
Trong những năm qua, các hệ thống gợi ý (hệ thống đề xuất, recommender system) đã trở nên phổ biến rộng rãi trong cộng đồng khoa học dữ liệu và học máy do tác động tích cực của chúng đến doanh thu cho các nền tảng thương mại điện tử và kinh doanh trực tuyến bằng cách đề xuất các mặt hàng cụ thể mà khách hàng sẽ quan tâm. Tuy nhiên, khi xây dựng hệ thống tư vấn sẽ gặp phải rất nhiều trở ngại. Để giải quyết những thách thức đó, rất nhiều công cụ đang được phát triển để giảm thiểu nỗ lực đầu tư khi xây dựng các hệ thống này như TensorFlow Recommenders, TorchRec và NVIDIA Merlin .
Trong bài viết này, chúng ta sẽ tìm hiểu sâu về NVIDIA Merlin, một framework tiên tiến để xây dựng hệ thống gợi ý trên quy mô lớn vì nó hứa hẹn sẽ giải quyết các thách thức khác nhau phát sinh từ quy trình làm việc của hệ thống gợi ý. Chúng tôi sẽ tóm tắt các điểm quan trọng sẽ hữu ích khi đánh giá tính phù hợp của nó đối với một dự án hoặc khi bắt đầu làm việc với nó.
Vấn đề
Một trong những vấn đề lớn nhất mà các công ty kinh doanh số đang phải đối mặt hiện nay là sự tham gia của người dùng vào nền tảng của họ, điều này đồng nghĩa với việc tăng lợi nhuận. Các câu hỏi như: làm cách nào để chúng tôi thu hút người dùng Youtube liên tiếp nhấp vào nút [What’s next] trong thời gian dài? Hoặc làm cách nào để chúng tôi cung cấp cho một người dùng Netflix cụ thể đề xuất “Điều gì được gợi ý cho bạn” sẽ giúp giữ chân họ lâu hơn một chút? Ngay cả khi bạn có một cửa hàng thời trang trực tuyến: làm cách nào để chúng tôi giúp khách hàng tìm thấy sản phẩm của họ một cách dễ dàng hơn? “Bạn cũng có thể thích… ” hoặc “ Thường xuyên được mua cùng…” giúp giải quyết vấn đề này.
Tất cả các ví dụ nói trên đều có thể thực hiện được nhờ hệ thống gợi ý.
Hệ thống gợi ý
Hệ thống gợi ý tăng doanh thu bán hàng bằng cách giúp khách hàng tìm thấy những mặt hàng mong muốn và mua những mặt hàng phù hợp nhất với họ mà không tốn nhiều công sức hơn.
Một số ví dụ minh họa về cách các hệ thống gợi ý tác động tích cực đến nền tảng kinh doanh số và thương mại điện tử là:
- Một báo cáo của McKinsey & Company cho rằng 35% doanh số bán hàng của Amazon là nhờ các khuyến nghị [1] .
- Theo bài báo ‘Nghiên cứu phát triển cá nhân hóa năm 2019’ do Monetate tổ chức: 78% doanh nghiệp có chiến lược cá nhân hóa toàn bộ hoặc một phần có mức tăng trưởng doanh thu (so với mức tăng trưởng doanh thu 45,4% của các doanh nghiệp không có chiến lược cá nhân hóa) [2].
- Một nghiên cứu của Epsilon cho thấy 80% người tiêu dùng có nhiều khả năng mua hàng hơn khi cửa hàng trực tuyến cung cấp trải nghiệm được cá nhân hóa [3].
- Theo Phân khúc: gần 60% người tiêu dùng đồng ý trở thành người mua sắm thường xuyên sau trải nghiệm mua sắm được cá nhân hóa [4].
Cộng tác và lọc nội dung
Xem xét một số tiêu chí để đưa ra đề xuất cụ thể cho người dùng, và do đó cũng có nhiều loại hệ thống gợi ý khác nhau. Cách phân loại tổng quát đầu tiên phân biệt giữa hệ thống được cá nhân hóa và không được cá nhân hóa. Một ví dụ minh họa cho trường hợp sau bao gồm các đề xuất dựa trên mức độ phổ biến (ví dụ: khi Netflix chiếu cho bạn những bộ phim nổi tiếng nhất ở quốc gia của bạn).
Mặt khác, các hệ thống gợi ý được cá nhân hóa nhằm mục đích đề xuất theo cách “tùy chỉnh” chủ yếu tìm ra ba kiểu bộ lọc: cộng tác, dựa trên nội dung và kết hợp – tận dụng lợi thế của cả hai hệ thống.
- Lọc cộng tác (collaborative filtering) dựa trên thực tế “sự tương đồng về sở thích” giữa những người dùng để đề xuất các mục mới. Dựa trên các tương tác trước đây giữa người dùng và mặt hàng cụ thể, thuật toán gợi ý sẽ học cách dự đoán tương tác trong tương lai. Ý tưởng là nếu một số người đã đưa ra những quyết định và mua hàng tương tự trong quá khứ, chẳng hạn như lựa chọn một bộ phim, thì khả năng cao là họ sẽ đồng ý về những lựa chọn bổ sung trong tương lai.
Ví dụ: trong Hình 1, có thể thấy rằng nếu Người dùng A và Người dùng B đều thích hai bộ phim giống nhau thì hệ thống sẽ giới thiệu cho người dùng B bộ phim thứ ba mà người dùng A thích.
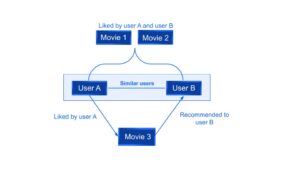
Hình 1: Ví dụ về lọc cộng tác
- Ngược lại, lọc nội dung (content filtering) sử dụng các thuộc tính hoặc tính năng của một sản phẩm – đây là phần nội dung – để đề xuất các mục khác tương tự như sở thích của người dùng. Cách tiếp cận này dựa trên sự giống nhau giữa các sản phẩm và tính năng của người dùng, thông tin được cung cấp về người dùng và các sản phẩm mà họ đã tương tác (ví dụ: giới tính, độ tuổi của người dùng, đánh giá trung bình về một bộ phim) mô hình hóa khả năng xảy ra tương tác mới.
Ví dụ: nếu người dùng thích một bộ phim A thì bộ phim B có tính năng tương tự phim A sẽ được đề xuất cho người dùng.
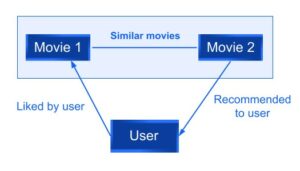
Hình 2: Ví dụ lọc dựa trên nội dung
- Hệ thống đề xuất kết hợp (hybrid recommender) nhắm mục đích đến việc khắc phục một số hạn chế của cả phương pháp lọc cộng tác và dựa trên nội dung. Có một số cách để triển khai loại hệ thống này: tạo nội dung và dự đoán dựa trên cộng tác một cách riêng biệt, sau đó kết hợp chúng, bằng cách thêm các khả năng dựa trên cộng tác vào cách tiếp cận dựa trên nội dung hoặc ngược lại.
Ví dụ: Netflix sử dụng phương pháp này bằng cách trước tiên so sánh nội dung được người dùng tương tự xem (lọc dựa trên cộng tác) và thứ hai bằng cách đề xuất phim có tính năng tương tự với phim được người dùng đánh giá cao (lọc dựa trên nội dung).
Những thách thức
Quá trình suy luận của hệ thống gợi ý bao gồm việc lựa chọn và xếp hạng các mục ứng cử viên theo xác suất dự đoán mà người dùng sẽ tương tác với chúng (những mục có xác suất dự đoán cao nhất sẽ được hiển thị cho người dùng).
Trong phần này, chúng ta sẽ thảo luận về cách đối phó với những trở ngại gặp phải ở mỗi bước của quy trình làm việc khi xây dựng hệ thống gợi ý từ đầu cho đến khi nó sẵn sàng cho khách hàng trong quá trình sản xuất.
1. Lấy dữ liệu và chuẩn bị cho việc đào tạo
Dữ liệu từ các tương tác của người dùng và mặt hàng đến từ các bài đánh giá, lượt thích hoặc thậm chí là số lần nhấp vào trang web và thường được lưu trữ trong kho dữ liệu hoặc hồ dữ liệu (data lake). Những phần dữ liệu này sau đó được sử dụng để đào tạo các hệ thống tư vấn. Mục tiêu chính của quy trình ETL (Trích xuất, Chuyển đổi và Tải) là chuẩn bị tập dữ liệu cho phần đào tạo thường có định dạng bảng thậm chí có thể đạt tới thang đo Terabyte, nghĩa là có rất nhiều dữ liệu cần xử lý trong kỹ thuật trích xuất (tức là tạo ra các ‘feature’ mới từ những feature hiện có) và các bộ phận tiền xử lý.
Ví dụ: nếu cửa hàng thời trang trực tuyến của bạn muốn sử dụng danh sách gửi thư để gửi đề xuất được cá nhân hóa mỗi tháng một lần, trước tiên bạn sẽ phải thu thập mọi tương tác của người dùng trong website của mình (ví dụ: người dùng thích mặt hàng nào, đánh giá trước đó được thực hiện), làm sạch dữ liệu (ví dụ: các đánh giá vô nghĩa) và chọn các tính năng sẽ được sử dụng đồng thời tạo các tính năng mới (ví dụ: tỷ lệ người dùng trung bình có thể hữu ích).
Nhiều thách thức nảy sinh từ bước này:
- Thiếu dữ liệu chất lượng cao: Việc thiếu dữ liệu chất lượng cao có thể khiến bạn gặp khó khăn trong việc xây dựng một công cụ đề xuất chính xác.
- Sự thưa thớt dữ liệu: chủ yếu được tìm thấy trong các hệ thống gợi ý cộng tác, vấn đề này xuất hiện khi một mục được ít người đánh giá nhưng có đánh giá xếp hạng cao sẽ không xuất hiện trong danh sách đề xuất. Điều này có thể đưa ra những đề xuất không chính xác cho những người dùng có sở thích “không phổ biến” so với những người dùng khác.
- Các hệ thống có thể thích ứng với sự thay đổi sở thích của người dùng: tính năng động của người dùng và vật phẩm cần được xem xét khi đề xuất (ví dụ: sở thích của người dùng gần đây không thể có tác động giống như các đề xuất cũ hơn)
- Các bước như kỹ thuật trích xuất (feature engineering), mã hóa phân loại và chuẩn hóa các biến liên tục thường có thể mất nhiều thời gian, đặc biệt đối với những hệ thống đề xuất thương mại liên quan đến các tập dữ liệu khổng lồ (terabyte hoặc thậm chí lớn hơn).
2. Đào tạo
Bước đào tạo thường được thực hiện bằng cách chọn một trong các khung có sẵn (chẳng hạn như Pytorch, Tensorflow hoặc Huge CTR – là thư viện NVIDIA Merlin sẽ được thảo luận sau), đánh giá và sau đó sẵn sàng chuyển sang giai đoạn sản xuất. Một số thách thức nảy sinh trong bước này là:
- Vấn đề ‘khởi đầu nguội’ (chủ yếu được tìm thấy trong lọc cộng tác): vấn đề này phát sinh khi một người dùng mới hoặc một mục mới vừa được thêm vào hệ thống gợi ý mà không có thông tin trước đó về người dùng, lý do tại sao hệ thống không thể dự đoán chính xác tiếp theo sự lựa chọn của người dùng.
- Vấn đề tắc nghẽn: có thể xảy ra trường hợp cửa hàng trực tuyến của bạn tăng trưởng bền vững dẫn đến việc mở rộng danh mục. Vì vậy, bây giờ, một lượng lớn dữ liệu ban đầu không được xem xét. Điều này có thể dẫn đến ‘sự cố tắc nghẽn’ trong đó các bảng nhúng có khả năng khổng lồ của bạn không còn phù hợp với bộ nhớ GPU của bạn và bạn phải thực hiện hành động khắc phục.
3. Triển khai và hoàn thiện hệ thống tư vấn
- Nhu cầu đào tạo lại liên tục do có người đăng ký mặt hàng/người dùng mới: ngay cả khi mô hình của bạn đang hoạt động trong quá trình sản xuất và đưa ra đề xuất cho người dùng, bạn có thể liên tục cần thêm sản phẩm mới vào cửa hàng trực tuyến của mình, điều này sẽ dẫn đến những tương tác mới với người dùng của bạn . Ngoài ra, bạn cũng sẽ có người dùng mới đăng ký. Cả hai trường hợp đều dẫn đến nhu cầu đào tạo lại mô hình của bạn để tiếp tục đáp ứng nhu cầu của người dùng. Điều này cũng dẫn đến nhu cầu load và unload mô hình một cách dễ dàng.
- Xử lý nhiều người dùng cùng một lúc
- Trong một số trường hợp, cần có khả năng suy luận theo thời gian thực: ví dụ: khi khách hàng ở bên cạnh khâu ‘thanh toán’ một sản phẩm thể thao cụ thể ‘được thêm vào giỏ hàng’, chẳng hạn như một số quần short chạy bộ, bạn cũng sẽ muốn đề xuất người dùng của mình mua một số quần áo chạy bộ khác. Trong trường hợp này, việc suy luận cần được thực hiện vào lúc này, tức là trong thời gian thực. Khi giải quyết những loại vấn đề này, thời gian suy luận và số lượng người dùng cần xử lý là những khía cạnh chính cần xem xét.
Ngược lại, nếu bạn muốn cửa hàng trực tuyến của mình sử dụng danh sách gửi thư để giới thiệu các sản phẩm được cá nhân hóa cho mỗi người dùng mỗi tháng một lần, bạn sẽ chỉ thực hiện bước suy luận trước khi gửi email. Điều này bao gồm một kịch bản không có thời gian thực.
Rất nhiều rào cản xuất hiện khi hệ thống gợi ý xuất hiện. Vì vậy, để làm cho cuộc sống của các nhà khoa học dữ liệu và nhà phát triển học máy trở nên đơn giản hơn (hoặc ít nhất là cố gắng) các công cụ và khung mới bắt đầu được phát triển để hỗ trợ công cụ đề xuất này: TensorFlow Recommenders (thư viện được phát triển bởi các nhà nghiên cứu của Google ), TorchRec (thư viện miền PyTorch) và Nvidia Merlin (framework do NVIDIA phát triển) là một số trong số đó.
Từ phần này trở đi, bài viết sẽ tập trung vào NVIDIA Merlin, được ra mắt vào năm 2020 và hứa hẹn sẽ giải quyết một số thách thức nêu trên.
NVIDIA Merlin
Thông tin chính thức từ NVIDIA Merlin xác định rằng đây là một ‘open source framework để xây dựng các hệ thống gợi ý hiệu suất cao trên quy mô lớn’. Framework này được thiết kế để tăng tốc toàn bộ hệ thống gợi ý trong toàn bộ quy trình đề xuất theo các bước sau:
- Sơ chế (Preprocessing)
- Kỹ thuật trích xuất (Feature engineering)
- Đào tạo (Training)
- Sự suy luận (Inference)
- Triển khai vào sản xuất (Deploy to production)
Sơ đồ sau đây trong Hình 3 cho thấy các tính năng chính mà NVIDIA Merlin đã được phát triển và cách nó điều phối toàn bộ hệ thống gợi ý. Khi có được bức tranh toàn cảnh về quy trình, chúng tôi có thể chuyển sang từng thư viện được thiết kế cho mục đích này.
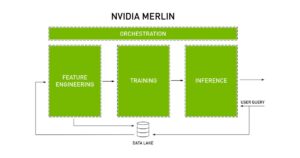
Hình 4: NVIDIA Merlin sắp xếp các tính năng chính của hệ thống gợi ý [6]
NVIDIA Merlin cung cấp nhiều thành phần để có thể sử dụng một thư viện hoặc nhiều thư viện để tăng tốc toàn bộ quy trình đề xuất: từ nhập dữ liệu, đào tạo, suy luận đến triển khai đến sản xuất.
Tùy thuộc vào vấn đề bạn đang cố gắng giải quyết, các thành phần của NVIDIA Merlin đang được sử dụng có thể khác nhau.
Ba thư viện chính được thiết kế để hoạt động cùng nhau là:
- NVTabular: được thiết kế để thao tác các bộ dữ liệu của hệ thống gợi ý ở dạng bảng. Các phần tiền xử lý và kỹ thuật tính năng được thực hiện bởi thư viện này.
- Các mô hình Merlin: cung cấp các mô hình tiêu chuẩn (như Hệ số ma trận hoặc Tháp hai) cho các hệ thống gợi ý. Thư viện này bao gồm một số khối xây dựng cho phép xác định kiến trúc mới.
- Các hệ thống Merlin: được thiết kế để triển khai quy trình đề xuất vào sản xuất. Điều này được thực hiện bằng cách tạo ra một tập hợp sẽ phục vụ cho Máy chủ suy luận Triton (được mô tả sau) sẽ thực hiện bước suy luận.
Ngoài ra còn có một số thư viện Merlin khác được thiết kế để giải quyết một số thách thức cụ thể:
- HugeCTR: đặc biệt hữu ích cho các trường hợp liên quan đến tập dữ liệu lớn và các bảng nhúng khổng lồ cho phép thực hiện bước đào tạo một cách hiệu quả bằng cách phân phối đào tạo trên nhiều GPU và nút.
- Transformers4Rec: được thiết kế cho các đề xuất tuần tự và dựa trên phiên, chức năng thư viện này làm cho nó khác biệt với phần còn lại. Công cụ đề xuất dựa trên trình tự nắm bắt các mẫu trình tự ở người dùng để có thể đoán trước ý định của người dùng tiếp theo và cung cấp cho họ các đề xuất chính xác hơn. Mặt khác, đề xuất dựa trên phiên (lớp con tuần tự) được sử dụng khi bạn chỉ có quyền truy cập vào một chuỗi tương tác ngắn trong phiên hiện tại nhằm đưa ra đề xuất được cá nhân hóa ngay cả khi lịch sử người dùng trước đó không có sẵn hoặc khi sở thích của người dùng thay đổi theo thời gian.
Ngoài Hình 3, nơi tóm tắt các tính năng chính của hệ thống gợi ý, Hình 4 cho thấy cách mỗi thư viện thực hiện một nhiệm vụ cụ thể trong quy trình làm việc của hệ thống gợi ý.
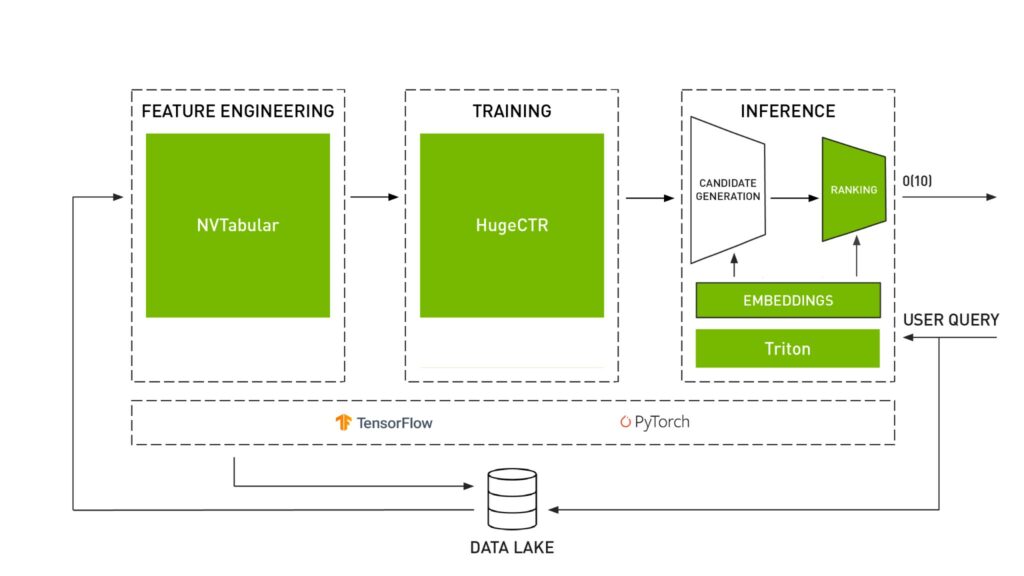 Hình 4: Thư viện NVIDIA Merlin [6]
Hình 4: Thư viện NVIDIA Merlin [6]
Lời khuyên trước khi làm theo: Hình 4 cho thấy cách Merlin được xây dựng trên Tensorflow và Pytorch. Tuy nhiên, trước khi theo dõi, bạn nên lưu ý rằng đối với hầu hết các thành phần, API Pytorch đã được khởi tạo nhưng chưa hoàn thiện tại thời điểm xuất bản bài viết này. Vì vậy, ví dụ: nếu trong dự án hiện tại của bạn, bạn cần sử dụng Mô hình Merlin thì bạn sẽ chưa thể xây dựng nó trên Pytorch.
Ngoài các thư viện này, NVIDIA Merlin còn tận dụng phần mềm NVIDIA AI đã phát triển sẵn có trong nền tảng của họ. Có thể đề cập đến Máy chủ suy luận NVIDIA Triton nhằm mục đích đạt được suy luận hiệu suất cao ở quy mô lớn trong sản xuất. Điều này đạt được “bằng cách chạy suy luận hiệu quả trên GPU bằng cách tối đa hóa thông lượng với sự kết hợp phù hợp giữa độ trễ và mức sử dụng GPU”, như được mô tả trong tài liệu chính thức của NVIDIA.
Trình đề xuất dựa trên phiên: một ứng dụng đầu cuối sử dụng NVIDIA Merlin
Một tình huống đặc biệt xảy ra khi bạn muốn dự đoán sở thích của người dùng tiếp theo nhưng lại không có thông tin trước về họ. Điều này rất hữu ích vì sở thích của người dùng có thể thay đổi theo thời gian hoặc ngay cả khi người dùng quyết định duyệt ở chế độ riêng tư. Vì vậy, chỉ cần thu thập thông tin từ phiên hiện tại có thể giúp giải quyết những vấn đề này.
Một ví dụ về điều này được trình bày trong tài liệu chính thức do NVIDIA cung cấp nhằm mục đích đề xuất các mục tiếp theo cho người dùng từ các tương tác trong phiên hiện tại.
Trong phần này, các bước chính và thư viện được sử dụng để đạt được mục tiêu này được mô tả (bạn có thể làm theo mã để đọc thêm trong [5],[6] ).
NVTabular thứ 1 : được sử dụng để xác định quy trình làm việc nhằm xử lý trước dữ liệu bằng cách nhóm các tương tác từ cùng một phiên, sắp xếp chúng theo thời gian.
Transformers4Rec thứ 2 : thư viện này cho phép bạn sử dụng kiến trúc transformer engine được nhập từ thư viện NLP Hugging Face Transformers để thực hiện đào tạo. Thư viện này cũng bao gồm các số liệu Recsys cho phép bạn đo lường mức độ hoạt động của mô hình.
Máy chủ Triton Inference thứ 3 : thư viện này cho phép triển khai và phục vụ mô hình cho suy luận. Việc triển khai từ cả hai đều đạt được: quy trình làm việc ETL (vì trong suy luận, bạn sẽ cần chuyển đổi dữ liệu đầu vào như được thực hiện trong quá trình đào tạo) và mô hình được đào tạo. Kết quả là bây giờ người dùng của bạn có thể truy vấn máy chủ để nhận được dự đoán mục tiếp theo.
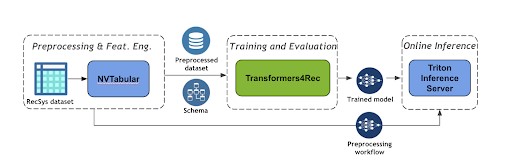
Hình 5: Quy trình làm việc của người đề xuất dựa trên phiên [6]
Về giải pháp
Sau khi đọc tài liệu chính thức của NVIDIA, chúng tôi quyết định tự mình thực hiện và thử một số thư viện. Mô hình NVTabular và Merlin là các thành phần chính nhằm tìm ra một số khía cạnh chính cần lưu ý trước khi quyết định tiếp tục với công cụ này.
- Giải pháp toàn diện
Mô hình Merlin, NVTabular và Hệ thống Merlin là các thành phần của Merlin được thiết kế để hoạt động cùng nhau. NVTabular sẽ xuất ra (ngoài các file sàn gỗ được xử lý trước), một file lược đồ mô tả các cấu trúc tập dữ liệu cần thiết để cung cấp cho Mô hình Merlin. Sau đó, việc kết hợp với các mô hình Merlin phải được thực hiện để có được đường dẫn suy luận mô hình. Bước cuối cùng sẽ là triển khai các mô hình và quy trình công việc NV-Tabular lên máy chủ Triton Inference.
Sự tích hợp được thiết kế này giữa các thư viện giúp việc xây dựng các đường dẫn RecSys từ đầu đến cuối trở nên đơn giản nhưng xét về tính linh hoạt thì việc quyết định chuyển sang công nghệ khác có thể gặp khó khăn.
- Lời khuyên về Docker container
Cách đơn giản nhất để sử dụng Merlin là chạy container docker có thể tìm thấy trong https://catalog.ngc.nvidia.com/containers để tránh các vấn đề phụ thuộc vào thư viện. Chúng tôi quyết định chạy nó trên phiên bản AWS g4dn.xlarge cung cấp một GPU, 4 vCPU và kích thước bộ nhớ 16GiB. Việc sử dụng loại phiên bản này có giá 243 USD mỗi tháng (được tính bằng máy tính AWS ). Dự án bạn sẽ bắt tay vào sẽ đặt ra chi phí hạ tầng của riêng bạn, chi phí này sẽ khác với dự án này nhưng chắc chắn cần phải được xem xét trước khi tiếp tục.
Như đã được đề cập trước đó, chúng tôi đã phát hiện ra từ tài liệu chính thức của NVIDIA lời khuyên sau: “Trong các bản phát hành đầu tiên của chúng tôi, Mô hình Merlin có API Tensorflow. API PyTorch đã được khởi tạo nhưng chưa hoàn thiện”.
Vì vậy, điều đầu tiên cần lưu ý: mặc dù có một số thành phần cụ thể (như đối với Transformers4rec ), NVIDIA Merlin được thiết kế để tích hợp với Tensorflow.
Lời kết
Trong bài viết này, chúng tôi thảo luận về tác động của hệ thống gợi ý trong nền tảng số ngày nay và các loại bộ lọc khác nhau. Sau đó, chúng tôi chuyển sang tìm hiểu những thách thức chính nảy sinh từ các hệ thống gợi ý và nhu cầu về các công cụ hỗ trợ từng bước của quy trình làm việc. Cuối cùng, chúng tôi đã giới thiệu và thảo luận về NVIDIA Merlin, một framework đầy hứa hẹn để xây dựng các hệ thống gợi ý toàn diện, hữu ích để tăng tốc quá trình tiền xử lý và kỹ thuật trích xuất bằng cách sử dụng NV Tabular nhưng chưa linh hoạt (cho đến nay) để sử dụng cho một hệ thống gợi ý hoàn chỉnh được xây dựng trên Pytorch. Chúng tôi cũng đã thảo luận về các đề xuất dựa trên phiên đặc biệt hữu ích khi không tìm thấy tương tác nào của người dùng trước đó.
Thông tin tham khảo:
[1] I. MacKenzie, C. Meyer, S. Noble (2013, October 1). “How retailers can keep up with consumers”. https://www.mckinsey.com/industries/retail/our-insights/how-retailers-can-keep-up-with-consumers
[2] Monetate (2019). “2019 Personalization Development Study”. https://info.monetate.com/rs/092-TQN-434/images/2019_Personalization_Development_Study_US.pdf
[3] Epsilon (2018, January 9). “New epsilon research indicates 80 of consumers are more likely to make a purchase when brands offer personalized experiences”. https://www.epsilon.com/us/about-us/pressroom/new-epsilon-research-indicates-80-of-consumers-are-more-likely-to-make-a-purchase-when-brands-offer-personalized-experiences
[4] Keating (2021, June 1). “Announcing the state of personalization 2021”. https://segment.com/blog/announcing-the-state-of-personalization-2021/
[5] NVIDIA. https://nvidia-merlin.github.io/Transformers4Rec/main/examples/tutorial/03-Session-based-recsys.html (accessed 12/12/2022)
[6] R. AK, G. Moreira (2022, June 28). “Transformers4rec – Building session based recommendation with an nvidia merlin library”. https://developer.nvidia.com/blog/transformers4rec-building-session-based-recommendations-with-an-nvidia-merlin-library/
[7] ] NVIDIA. https://github.com/NVIDIA-Merlin/Merlin (accessed 12/12/2022)
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?