Nhìn chung, các nhà sản xuất chip lớn nhất thế giới khá kín kẽ về các siêu máy tính (supercomputer) khổng lồ mà họ sử dụng để thiết kế và thử nghiệm các thiết bị của họ. Nhưng thi thoảng, Intel và AMD cũng đã tiết lộ một số manh mối về các hệ thống đặc biệt này của họ.
Chúng tôi không rõ NVidia đã sử dụng loại tài nguyên nào cho các hệ thống EDA của họ – chúng tôi đang cố gắng tìm hiểu về điều này – nhưng chỉ biết rằng họ vừa nâng cấp một siêu máy tính rất mạnh để phát triển trí tuệ nhân tạo, và cũng để thực hiện mục tiêu kép của họ với mảng kinh doanh thiết kế chip.
Là một phần của hội nghị siêu máy tính SC17, NVidia đã giới thiệu thế hệ tiếp theo của hệ thống điện toán lai CPU-GPU có tên gọi là “SaturnV”, có hiệu năng cao hơn, đa dạng hơn, nhờ vào việc sử dụng bộ tăng tốc GPU Tesla V100 dựa trên kiến trúc Volta độc quyền của Nvidia bên trong nền tảng máy chủ AI DGX-1.


Hệ thống Saturn V phiên bản đầu tiên, được trình làng tại hội nghị SC16 năm ngoái, dựa trên các máy chủ DGX-1 và bộ tăng tốc GPU Tesla P100, có ít oomph hơn và không hỗ trợ Tensor Core, tính năng hiện có trên dòng GPU Volta chuyên cho các xử lý machine learning. Hệ thống này có 124 máy chủ DGX-1P, mỗi máy chủ có hai bộ xử lý 20 nhân Broadwell Xeon E5 tốc độ 2,2 GHz, bộ nhớ CPU 512 GB và tám GPU P100 ở dạng SXM2 form-factor cho phép chúng được cắm trực tiếp vào bo mạch chủ và thực hiện kết nối NVLink 1.0. Mỗi bộ tăng tốc GPU Tesla P100 đều có stack memory HBM2 16 GB và được liên kết trong một mạng lưới hybrid kết nối khối lập phương với nhau.

Sử dụng lưu trữ dữ liệu FP16 half-precision trong bộ nhớ GPU, tám GPU Pascal có thể cung cấp 170 teraflop hiệu suất tổng hợp cho các thuật toán học sâu và tổng cộng 42,5 teraflop cho các phép toán double-precision. Mặt chính trên hệ thống DGX-1P có trang bị PCI-Express Switch để liên kết GPU với cặp bộ điều hợp InfiniBand hai cổng 100Gbps từ Mellanox Technologies và bộ đôi cổng Ethernet 10Gbps đi ra từ các bộ xử lý Xeon. Hệ thống này có bốn ổ SSD flash 1,92 TB để lưu trữ băng thông cao, cần thiết để giúp cho CPU và GPU làm việc và quan trọng là bộ nhớ cache cực nhanh cho các thuật toán học máy. DGX-1P phù hợp với chassis 3U và tiêu tốn 3200 watt trên tất cả các thành phần của nó.
Trên 124 node DGX-1P đó, hệ thống Saturn V ban đầu có 4,9 petaflops hiệu suất dấu chấm động “peak double precision” và, chạy thử nghiệm toán học ma trận Linpack Fortran có thể mang lại hiệu quả tính toán 67,5% ở 3,31 petaflops, giúp mang lại vị trí số 28 trong danh sách 500 siêu máy tính hàng đầu của tháng 11 năm 2016. Có tổng cộng 350 kilowatt cho toàn bộ hệ thống, hoạt động lên tới 9,46 gigaflops mỗi watt, đây là máy Linpack tiết kiệm năng lượng nhất được thử nghiệm một năm trước. Mỗi máy chủ DGX-1P có giá niêm yết 129.000 USD và bao gồm giá trị của AI software-stack, gói support, và thêm vào một mạng InfiniBand có khả năng kết hợp tất cả các máy chủ trong mạng EDR InfiniBand hai tầng, chúng tôi nghĩ rằng Saturn V phiên bản ban đầu có giá khoảng 18 triệu USD theo giá niêm yết, hoặc khoảng 3,750 USD mỗi peak teraflop. Máy này có thể được giảm giá trong môi trường thực tế, nhưng do sự khan hiếm và nhu cầu cao của nó, có thể là không.
