
Apache MXNet là một framework học sâu (DL) linh hoạt và có thể mở rộng, hỗ trợ nhiều mô hình học sâu, ngôn ngữ lập trình và có giao diện phát triển được đánh giá cao về tính dễ sử dụng.
Apache MXNet là gì?
MXNet là một framework học sâu mã nguồn mở cho phép người dùng xác định, đào tạo và triển khai các mạng thần kinh sâu (deep neural networks) trên nhiều loại thiết bị, từ hạ tầng đám mây đến thiết bị di động. Có khả năng mở rộng cao, cho phép đào tạo mô hình nhanh chóng, hỗ trợ mô hình lập trình linh hoạt và nhiều ngôn ngữ.
MXNet cho phép người dùng mix các cách lập trình biểu tượng và mệnh lệnh để tối đa hóa cả hiệu quả và năng suất. Được xây dựng trên một bộ lập lịch tự động song song hóa cả hoạt động tượng trưng và mệnh lệnh một cách nhanh chóng. Lớp tối ưu hóa biểu đồ trên cùng giúp việc thực thi biểu tượng nhanh chóng và tiết kiệm bộ nhớ.

Thư viện MXNet có tính di động và nhẹ nhàng. Được tăng tốc với NVIDIA Pascal GPUs và mở rộng quy mô trên nhiều GPU và nhiều nodes, cho phép người dùng đào tạo mô hình nhanh hơn.
Tại sao lại là Apache MXNet?
Apache MXNet cung cấp các tính năng và lợi ích chính sau:
- Hybrid front-end: API Gluon kết hợp biểu tượng cung cấp tính dễ dàng cho việc tạo mẫu, đào tạo và triển khai các mô hình mà không làm giảm tốc độ đào tạo. Các nhà phát triển chỉ cần một vài dòng mã Gluon để xây dựng các mô hình hồi quy tuyến tính (linear regression), CNN và LSTM lặp lại cho các mục đích sử dụng như phát hiện đối tượng, nhận dạng giọng nói và công cụ đề xuất.
- Khả năng mở rộng: Được thiết kế từ đầu cho hạ tầng đám mây, MXNet sử dụng máy chủ tham số phân tán có thể đạt được quy mô gần như tuyến tính bằng cách sử dụng nhiều GPU hoặc CPU. Tải xử lý học sâu có thể được phân bổ trên nhiều GPU với khả năng mở rộng gần như tuyến tính và tự động mở rộng quy mô. Các thử nghiệm do Amazon Web Services thực hiện cho thấy MXNet hoạt động nhanh hơn 109 lần trên một cụm 128 GPU so với một GPU duy nhất. Nhờ khả năng mở rộng quy mô thành nhiều GPU (trên nhiều máy chủ) cùng với tốc độ phát triển và tính di động mà AWS đã sử dụng MXNet làm framework học sâu thay vì các lựa chọn thay thế như TensorFlow, Theano và Torch.
- Hệ sinh thái: MXNet có bộ công cụ và thư viện dành cho thị giác máy tính, xử lý ngôn ngữ tự nhiên, chuỗi thời gian, v.v.
- Ngôn ngữ: Các ngôn ngữ được MXNet hỗ trợ bao gồm Python, C++, R, Scala, Julia, Matlab và JavaScript. MXNet cũng biên dịch sang C++, tạo ra bản trình bày mô hình mạng thần kinh nhẹ có thể chạy trên mọi thứ, từ các thiết bị có công suất thấp như Raspberry Pi đến máy chủ đám mây.

MXNet hoạt động như thế nào?
Được tạo ra bởi một nhóm các tổ chức học thuật và được tạo ra tại Apache Software Foundation, MXNet (hoặc “mix-net”) được thiết kế để kết hợp các ưu điểm của các phương pháp lập trình khác nhau để phát triển mô hình học sâu—bắt buộc, trong đó chỉ rõ chính xác “cách thức” tính toán được thực hiện và mang tính khai báo hoặc tượng trưng, tập trung vào “cái gì” nên được thực hiện.
