
Dask là một thư viện mã nguồn mở linh hoạt dành cho xử lý song song và phân tán bằng Python.
Dask hoạt động như thế nào?
Dask là một thư viện mã nguồn mở được thiết kế để cung cấp khả năng xử lý song song hóa với Python stack. Cung cấp khả năng tích hợp với các thư viện Python như NumPy Arrays, Pandas DataFrames và Scikit-Learn để cho phép thực thi song song trên nhiều nhân, nhiều đơn vị xử lý và hệ thống máy tính mà không cần phải học các thư viện hoặc ngôn ngữ mới.
Thư viện Dask được cấu thành bởi hai phần:
- Một Collections API cho các lists, arrays và DataFrame song song để mở rộng quy mô từ gốc cho NumPy, Pandas và Scikit-Learn chạy trong môi trường phân tán hoặc lớn hơn bộ nhớ. Dask collections là các collection song song từ thư viện nền (ví dụ: Dask array bao gồm các Numpy array) và chạy trên bộ lập lịch tác vụ.
- Trình lập lịch tác vụ để xây dựng biểu đồ tác vụ cũng như điều phối, lên lịch và giám sát các tác vụ được tối ưu hóa cho khối lượng công việc tương tác trên các cores CPU và hệ thống máy tính.


Ba parallel collections (tập hợp song song hóa) của Dask được gọi là DataFrames, Bags và Arrays, mỗi tập hợp cũng có thể tự động sử dụng dữ liệu được phân vùng giữa RAM và disk, được phân phối trên nhiều nodes trong một cụm, tùy thuộc vào tình trạng sẵn có của tài nguyên. Đối với các bài toán có thể song song hóa nhưng không phù hợp với các khái niệm trừu tượng cấp cao như Dask Arrays hoặc DataFrames, có một hàm “delayed” sử dụng trong Python để sửa đổi các hàm sao cho chúng hoạt động một cách trì hoãn. Có nghĩa là việc thực thi bị trì hoãn, hàm và các đối số của nó được đặt vào biểu đồ nhiệm vụ.
Bộ lập lịch tác vụ của Dask có thể mở rộng tới các cụm hàng nghìn nodes và các thuật toán đã được thử nghiệm trên một số siêu máy tính lớn. Giao diện lập lịch tác vụ có thể được tùy chỉnh cho các công việc cụ thể. Dask mang lại chi phí thấp, độ trễ thấp và tuần tự hóa tối thiểu cần thiết cho tốc độ.
Trong kịch bản phân tán, người lập lịch trình sẽ điều phối nhiều công việc và chuyển tính toán đến đúng công việc mình muốn để duy trì liên tục, không bị ngắt quãng. Một số người dùng có thể chia sẻ cùng một hệ thống. Cách tiếp cận này hoạt động với hệ thống tệp Hadoop HDFS, các nơi lưu trữ cloud object như bộ lưu trữ S3 của Amazon.
Bộ lập lịch cho một máy đơn được tối ưu hóa để sử dụng nhiều hơn bộ nhớ và phân chia các tác vụ trên nhiều threads và processors. Nó sử dụng phương pháp tiếp cận có chi phí thấp, tiêu tốn khoảng 50 micro giây cho mỗi tác vụ.
Tại sao lại cần đến Dask?
Ngôn ngữ lập trình cấp cao, thân thiện với người dùng của Python và các thư viện python như NumPy, Pandas và scikit-learn đã được các nhà khoa học dữ liệu áp dụng đáng kể.
Được phát triển trước khi các trường hợp sử dụng dữ liệu lớn trở nên phổ biến, các thư viện này không có giải pháp mạnh mẽ cho tính song song. Python là lựa chọn phù hợp cho điện toán single-core, nhưng người dùng buộc phải tìm các giải pháp khác cho tính song song multi-core hoặc multi-machine. Điều này gây ra sự gián đoạn trải nghiệm cho người dùng.
