
GPU tốt nhất cho học sâu
Thông thường, giai đoạn đào tạo của quá trình học sâu (Deep Learning) mất nhiều thời gian nhất để đạt được kết quả. Đây không chỉ là một quá trình tốn thời gian mà còn tốn kém. Phần có giá trị nhất của quá trình học sâu là yếu tố con người – các nhà khoa học dữ liệu thường đợi hàng giờ hoặc hàng ngày để việc đào tạo hoàn thành, điều này làm ảnh hưởng đến năng suất của họ và thời gian đưa các mô hình mới ra thị trường.
Để giảm đáng kể thời gian đào tạo, bạn có thể sử dụng GPU chuyên dụng cho học sâu, cho phép bạn thực hiện song song các hoạt động tính toán AI. Khi đánh giá GPU, bạn cần xem xét khả năng kết nối nhiều GPU với nhau, phần mềm hỗ trợ có sẵn, chi phí license, tính song song của dữ liệu, việc sử dụng bộ nhớ GPU và hiệu suất chung.
Trong bài viết này, bạn sẽ tìm hiểu về:

- Tầm quan trọng của GPU trong học sâu
- Cách chọn GPU tốt nhất cho việc học sâu
- Sử dụng GPU phổ thông để học sâu
- GPU học sâu tốt nhất dành cho trung tâm dữ liệu
- Hệ thống NVIDIA DGX và học sâu trên quy mô lớn
Tại sao GPU lại quan trọng đối với Học sâu?
Giai đoạn dài nhất và sử dụng nhiều tài nguyên nhất của hầu hết các triển khai học sâu là giai đoạn đào tạo. Giai đoạn này có thể được thực hiện trong một khoảng thời gian hợp lý đối với các mô hình có số lượng thông số nhỏ hơn nhưng khi số lượng của bạn tăng lên, thời gian đào tạo của bạn cũng theo đó mà nhân lên. Điều này tạo ra chi phí kép; tài nguyên của bạn bị chiếm dụng lâu hơn và nhóm của bạn phải chờ đợi, lãng phí thời gian quý báu.
Các đơn vị xử lý đồ họa (GPU) có thể giảm các chi phí này, cho phép bạn chạy các mô hình với số lượng lớn các thông số một cách nhanh chóng và hiệu quả. Điều này là do GPU cho phép bạn song song hóa các nhiệm vụ đào tạo của mình, phân phối các tác vụ qua các cụm bộ xử lý và thực hiện đồng thời các hoạt động tính toán.
GPU cũng được tối ưu hóa để thực hiện các tác vụ mục tiêu, hoàn thiện các phép tính nhanh hơn so với phần cứng không chuyên dụng. Các bộ xử lý này cho phép bạn xử lý các tác vụ tương tự nhanh hơn và giải phóng CPU của bạn cho các tác vụ khác. Điều này giúp loại bỏ các tắc nghẽn do giới hạn xử lý gây ra.
Chọn GPU nào tốt nhất cho học sâu?
Việc chọn GPU để triển khai của bạn có ý nghĩa đáng kể về ngân sách và hiệu suất. Bạn cần chọn GPU có thể hỗ trợ dự án của bạn về lâu dài và có khả năng mở rộng quy mô thông qua tích hợp và phân cụm. Đối với các dự án quy mô lớn, điều này có nghĩa là chọn GPU cấp sản xuất (production-grade) hoặc trung tâm dữ liệu.
Các yếu tố GPU cần xem xét
Những yếu tố này ảnh hưởng đến khả năng mở rộng và dễ sử dụng của GPU bạn chọn.
Khả năng kết nối các GPU với nhau
Khi chọn GPU, bạn cần xem xét dòng GPU nào có thể được kết nối với nhau. Việc kết nối các GPU liên hệ trực tiếp với khả năng mở rộng triển khai của bạn và khả năng sử dụng đa GPU và các chiến lược đào tạo phân tán.
Thông thường, GPU phổ thông không hỗ trợ kết nối (ví dụ NVlink cho kết nối GPU nội bộ bên trong máy chủ và Infiniband / RoCE để liên kết GPU giữa các máy chủ với nhau) và NVIDIA đã loại bỏ khả năng kết nối ở các mẫu GPU cấp dưới RTX 2080.
Phần mềm hỗ trợ
GPU NVIDIA được hỗ trợ tốt nhất về thư viện Machine Learning và tích hợp với các framework phổ biến, chẳng hạn như PyTorch hoặc TensorFlow. Bộ công cụ NVIDIA CUDA bao gồm các thư viện tăng tốc GPU, trình biên dịch C và C ++ và runtime cũng như các công cụ tối ưu hóa và gỡ lỗi. Nó cho phép bạn bắt đầu ngay lập tức mà không cần lo lắng về việc xây dựng các tích hợp tùy chỉnh.
License
Một yếu tố khác cần xem xét là các hướng dẫn của NVIDIA về việc sử dụng một số chip nhất định trong các trung tâm dữ liệu. Kể từ bản cập nhật license vào năm 2018, có thể có những hạn chế đối với việc sử dụng phần mềm CUDA với GPU phổ thông trong trung tâm dữ liệu. Điều này có thể yêu cầu các tổ chức chuyển đổi sang GPU cấp production.
3 Yếu tố thuật toán ảnh hưởng đến việc sử dụng GPU
Theo kinh nghiệm của chúng tôi khi giúp các tổ chức tối ưu hóa khối lượng công việc học sâu quy mô lớn, sau đây là ba yếu tố chính bạn nên xem xét khi mở rộng thuật toán của mình trên nhiều GPU.
- Tính song song dữ liệu – Xem xét lượng dữ liệu mà thuật toán của bạn cần xử lý. Nếu bộ dữ liệu lớn, hãy đầu tư vào GPU có khả năng thực hiện đào tạo đa GPU một cách hiệu quả. Đối với bộ dữ liệu quy mô rất lớn, hãy đảm bảo rằng các máy chủ có thể giao tiếp rất nhanh với nhau và với các thành phần lưu trữ, sử dụng các công nghệ như Infiniband / RoCE, để cho phép đào tạo phân tán hiệu quả.
- Việc sử dụng bộ nhớ – Bạn sẽ xử lý đầu vào dữ liệu lớn để lập mô hình? Ví dụ: các mô hình xử lý hình ảnh y tế hoặc video dài có bộ đào tạo rất lớn, vì vậy bạn sẽ muốn đầu tư vào GPU có bộ nhớ tương đối lớn. Ngược lại, dữ liệu dạng bảng như đầu vào văn bản cho các mô hình NLP thường nhỏ và bạn có thể thực hiện với ít bộ nhớ GPU hơn.
- Hiệu suất của GPU – Cân nhắc xem bạn có định sử dụng GPU để gỡ lỗi và phát triển hay không. Trong trường hợp này, bạn sẽ không cần GPU mạnh nhất. Để điều chỉnh các mô hình trong thời gian dài, bạn cần có GPU mạnh để đẩy nhanh thời gian đào tạo, tránh phải đợi hàng giờ hoặc hàng ngày để các mô hình chạy.
Sử dụng GPU phổ thông cho việc học sâu
Mặc dù GPU phổ thông không phù hợp với các dự án học sâu quy mô lớn, nhưng những bộ xử lý này có thể cung cấp bước ban đầu tốt cho học sâu. GPU phổ thông cũng có thể là một tùy chọn rẻ cho các tác vụ ít phức tạp hơn, chẳng hạn như lập kế hoạch mô hình hoặc thử nghiệm cấp thấp. Tuy nhiên, khi mở rộng quy mô, bạn sẽ cần xem xét các GPU cấp trung tâm dữ liệu và các hệ thống học sâu cao cấp như dòng máy chủ DGX của NVIDIA.
Đặc biệt, Titan V đã được chứng minh là cung cấp hiệu suất tương tự như GPU cấp trung tâm dữ liệu khi nói đến Word RNN. Ngoài ra, hiệu suất của nó đối với CNN chỉ thấp hơn một chút so với các tùy chọn cấp cao hơn. Titan RTX và RTX 2080 Ti cũng không kém là bao.
NVIDIA Titan V
Titan V là một GPU PC được thiết kế để các nhà khoa học và nhà nghiên cứu sử dụng. Nó dựa trên công nghệ Volta của NVIDIA và bao gồm các lõi Tensor. Titan V có các phiên bản Standard và ‘CEO’.
Phiên bản Standard cung cấp bộ nhớ 12GB, hiệu suất 110 teraflop, bộ nhớ đệm L2 4,5MB và bus bộ nhớ 3.072-bit. Phiên bản CEO cung cấp bộ nhớ 32 GB và hiệu suất 125 teraflop, bộ nhớ đệm 6MB và bus bộ nhớ 4.096 bit. Phiên bản thứ hai cũng sử dụng cùng một ngăn xếp bộ nhớ HBM2 8-Hi được sử dụng trong các đơn vị Tesla 32GB.
NVIDIA Titan RTX
Titan RTX là GPU PC dựa trên kiến trúc GPU Turing của NVIDIA được thiết kế cho khối lượng công việc sáng tạo và học máy. Nó bao gồm các công nghệ Tensor Core và RT Core để cho phép dò tia và tăng tốc AI.
Mỗi Titan RTX cung cấp 130 teraflop, bộ nhớ GDDR6 24GB, bộ nhớ đệm 6MB và 11 GigaRays mỗi giây. Điều này là do 72 lõi Turing RT và 576 lõi Turing Tensor đa độ chính xác.
NVIDIA GeForce RTX 2080 Ti
GeForce RTX 2080 Ti là một GPU PC được thiết kế cho những người đam mê. Nó dựa trên bộ xử lý đồ họa TU102. Mỗi GeForce RTX 2080 Ti cung cấp bộ nhớ 11GB, bus bộ nhớ 352-bit, bộ nhớ đệm 6MB và hiệu suất khoảng 120 teraflop.
GPU học sâu tốt nhất cho các dự án quy mô lớn và trung tâm dữ liệu
Sau đây là các GPU được khuyến nghị sử dụng trong các dự án AI quy mô lớn.
NVIDIA Tesla A100
A100 là GPU có lõi Tensor kết hợp công nghệ GPU đa phiên bản (MIG). Nó được thiết kế cho máy học, phân tích dữ liệu và HPC.
Tesla A100 được tạo ra để có thể mở rộng lên đến hàng nghìn unit và mỗi unit lại có thể được ‘băm’ thành bảy instance GPU khác nhau cho bất kỳ kích thước của workload nào. Mỗi Tesla A100 cung cấp hiệu suất lên tới 624 teraflop, bộ nhớ 40GB, băng thông bộ nhớ 1.555 GB và kết nối 600GB/s.
NVIDIA Tesla V100
NVIDIA Tesla V100 là GPU hỗ trợ Tensor Core được thiết kế cho học máy, học sâu và máy tính hiệu suất cao (HPC). Nó được cung cấp bởi công nghệ NVIDIA Volta, hỗ trợ công nghệ lõi Tensor, chuyên dùng để tăng tốc các hoạt động tensor phổ biến trong học sâu. Mỗi chiếc Tesla V100 cung cấp hiệu suất 149 teraflop, bộ nhớ lên đến 32GB và bus bộ nhớ 4.096 bit.
NVIDIA Tesla P100
Tesla P100 là GPU dựa trên kiến trúc NVIDIA Pascal được thiết kế cho máy học và HPC. Mỗi P100 cung cấp hiệu suất lên tới 21 teraflop, bộ nhớ 16GB và bus bộ nhớ 4.096 bit.
NVIDIA Tesla K80
Tesla K80 là một GPU dựa trên kiến trúc NVIDIA Kepler được thiết kế để tăng tốc tính toán khoa học và phân tích dữ liệu. Nó bao gồm 4.992 lõi NVIDIA CUDA và công nghệ GPU Boost™. Mỗi K80 cung cấp hiệu suất lên đến 8,73 teraflop, 24GB bộ nhớ GDDR5 và 480GB băng thông bộ nhớ.
TPU của Google
Đặc biệt một tí với các Tensor Processing Unit (TPU) của Google. TPU là loại chip/mạch tích hợp cloud-base, và thuộc dạng application-specific integrated circuits (ASIC) dành cho học sâu. Các đơn vị này được thiết kế đặc biệt để sử dụng với TensorFlow và chỉ khả dụng trên Google Cloud Platform.
Mỗi TPU có thể cung cấp hiệu suất lên đến 420 teraflop và bộ nhớ băng thông cao 128 GB (HBM). Ngoài ra còn có các phiên bản pod có thể cung cấp hơn 100 petaflop hiệu suất, 32TB HBM và mạng lưới hình xuyến 2D.
NVIDIA DGX cho Học sâu trên quy mô (Large-scale Deep Learning)
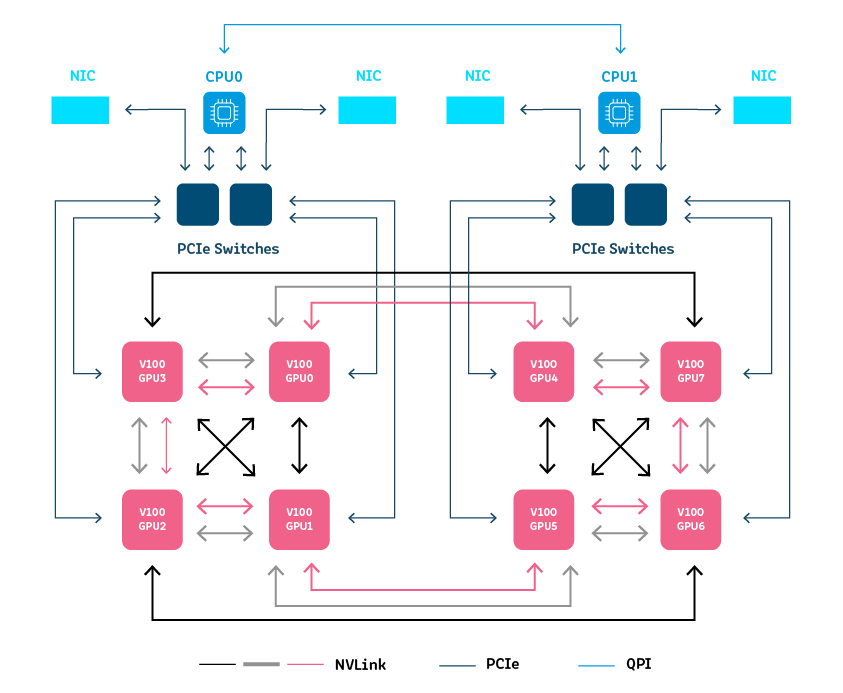
Hệ thống NVIDIA DGX là giải pháp full-stack được thiết kế cho Machine Learning cấp doanh nghiệp. Các hệ thống này dựa trên một lớp phần mềm tối ưu hóa cho AI, khả năng mở rộng đa node và chính sách hỗ trợ cấp doanh nghiệp.
Bạn có thể triển khai DGX stack trong các container hoặc bare-metal. Công nghệ này thiết kế theo kiểu plug-n-play và được tích hợp hoàn toàn với các giải pháp phần mềm và thư viện học sâu của NVIDIA. DGX có sẵn với các máy trạm, máy chủ hoặc cụm máy chủ.
DGX-1
DGX-1 là một máy chủ GPU dựa trên Hệ điều hành Máy chủ Ubuntu Linux. Nó tích hợp với các giải pháp Red Hat và bao gồm ứng dụng đào tạo học sâu DIGITS, NVIDIA Deep Learning SDK, bộ công cụ CUDA và Tiện ích Docker Engine cho GPU NVIDIA.
Mỗi DGX-1 cung cấp:
- Hai CPU Intel Xeon để điều phối framework học sâu, khởi động và quản lý lưu trữ
- Lên đến 8 GPU lõi Tensor Tesla V100 với bộ nhớ 32 GB
- 300Gb / giây kết nối NVLink
- Giao tiếp 800GB / giây với độ trễ thấp
- Một ổ SSD hệ điều hành khởi động 480GB duy nhất và bốn ổ SSD SAS 1,92 TB (tổng cộng 7,6 TB) được cấu hình RAID 0 striped volume
DGX-2
DGX-2 là cấp độ tiếp theo nâng cấp từ DGX-1. Nó dựa trên kết cấu mạng NVSwitch cho khả năng mở rộng và tính song song cao hơn.
Mỗi DGX-2 cung cấp:
- 02 petaflop hiệu suất
- SSD NVME 2X 960GB cho hệ điều hành và 30TB dung lượng lưu trữ SSD
- 16 Tesla V100 Tensor Core GPU với bộ nhớ 32 GB
- 12 NVSwitch, 2,4TB/s bisection bandwidth
- 1,6TB/s bi-directional, low-latency bandwidth
- Bộ nhớ hệ thống 1.5TB
- Hai CPU Xeon Platinum để điều phối, khởi động và lưu trữ framework học sâu
- Hai card ethernet I/O cao
DGX A100
DGX A100 được thiết kế để trở thành một hệ thống chung cho các tải công việc học máy, bao gồm phân tích, đào tạo và suy luận. Nó được tối ưu hóa hoàn toàn cho CUDA-X. DGX A100 có thể được xếp chồng lên nhau với các unit A100 khác để tạo ra các cụm AI khổng lồ, bao gồm cả NVIDIA DGX SuperPOD.
Mỗi DGX A100 cung cấp:
- 05 petaflop hiệu suất
- 08 GPU A100 Tensor Core với bộ nhớ 40GB
- Sáu bộ switch NVS cho băng thông hai chiều 4,8TB
- 09 bộ giao tiếp mạng Mellanox Connectx-6 với băng thông hai chiều 450GB/s
- 02 CPU AMD 64 lõi để điều phối framework học sâu, khởi động và lưu trữ
- Bộ nhớ hệ thống 1TB
- 2 ổ M.2 NVME 2x 1,92TB để lưu trữ hệ điều hành và bộ nhớ SSD 15TB
…và DGX H100?
Mặc dù được NVIDIA thông báo là đến đầu năm sau (2023) mới cung cấp ra thị trường, thông tin về dòng ‘siêu GPU’ này đã được tiết lộ với các chỉ số hiệu năng gây choáng ngợp. Về tổng quan thì mẫu GPU cho data center mới này có hiệu năng xử lý AI gấp 4.5 lần so với thế hệ A100, băng thông nội bộ qua NVLink switch lên đến 900 Gigabytes/second,… và rất nhiều bổ sung khác được thêm vào để đưa việc triển khai dự án AI lên cấp độ chưa từng có.
Xem thêm thông tin chi tiết về H100 qua bài: Thông số kỹ thuật và hiệu năng của GPU NVIDIA H100 Hopper
GPU nào tốt nhất cho Học sâu?
Thật không may, không có câu trả lời dễ dàng. GPU tốt nhất cho dự án của bạn sẽ phụ thuộc vào mức độ trưởng thành của hoạt động AI của bạn, quy mô hoạt động của bạn cũng như các thuật toán và mô hình cụ thể mà bạn đang làm việc.
Ở giai đoạn ban đầu của dự án, bạn hoàn toàn có thể sử dụng các GPU cấp phổ thông phù hợp cho các tác vụ đơn giản, các thử nghiệm ở quy mô nhỏ. Nhưng khi dự án AI của bạn đi sâu hơn và với quy mô lớn dần, những GPU cấp cao được thiết kế chuyên dụng cho trung tâm dữ liệu và Deep Learning với khả năng liên kết và sizing theo thời gian là những lựa chọn gần như bắt buộc.
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- Hướng dẫn lựa chọn GPU phù hợp cho AI, Machine Learning
- 5 điều bạn cần biết về NVIDIA DGX Spark – Chiếc máy tính mơ ước của các nhà phát triển AI
- SLM và AI tại biên: Bình minh của một kỷ nguyên mới hay chỉ là cơn sốt nhất thời?