
Xây dựng một hệ thống lưu trữ từ một thiết bị lưu trữ duy nhất là điều đã quá dễ dàng. Nhưng việc tập hợp hàng chục nghìn thiết bị lưu trữ và biến chúng [trở thành] một hệ thống lưu trữ duy nhất là vô cùng khó khăn. Việc giải quyết thành công thách thức này trong hơn hai thập kỷ đã đưa DDN, nhà cung cấp giải pháp lưu trữ phân tán cho HPC, trở thành công ty dẫn đầu thị trường về lưu trữ dữ liệu ở quy mô siêu lớn (hyperscale). DDN là một tập thể với những cá nhân khao khát giải quyết các vấn đề kỹ thuật, và không có sự nghỉ ngơi ở đỉnh cao. Với mỗi năm trôi qua, các hệ thống ngày càng lớn hơn và việc tạo ra một hệ thống lưu trữ phân tán ảo trở nên khó khăn hơn. Quy mô của vấn đề liên quan trực tiếp đến số lượng thành phần trong hệ thống lưu trữ phân tán. Càng có nhiều thành phần, tỷ lệ lỗi càng cao và càng khó để che giấu những lỗi đó một cách minh bạch để tạo ra giao tiếp bề ngoài của một hệ thống lưu trữ duy nhất không thay đổi. Mặc dù số lượng thành phần trong một hệ thống lưu trữ thông thường từ lâu đã tăng lên theo từng năm, nhưng gần đây có hai xu hướng đã làm tăng tốc độ tăng trưởng này.
Xu hướng đầu tiên góp phần vào sự tăng trưởng nhanh chóng về số lượng thành phần trong một hệ thống lưu trữ phân tán thông thường là tốc độ tăng trưởng của từng thành phần lưu trữ riêng lẻ đã chậm lại.
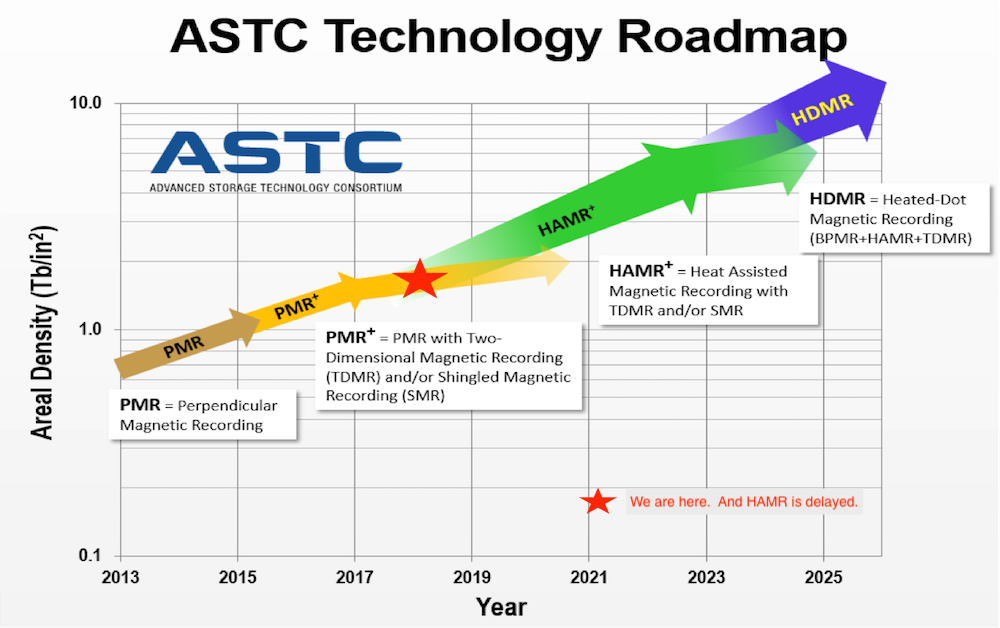
Sơ đồ sau từ Seagate cho thấy tốc độ tăng trưởng dung lượng ổ đĩa cứng là hằng số nhưng thật không may HAMR bị chậm lại và hiện tại chúng ta đang ở trong đường cong PMR phẳng. Do đó, tổng số ổ đĩa cứng trong một hệ thống lưu trữ thông thường đang tăng với tốc độ nhanh hơn trước đây.

Xu hướng thứ hai gây ra sự gia tăng số lượng thành phần trong một hệ thống lưu trữ phân tán thông thường là sự xuất hiện của nhiều nguồn dữ liệu hơn trước đây. Theo truyền thống, các hệ thống lưu trữ phân tán đóng vai trò là kho lưu trữ dữ liệu được tạo ra trên máy tính (ví dụ: đầu ra mô phỏng). Tuy nhiên, gần đây, nhu cầu về dung lượng ngày càng tăng do các luồng dữ liệu bổ sung từ cảm biến, thiết bị và Internet-of-Things nói chung. Những cơn sốt Trí tuệ Nhân tạo và học máy góp phần vào xu hướng này vì rõ ràng là độ chính xác suy luận được cải thiện với các tập dữ liệu lớn hơn. Nhu cầu về các giải pháp mở rộng dung lượng ngày càng tăng chóng mặt và không ngừng nghỉ.
Những xu hướng này đe dọa khả năng tiếp tục tạo ra viễn tưởng về một hệ thống lưu trữ duy nhất từ số lượng thành phần ngày càng tăng. Hai vấn đề đáng sợ nhất là dữ liệu có thể bị mất hoặc thậm chí tệ hơn là bị hỏng một cách âm thầm. Do đó, trách nhiệm lớn nhất đối với nhà cung cấp DDN là bảo vệ khách hàng khỏi những vấn đề này.
Để cung cấp các sản phẩm cân bằng về mặt kinh tế, bảo vệ chống mất dữ liệu đòi hỏi phải hiểu sâu sắc về việc phân phối lỗi và cơ chế bảo vệ. Các mô hình Markov chuẩn từ lâu đã đủ cho các mô hình trước và các thuật toán RAID truyền thống từ lâu đã đủ cho các mô hình về sau. Tuy nhiên, hiện nay chúng ta đã bước vào một chế độ mà các mô hình này không còn phù hợp nữa. Để giải quyết những hạn chế mới lộ ra của RAID truyền thống, tất cả các sản phẩm DDN hiện được trang bị Declustered Parity Redundancy (DCR) hàng đầu trong ngành. Tuy nhiên, tương lai còn mù mờ và có thể mang đến những hệ thống lớn hơn mà DCR không đủ. Do đó, hãng hiện đang bắt tay vào nghiên cứu với các đối tác chuyên sâu là Phòng thí nghiệm quốc gia Los Alamos (LANL) để đảm bảo các sản phẩm của hãng luôn đi trước các xu hướng về công nghệ và kiến trúc. Vì các mô hình Markov không còn phù hợp ở quy mô này nữa nên nghiên cứu của DDN sẽ xây dựng xung quanh các nghiên cứu mô phỏng cũng như các phương pháp chính thức để xác thực các mô phỏng.
LANL gần đây đã thành lập một nhóm có tên là Efficient Mission Centric Computing Consortium (EMC3) để nghiên cứu các vấn đề như thế này. DDN là nhà cung cấp đầu tiên tham gia vào nhóm này.
Theo DDN Blog

Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi hiện là đối tác phân phối của DataDirect Networks cho các giải pháp lưu trữ hiệu năng cao trong AI, Deep Learning.
DDN (DataDirect Networks) là nhà tiên phong toàn cầu trong lĩnh vực lưu trữ và quản lý dữ liệu hiệu suất cao. Hãng chuyên cung cấp các giải pháp hạ tầng AI và tính toán hiệu năng cao (HPC), giúp các tổ chức xử lý lượng dữ liệu khổng lồ một cách hiệu quả. DDN được tin cậy bởi các doanh nghiệp lớn, trung tâm nghiên cứu và siêu máy tính trên toàn thế giới để tăng tốc các ứng dụng AI và phân tích.
Bạn muốn trở thành đối tác bán hàng DDN của NTC?
Bài viết liên quan
- Hướng dẫn triển khai máy chủ GPU tại chỗ trong các phòng máy doanh nghiệp
- NVIDIA ConnectX-8 SuperNIC: Đột phá kiến trúc hạ tầng AI với PCIe Gen6
- NVIDIA: Công nghệ Silicon Photonics và Co-Packaged Optics – Thay đổi cuộc chơi trong kỷ nguyên AI và HPC
- Khai thác tiềm năng dữ liệu trong doanh nghiệp: Tổng quan về các nền tảng phân tích hàng đầu
- Giải pháp tích hợp AI vào hệ thống lưu trữ dữ liệu doanh nghiệp: Tương lai đã đến!
- NVIDIA NVLink Thế hệ thứ 5: Bước nhảy vọt về băng thông cho kỷ nguyên AI nghìn tỷ tham số