
Sự bùng nổ của trí tuệ nhân tạo (AI), đặc biệt là các mô hình ngôn ngữ lớn (LLM), đã tạo ra một nhu cầu chưa từng có về hiệu suất tính toán và băng thông dữ liệu. Các “nhà máy AI” (AI factories) hiện đại được xây dựng để xử lý các mô hình có quy mô hàng nghìn tỷ tham số, đòi hỏi luồng dữ liệu khổng lồ phải được di chuyển liên tục và hiệu quả giữa các bộ xử lý đồ họa (GPU), bộ nhớ hệ thống, và các node máy chủ. Nhu cầu này đã vượt quá giới hạn của các kiến trúc hạ tầng truyền thống, dẫn đến các điểm nghẽn nghiêm trọng, làm giảm hiệu suất tổng thể của hệ thống.
Kỷ nguyên mới cho hạ tầng AI và HPC

Để giải quyết thách thức này, NVIDIA đã giới thiệu một giải pháp mang tính đột phá tại Computex 2025: NVIDIA ConnectX-8 SuperNIC Switch. Đây không chỉ là một card mạng (NIC) thông thường mà là một nền tảng kiến trúc tích hợp, được thiết kế để tái định hình cách các hệ thống GPU dựa trên PCIe hoạt động. Bằng cách tận dụng các cải tiến của giao thức kết nối PCIe Gen6, ConnectX-8 SuperNICs hứa hẹn sẽ mở ra một kỷ nguyên mới cho các trung tâm dữ liệu AI và tính toán hiệu năng cao (HPC), mang lại hiệu suất vượt trội, đơn giản hóa thiết kế và giảm đáng kể chi phí sở hữu tổng thể (TCO).
Kiến trúc nền tảng đột phá: Từ thiết kế truyền thống đến NVIDIA ConnectX-8 SuperNIC


Hạn chế của kiến trúc server PCIe truyền thống
Kiến trúc server đa GPU dựa trên PCIe truyền thống, đặc biệt là các hệ thống 8-GPU, thường có thiết kế phức tạp và rời rạc. Một cấu hình điển hình bao gồm hai CPU, tám GPU (ví dụ: NVIDIA L40) và một cụm gồm năm card mạng, trong đó có bốn NIC NVIDIA ConnectX-7 400G và một BlueField-3 DPU. Để đảm bảo giao tiếp giữa các GPU với nhau (GPU-to-GPU) và giữa GPU với mạng (GPU-to-networking), kiến trúc này yêu cầu hai đến bốn switch PCIe rời rạc.
Thiết kế này mang lại nhiều nhược điểm cố hữu. Các luồng dữ liệu quan trọng giữa các GPU hoặc giữa GPU và các NIC thường phải đi qua các switch PCIe rời rạc, hoặc thậm chí qua CPU và liên kết inter-socket giữa các CPU. Điều này tạo ra các điểm nghẽn về băng thông và độ trễ, giới hạn hiệu suất của toàn hệ thống. Hơn nữa, việc sử dụng nhiều thành phần rời rạc làm tăng đáng kể độ phức tạp của thiết kế bo mạch, yêu cầu hệ thống cáp phức tạp, và cuối cùng làm tăng chi phí sản xuất, tiêu thụ năng lượng và chi phí sở hữu tổng thể.
Giải pháp tích hợp đột phá của ConnectX-8 SuperNIC
NVIDIA ConnectX-8 SuperNIC Switch là một bước chuyển mình kiến trúc, thay thế thiết kế rời rạc bằng một nền tảng tích hợp cao. Sản phẩm này về cơ bản là một GPU backplane tích hợp sẵn kết nối mạng ConnectX-8. Cụ thể, nó là một bo mạch hỗ trợ 8-GPU, tích hợp một switch PCIe 6.0 48-lane và bốn giao diện mạng ConnectX-8 800Gb/s chuyên dụng.
Lợi ích cốt lõi của kiến trúc này nằm ở khả năng bỏ qua hoàn toàn CPU (CPU bypass). Các làn PCIe, switch và mạng tích hợp được thiết kế để tạo ra một kênh giao tiếp trực tiếp giữa GPU với GPU và giữa GPU với mạng, loại bỏ các điểm nghẽn do CPU và các liên kết inter-socket truyền thống gây ra. Điều này cải thiện đáng kể luồng dữ liệu, giảm độ trễ và tăng thông lượng, mang lại hiệu suất cao hơn cho các tác vụ cần giao tiếp liên tục và tốc độ cao giữa các GPU.
Sự tích hợp này không chỉ là một cải tiến về tốc độ mà là một sự tái cấu trúc căn bản đường đi của dữ liệu. Nguyên nhân chính của hiệu suất vượt trội là sự kết hợp của ba yếu tố: mạng 800Gb/s, switch PCIe Gen6 và khả năng bỏ qua CPU. Sự kết hợp này mang lại lợi ích về hiệu suất của các nền tảng cao cấp như DGX/HGX (sử dụng NVLink) cho các server PCIe tiêu chuẩn, giúp các doanh nghiệp không đủ điều kiện về chi phí hoặc hạ tầng để triển khai DGX vẫn có thể xây dựng các “AI factories” mạnh mẽ với TCO thấp hơn và khả năng mở rộng tốt hơn.
Bảng sau đây tóm tắt sự khác biệt về kiến trúc giữa hai phương pháp tiếp cận:
Bảng 1: So sánh Kiến trúc Hệ thống: Server ConnectX-7 Truyền thống vs. ConnectX-8 SuperNIC
| Đặc điểm | Server ConnectX-7 Truyền thống | Server với ConnectX-8 SuperNIC |
| Thành phần chính | CPU, GPU, NIC rời rạc, switch PCIe rời rạc | GPU backplane tích hợp switch PCIe và NIC |
| Số lượng linh kiện | Nhiều (ví dụ: 4x ConnectX-7 NIC, 2-4x switch PCIe) | Ít hơn (1x SuperNIC Switch thay thế nhiều thành phần) |
| Đường đi dữ liệu | Phức tạp, đi qua CPU và các switch rời rạc | Trực tiếp, bỏ qua CPU (CPU bypass) |
| Băng thông/NIC | 400Gb/s (ConnectX-7) | 800Gb/s (ConnectX-8) |
| Độ phức tạp thiết kế | Cao | Thấp, đơn giản hóa bo mạch chủ |
Phân tích chuyên sâu về NVIDIA ConnectX-8 SuperNICs

Thông số kỹ thuật và tính năng nổi bật
NVIDIA ConnectX-8 SuperNICs được thiết kế để cung cấp hiệu suất mạng cực cao, đáp ứng nhu cầu của các mô hình AI quy mô lớn. Các thông số kỹ thuật cốt lõi của thiết bị này bao gồm:
- Băng thông tối đa: Mỗi ConnectX-8 NIC cung cấp băng thông lên tới 800 gigabit mỗi giây (Gb/s), với tổng băng thông 3200 Gb/s trên toàn bộ SuperNIC.
- Giao diện Host: Hỗ trợ giao diện PCIe Gen6 với tối đa 48 làn. Điều này cho phép các GPU tương thích PCIe 6.0 tận dụng tốc độ 800Gb/s, ngay cả khi nền tảng CPU host không hỗ trợ PCIe Gen6.
- Chuẩn mạng hỗ trợ: Hỗ trợ cả InfiniBand (tối đa 800Gb/s XDR IB) và Ethernet (tối đa 2x400GbE).
- Công nghệ tăng tốc In-Network Computing: ConnectX-8 tích hợp các công nghệ offloading mạnh mẽ, giải phóng CPU khỏi các tác vụ mạng và cải thiện hiệu suất.
- RDMA (Remote Direct Memory Access) và RoCEv2: Cho phép truyền dữ liệu trực tiếp giữa bộ nhớ của các thiết bị (GPU) mà không cần can thiệp của CPU, giúp giảm đáng kể độ trễ và giải phóng tài nguyên CPU.
- GPUDirect RDMA và GPUDirect Storage: Công nghệ này cho phép GPU giao tiếp trực tiếp với các thiết bị mạng và lưu trữ, tối ưu hóa quá trình tiền xử lý và nạp dữ liệu.
- SHARP (Scalable Hierarchical Aggregation and Reduction Protocol): Một công nghệ In-Network Computing để tăng tốc các phép toán tập thể (collective operations) như AllReduce, rất quan trọng trong huấn luyện AI phân tán quy mô lớn.
Bảng 2: Các Thông số Kỹ thuật Chi tiết của NVIDIA ConnectX-8 SuperNIC
| Thông số | Giá trị |
| Băng thông tối đa | 800 Gb/s |
| Tổng băng thông | 3200 Gb/s (tại 4 NIC) |
| Giao diện Host | PCIe Gen6 x16, lên đến 48 làn |
| Chuẩn mạng hỗ trợ | InfiniBand, Ethernet |
| Tốc độ InfiniBand | 800/400/200/100 Gb/s |
| Tốc độ Ethernet | 400/200/100/50/25 Gb/s |
| Tính năng nổi bật | In-Network Computing, RDMA/RoCEv2, GPUDirect RDMA/Storage, SHARP |
So sánh chi tiết với NVIDIA ConnectX-7
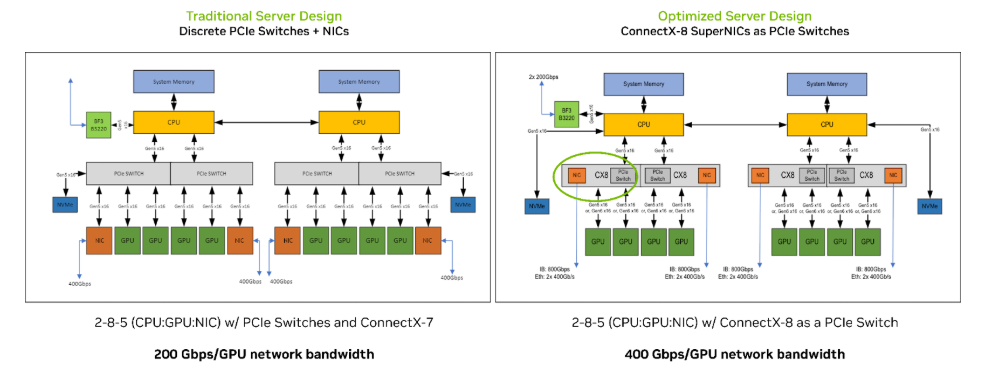
Điểm khác biệt dễ nhận thấy nhất giữa ConnectX-8 và ConnectX-7 là băng thông: ConnectX-8 cung cấp băng thông 800 Gb/s, gấp đôi so với 400 Gb/s của ConnectX-7. Tuy nhiên, sự khác biệt quan trọng hơn lại nằm ở vai trò kiến trúc của chúng trong hệ thống.
ConnectX-7 là một card mạng (NIC) hoặc bộ điều hợp kênh chủ (HCA) độc lập. Nó cần các thành phần rời rạc khác, đặc biệt là các switch PCIe, để tạo thành một hệ thống đa GPU hoàn chỉnh. Ngược lại, ConnectX-8 được thiết kế như một “SuperNIC Switch”. Điều này có nghĩa là nó tích hợp sẵn switch PCIe 6.0 trên cùng một bo mạch.
Sự tích hợp này cho phép ConnectX-8 đảm nhận một vai trò mới, không chỉ là giao diện mạng mà còn là trung tâm điều phối dữ liệu nội bộ hệ thống. Nó tạo ra một mạng lưới kết nối chặt chẽ giữa các GPU và các NIC, đơn giản hóa thiết kế tổng thể và tối ưu hóa luồng dữ liệu mà kiến trúc rời rạc của ConnectX-7 không thể đạt được.
PCIe Gen6: Nền tảng kết nối tương lai cho AI

Tổng quan về PCIe Gen6
PCIe (Peripheral Component Interconnect Express) là giao diện kết nối tiêu chuẩn, đóng vai trò là xương sống của mọi hệ thống máy tính hiện đại. Nó kết nối các thành phần hiệu suất cao như GPU, NIC và ổ đĩa NVMe với CPU. Với sự ra đời của PCIe Gen6, tiêu chuẩn này tiếp tục truyền thống tăng gấp đôi băng thông so với thế hệ trước. Tốc độ truyền dữ liệu mỗi làn của PCIe 6.0 đạt 64 gigatransfers mỗi giây (GT/s). Đối với một liên kết x16, đây là cấu hình phổ biến cho card đồ họa và card mạng, băng thông của liên kết đạt 128 gigabytes mỗi giây (GB/s) theo một chiều, với tổng băng thông song công lên tới 256 GB/s.
Các đổi mới kỹ thuật đột phá
Việc tăng gấp đôi băng thông không chỉ là một thay đổi đơn lẻ mà là một chuỗi các đổi mới kỹ thuật liên kết chặt chẽ với nhau. Mỗi thay đổi được thực hiện để giải quyết thách thức do thay đổi trước đó tạo ra, tạo nên một chuỗi phát triển liền mạch và hiệu quả.
- Mã hóa PAM4 Signaling: Thay vì tăng tần số đồng hồ như các thế hệ trước, PCIe Gen6 sử dụng kỹ thuật điều chế biên độ xung bốn mức (PAM4). Trong khi PCIe Gen5 sử dụng mã hóa NRZ với hai mức điện áp (đại diện cho bit 0 và 1), PAM4 sử dụng bốn mức điện áp khác nhau để mã hóa 2 bit dữ liệu trên mỗi chu kỳ xung nhịp (00, 01, 10, 11). Điều này cho phép gấp đôi băng thông mà không cần tăng tần số cơ bản của bus.
- Sửa lỗi tiến (Forward Error Correction – FEC): Mặc dù PAM4 cho phép tăng băng thông, nó lại dễ bị nhiễu tín hiệu hơn do khoảng cách giữa các mức điện áp hẹp hơn. Điều này làm giảm tỷ lệ tín hiệu trên nhiễu (SNR) và tăng tỷ lệ lỗi bit. Để khắc phục, PCIe 6.0 giới thiệu cơ chế sửa lỗi tiến (FEC) để tự động phát hiện và sửa các lỗi nhỏ trong quá trình truyền dữ liệu mà không cần gửi lại toàn bộ gói tin. Cơ chế này được thiết kế để có độ trễ cực thấp, dưới 2 nanosecond, đảm bảo hiệu quả cho các ứng dụng có độ trễ nhạy cảm.
- Chế độ FLIT (Flow Control Unit): Để FEC hoạt động hiệu quả, các gói dữ liệu cần có kích thước cố định. Do đó, PCIe 6.0 giới thiệu chế độ FLIT, thay thế các gói dữ liệu có kích thước thay đổi của các thế hệ trước. Chế độ này không chỉ hỗ trợ FEC mà còn mang lại nhiều lợi ích khác: nó đơn giản hóa việc quản lý dữ liệu ở tầng controller, loại bỏ overhead từ các cơ chế mã hóa cũ như 128b/130b và DLLP, từ đó cải thiện hiệu quả băng thông và giảm độ trễ một cách đáng kể.
Bảng 3: So sánh Thông số Kỹ thuật Cốt lõi của PCIe Gen6 và PCIe Gen5
| Đặc điểm | PCIe Gen6 | PCIe Gen5 |
| Tốc độ (GT/s/làn) | 64 | 32 |
| Băng thông (GB/s, x16) | 128 (một chiều) | 64 (một chiều) |
| Mã hóa | PAM4/FLIT | 128b/130b |
| Cơ chế sửa lỗi | FEC & CRC | CRC |
| Tính năng nổi bật | FLIT mode, L0p power state, TCO thấp hơn | N/A |
Các ứng dụng và tầm quan trọng trong thực tiễn

Sự ra đời của NVIDIA ConnectX-8 SuperNIC Switch và nền tảng PCIe Gen6 là một bước tiến quan trọng, giải quyết các thách thức về hiệu suất và khả năng mở rộng trong các hệ thống tính toán quy mô lớn. Nền tảng này mang lại lợi ích trực tiếp cho nhiều ứng dụng đòi hỏi băng thông và độ trễ cực thấp :
- Huấn luyện AI và Học máy chuyên sâu (AI Deep Learning & Machine Learning): Các mô hình AI hiện đại phụ thuộc rất nhiều vào giao tiếp giữa các GPU và giữa các node. ConnectX-8 SuperNICs cung cấp băng thông cao và độ trễ thấp, cho phép các tác vụ huấn luyện phân tán quy mô lớn được thực hiện hiệu quả hơn.
- Mô phỏng kỹ thuật (Engineering Simulation): Các tác vụ như Phân tích phần tử hữu hạn (FEA) và Động lực học chất lỏng tính toán (CFD) cần xử lý lượng lớn dữ liệu và trao đổi liên tục giữa các GPU. Kiến trúc mới giúp tăng tốc các mô phỏng này, cho phép các kỹ sư thực hiện các phép tính phức tạp hơn trong thời gian ngắn hơn.
- Phân tích dữ liệu lớn và Rendering: Các ứng dụng trong lĩnh vực tài chính, y tế, sinh học và đồ họa cần di chuyển các tập dữ liệu khổng lồ. Băng thông 800 Gb/s của ConnectX-8 SuperNICs đảm bảo luồng dữ liệu thông suốt, giảm thiểu tắc nghẽn.
Các lợi ích của kiến trúc này không chỉ dừng lại ở hiệu suất lý thuyết. Băng thông gấp đôi và độ trễ thấp hơn của ConnectX-8 giúp tăng tốc các mô hình huấn luyện AI quy mô lớn trong thực tế. Các luồng dữ liệu cần độ trễ thấp và băng thông cao, đặc biệt là các phép toán giao tiếp tập thể (collective communication) như NCCL all-to-all trong các hệ thống đa GPU và đa node, sẽ được hưởng lợi lớn. Dữ liệu cho thấy nền tảng mới này có thể mang lại hiệu suất NCCL all-to-all cao hơn tới 2 lần, một chỉ số quan trọng cho khả năng mở rộng của các “AI factories”. Điều này chứng minh rằng ConnectX-8 không chỉ là một sự nâng cấp về tốc độ mà là một sự thay đổi cơ bản trong cách dữ liệu được xử lý trong các trung tâm dữ liệu AI.
Lời kết
NVIDIA ConnectX-8 SuperNICs, được xây dựng trên nền tảng PCIe Gen6, đại diện cho một bước tiến quan trọng trong kiến trúc hạ tầng AI dựa trên PCIe. Bằng cách tích hợp switch PCIe và giao diện mạng tốc độ cao vào một thiết bị duy nhất, nó giải quyết một cách hiệu quả các điểm nghẽn của các thiết kế truyền thống. Khả năng bỏ qua CPU giúp cải thiện đáng kể giao tiếp giữa các GPU và giữa GPU với mạng, mang lại hiệu suất vượt trội cho các tác vụ tính toán chuyên sâu.
Được kích hoạt bởi các đổi mới kỹ thuật của PCIe Gen6, bao gồm mã hóa PAM4, chế độ FLIT và cơ chế sửa lỗi FEC, ConnectX-8 SuperNICs không chỉ tăng gấp đôi băng thông mà còn nâng cao hiệu quả và độ tin cậy của luồng dữ liệu. Sự đơn giản hóa thiết kế và giảm số lượng linh kiện cũng giúp giảm chi phí sở hữu tổng thể, làm cho các nền tảng AI mạnh mẽ trở nên dễ tiếp cận hơn đối với các doanh nghiệp.
Tóm lại, ConnectX-8 SuperNIC và PCIe Gen6 là những mảnh ghép nền tảng, thiết yếu để xây dựng thế hệ hạ tầng AI tiếp theo. Chúng giải quyết các thách thức về băng thông và độ trễ, mở đường cho việc phát triển các mô hình AI ngày càng lớn và phức tạp hơn với hiệu suất và TCO được tối ưu hóa, đảm bảo một tương lai bền vững cho các “AI factories”.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?