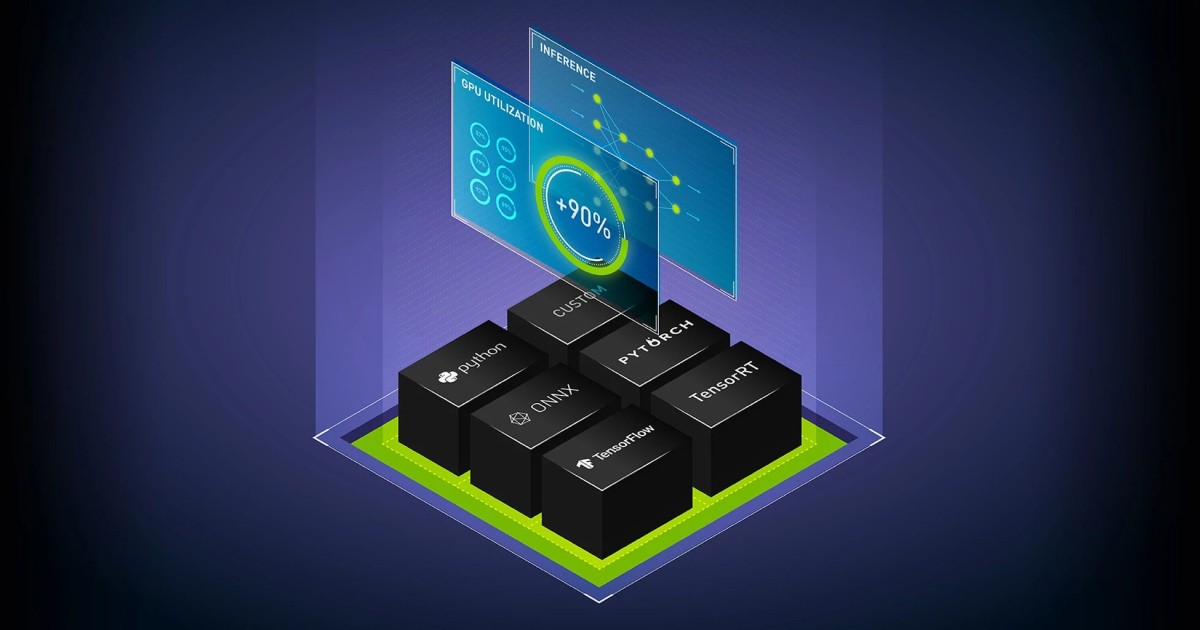
Suy luận dành cho mọi tác vụ AI
Chạy suy luận trên các mô hình Học máy (ML) hoặc Học sâu (DL) đã được đào tạo từ bất kỳ framework nào trên bất kỳ bộ xử lý nào – GPU, CPU hay các loại khác – với NVIDIA Triton Inference Server. Là một phần của nền tảng NVIDIA AI và được bao gồm trong bộ giải pháp NVIDIA AI Enterprise, Triton Inference Server là phần mềm nguồn mở, giúp tiêu chuẩn hóa việc triển khai và chạy các mô hình AI trên mọi workload.
Khám phá các lợi ích của Triton Inference Server

Hỗ trợ tất cả các framework đào tạo và suy luận
Triển khai các mô hình AI trên bất kỳ framework chính nào với Triton Inference Server – bao gồm TensorFlow, PyTorch, Python, ONNX, NVIDIA TensorRT, RAPIDS cuML, XGBoost, scikit-learn RandomForest, OpenVINO, C++ tùy chỉnh,…
![]()
Suy luận hiệu suất cao trên mọi nền tảng
Tối đa hóa thông lượng và mức sử dụng với tính năng batching động, thực thi đồng thời, cấu hình tối ưu cũng như truyền phát âm thanh và video. Triton Inference Server hỗ trợ tất cả NVIDIA GPU, x86 và Arm CPU cũng như AWS Inferentia.
![]()
Mã nguồn mở và được thiết kế cho DevOps và MLOps
Tích hợp Triton Inference Server vào các giải pháp DevOps và MLOps như Kubernetes để mở rộng quy mô và Prometheus để giám sát. Nó cũng có thể được sử dụng trong tất cả các nền tảng AI và MLOps tại chỗ và đám mây lớn.
![]()
Khả năng quản lý, tính ổn định của API và bảo mật cấp doanh nghiệp
NVIDIA AI Enterprise, bao gồm NVIDIA Triton Inference Server và Triton Management Service (Dịch vụ quản lý), là một nền tảng phần mềm AI an toàn, ở cấp độ sản xuất được thiết kế để tăng tốc thời gian tạo ra giá trị với sự hỗ trợ, bảo mật và tính ổn định của API.
Bắt đầu với Triton

Mua NVIDIA AI Enterprise với Triton dành cho triển khai sản xuất
Mua NVIDIA AI Enterprise, bao gồm NVIDIA Triton Inference Server và Triton Management Service dành cho suy luận ở cấp độ sản xuất.
→ Đăng ký ngay để nhận NVIDIA AI Enterprise Evaluation License trong 90 ngày
→ Đăng ký trải nghiệm thử Triton Inference Server trên NVIDIA LaunchPad