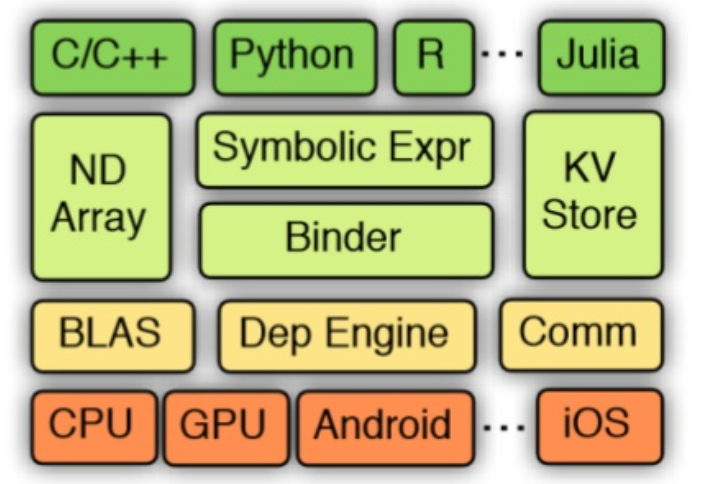
Tham khảo tài liệu: https://www.cs.cmu.edu/~muli/file/mxnet-learning-sys.pdf
Chế độ lập trình mệnh lệnh
NDArray của MXNet, với lập trình mệnh lệnh, là công cụ chính của MXNet để lưu trữ và chuyển đổi dữ liệu. NDArray được sử dụng để biểu diễn, thao tác đầu vào và đầu ra của mô hình dưới dạng mảng đa chiều. NDArray tương tự như ndarray của NumPy, nhưng chúng có thể chạy trên GPU để tăng tốc tính toán.
Lập trình mệnh lệnh có ưu điểm là nó quen thuộc với các nhà phát triển có nền tảng lập trình thủ tục, việc cập nhật tham số và gỡ lỗi tương tác sẽ tự nhiên hơn.
Chế độ lập trình tượng trưng
Mạng thần kinh chuyển đổi dữ liệu đầu vào bằng cách áp dụng các lớp hàm lồng nhau cho các tham số đầu vào. Mỗi lớp bao gồm một hàm tuyến tính theo sau là một phép biến đổi phi tuyến tính. Mục tiêu của học sâu là tối ưu hóa các tham số này (bao gồm trọng số và độ lệch) bằng cách tính toán đạo hàm riêng (độ dốc) của chúng đối với số liệu tổn thất. Trong quá trình lan truyền thuận, mạng nơ-ron lấy các tham số đầu vào và đưa ra điểm tin cậy cho các nút ở lớp tiếp theo cho đến khi đạt đến lớp đầu ra nơi tính toán sai số của điểm. Với lan truyền ngược bên trong một quy trình được gọi là giảm độ dốc, các lỗi sẽ được gửi lại qua mạng và các trọng số được điều chỉnh, cải thiện mô hình.
Đồ thị là cấu trúc dữ liệu bao gồm các nodes được kết nối (called vertices) và các cạnh (edges). Mọi khuôn khổ hiện đại cho học sâu đều dựa trên khái niệm đồ thị, trong đó mạng lưới thần kinh được biểu thị dưới dạng cấu trúc đồ thị của các phép tính.
Lập trình biểu tượng MXNet cho phép các hàm được xác định một cách trừu tượng thông qua các biểu đồ tính toán. Với lập trình biểu tượng, các hàm phức tạp trước tiên được biểu thị dưới dạng các giá trị tại chỗ. Sau đó, các hàm này có thể được thực thi bằng cách liên kết chúng với các giá trị thực. Lập trình tượng trưng cũng cung cấp các lớp mạng thần kinh được xác định trước cho phép thể hiện các mô hình lớn một cách chính xác với công việc ít lặp lại hơn và hiệu suất tốt hơn.