Nhu cầu ngày càng tăng về quy mô khối lượng công việc trong Python đã dẫn đến sự phát triển tự nhiên của Dask trong 5 năm qua. Dask dễ dàng cài đặt, được cung cấp nhanh chóng để tăng tốc độ phân tích dữ liệu trong Python mà không yêu cầu nhà phát triển nâng cấp cơ sở hạ tầng phần cứng hoặc chuyển sang ngôn ngữ lập trình khác. Cú pháp được sử dụng để khởi chạy các công việc Dask giống như cú pháp được sử dụng cho các hoạt động Python khác.
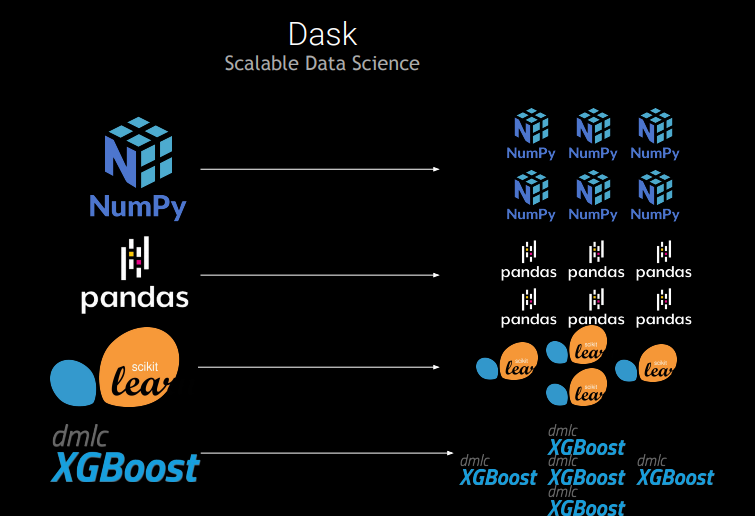
Phổ biến với các nhà phát triển web, Python có một hệ thống networking mạnh mẽ mà Dask tận dụng để xây dựng một hệ thống điện toán phân tán linh hoạt, hiệu quả, có khả năng mở rộng nhiều khối lượng công việc khác nhau. Tính linh hoạt của Dask giúp nó nổi bật so với các giải pháp dữ liệu lớn khác như Hadoop hoặc Apache Spark và việc hỗ trợ mã nguồn giúp người dùng Python và nhà phát triển C/C++/CUDA đặc biệt dễ dàng làm việc.
Dask đã nhanh chóng được cộng đồng nhà phát triển Python chấp nhận và phát triển cùng với sự phổ biến của Numpy và Pandas, cung cấp các tiện ích mở rộng có giá trị cho Python để giải quyết các phân tích đặc biệt và tính toán toán học.
Quy mô tốt hơn nhiều so với Pandas và hoạt động đặc biệt tốt trên các tác vụ dễ dàng song song hóa, chẳng hạn như sắp xếp dữ liệu trên hàng nghìn bảng tính. Trình tăng tốc có thể tải hàng trăm Pandas DataFrames vào bộ nhớ và phối hợp chúng với một lần trừu tượng hóa duy nhất.
Ngày nay, Dask được quản lý bởi một cộng đồng các nhà phát triển bao gồm hàng chục tổ chức và dự án PyData như Pandas, Jupyter và Scikit-Learn. Sự tích hợp của Dask với các công cụ phổ biến này đã dẫn đến việc áp dụng tăng lên nhanh chóng, với khoảng 20% trong số các nhà phát triển cần các công cụ dữ liệu lớn Pythonic.

Dask hiệu suất hơn khi có GPU
Về mặt kiến trúc, CPU chỉ bao gồm một vài cores với nhiều bộ nhớ đệm có thể xử lý một số threads phần mềm cùng một lúc. Ngược lại, GPU bao gồm hàng trăm cores có thể xử lý hàng nghìn threads cùng một lúc.
GPU cung cấp công nghệ điện toán song song chưa từng có.
Dask + NVIDIA: Thúc đẩy phân tích dữ liệu
NVIDIA hiểu rõ sức mạnh mà GPU mang lại cho việc phân tích dữ liệu. Đó là lý do họ đã nỗ lực hết sức để uỷ quyền cho những người thực hành khoa học dữ liệu, học máy và trí tuệ nhân tạo để tận dụng tối đa dữ liệu của họ. Nhận thấy sức mạnh và khả năng truy cập linh hoạt của Dask, NVIDIA bắt đầu sử dụng nó trong dự án RAPIDS với mục tiêu mở rộng quy mô khối lượng công việc phân tích dữ liệu được tăng tốc cho nhiều GPU.
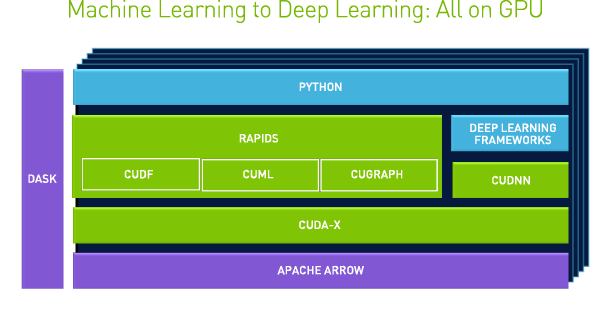
Giao diện Python dễ tiếp cận và tính linh hoạt ngoài khoa học dữ liệu, Dask đã phát triển sang các dự án khác trên khắp NVIDIA, trở thành lựa chọn mặc nhiên trong các ứng dụng mới, từ phân tích cú pháp JSON đến quản lý quy trình học sâu từ đầu đến cuối. Dưới đây là một số dự án và sự hợp tác của NVIDIA sử dụng Dask:
RAPIDS
RAPIDS là một bộ thư viện phần mềm mã nguồn mở và API để thực thi quy trình khoa học dữ liệu hoàn toàn trên GPU, giảm thời gian đào tạo từ vài ngày xuống còn vài phút. Được xây dựng dựa trên CUDA, RAPIDS kết hợp nhiều năm phát triển về đồ họa, học máy, điện toán hiệu năng cao (HPC), v.v.
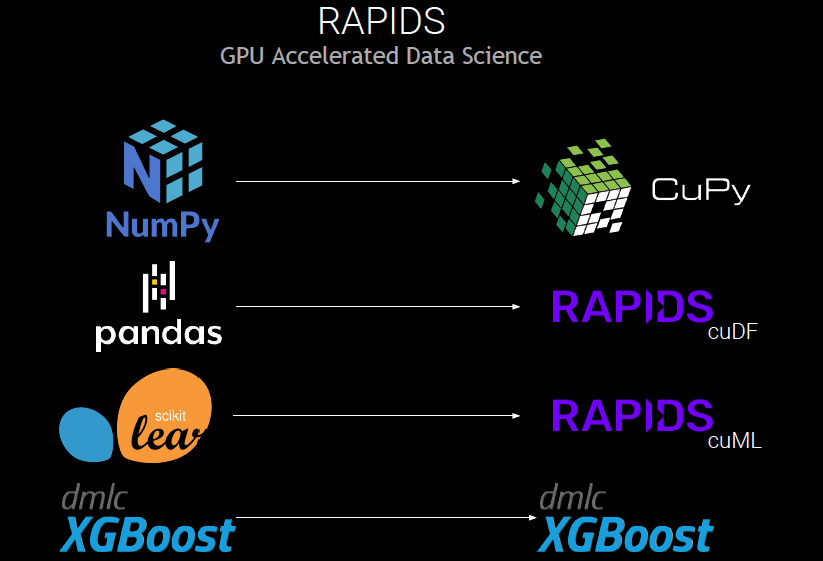
Mặc dù CUDA cực kỳ mạnh mẽ nhưng hầu hết những người thực hành phân tích dữ liệu đều thích thử nghiệm, xây dựng và đào tạo các mô hình bằng bộ công cụ Python, như NumPy, Pandas và Scikit-Learn đã nói ở trên. Dask là một thành phần quan trọng của hệ sinh thái RAPIDS, giúp người thực hành dữ liệu thậm chí còn dễ dàng tận dụng lợi thế của điện toán tăng tốc thông qua trải nghiệm người dùng dựa trên Python.
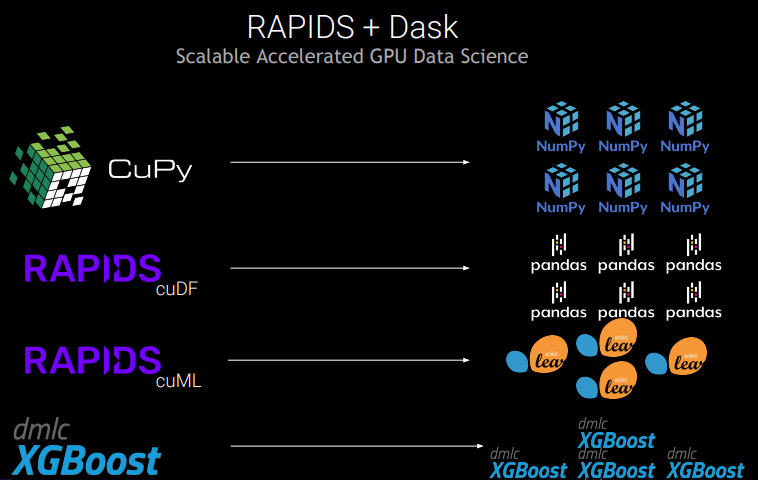
NVTabular
NVTabular là một thư viện tiền xử lý và kỹ thuật tính năng được thiết kế để thao tác nhanh chóng và dễ dàng hàng terabyte của bộ dữ liệu dạng bảng. Được xây dựng trên thư viện Dask-cuDF, cung cấp lớp trừu tượng cấp cao giúp đơn giản hóa việc tạo các hoạt động ETL hiệu suất cao ở quy mô lớn. NVTabular có thể mở rộng tới hàng nghìn GPU bằng cách tận dụng RAPIDS và Dask, loại bỏ tình trạng tắc nghẽn khi chờ quá trình ETL kết thúc.
BlazingSQL
BlazingSQL là một công cụ SQL phân phối cực kỳ nhanh trên GPU cũng được xây dựng dựa trên Dask-cuDF. Cho phép các nhà khoa học dữ liệu dễ dàng kết nối các bộ lưu trữ dữ liệu quy mô lớn với các phân tích được tăng tốc bằng GPU. Với một vài dòng mã, người thực hành có thể truy vấn trực tiếp các định dạng tệp thô như CSV và Apache Parquet bên trong bộ lưu trữ dữ liệu như HDFS và AWS S3, đồng thời chuyển trực tiếp kết quả vào bộ nhớ GPU.
BlazingDB Inc, công ty đứng sau BlazingSQL, đóng góp cốt lõi cho RAPIDS và hợp tác chặt chẽ với NVIDIA.
cuStreamz
Trong nội bộ NVIDIA sử dụng Dask để cung cấp năng lượng cho các bộ phận sản phẩm và hoạt động kinh doanh. Sử dụng Streamz, Dask và RAPIDS, họ đã xây dựng cuStreamz, một nền tảng dữ liệu phát trực tuyến được tăng tốc bằng cách sử dụng 100% Python nguyên gốc. Với cuStreamz, họ có thể tiến hành phân tích theo thời gian thực cho một số ứng dụng có yêu cầu khắt khe nhất như GeForce NOW, NVIDIA GPU Cloud và NVIDIA DRIVE Sim. Mặc dù đây là một dự án non trẻ nhưng NVIDIA đã thấy tổng chi phí sở hữu giảm đáng kể so với các nền tảng dữ liệu phát trực tuyến khác bằng cách sử dụng cuStreamz hỗ trợ Dask.
Các trường hợp sử dụng cho Dask
Khả năng xử lý hàng trăm terabyte dữ liệu một cách hiệu quả của Dask khiến nó trở thành một công cụ mạnh mẽ để bổ sung tính song song cho quá trình xử lý học máy (ML). Cho phép thực hiện nhanh hơn việc phân tích bộ dữ liệu lớn, đa chiều, đồng thời tăng tốc và mở rộng quy trình hoặc quy trình làm việc của khoa học dữ liệu. Do đó, có thể được sử dụng trong nhiều trường hợp sử dụng khác nhau trong HPC, dịch vụ tài chính, an ninh mạng và bán lẻ. Ví dụ: Dask làm việc với quy trình công việc Numpy để cho phép phân tích dữ liệu đa chiều trong Địa học, hình ảnh vệ tinh, gen, ứng dụng y sinh và thuật toán học máy.
Sử dụng Pandas DataFrames, Dask có thể kích hoạt các ứng dụng trong phân tích chuỗi thời gian, thông minh kinh doanh và chuẩn bị dữ liệu. Dask-ML, một thư viện dành cho học máy song song và phân tán, được sử dụng với Scikit-Learn và XGBoost để tạo ra chương trình đào tạo và dự đoán có thể mở rộng trên các mô hình và bộ dữ liệu lớn. Các nhà phát triển có thể sử dụng quy trình làm việc Dask tiêu chuẩn để chuẩn bị và thiết lập dữ liệu, sau đó chuyển dữ liệu cho XGBoost hoặc Tensorflow.
Dask + RAPIDS: Kích hoạt đổi mới trong doanh nghiệp
Nhiều công ty đang áp dụng cả Dask và RAPIDS để mở rộng quy mô một số hoạt động quan trọng. Một số đối tác lớn của NVIDIA, những người dẫn đầu trong ngành của họ, đang sử dụng chúng để tăng cường khả năng phân tích dữ liệu. Dưới đây là một số ví dụ thú vị gần đây:
Capital One
Với sứ mệnh “thay đổi hoạt động ngân hàng theo hướng tốt đẹp”, Capital One đã đầu tư rất nhiều vào phân tích dữ liệu quy mô lớn để cung cấp các sản phẩm và dịch vụ tốt hơn cho khách hàng cũng như nâng cao hiệu quả hoạt động trên toàn doanh nghiệp. Với một cộng đồng lớn gồm các nhà khoa học dữ liệu thân thiện với Python, Capital One sử dụng Dask và RAPIDS để mở rộng quy mô và tăng tốc khối lượng công việc Python khó có thể song song theo truyền thống và giảm bớt đáng kể thời gian học tập cho phân tích dữ liệu lớn.
Trung tâm tính toán khoa học nghiên cứu năng lượng quốc gia
Tận tâm cung cấp tài nguyên tính toán và kiến thức chuyên môn cho nghiên cứu khoa học cơ bản, NERSC là công ty hàng đầu thế giới trong việc thúc đẩy khám phá khoa học thông qua tính toán. Một phần của sứ mệnh đó là giúp các nhà nghiên cứu có thể tiếp cận siêu máy tính để thúc đẩy hoạt động khám phá khoa học. Với Dask và RAPIDS, sức mạnh đáng kinh ngạc của siêu máy tính mới nhất “Perlmutter” trở nên dễ dàng tiếp cận bởi các nhà nghiên cứu và nhà khoa học có kiến thức nền tảng hạn chế về siêu máy tính. Bằng cách tận dụng Dask để tạo ra một giao diện quen thuộc, họ đặt sức mạnh của siêu máy tính vào tay các nhà khoa học nhằm thúc đẩy những đột phá tiềm năng trên các lĩnh vực.
Phòng thí nghiệm quốc gia Oak Ridge
Giữa đại dịch toàn cầu, Phòng thí nghiệm quốc gia Oak Ridge vượt qua ranh giới của sự đổi mới bằng cách xây dựng một “phòng thí nghiệm ảo” để nghiên cứu ra thuốc trong cuộc chiến chống lại COVID-19. Bằng cách sử dụng GPU Dask, RAPIDS, BlazingSQL và NVIDIA, các nhà nghiên cứu có thể sử dụng sức mạnh của siêu máy tính Summit để sàng lọc khả năng của các hợp chất phân tử nhỏ liên kết với protease chính của SARS-CoV-2. Với bộ công cụ linh hoạt như vậy, các kỹ sư có thể thiết lập và chạy quy trình làm việc tùy chỉnh này trong vòng chưa đầy hai tuần và xem kết quả truy vấn tính bằng giây.
Phòng thí nghiệm Walmart
Một gã khổng lồ trong lĩnh vực bán lẻ, Walmart sử dụng bộ dữ liệu khổng lồ để phục vụ khách hàng tốt hơn, dự đoán nhu cầu sản phẩm và nâng cao hiệu quả nội bộ. Dựa vào phân tích dữ liệu quy mô lớn để hoàn thành các mục tiêu này, Walmart Labs đã chuyển sang Dask, XGBoost và RAPIDS để giảm thời gian đào tạo xuống 100 lần, cải thiện độ chính xác và lặp lại mô hình nhanh chóng để tiếp tục hoạt động kinh doanh. Với Dask, họ mở ra sức mạnh của NVIDIA GPU cho các nhà khoa học dữ liệu để giải quyết những vấn đề khó khăn của họ.
Dask trong doanh nghiệp: Một thị trường đang phát triển
Với sự thành công ngày càng tăng ở các tổ chức lớn, ngày càng có nhiều công ty đáp ứng nhu cầu về các sản phẩm và dịch vụ của Dask trong doanh nghiệp. Dưới đây là một số công ty đang giải quyết nhu cầu Dask của doanh nghiệp, báo hiệu sự khởi đầu của một thị trường trưởng thành:
Anaconda
Như phần lớn hệ sinh thái SciPy, Dask bắt đầu tại Anaconda Inc, nơi nó có sức hút và phát triển thành một cộng đồng nguồn mở lớn hơn. Khi cộng đồng phát triển và các doanh nghiệp bắt đầu áp dụng Dask, Anaconda bắt đầu cung cấp các dịch vụ tư vấn, đào tạo và hỗ trợ nguồn mở để doanh nghiệp dễ dàng sử dụng. Là nhà đề xuất chính về phần mềm nguồn mở, Anaconda cũng sử dụng nhiều Dask maintainers, cung cấp sự hiểu biết sâu sắc về phần mềm cho khách hàng doanh nghiệp.
Coiled
Được thành lập bởi những Dask maintainers như trưởng dự án Dask và cựu NVIDIAN Matthew Rocklin Coiled cung cấp giải pháp được quản lý xung quanh Dask để giúp dễ dàng trong cả môi trường đám mây và doanh nghiệp, cũng như hỗ trợ doanh nghiệp giúp tối ưu hóa phân tích Python trong các tổ chức. Sản phẩm triển khai được quản lý được lưu trữ công khai cung cấp một cách mạnh mẽ nhưng trực quan để sử dụng cả Dask và RAPIDS đến hiện nay.
Quansight
Dành riêng cho việc giúp các doanh nghiệp tạo ra giá trị từ dữ liệu của họ, Quansight cung cấp nhiều dịch vụ khác nhau để thúc đẩy phân tích dữ liệu trong các ngành. Tương tự như Anaconda, Quansight cung cấp dịch vụ tư vấn và đào tạo cho các doanh nghiệp sử dụng Dask. Được tích hợp với hệ sinh thái PyData và NumFOCUS, Quansight cũng cung cấp hỗ trợ cho các doanh nghiệp cần cải tiến hoặc sửa lỗi trong phần mềm nguồn mở.
Tại sao Dask lại quan trọng đối với nhóm khoa học dữ liệu
Đó là tất cả về khả năng tăng tốc và hiệu quả. Các nhà phát triển làm việc trên các thuật toán tương tác muốn thực thi nhanh chóng để họ có thể sửa đổi các dữ liệu “đầu vào” và “biến”. Máy tính để bàn và máy tính xách tay có bộ nhớ hạn chế có thể bị thiếu tài nguyên khi chạy các tập dữ liệu lớn. Dask có chức năng vượt trội giúp xử lý hiệu quả hơn ngay cả trên một CPU. Khi áp dụng cho một cụm, việc thực thi một thao tác trên nhiều CPU và GPU có thể được thực hiện bằng một lệnh duy nhất giúp giảm 90% thời gian xử lý. Dask cho phép các tập dữ liệu đào tạo rất lớn điển hình của học máy chạy trong các môi trường mà lẽ ra không thể hỗ trợ chúng.
Với cấu trúc mã thấp, mô hình thực thi chi phí thấp và tích hợp dễ dàng vào quy trình làm việc Python, Pandas và Numpy, Dask nhanh chóng trở thành một phần trong bộ công cụ của mọi nhà phát triển Python.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?