Nếu Intel có cổng NVLink trên Xeons, hiệu năng chắc chắn sẽ cao hơn không nghi ngờ gì nữa, và có một lý do thuyết phục để Nvidia dự tính tạo ra một biến thể Power9 của DGX-1. Ví dụ, bạn có thể gọi nó là DGP-1V, nghĩa là sự kết hợp của bộ xử lý Power9, kết nối NVLink 2.0 và bộ tăng tốc Volta. Với các cổng NVLink trên CPU và sự kết hợp bộ nhớ cache trên bộ nhớ CPU và GPU, hiệu suất hiệu suất sẽ được cải thiện đáng kể.
Điều đó đưa chúng ta đến bước lặp mới của hệ thống Saturn V, dựa trên các hệ thống DGX-1V được nâng cấp đóng gói GPU Volta. Theo như chúng tôi biết, các hệ thống DGX-1V chưa được nâng cấp lên bộ xử lý của Sk Skakeake Xeon SP của Intel và không có lý do nào để làm như vậy khi xem xét rằng chúng có giá cao hơn thế hệ Xe Broadwell trước loại công việc .

Hệ thống máy Saturn V phiên bản mới sẽ giống một con mãnh long hơn, với 660 nodes và nó sử dụng bộ tăng tốc Tesla V100, rõ ràng có nhiều oomph hơn. Hệ thống Saturn V thế hệ thứ hai cùng có tám bộ tăng tốc GPU cho mỗi node, nhưng lần này là sử dụng kết nối NVLink 2.0 nhanh hơn để liên kết các GPU, chia sẻ bộ nhớ và luồng xử lý. Cụm này có tổng cộng 5.280 bộ tăng tốc GPU Volta, mang lại 80 petaflops hiệu suất cực đại ở single-precision và 40 petaflops ở double-precision, theo lý thuyết sẽ làm cho nó nằm trong số mười hệ thống hàng đầu trên thế giới ngay cả ở “double precision floating point”. Nhờ tính năng hỗ trợ Tensor Core, hệ thống sẽ có hiệu suất hiệu quả đối với khối lượng công việc học máy của 660 petaflops (đó là sự pha trộn giữa FP32 và FP16).
Đối với bảng xếp hạng Green 500 và Top 500 vào tháng 11, Nvidia chỉ thử nghiệm một phần 33 nút của máy Saturn V thế hệ tiếp theo. Hệ thống đặc biệt này có hiệu suất cực đại về mặt lý thuyết là 1,82 petaflop với độ chính xác gấp đôi và mang lại 1,07 petaflop trong thử nghiệm Linpack, cho hiệu quả tính toán là 58,8%. Mặc dù hiệu suất tính toán đó thấp hơn đáng kể so với Saturn V ban đầu, hệ thống này chỉ đốt cháy 97 kilowatt và dù sao cũng đã đạt được 15,1 gigaflop tuyệt vời trên mỗi watt trên Linpack. Với một loạt các điều chỉnh, hiệu suất có thể tăng lên và hiệu quả thậm chí còn cao hơn.