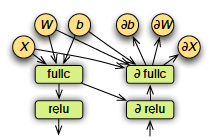
Tài liệu tham khảo: https://www.cs.cmu.edu/~muli/file/mxnet-learning-sys.pdf
Lập trình tượng trưng có những ưu điểm sau:
- Các ranh giới rõ ràng của biểu đồ tính toán mang lại nhiều cơ hội tối ưu hóa hơn cho người thực thi MXNet
- Việc chỉ định biểu đồ tính toán cho cấu hình mạng thần kinh dễ dàng hơn
Chế độ lập trình kết hợp với API Gluon
Một trong những ưu điểm chính của MXNet là giao diện lập trình kết hợp, Gluon, giúp thu hẹp khoảng cách giữa giao diện mệnh lệnh và giao diện tượng trưng trong khi vẫn giữ được khả năng và lợi thế của cả hai. Gluon là một ngôn ngữ dễ học, tạo ra các mô hình di động nhanh. Với API Gluon, người dùng có thể tạo nguyên mẫu mô hình của mình một cách bắt buộc bằng cách sử dụng NDArray. Sau đó, người dùng có thể chuyển sang chế độ tượng trưng bằng lệnh hybridize để đào tạo và suy luận mô hình nhanh hơn. Ở chế độ biểu tượng, mô hình chạy nhanh hơn dưới dạng biểu đồ được tối ưu hóa thực thi MXNet và có thể dễ dàng xuất để suy luận trong các liên kết ngôn ngữ khác nhau như java hoặc C++.
Tại sao MXNet được cải thiện khi dùng GPU ?
Về mặt kiến trúc, CPU chỉ bao gồm một vài core với nhiều bộ nhớ đệm có thể xử lý một số threads phần mềm cùng một lúc. Ngược lại, GPU bao gồm hàng trăm cores có thể xử lý hàng nghìn threads cùng một lúc.

Bởi vì mạng thần kinh được tạo ra từ số lượng lớn các tế bào thần kinh giống hệt nhau nên về bản chất chúng rất song song. Tính song song này ánh xạ một cách tự nhiên tới GPU , giúp tăng tốc độ tính toán đáng kể so với việc đào tạo chỉ dùng CPU. GPU đã trở thành nền tảng được lựa chọn để đào tạo các hệ thống dựa trên mạng thần kinh lớn, phức tạp vì lý do này. Bản chất song song của các hoạt động suy luận cũng rất phù hợp để thực hiện trên GPU.
Với các thuật toán cải tiến, bộ dữ liệu lớn hơn và khả năng tính toán được tăng tốc bằng GPU, mạng thần kinh học sâu đã trở thành một công cụ không thể thiếu để nhận dạng hình ảnh, nhận dạng giọng nói, dịch ngôn ngữ, v.v. trong nhiều ngành. MXNet được phát triển với mục tiêu cung cấp các công cụ mạnh mẽ giúp các nhà phát triển khai thác toàn bộ khả năng của GPU và điện toán đám mây.
Nói một cách đơn giản, người dùng càng sử dụng nhiều GPU để hoạt động trên thuật toán đào tạo MXNet thì công việc sẽ hoàn thành càng nhanh. Framework này nổi bật về hiệu suất có thể mở rộng với các cải tiến tốc độ gần như tuyến tính khi có nhiều GPU hơn được cung cấp. MXNet được thiết kế để tự động mở rộng quy mô theo GPU có sẵn, một điểm cộng cho việc điều chỉnh hiệu suất.
Các ứng dụng thực tiễn
Ứng dụng điện thoại thông minh
MXNet rất phù hợp để nhận dạng hình ảnh và khả năng hỗ trợ các mô hình chạy trên nền tảng bộ nhớ hạn chế, tiêu thụ điện năng thấp khiến nó trở thành lựa chọn tốt để triển khai trên điện thoại di động. Các mô hình được xây dựng bằng MXNet đã được chứng minh là mang lại kết quả nhận dạng hình ảnh có độ tin cậy cao chạy nguyên bản trên máy tính xách tay. Việc kết hợp bộ xử lý cục bộ và đám mây có thể cho phép các ứng dụng phân tán mạnh mẽ trong các lĩnh vực như thực tế tăng cường, nhận dạng đối tượng và hoạt cảnh.