Tải xuống Container và Code để phát triển
Các container Triton Inference Server có sẵn trên NVIDIA NGC và dưới dạng open-source code trên GitHub.
Triton Management Service
Tự động hóa việc triển khai nhiều instance Triton Inference Server trong Kubernetes với khả năng điều phối mô hình tiết kiệm tài nguyên trên GPU và CPU.
Tính năng và Công cụ

Suy luận Mô hình ngôn ngữ lớn
TensorRT-LLM là một thư viện mã nguồn mở để xác định, tối ưu hóa và thực thi các mô hình ngôn ngữ lớn (LLMs) dành cho suy luận trong sản xuất. Nó duy trì chức năng cốt lõi của FasterTransformer, kết hợp với Trình biên dịch học sâu của TensorRT, trong API Python nguồn mở để nhanh chóng hỗ trợ các mô hình và tùy chỉnh mới.

Các tập hợp mô hình
Nhiều tác vụ AI hiện đại yêu cầu thực thi nhiều mô hình, thường có các bước xử lý trước và sau cho mỗi truy vấn. Triton hỗ trợ các tập hợp (ensembles) và pipeline mô hình, có thể thực thi các phần khác nhau của tập hợp trên CPU hoặc GPU và cho phép nhiều framework bên trong tập hợp.

Tree-Based Models
Phần phụ trợ của Forest Inference Library (FIL) trong Triton cung cấp hỗ trợ suy luận hiệu suất cao của các tree-based model với khả năng giải thích (giá trị SHAP) trên CPU và GPU. Nó hỗ trợ các mô hình từ XGBoost, LightGBM, scikit-learn RandomForest, RAPIDS cuML RandomForest và các mô hình khác ở định dạng Treelite.

NVIDIA PyTriton
PyTriton cung cấp một giao diện đơn giản cho phép các nhà phát triển Python sử dụng Triton để phục vụ mọi thứ – mô hình, hàm xử lý đơn giản hoặc toàn bộ quy trình suy luận. Hỗ trợ gốc này dành cho Triton bằng Python cho phép tạo mẫu và thử nghiệm nhanh chóng các mô hình Học máy với hiệu suất và hiệu quả. Chỉ một dòng code mang đến Triton, cung cấp các lợi ích như batching động, thực thi mô hình đồng thời và hỗ trợ GPU và CPU. Điều này giúp loại bỏ nhu cầu thiết lập kho lưu trữ mô hình và chuyển đổi định dạng mô hình. Pipeline code suy luận hiện có có thể được sử dụng mà không cần sửa đổi.

NVIDIA Triton Model Analyzer
Trình phân tích mô hình Triton là một công cụ tự động đánh giá các cấu hình triển khai mô hình trong Triton Inference Server, chẳng hạn như kích thước batch, độ chính xác và các instance thực thi đồng thời trên bộ xử lý đích. Nó giúp chọn cấu hình tối ưu để đáp ứng các ràng buộc về chất lượng dịch vụ (QoS) của ứng dụng – chẳng hạn như các yêu cầu về độ trễ, thông lượng và bộ nhớ – đồng thời giảm thời gian cần thiết để tìm cấu hình tối ưu. Công cụ này cũng hỗ trợ các tập hợp mô hình và phân tích đa mô hình.
Câu chuyện khách hàng

Khám phá cách Amazon cải thiện sự hài lòng của khách hàng với NVIDIA AI bằng việc tăng tốc suy luận lên gấp 5 lần.

Tìm hiểu cách American Express cải thiện khả năng phát hiện gian lận bằng việc phân tích hàng chục triệu giao dịch hàng ngày nhanh hơn 50 lần.

Khám phá cách Siemens Energy tăng cường kiểm tra bằng việc cung cấp khả năng giám sát từ xa dựa trên AI để phát hiện rò rỉ, tiếng ồn bất thường,…
Xem cách Microsoft Teams sử dụng Triton Inference Server để tối ưu hóa phụ đề và phiên âm trực tiếp bằng nhiều ngôn ngữ với độ trễ rất thấp.

Xem cách NIO đạt được quy trình suy luận có độ trễ thấp bằng cách tích hợp NVIDIA Triton Inference Server vào quy trình suy luận lái xe tự động của họ.
Tích hợp hệ sinh thái
Triton là lựa chọn hàng đầu cho suy luận hiệu suất cao và có thể mở rộng. Nó có sẵn trong Alibaba Cloud, Amazon Elastic Kubernetes Service (EKS), Amazon Elastic Container Service (ECS), Amazon SageMaker, Google Kubernetes Engine (GKE), Google Vertex AI, HPE Ezmeral, Microsoft Azure Kubernetes (AKS), Azure Machine Learning và Oracle Cloud Infrastucture Data Science Platform.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale