
NVIDIA vừa công bố hệ thống DGX GH200 tại COMPUTEX 2023, đánh dấu một bước đột phá khác trong điện toán tăng tốc qua GPU nhằm cung cấp sức mạnh cho các hệ thống AI cực lớn có đòi hỏi khắt khe nhất. Bài viết này sẽ mô tả các khía cạnh quan trọng của kiến trúc NVIDIA DGX GH200, cũng như thảo luận thêm về cách giải pháp NVIDIA Base Command cho phép triển khai nhanh chóng, tăng tốc quá trình tích hợp và đơn giản hóa việc quản lý hệ thống.
Mô hình lập trình bộ nhớ thống nhất (unified memory programming model, UMPM) của GPU là nền tảng của nhiều bước đột phá khác nhau trong các ứng dụng điện toán tăng tốc phức tạp trong 7 năm qua. Vào năm 2016, NVIDIA đã giới thiệu công nghệ NVLink và UMPM với CUDA-6, được thiết kế để tăng bộ nhớ khả dụng cho các hệ thống được GPU tăng tốc.
Kể từ đó, cốt lõi của mọi hệ thống DGX là một tổ hợp GPU trên một tấm nền được kết nối với NVLink, trong đó mỗi GPU có thể truy cập bộ nhớ của nhau với tốc độ NVLink. Nhiều hệ thống DGX như vậy với sự kết hợp GPU chằng chịt được kết nối với mạng tốc độ cao để tạo thành các siêu máy tính lớn hơn, chẳng hạn như siêu máy tính NVIDIA Selene. Tuy nhiên, một thế hệ các mô hình AI khổng lồ, hàng nghìn tỷ tham số mới phát triển sẽ cần vài tháng để đào tạo hoặc thậm chí không thể xử lý được, ngay cả trên các siêu máy tính tốt nhất hiện nay.
Để tạo điều kiện cho các nhà khoa học đang cần một nền tảng tiên tiến có thể giải quyết những thách thức đặc biệt này, NVIDIA đã kết hợp siêu chip NVIDIA Grace Hopper với NVLink Switch System, kết hợp lên đến 256 GPU trong hệ thống NVIDIA DGX GH200. Trong hệ thống DGX GH200, mô hình lập trình bộ nhớ dùng chung GPU có thể truy cập 144 terabyte bộ nhớ ở tốc độ cao qua NVLink.
So với một hệ thống NVIDIA DGX A100 320 GB duy nhất, NVIDIA DGX GH200 cung cấp bộ nhớ nhiều hơn gần 500 lần cho mô hình lập trình bộ nhớ dùng chung GPU qua NVLink, tạo thành một GPU có kích thước trung tâm dữ liệu khổng lồ. NVIDIA DGX GH200 là siêu máy tính đầu tiên phá vỡ rào cản 100 terabyte đối với bộ nhớ mà GPU có thể truy cập qua NVLink.
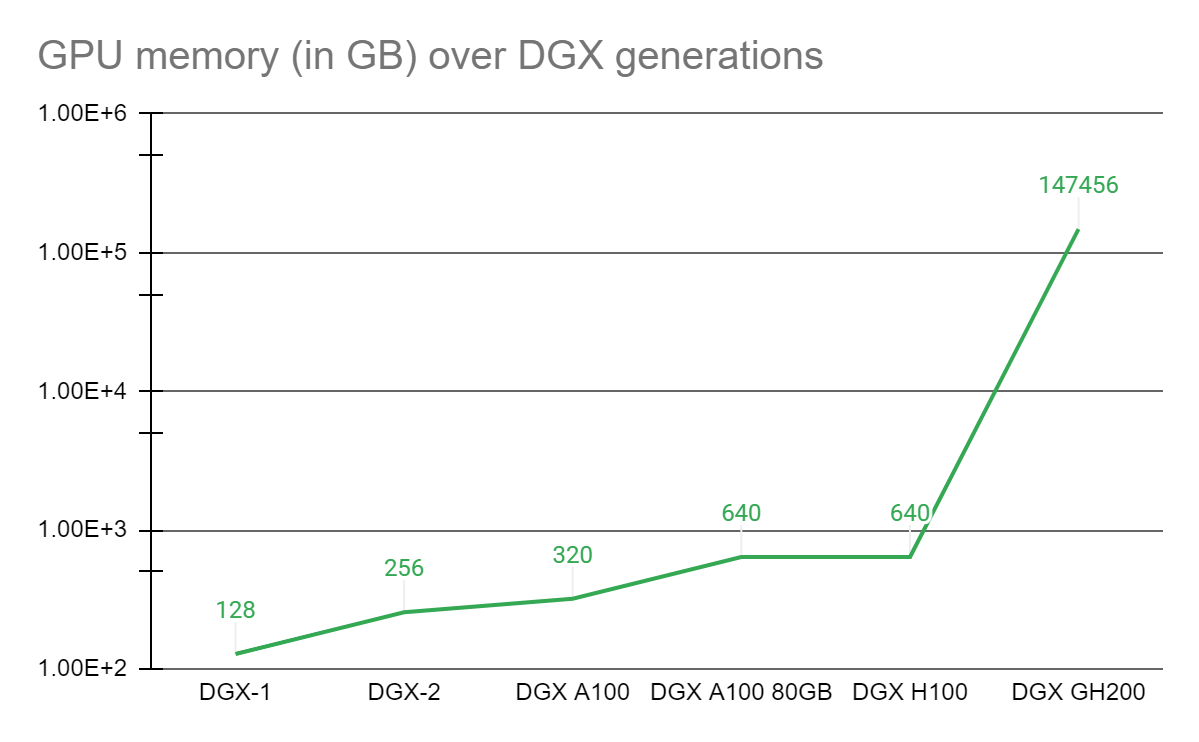 Hình 1. Tăng bộ nhớ GPU do tiến trình NVLink
Hình 1. Tăng bộ nhớ GPU do tiến trình NVLink
Kiến trúc hệ thống NVIDIA DGX GH200
Siêu chip NVIDIA Grace Hopper và NVLink Switch System là các building-block của kiến trúc NVIDIA DGX GH200. Siêu chip NVIDIA Grace Hopper kết hợp kiến trúc Grace và Hopper bằng cách sử dụng NVIDIA NVLink-C2C để cung cấp mô hình bộ nhớ kết hợp CPU + GPU. NVLink Switch System, được hỗ trợ bởi công nghệ NVLink thế hệ thứ tư, mở rộng kết nối NVLink trên các siêu chip để tạo ra một hệ thống đa GPU liền mạch, băng thông cao.
Mỗi siêu chip NVIDIA Grace Hopper trong NVIDIA DGX GH200 có bộ nhớ CPU LPDDR5 480 GB, ở mức tiêu thụ năng lượng/mỗi GB chỉ bằng 1/8, so với DDR5 và 96 GB của HBM3. CPU NVIDIA Grace và GPU Hopper được kết nối với nhau bằng NVLink-C2C, cung cấp băng thông gấp 7 lần so với PCIe Gen5 với công suất chỉ bằng 1/5.
NVLink Switch System tạo thành một cấu trúc NVLink fat-tree hai cấp, non-blocking, để kết nối toàn bộ 256 siêu chip Grace Hopper trong hệ thống DGX GH200. Mỗi GPU trong DGX GH200 có thể truy cập bộ nhớ của các GPU khác và bộ nhớ GPU mở rộng của tất cả các CPU NVIDIA Grace với tốc độ 900 GBps.
Các bảng mạch nền lắp siêu chip Grace Hopper được kết nối với NVLink Switch System bằng cách sử dụng cáp tùy biến cho lớp liên kết NVLink đầu tiên. Cáp LinkX mở rộng khả năng kết nối trong lớp thứ hai của liên kết NVLink.