Các ứng dụng nhận dạng giọng nói và hình ảnh cũng có những khả năng hấp dẫn đối với người khiếm khuyết. Ví dụ: ứng dụng di động có thể giúp những người khiếm thị nhận thức rõ hơn về môi trường xung quanh và những người khiếm thính có thể dịch các cuộc hội thoại bằng giọng nói thành văn bản.
Xe tự hành
Ô tô và xe tải tự lái phải xử lý một lượng dữ liệu khổng lồ để đưa ra quyết định trong thời gian gần như thực. Các mạng phức tạp đang phát triển để hỗ trợ các đội xe tự hành sử dụng quy trình xử lý phân tán ở mức độ chưa từng có để phối hợp mọi thứ, từ quyết định phanh trên một chiếc ô tô đến quản lý giao thông trên toàn bộ thành phố.
TuSimple đang xây dựng mạng lưới vận chuyển hàng hóa tự động gồm các tuyến đường được lập bản đồ cho phép vận chuyển hàng hóa tự động trên khắp vùng Tây Nam Hoa Kỳ đã chọn MXNet làm nền tảng nền tảng để phát triển mô hình trí tuệ nhân tạo. Công ty đang đưa công nghệ xe tự lái vào một ngành đang phải đối mặt với tình trạng thiếu hụt tài xế thường xuyên cũng như chi phí cao do tai nạn, lịch làm việc và nhiên liệu kém hiệu quả.
TuSimple chọn MXNet vì tính di động đa nền tảng, hiệu quả đào tạo và khả năng mở rộng. Một yếu tố là điểm benchmark so sánh MXNet với TensorFlow và nhận thấy rằng trong môi trường có 8 GPU, MXNet nhanh hơn, tiết kiệm bộ nhớ hơn và chính xác hơn.
Tại sao MXNet lại quan trọng đối với…
Nhà khoa học dữ liệu
Học máy là một phần ngày càng phát triển của bối cảnh khoa học dữ liệu. Đối với những người chưa quen với những điểm hay của việc phát triển mô hình học sâu, MXNet là một nơi tốt để bắt đầu. Hỗ trợ ngôn ngữ rộng rãi, API Gluon và tính linh hoạt của nó rất phù hợp với các tổ chức đang phát triển bộ kỹ năng học sâu của riêng họ. Sự chứng thực của Amazon đảm bảo rằng MXNet sẽ tồn tại lâu dài và hệ sinh thái bên thứ ba sẽ tiếp tục phát triển. Nhiều chuyên gia đề xuất MXNet là điểm khởi đầu tốt cho những chuyến tham quan trong tương lai vào các khuôn khổ học sâu phức tạp hơn.
Các nhà nghiên cứu học máy
MXNet thường được các nhà nghiên cứu sử dụng vì khả năng tạo nguyên mẫu nhanh chóng, giúp chuyển đổi ý tưởng nghiên cứu thành mô hình và đánh giá kết quả dễ dàng hơn. Nó cũng hỗ trợ lập trình mệnh lệnh mang lại nhiều quyền kiểm soát hơn cho các nhà nghiên cứu trong việc tính toán. Framework cụ thể này cũng đã cho thấy hiệu suất đáng kể trên một số loại mô hình nhất định khi so sánh với các framework khác do sử dụng nhiều CPU và GPU.
Nhà phát triển phần mềm
Tính linh hoạt có giá trị trong công nghệ phần mềm và MXNet gần như là một framework học sâu linh hoạt nhất có thể. Ngoài khả năng hỗ trợ ngôn ngữ rộng, nó còn hoạt động với nhiều định dạng dữ liệu khác nhau, bao gồm lưu trữ đám mây Amazon S3 và có thể tăng hoặc giảm quy mô để phù hợp với hầu hết các nền tảng. Năm 2019, MXNet đã bổ sung hỗ trợ cho Horovod, một framework học tập phân tán do Uber phát triển. Điều này mang lại cho các kỹ sư phần mềm sự linh hoạt hơn nữa trong việc chỉ định môi trường triển khai, có thể bao gồm mọi thứ từ máy tính xách tay đến máy chủ đám mây.
MXNet với NVIDIA GPU
MXNet khuyến nghị NVIDIA GPU để đào tạo và triển khai mạng thần kinh vì nó cung cấp sức mạnh tính toán cao hơn đáng kể so với CPU, mang lại hiệu suất tăng đáng kể trong suy luận. Các nhà phát triển có thể dễ dàng bắt đầu với MXNet bằng NGC (NVIDIA GPU Cloud). Tại đây, người dùng có thể kéo các container có sẵn các mô hình được đào tạo trước cho nhiều tác vụ khác nhau như thị giác máy tính, xử lý ngôn ngữ tự nhiên, v.v. với tất cả các phần phụ thuộc và framework trong một container. Với NVIDA TensorRT, hiệu suất suy luận có thể được cải thiện đáng kể trên MXNet khi sử dụng NVIDIA GPUs.
NVIDIA Deep Learning dành cho nhà phát triển
Các framework học sâu được tăng tốc với GPU mang lại sự linh hoạt trong việc thiết kế và huấn luyện các mạng thần kinh sâu tùy chỉnh, đồng thời cung cấp giao diện cho các ngôn ngữ lập trình được sử dụng phổ biến như Python và C/C++. Các framework học sâu được sử dụng rộng rãi như MXNet, PyTorch, TensorFlow và các framework khác dựa vào thư viện tăng tốc NVIDIA GPU để cung cấp chương trình đào tạo tăng tốc đa GPU, hiệu suất cao.
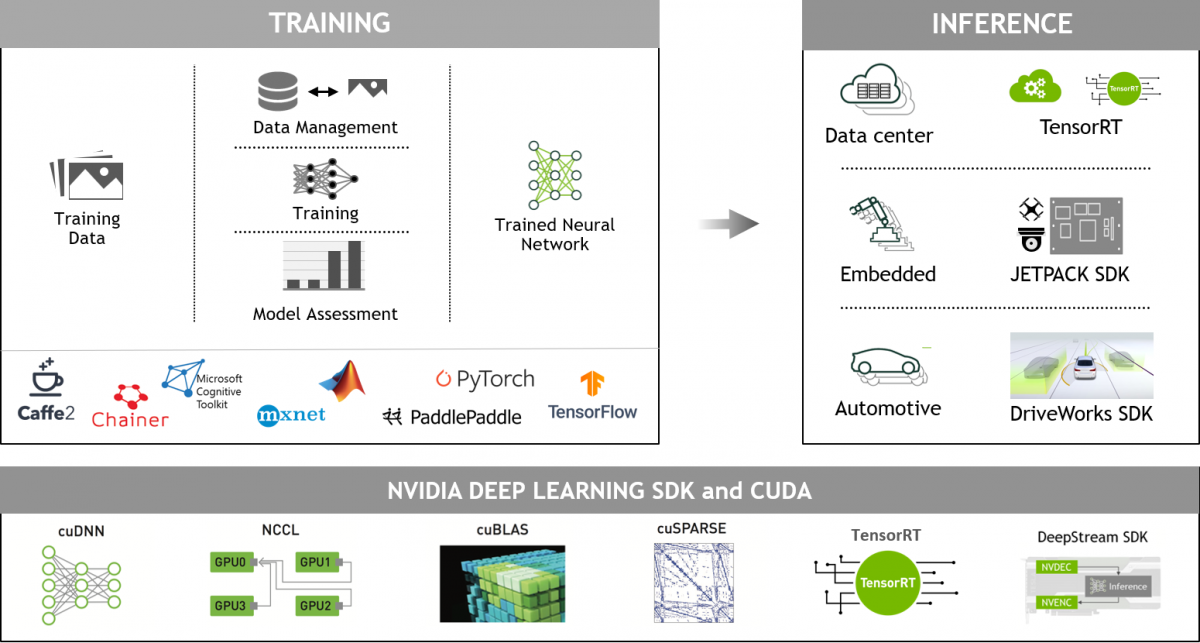
Khoa học dữ liệu toàn diện, tăng tốc NVIDIA GPU
Bộ thư viện phần mềm nguồn mở NVIDIA RAPIDS, được xây dựng trên CUDA-X AI, cung cấp khả năng thực thi các quy trình phân tích và khoa học dữ liệu từ đầu đến cuối hoàn toàn trên GPU. Nó dựa trên nguyên lý NVIDIA CUDA để tối ưu hóa điện toán ở mức độ thấp, nhưng vẫn thể hiện tính song song của GPU và tốc độ bộ nhớ băng thông cao thông qua giao diện Python thân thiện với người dùng.
Với Khung dữ liệu GPU RAPIDS, dữ liệu có thể được tải lên GPU bằng giao diện giống như Pandas, sau đó được sử dụng cho các thuật toán phân tích biểu đồ và học máy được kết nối khác nhau mà không cần tách khỏi GPU. Mức độ tương tác này có thể thực hiện được thông qua các thư viện như Apache Arrow. Điều này cho phép tăng tốc quy trình từ đầu đến cuối từ chuẩn bị dữ liệu đến học máy cho đến học sâu.
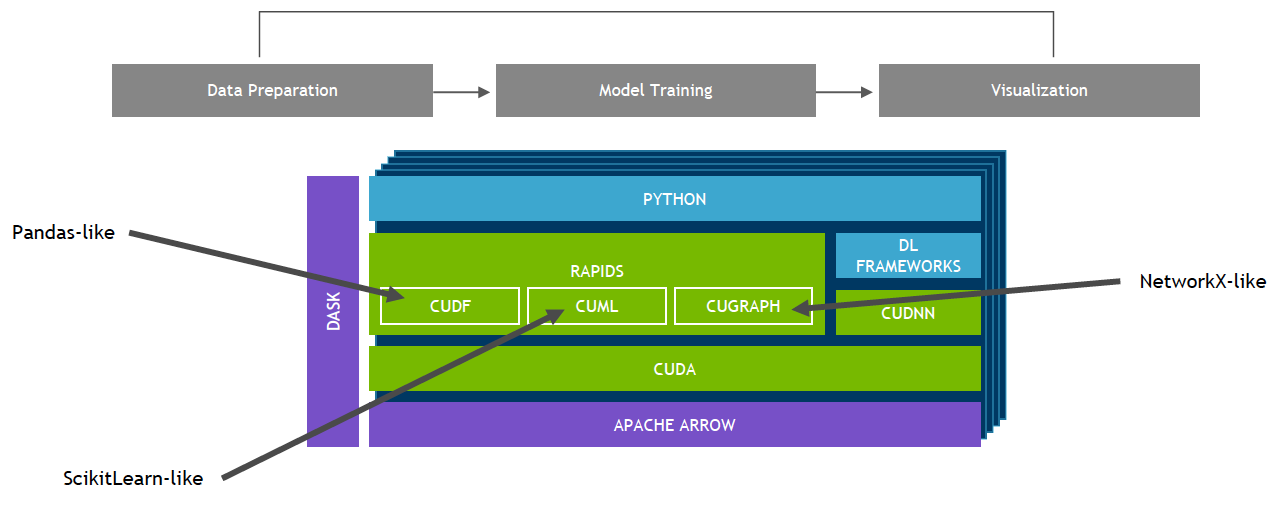
RAPIDS hỗ trợ chia sẻ bộ nhớ thiết bị giữa nhiều thư viện khoa học dữ liệu phổ biến. Điều này giữ dữ liệu trên GPU và tránh việc sao chép qua lại tốn kém vào bộ nhớ máy chủ.
Bài viết liên quan
- Hướng dẫn lựa chọn GPU phù hợp cho AI, Machine Learning
- U.2 SSD: “Chiến binh” hiệu năng cao ẩn mình trong thế giới lưu trữ doanh nghiệp
- NVIDIA Dynamo – Thư viện nguồn mở tăng tốc và mở rộng các mô hình lý luận AI
- Tôi có cần CPU kép không?
- Những lợi ích của việc chạy suy luận AI ngay tại biên, thay vì trong trung tâm dữ liệu
- Suy luận AI trên các máy chủ thông dụng của HPE, Dell và Supermicro