicro Product Lines for AI and HPC Based on NVIDIA H100
Supermicro có một lịch sử lâu dài trong việc cung cấp các hệ thống tiên tiến nhất cho cơ sở hạ tầng điện toán tăng tốc và các ứng dụng HPC. Ngoài việc kết hợp các công nghệ GPU mới nhất của NVIDIA, Supermicro còn cung cấp GPU với nhiều thiết kế được tối ưu hóa cho khối lượng công việc cụ thể. Bằng cách kết hợp GPU từ các thiết bị biên với máy chủ GPU trung tâm dữ liệu rất mạnh, các ứng dụng có thể được đặt gần nơi tạo dữ liệu hơn, giảm độ trễ và tối ưu hóa các ứng dụng đào tạo và suy luận AI.

Dòng máy chủ, máy trạm và thiết bị biên Supermicro GPU được thiết kế và tối ưu hóa để đáp ứng nhu cầu của các chuyên gia kỹ thuật yêu cầu các công nghệ CPU và GPU mới nhất. Các hệ thống không thỏa hiệp này được thiết kế cho các CPU và GPU mới nhất, với các tùy chọn làm mát bằng chất lỏng khi cần thiết. Mặc dù nhiều máy chủ Supermicro có thể chứa một GPU đơn hoặc kép trên mỗi nút, nhưng các máy chủ GPU được NVIDIA chứng nhận của Supermicro được thiết kế cho tối đa 10 GPU.
Các máy chủ này yêu cầu nỗ lực kỹ thuật chi tiết để đảm bảo rằng lượng làm mát phù hợp được thiết kế trong hệ thống để xử lý nhu cầu nhiệt cao cấp của GPU. Supermicro đang cung cấp đa dạng các máy chủ hỗ trợ sử dụng GPU NVIDIA H100 hoạt động dựa trên sức mạnh tính toán của các bộ xử lý mới nhất của Intel hoặc AMD thế hệ thứ 4.
Next-Gen 8U Universal GPU System
Thích hợp cho các mô hình đào tạo AI và HPC quy mô lớn nhất hiện nay, nổi bật với khả năng tản nhiệt vượt trội với âm thanh giảm, nhiều I/O hơn và dung lượng lưu trữ lớn

- GPU: NVIDIA HGX H100 8-GPU (Codenamed Hopper)
- GPU Featureset: With 80 billion transistors the H100 is the world’s most advanced chip ever built and delivers up to 9 times faster performance for AI training
- CPU: Dual Processors
- Memory: ECC DDR5 up to 4800MT/s
- Drives: Up to 24 Hot-Swap NVMe/SATA

Next-Gen 4U/5U Universal GPU System
Được tối ưu hóa cho các trường hợp sử dụng và khối lượng công việc Suy luận AI. Mô-đun theo thiết kế cho tính linh hoạt cao nhất.

- GPU: NVIDIA HGX H100 4-GPU
- GPU Featureset : H100 HGX is able to accelerate AI Inference by up to 30 times more performance over previous generation
- CPU: Dual Processors
- Memory: ECC DDR5 up to 4800MT/s
- Drives: Up to 8 Hot-Swap NVMe U.2 connect to PCI-E Switch or 10 Hot-Swap 2.5” SATA/SAS

Next-Gen 4U 10GPU PCI-E Gen 5 System
Thiết kế linh hoạt cho AI và khối lượng công việc chuyên sâu về đồ họa, hỗ trợ tối đa 10 GPU NVIDIA.

- GPU: Up to 10 double-width PCI-E GPUs per node
- GPU Featureset: The NVIDIA L40 PCI-E GPUs in this system are ideal for driving media and graphic workloads
- CPU: Dual Processors
- Memory: ECC DDR5 up to 4800MT/s
- Drives: 24 Hot-Swap Bays

Next-Gen 4U 4GPU System
Được tối ưu hóa cho cộng tác 3D Metaverse, Nhà khoa học dữ liệu và Người tạo nội dung. Có sẵn ở cả Rackmount và Workstation
- GPU: NVIDIA PCI-E H100 4-GPU
- GPU Featureset: NVIDIA H100 GPUs are the world’s first accelerator with confidential computing capability, increasing confidence in secure collaboration
- CPU: Dual Processors
- Memory: ECC DDR5 up to 4800MT/s
- Drives: 8 Hot-Swap 3.5” drive bays, up to 8 NVMe drives, 2x M.2 (SATA or NVMe)
NVIDIA H100 Highlights

NVIDIA H100 là GPU mới nhất trong chuỗi dài các GPU được tối ưu hóa của NVIDIA. GPU NVIDIA H100 Tensor Core, được hỗ trợ bởi kiến trúc Hopper, mang đến một bước tiến nhảy vọt trong việc tăng tốc khối lượng công việc AI và HPC. Ngoài ra, H100 bảo mật dữ liệu thông qua khả năng Điện toán mật của NVIDIA. Do đó, các nhà phát triển ứng dụng có thể phân phối và triển khai các mô hình AI độc quyền của họ ở quy mô lớn trên cơ sở hạ tầng dùng chung hoặc từ xa.
NVIDIA H100 đặc biệt sử dụng các công nghệ tiên tiến sau:
• 80 GB of HBM3 memory, including a 50 MB of L2 cache – nhiều dữ liệu hơn có thể được thực hiện trên. Để tận dụng tối đa hiệu suất điện toán đó, H100 chứa bộ nhớ HBM3 với băng thông bộ nhớ 3terabyte mỗi giây (TB/giây) hàng đầu, tăng 50 phần trăm so với thế hệ trước. Sự kết hợp giữa bộ nhớ HBM nhanh hơn này và bộ nhớ đệm lớn hơn cung cấp khả năng tăng tốc các mô hình AI có cường độ tính toán cao nhất.
• PCI-E-5.0 – Giao tiếp nhanh hơn với CPU – H100 là GPU đầu tiên hỗ trợ PCIe Gen5, cung cấp tốc độ cao nhất có thể ở mức 128GB/giây (hai chiều). Giao tiếp nhanh này cho phép kết nối tối ưu với các CPU hiệu suất cao nhất và NVIDIA ConnectX-7 SmartNIC và BlueField-3 DPU, cho phép tăng tốc mạng Ethernet lên đến 400Gb/giây hoặc NDR 400Gb/giây InfiniBand cho khối lượng công việc HPC và AI an toàn.
• Có thể liên kết tối đa 256 GPU với Hệ thống chuyển mạch NVIDIA NVLink. Công nghệ này tăng tốc mọi thứ, từ khối lượng công việc quy mô exascale với Công cụ biến áp chuyên dụng cho các mô hình ngôn ngữ nghìn tỷ tham số cho đến các phân vùng GPU đa phiên bản (MIG) có kích thước phù hợp.
Sau đây cho thấy hiệu suất của GPU NVIDIA H100: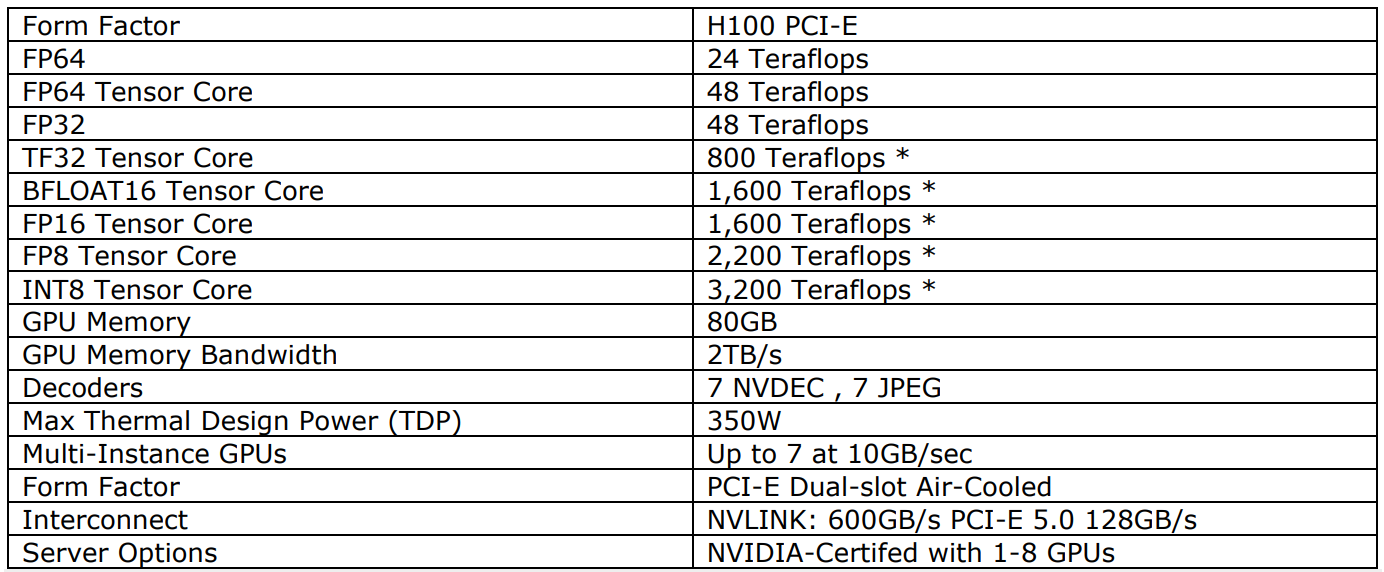
Từ chế độ xem hiệu suất, H100 nhanh hơn, hiệu quả hơn nhiều so với NVIDIA A100 trong một số tác vụ và ứng dụng. Các biểu đồ sau (do NVIDIA cung cấp) cho thấy NVIDIA H100 nhanh hơn thế nào khi so sánh với NVIDIA A100.
Workload Matching
Một số khối lượng công việc sẽ được tối ưu hóa với các sản phẩm khác nhau từ Supermicro. Dưới đây là kết quả chung về khối lượng công việc AI và HPC được tối ưu hóa với GPU NVIDIA H100.