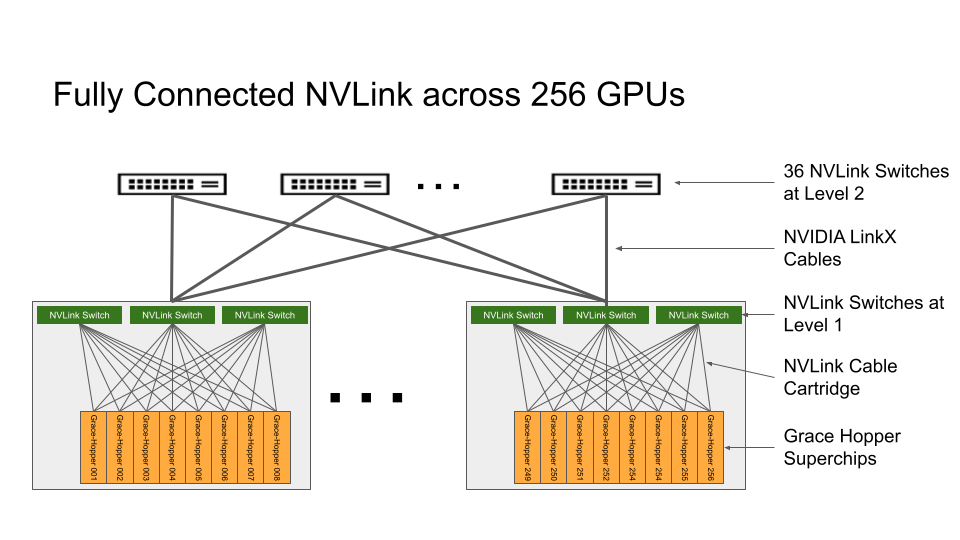 Hình 2. Cấu trúc liên kết của NVIDIA NVLink Switch System được kết nối đầy đủ trên NVIDIA DGX GH200 có 256 GPU
Hình 2. Cấu trúc liên kết của NVIDIA NVLink Switch System được kết nối đầy đủ trên NVIDIA DGX GH200 có 256 GPU
Trong hệ thống DGX GH200, các luồng GPU có thể xử lý bộ nhớ HBM3 và LPDDR5X ngang hàng từ các siêu chip Grace Hopper khác trong mạng NVLink bằng NVLink page table. Thư viện tăng tốc NVIDIA Magnum IO tối ưu hóa giao tiếp GPU để đạt hiệu quả, nâng cao khả năng mở rộng ứng dụng với tất cả 256 GPU.
Mỗi siêu chip Grace Hopper trong DGX GH200 đều được ghép nối với một bộ điều hợp mạng NVIDIA ConnectX-7 và một NIC NVIDIA BlueField-3. DGX GH200 có băng thông bi-section là 128 TBps và 230.4 TFLOPS năng lực tính toán in-network của NVIDIA SHARP để tăng tốc các hoạt động chung thường được sử dụng trong AI và tăng gấp đôi băng thông hiệu quả của NVLink Network System bằng cách giảm chi phí truyền dữ liệu của các hoạt động chung toàn hệ thống.
Để mở rộng quy mô vượt qua con số 256 GPU, bộ điều hợp ConnectX-7 có thể kết nối nhiều hệ thống DGX GH200 với nhau để mở rộng thành một giải pháp thậm chí còn lớn hơn. Sức mạnh của DPU BlueField-3 cho phép chuyển đổi bất kỳ môi trường điện toán doanh nghiệp nào thành đám mây riêng ảo được bảo mật và tăng tốc, cho phép các tổ chức chạy tải xử lý ứng dụng trong môi trường an toàn, nhiều bên thuê.
Các trường hợp sử dụng mục tiêu và lợi ích về hiệu suất
Bước đột phá của thế hệ bộ nhớ GPU mới giúp cải thiện đáng kể hiệu suất của các ứng dụng AI và HPC bị tắc nghẽn do kích thước bộ nhớ GPU. Nhiều tải xử lý AI và HPC chính thống có thể nằm hoàn toàn trong bộ nhớ GPU tổng hợp của một hệ thống NVIDIA DGX H100 duy nhất . Đối với một workload như vậy, DGX H100 là giải pháp đào tạo hiệu quả nhất.
Các loại workload khác – chẳng hạn như Mô hình gợi ý học sâu (DLRM) với hàng terabyte bảng nhúng, mô hình đào tạo Graph Neural Network quy mô terabyte hoặc tải xử lý phân tích dữ liệu lớn – ghi nhận tốc độ tăng từ 4x lên 7x với DGX GH200. Điều này cho thấy DGX GH200 là một giải pháp tốt hơn cho các mô hình AI và HPC tiên tiến cần bộ nhớ lớn để lập trình bộ nhớ dùng chung GPU.
Cơ chế tăng tốc được mô tả chi tiết trong whitepaper Kiến trúc siêu chip NVIDIA Grace Hopper.
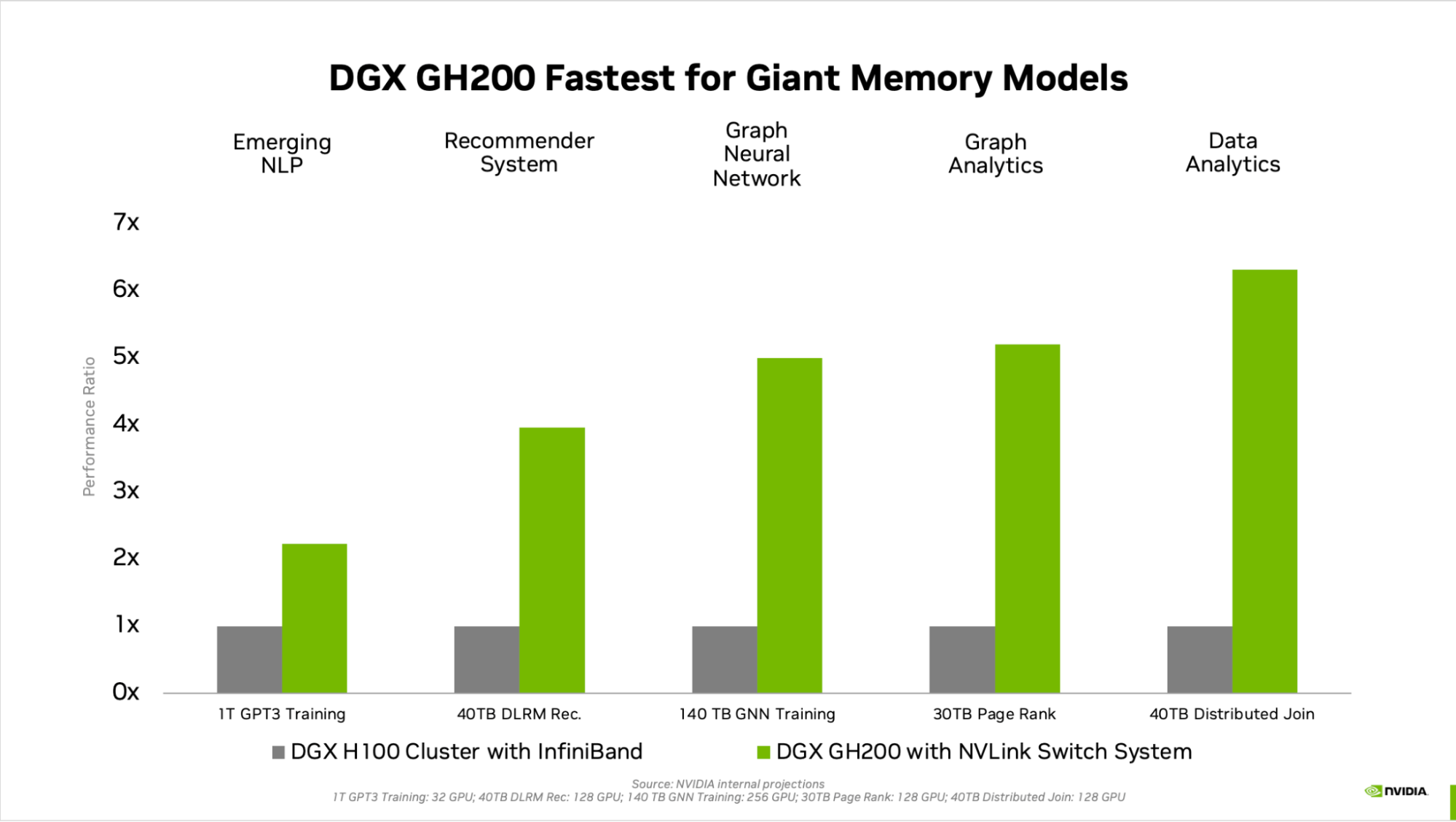 Hình 3. So sánh hiệu suất cho tải xử lý AI bộ nhớ khổng lồ
Hình 3. So sánh hiệu suất cho tải xử lý AI bộ nhớ khổng lồ
Được thiết kế có mục đích cho các tải xử lý đòi hỏi khắt khe nhất
Mọi thành phần xuyên suốt DGX GH200 đều được lựa chọn để giảm thiểu tắc nghẽn đồng thời tối đa hóa hiệu suất mạng cho các tải xử lý chính và sử dụng đầy đủ tất cả các khả năng mở rộng của phần cứng. Kết quả là khả năng mở rộng tuyến tính và khả năng sử dụng cao của không gian bộ nhớ dùng chung đồ sộ.
Để tận dụng tối đa hệ thống tiên tiến này, NVIDIA cũng đã thiết kế một cấu trúc lưu trữ tốc độ cực cao để chạy ở công suất tối đa và xử lý nhiều loại dữ liệu (văn bản, dữ liệu dạng bảng, âm thanh và video) – song song và ổn định hiệu suất.
Giải pháp NVIDIA toàn diện
DGX GH200 đi kèm với NVIDIA Base Command, bao gồm một hệ điều hành được tối ưu hóa cho AI, trình quản lý cụm, thư viện giúp tăng tốc tính toán, lưu trữ và hạ tầng mạng được tối ưu hóa cho kiến trúc hệ thống DGX GH200.
DGX GH200 cũng bao gồm NVIDIA AI Enterprise, cung cấp một bộ phần mềm và các framework được tối ưu hóa để chuẩn hóa việc phát triển và triển khai AI. Giải pháp toàn diện này cho phép khách hàng tập trung vào đổi mới và bớt lo lắng hơn về việc quản lý hạ tầng CNTT của họ.
 Hình 4. Toàn bộ siêu máy tính AI NVIDIA DGX GH200 bao gồm NVIDIA Base Command và NVIDIA AI Enterprise
Hình 4. Toàn bộ siêu máy tính AI NVIDIA DGX GH200 bao gồm NVIDIA Base Command và NVIDIA AI Enterprise
Tăng tốc các hệ thống AI và HPC khổng lồ
NVIDIA đang đẩy nhanh công việc để cung cấp DGX GH200 vào cuối năm nay. NVIDIA mong muốn cung cấp hệ thống siêu máy tính đầu tiên của loại này và trao quyền cho bạn đổi mới cũng như theo đuổi đam mê của mình trong việc giải quyết những thách thức lớn nhất về AI và HPC hiện nay. Tìm hiểu thêm về DGX GH200.
Tìm hiểu thêm về DGX:
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale