
Stream processing là xử lý liên tục các sự kiện dữ liệu mới khi chúng được nhận.
Stream processing là gì?
Stream (dòng/luồng) là một chuỗi các sự kiện liên tục của dữ liệu đi từ nơi sản xuất đến nơi tiêu thụ. Rất nhiều dữ liệu được tạo ra dưới dạng một luồng của các sự kiện, chẳng hạn như giao dịch tài chính, đo lường cảm biến hoặc nhật ký máy chủ web.

Các thư viện Stream processing, chẳng hạn như Streamz, giúp xây dựng các quy trình để quản lý các dòng dữ liệu liên tục, cho phép ứng dụng phản hồi các sự kiện khi chúng xảy ra.
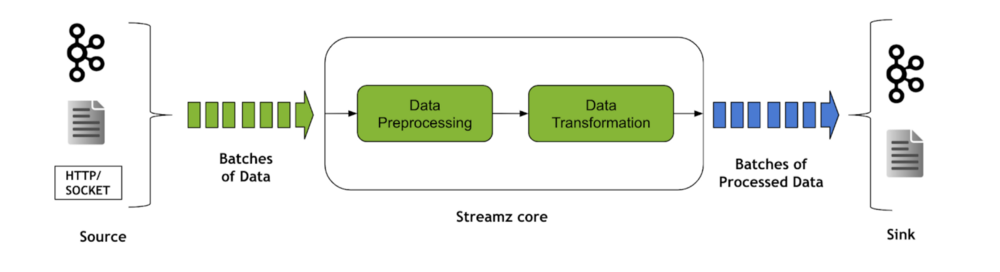
Quy trình stream processing thường bao gồm nhiều hành động như lọc, tổng hợp, đếm, phân tích, chuyển đổi, làm mới, phân nhánh, nối, kiểm soát lưu lượng, phản hồi về các giai đoạn trước, áp lực ngược và lưu trữ.
Tại sao cần đến Stream Processing?
Việc xử lý liên tục các luồng dữ liệu rất hữu ích trong nhiều ứng dụng như:
- Chăm sóc sức khỏe: giám sát liên tục dữ liệu thiết bị
- Thành phố thông minh: mô hình và quản lý ùn tắc giao thông
- Sản xuất: tối ưu hóa và dự đoán được thời gian bảo trì
- Giao thông vận tải: tối ưu hóa lộ trình và mức tiêu thụ nhiên liệu
- Ô tô: ô tô thông minh, ô tô tự lái
- An ninh mạng, phát hiện bất thường: xử lý nhật ký web hoặc khủng bố mạng
- Tài chính: dự doán được thời gian của thị trường chứng khoán
- Học máy: dự đoán theo thời gian thực
- Quảng cáo: quảng cáo dựa trên vị trí hoặc hành động của người tiêu dùng
Thị trường stream processing đang có sự tăng trưởng theo cấp số nhân với các doanh nghiệp phụ thuộc nhiều vào các hoạt động phân tích, suy luận, giám sát trong thời gian thực, v.v. Các dịch vụ được xây dựng trên tính năng phát trực tuyến hiện là thành phần cốt lõi của hoạt động kinh doanh hàng ngày và các sự kiện từ xa có cấu trúc cũng như nhật ký phi cấu trúc đang tăng trưởng với tốc độ hơn 5 lần so với cùng kỳ năm trước. Truyền tải dữ liệu lớn ở quy mô này đang trở nên cực kỳ phức tạp và khó thực hiện hiệu quả trong môi trường kinh doanh hiện đại, nơi việc truyền phát dữ liệu tin cậy, tiết kiệm chi phí là điều tối quan trọng.
Tăng tốc Stream Processing với GPU
NVIDIA RAPIDS cuStreamz là thư viện xử lý dữ liệu streaming được tăng tốc GPU đầu tiên, được xây dựng với mục tiêu tăng tốc thông lượng stream processing và giảm tổng chi phí sở hữu (TCO). Quy trình cuStreamz tại NVIDIA đã giúp tiết kiệm hàng trăm nghìn đô la mỗi năm. Được viết bằng Python, cuStreamz được xây dựng dựa trên RAPIDS, công cụ tăng tốc GPU cho các thư viện khoa học dữ liệu. Khả năng tăng tốc GPU từ đầu đến cuối đang nhanh chóng trở thành tiêu chuẩn, Flink adding GPU support và NVIDIA đã trở thành một phần của xu hướng này.
cuStreamz được xây dựng trên:
- Streamz, một thư viện Python mã nguồn mở giúp xây dựng các quy trình (pipelines) quản lý các luồng dữ liệu liên tục;
- Dask, một công cụ scheduler mạnh mẽ và tin cậy để song song hóa tải xử lý truyền phát trực tuyến;
- RAPIDS, bộ thư viện được tăng tốc bởi GPU được tận dụng để xử lý truyền phát.
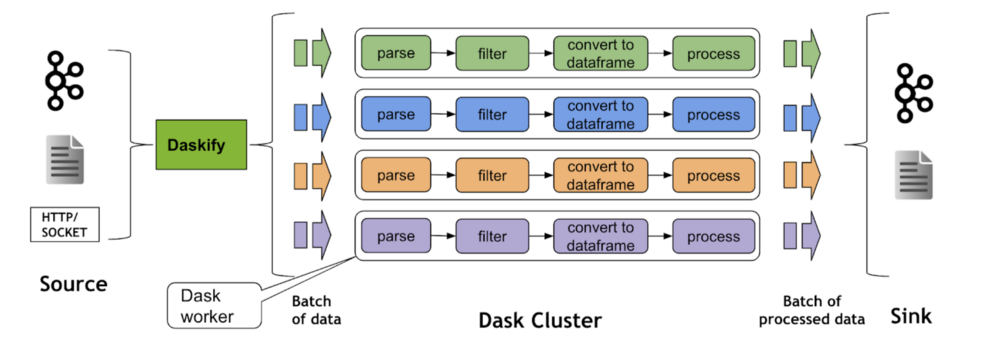
cuStreamz tăng tốc Streamz bằng cách tận dụng RAPIDS cuDF để tăng tốc xử lý truyền dữ liệu bằng GPU. cuStreamz cũng được hưởng lợi từ các trình đọc và ghi JSON, Parquet và CSV được tăng tốc của cuDF. Nhóm cuStreamz đã xây dựng một trình kết nối nguồn dữ liệu trực tiếp vào các dataframe của cuDF, giúp tăng đáng kể hiệu suất từ đầu đến cuối. Sau đó, các streaming pipeline có thể được song song hóa bằng cách sử dụng Dask để chạy ở chế độ phân tán nhằm đạt được hiệu suất tốt hơn trên quy mô lớn.
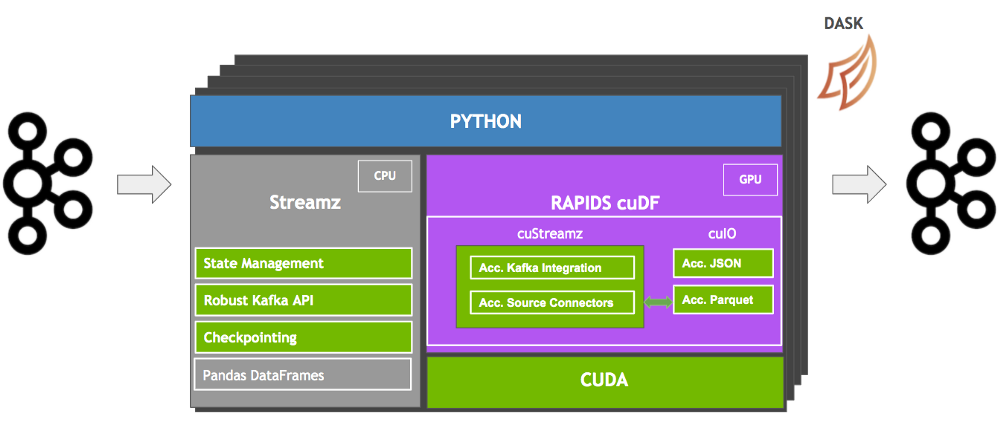
Kiến trúc cuStreamz được tóm tắt ở mức cao ở sơ đồ bên dưới. cuStreamz là cầu nối kết nối tính năng phát trực tuyến Python với GPU, đồng thời bổ sung các tính năng phát trực tuyến phức tạp và đáng tin cậy như điểm kiểm tra và quản lý trạng thái. cuStreamz cung cấp các khối xây dựng cần thiết để viết các tác vụ phát trực tuyến đáng tin cậy trên GPU với hiệu suất tốt hơn và chi phí thấp hơn.
Khoa học dữ liệu toàn diện, được tăng tốc bởi GPU
Bộ thư viện phần mềm nguồn mở RAPIDS, được xây dựng trên NVIDIA CUDA-X AI, cung cấp khả năng thực thi các quy trình phân tích và khoa học dữ liệu từ đầu đến cuối hoàn toàn trên GPU. Nó dựa trên các nguyên hàm NVIDIA CUDA để tối ưu hóa các lệnh xử lý cấp thấp nhưng vẫn giữ tính song song của GPU và tốc độ bộ nhớ băng thông cao thông qua giao diện Python thân thiện với người dùng.
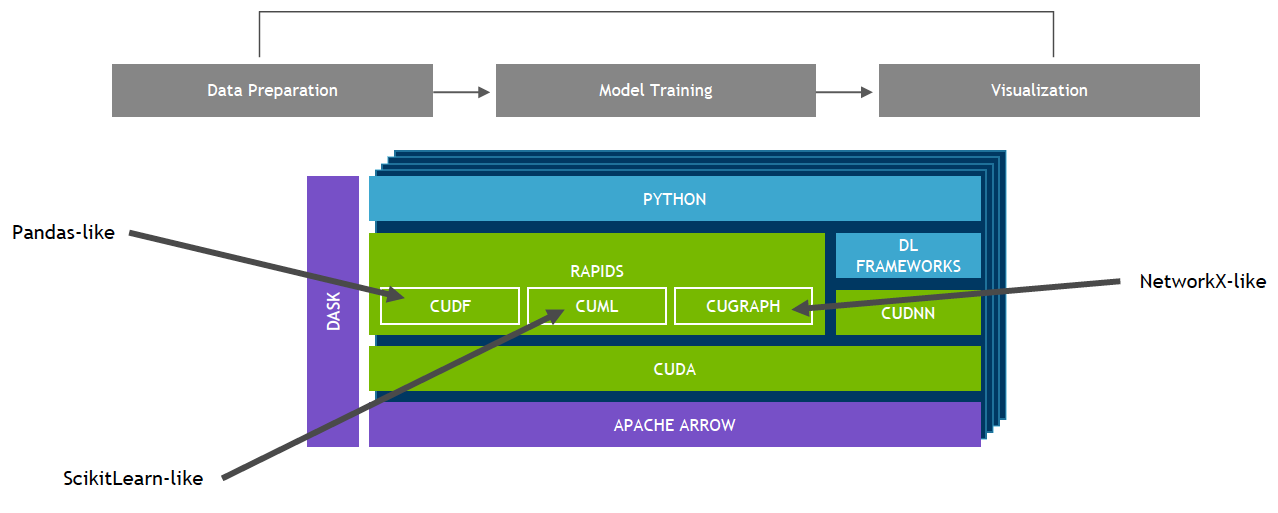
Với RAPIDS GPU DataFrame, dữ liệu có thể được tải lên GPU bằng giao diện giống như Pandas, sau đó được sử dụng cho các thuật toán phân tích biểu đồ và học máy được kết nối khác nhau mà không tách khỏi GPU. Mức độ tương tác này có thể thực hiện được thông qua các thư viện như Apache Arrow. Nó cho phép tăng tốc quy trình từ đầu đến cuối, từ việc chuẩn bị dữ liệu học máy cho đến học sâu.
Các thuật toán học máy cuML và các phép toán nguyên thủy của RAPIDS tuân theo API tương tự như scikit-learn. Nhiều thuật toán phổ biến như XGBoost được hỗ trợ cho cả triển khai GPU đơn và trung tâm dữ liệu lớn. Đối với các tập dữ liệu lớn, việc triển khai dựa trên GPU này có thể hoàn thành với tốc độ nhanh hơn 10-50 lần so với CPU.
RAPIDS hỗ trợ chia sẻ bộ nhớ thiết bị giữa nhiều thư viện khoa học dữ liệu phổ biến. Điều này giữ dữ liệu trên GPU và tránh việc sao chép qua lại vào vùng nhớ của host.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?