→ Xem thêm: Các sản phẩm GPU NVIDA tối ưu cho vGPU
→ Xem thêm: Các sản phẩm Supermicro tối ưu cho vGPU
→ Xem thêm: NVIDIA AI Enterprise và GPU NVIDIA cho NVAIE
 Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Supermicro là nhà sản xuất toàn cầu về giải pháp máy chủ hiệu suất cao, là nhà cung cấp hàng đầu các giải pháp điện toán xanh toàn diện cho HPC, Data Center, Cloud Computing, Enterprise IT, Hadoop / Big Data và Hệ thống nhúng trên toàn thế giới.
Với kinh nghiệm làm nhà phân phối chính thức máy chủ Supermicro từ năm 2005, Nhất Tiến Chung (NTC) tiên phong đem đến các giải pháp hạ tầng CNTT dựa trên danh mục phần cứng đa dạng và tối ưu chi phí đầu tư nhất từ Supermicro. Các máy chủ GPU và máy chủ lưu trữ hiệu năng cao chuyên dụng cho AI, Deep Learning, cấu hình tùy biến theo nhu cầu, được nhiều đối tác lựa chọn cho dự án của mình. Vui lòng liên hệ để được tư vấn giải pháp, hoàn toàn miễn phí.
Bạn muốn trở thành đối tác bán hàng Supermicro của NTC?
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- Hướng dẫn triển khai máy chủ GPU tại chỗ trong các phòng máy doanh nghiệp
- NVIDIA ConnectX-8 SuperNIC: Đột phá kiến trúc hạ tầng AI với PCIe Gen6
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- NVIDIA hiện đang cung cấp những dòng GPU nào?