Nvidia không cung cấp giá cho kế hoạch nâng cấp cho Saturn V thế hệ tiếp theo, nhưng DGX-1V có giá niêm yết là 149.000 đô la một pop, được tải lên. Mạng InfiniBand phức tạp hơn một chút trong khoảng thời gian này và chúng tôi nghĩ rằng sẽ đắt hơn và ước tính rằng, tùy thuộc vào cách mạng đó được định giá (và không bao gồm hệ thống tệp Luster hoặc GPFS bên ngoài), Saturn V mới này có thể có giá ở đâu đó 100 triệu đến 110 triệu đô la theo giá niêm yết với hỗ trợ ngăn xếp AI đầy đủ, không có bộ nhớ ngoài và mạng EDR InfiniBand khá mạnh. Nếu các tỷ lệ Linpack được giữ – và không có lý do gì để tin rằng nó sẽ không – trên toàn bộ 660 nút, vẫn chưa được xây dựng, thì đôi khi Nvidia sẽ có xếp hạng khoảng 22,3 petaflop trên Sao Thổ hoàn toàn thế hệ tiếp theo V trong bài kiểm tra Linpack, hệ thống này sẽ trở thành hệ thống hiệu suất cao thứ ba được thử nghiệm cho Top 500 và rõ ràng trong số các siêu máy tính hàng đầu trên thế giới (bao gồm cả những hệ thống chưa chạy Linpack và đưa chúng vào Top 500). Và với mức giá 90 triệu USD, cỗ máy Saturn V thế hệ tiếp theo sẽ cung cấp Linpack điểm nổi DP với chi phí khoảng 40.300 USD mỗi teraflop – nhiều hơn một chút so với Saturn V dựa trên Pascal – nhưng mang lại hiệu quả tăng giá / hiệu năng rất lớn cho máy khối lượng công việc học tập. DGX-1P có 170 teraflop hiệu suất học máy tại FP16, nhưng DGX-1V có 960 teraflop sử dụng Lõi kéo, hoặc hệ số 5,6X. Ngay cả khi hệ thống Saturn V thế hệ thứ hai có giá cao hơn rất nhiều, thì việc kiếm tiền từ các công việc đào tạo và suy luận về máy học này sẽ tốt hơn rất nhiều. Sẽ rất thú vị khi xem đường phố thực sự định giá những hệ thống này và các hệ thống hybrid khác sử dụng bộ tăng tốc GPU Volta như thế nào. Nó sẽ là khó khăn, thực sự.
Dù hệ thống máy Saturn V thế hệ tiếp theo có chi phí Nvidia để xây dựng và sau đó bán cho chính nó, điều này thể hiện một khoản đầu tư khá lớn cho bất kỳ công ty nào. Mọi người có thể nghĩ rằng Nvidia đang bán máy cho chính nó với chi phí, nhưng không quá nhanh về điều đó. Nvidia có thể có một bộ phận hoặc nhiều bộ phận đang sử dụng nó mua nó từ nhóm trung tâm dữ liệu Tesla với giá đầy đủ và tăng đáng kể doanh thu được báo cáo trong đơn vị Tesla đó. Chúng tôi nghĩ rằng công ty sẽ phân chia sự khác biệt. Nhưng nó sẽ không ở đâu thấp như những gì Bộ năng lượng Hoa Kỳ đang chi trả cho các hệ thống của Hội nghị thượng đỉnh Hồi giáo và Giới hạn Sierra cho Phòng thí nghiệm quốc gia Oak Ridge và Phòng thí nghiệm quốc gia Lawrence Livermore. Họ đang nhận được hai máy với đỉnh kết hợp là 325 petaflop với giá $ 325 triệu. Nếu hai phần ba flops thực sự có thể chạy Linpack trong các máy này, đây là khoảng 15.000 đô la mỗi teraflop. Chính phủ Mỹ đang nhận được một thỏa thuận khá, thực sự. Sau đó, một lần nữa, chú Sam đã trả tiền cho việc phát minh ra công nghệ này, vì vậy có điều đó.
Ngoài các nguồn cấp dữ liệu và tốc độ và chi phí tiềm năng của hệ thống Saturn V thế hệ tiếp theo, có những cân nhắc về kiến trúc hệ thống và mạng để nghĩ đến khi xây dựng một hệ thống như vậy. Phil Rogers, một kiến trúc sư máy chủ tại Nvidia, đã mô tả tại một phiên tại SC17 về cách cấu trúc của máy Saturn V mới.
Khối xây dựng cơ bản là cụm mười hai nút trông như thế này:
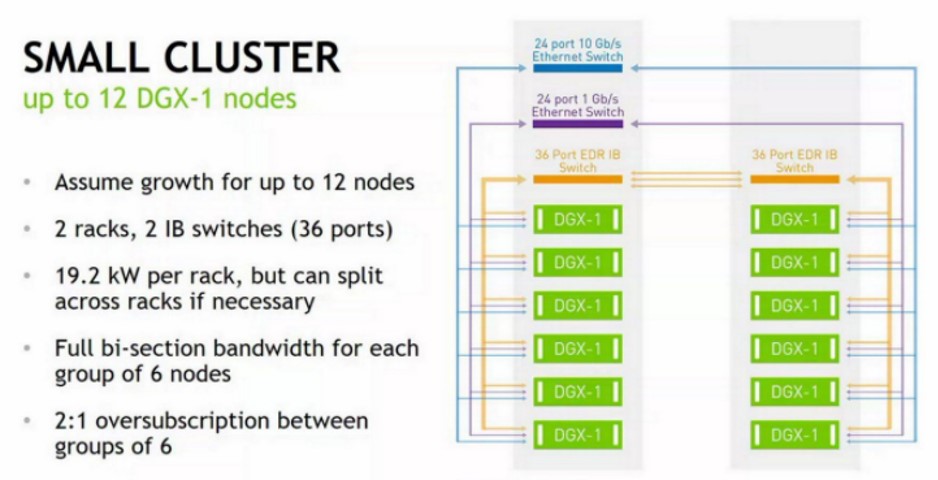
Điều đầu tiên bạn lưu ý từ hai bức ảnh Saturn V là bạn không thể, ở các mật độ năng lượng này, làm quá tải các giá đỡ và vẫn sử dụng làm mát không khí. Vì vậy, Nvidia chỉ đặt sáu nút DGX-1P vào một giá đỡ. Có một công tắc EDR InfiniBand 36 cổng từ Mellanox Technologies ở đầu mỗi giá để liên kết các nút với nhau trong giá và trên các giá đỡ. Có một công tắc Ethernet 24 cổng 10 Gb / giây để liên kết các nút ra với bộ lưu trữ ngoài và với người dùng hệ thống, và một công tắc 24 cổng 1 Gb / giây được sử dụng để quản lý các nút DGX-1P trong cụm này .
Cấp độ tiếp theo, ba trong số các cụm nhỏ này được tổ chức thành một cụm có kích thước trung bình, mà Nvidia gọi là một nhóm, như thế này:
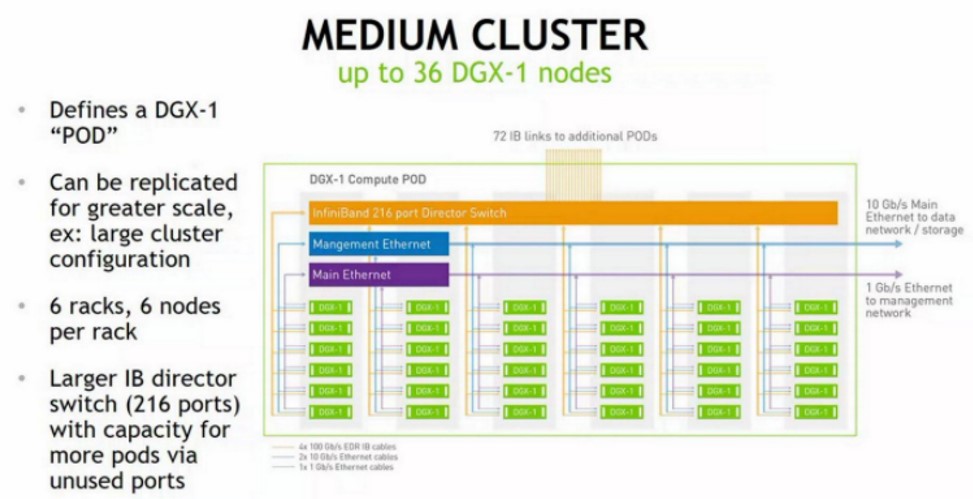
Để tạo nhóm, một công tắc giám đốc EDR InfiniBand của cổng 216 được sử dụng để tạo một tầng khác trong mạng cây béo và ghép chéo ba bộ giá đỡ với nhau.
Các nhóm này sau đó được sao chép và liên kết bởi các công tắc mô-đun lớn hơn nhiều trong tầng thứ ba của mạng cây béo, trong trường hợp này sử dụng bộ chuyển đổi giám đốc EDR InfiniBand gồm 324 cổng, như sau:
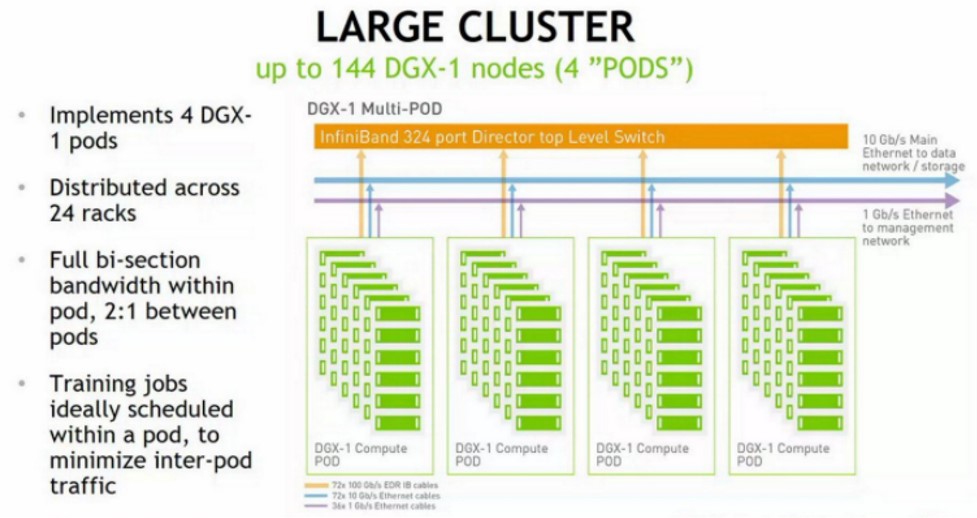
Hình trên của Saturn V thế hệ tiếp theo cho thấy bốn hàng gồm 22 giá đỡ, mỗi hàng có tổng cộng 528 hệ thống và hình ảnh này không ánh xạ vật lý tốt với những gì được nói trong bài thuyết trình của Nvidia trừ khi các nhóm được tạo ra trên sáu hàng ( có nghĩa là chúng ta không thể nhìn thấy tất cả), không nằm cạnh nhau trong các hàng nơi có rõ ràng 11 giá đỡ trong một hàng. Một cái gì đó là sôi nổi, và chúng tôi không chắc chắn những gì. Chúng tôi nghi ngờ rằng vì bản nâng cấp Saturn V chưa được cài đặt đầy đủ, đây là lỗi của một nghệ sĩ đồ họa, người có nghĩa là đặt 24 giá đỡ liên tiếp và 12 giá đỡ liên tiếp. Sau đó, tất cả hoạt động như nó cần.
Rogers đã giải thích một số khoảnh khắc của a-ha-mai trong việc xây dựng các hệ thống Saturn V tại Nvidia. Mặc dù chuyên môn của HPC có thể giúp đỡ, ngay cả với điều này, những điểm tương đồng bị hạn chế. Bạn tách các thứ khác nhau cho khối lượng công việc AI dựa trên khả năng mở rộng của các khung máy học. Nếu bạn muốn điều khiển hiệu suất tối ưu, thì mật độ năng lượng không thể quá cao, ít nhất là không phải cho trung tâm dữ liệu làm mát bằng không khí mà Nvidia dường như đang sử dụng. Ngoài ra, đối với khối lượng công việc học máy tại Nvidia, bộ dữ liệu ở bất kỳ nơi nào từ hàng chục nghìn đến hàng triệu đối tượng, có thêm tới terabyte dung lượng lưu trữ trên các máy Saturn V và bộ đệm đọc mà các ổ flash đó cung cấp cho các nút đặc biệt quan trọng đối với các nút hiệu suất học máy ngay cả khi nó không tạo ra sự khác biệt cho Linpack.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale