
Hiện nay, vẫn còn hiều người nghĩ rằng trí tuệ nhân tạo (AI) chỉ xoay quanh GPU, nhưng đây chỉ là một phần nhỏ của toàn bộ câu chuyện. Đúng là việc huấn luyện mô hình nền tảng tiêu tốn nhiều tài nguyên từ GPU, và tùy thuộc vào lượng dữ liệu cũng như kích thước mô hình, có thể yêu cầu hàng nghìn GPU và giờ làm việc, cùng với lượng điện năng khổng lồ. Tuy nhiên, đó chỉ là một phần của quá trình cần thiết để xây dựng các hệ thống dữ liệu mạnh mẽ, biến dữ liệu thô thành các mô hình AI ứng dụng.
Hôm nay, chúng ta sẽ khám phá những công việc nặng nhọc diễn ra ngoài các cụm GPU: cách dữ liệu thô được xử lý, làm sạch và đưa vào hạ tầng huấn luyện mô hình, cũng như các bước xử lý tiếp theo. Mỗi giai đoạn đều được thực hiện một cách an toàn và đảm bảo tính minh bạch cũng như quản trị dữ liệu.
Hiểu về Hệ thống Dữ liệu trong AI
Trong AI, một hệ thống dữ liệu (data pipeline) được định nghĩa là: các quy trình và chuyển đổi mà dữ liệu trải qua từ trạng thái thô đến khi trở nên tinh lọc, chuẩn bị để huấn luyện các mô hình AI trước khi bước vào các giai đoạn tinh chỉnh, lượng tử hóa và suy luận, có hoặc không có RAG/RLHF. Bài viết này sẽ tập trung vào các giai đoạn chuẩn bị dữ liệu và huấn luyện.

Phần này của hành trình bao gồm nhiều giai đoạn, từ việc thu thập dữ liệu, làm sạch, chuyển đổi và “mã hóa” dữ liệu, trước khi đưa dữ liệu vào các mô hình AI. Quá trình này có thể diễn ra theo từng đợt (giống như quy trình ETL – Extract, Transform, Load – truyền thống cho cơ sở dữ liệu), nhưng hệ thống dữ liệu trong AI thường là các quy trình streaming, không dựa trên một thời điểm cố định. Sau khi mô hình được huấn luyện, các yếu tố quan trọng khác như tinh chỉnh, lượng tử hóa, sinh dữ liệu tăng cường (RAG), v.v., đóng vai trò quan trọng để đưa ra kết quả suy luận chính xác. Tất cả các giai đoạn này đều tiêu thụ và di chuyển dữ liệu. Như Giáo sư nổi tiếng của Đại học Stanford, Andrew Ng, đã nói:
Thay vì tập trung vào mã nguồn, các công ty nên chú trọng phát triển các phương pháp kỹ thuật hệ thống để cải thiện dữ liệu một cách đáng tin cậy, hiệu quả và có hệ thống. Nói cách khác, các công ty cần chuyển từ cách tiếp cận tập trung vào mô hình sang cách tiếp cận tập trung vào dữ liệu
Các thành phần quan trọng của hệ thống dữ liệu
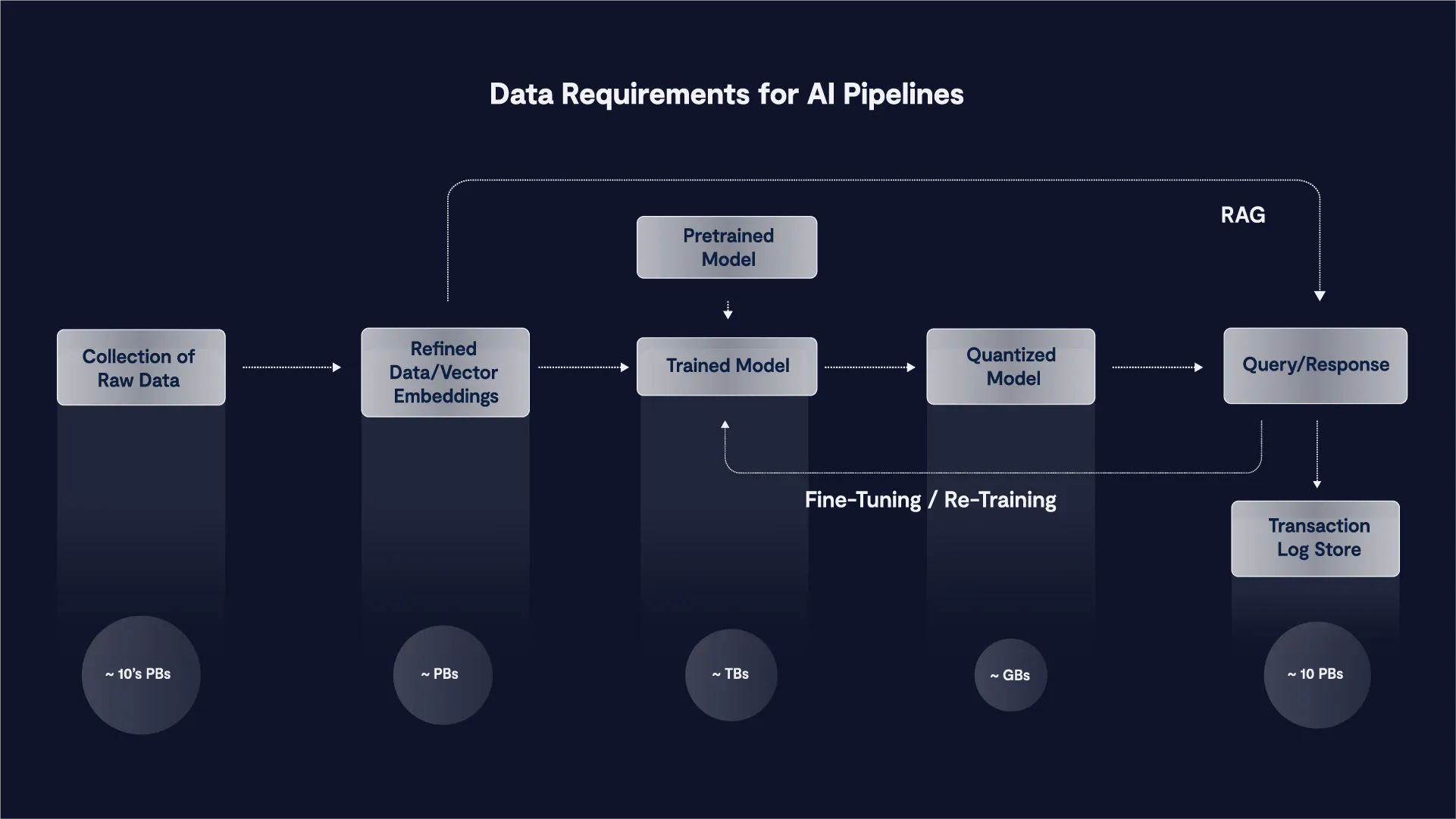
Nhiều người thường tập trung vào các GPU đắt đỏ để huấn luyện mô hình AI, nhưng họ sẽ sai lầm nếu bỏ qua sự thật rằng 80% thời gian huấn luyện thực tế được dành cho việc xử lý dữ liệu thô từ các nguồn như dữ liệu nội bộ của công ty, dữ liệu từ internet, Github, Arxiv và PubMed, cùng nhiều nguồn khác. Quá trình này bao gồm việc tinh chỉnh dữ liệu để nội dung phù hợp được định dạng đúng cho mô hình mà chúng ta muốn huấn luyện.
Tất cả các giai đoạn trong hệ thống dữ liệu đều tiêu thụ và tạo ra dữ liệu; việc di chuyển dữ liệu này chiếm một lượng thời gian đáng kể. VAST cung cấp một không gian tên chung cho tất cả các giai đoạn trong hệ thống dữ liệu, loại bỏ nhu cầu di chuyển dữ liệu từ giai đoạn này sang giai đoạn khác. Quá trình chuẩn bị dữ liệu ban đầu này mang tính lặp đi lặp lại cao và thường phải quay lại các bước trước đó để tinh chỉnh chính xác. Việc loại bỏ sự di chuyển dữ liệu giúp dự đoán trước được quá trình huấn luyện mô hình, từ đó giảm thời gian và chi phí huấn luyện tổng thể.
Ví dụ Thực Tế: Huấn luyện Mô hình GPT
Để minh họa hiệu quả của Nền tảng Dữ liệu VAST với các hệ thống dữ liệu AI, hãy xem xét ví dụ về việc huấn luyện các mô hình ngôn ngữ lớn (LLMs) như Generative Pre-trained Transformer (GPT). Huấn luyện các mô hình này đòi hỏi phải xử lý khối lượng lớn dữ liệu văn bản, yêu cầu việc thu thập, làm sạch, chuyển đổi và lưu trữ dữ liệu một cách hiệu quả. Hệ thống này phần nào được lấy cảm hứng từ hệ thống RefinedWeb, được sử dụng để tạo token cho mô hình TII/Falcon-40B LLM, một trong những mô hình thành công và có ảnh hưởng nhất trên HuggingFace.
Dưới đây là một ví dụ về hệ thống dữ liệu và quá trình chuyển đổi dữ liệu.
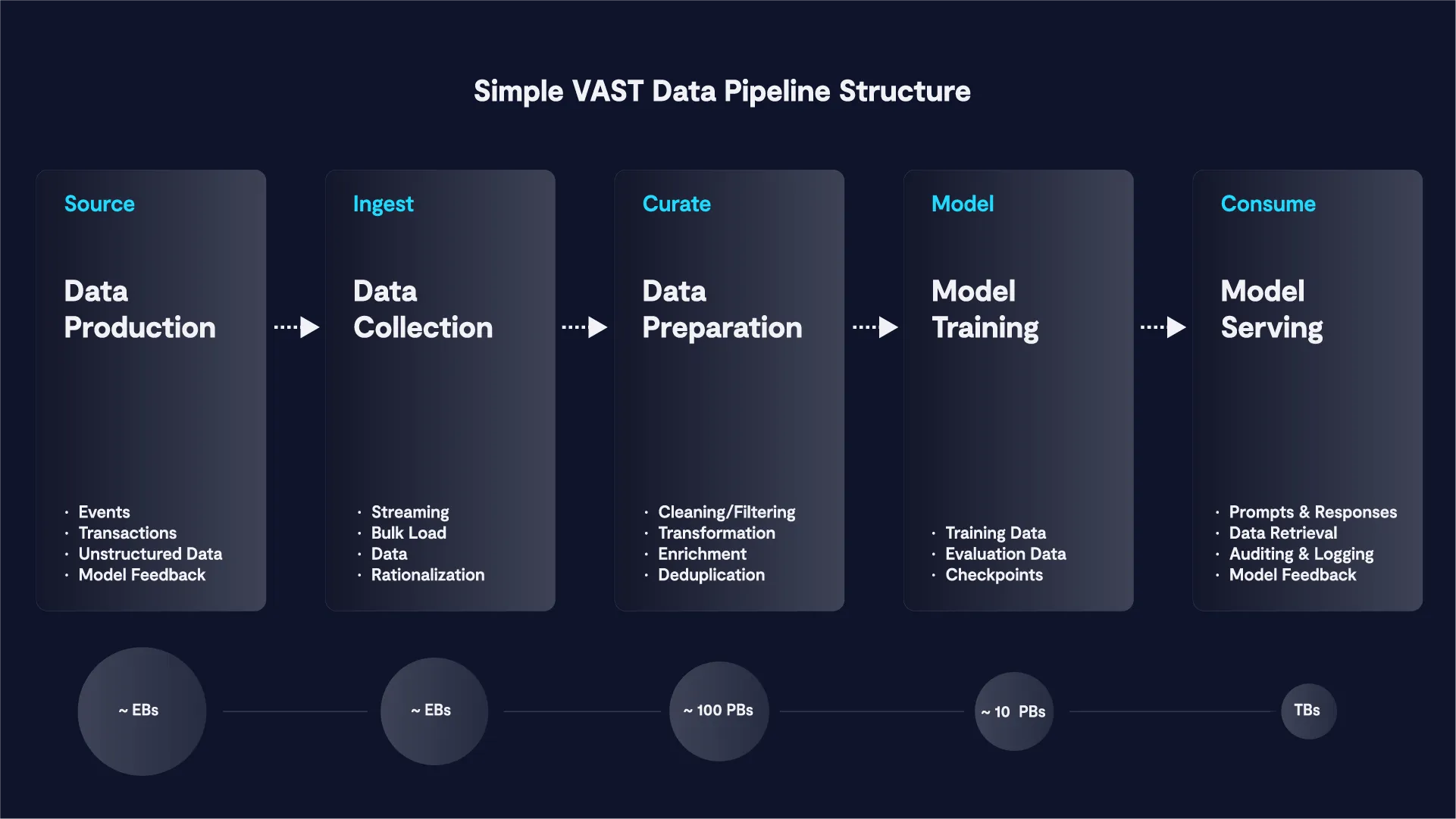
Quy Trình Từng Bước với VAST Data
- Thu thập Dữ liệu: Dữ liệu thô từ CommonCrawl, được lưu trữ trên AWS, được thu thập thông qua lớp lưu trữ tốc độ cao của VAST Data bằng các công cụ S3 gốc để đảm bảo việc thu thập dữ liệu nhanh chóng và hiệu quả. CommonCrawl là một dự án dài hạn chuyên thu thập dữ liệu từ Internet và tổng hợp các bản HTML thô của các trang web mà nó tìm thấy. Đây là điểm khởi đầu phổ biến nhất để tạo ra các tập dữ liệu huấn luyện cho các mô hình LLM.
- Làm sạch Dữ liệu: Dữ liệu thô sau đó được chuyển đổi sang định dạng Parquet. Dữ liệu HTML thô được phân tích để làm sạch nội dung, sử dụng các công cụ như BeautifulSoup để trích xuất văn bản hữu ích từ các mã markup được thu thập ban đầu. Nền tảng VAST Data cho phép lưu trữ dữ liệu thông qua các bản ghi trong VAST DataBase. Bằng cách tạo ra các trạng thái trung gian của quá trình xử lý dữ liệu, các quy trình làm sạch lặp đi lặp lại có thể diễn ra mà không cần bắt đầu lại từ đầu. Quá trình này sử dụng Spark, kết nối với VAST DataBase thông qua Spark Connector.
- Chuyển đổi Dữ liệu: Dữ liệu được chuyển đổi thông qua nhiều thao tác, như loại bỏ các từ trong danh sách đen, thẻ XML, cookie, menu thả xuống, v.v. Các bản ghi văn bản trùng lặp cũng bị loại bỏ. Cuối cùng, ngôn ngữ được xác định và lưu trữ dưới dạng một cột riêng trong cơ sở dữ liệu. Bằng cách này, việc chọn một ngôn ngữ cụ thể chỉ đơn giản là một yêu cầu truy vấn.
- Huấn luyện Dữ liệu: Giai đoạn cuối cùng là trích xuất các bản ghi văn bản để huấn luyện và chuyển đổi chúng thành các token. Quá trình token hóa và huấn luyện cho các mô hình GPT được thực hiện bằng cách sử dụng kho lưu trữ Megatron-LM từ NVIDIA trên GitHub.
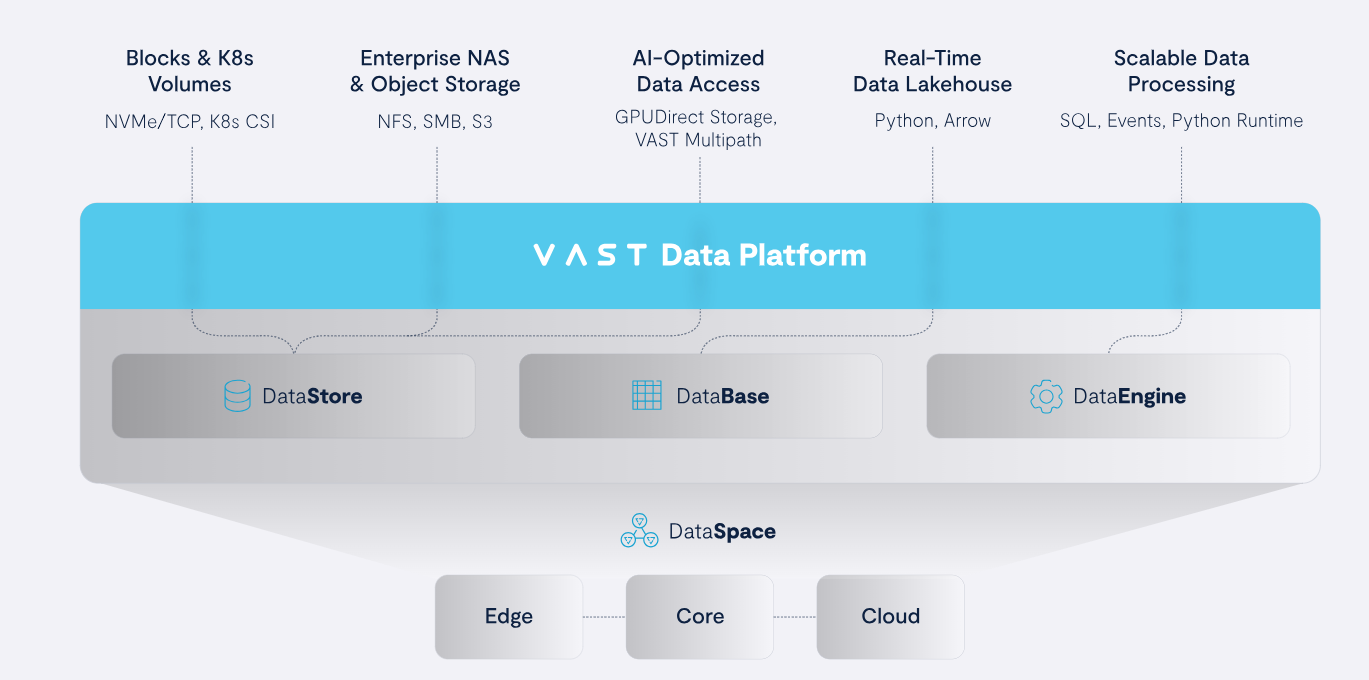
Cách Tiếp Cận của VAST trong Quản Lý Hệ thống Dữ liệu
Phương pháp của VAST tích hợp nhiều tính năng sáng tạo để giải quyết những thách thức đặc thù trong xử lý dữ liệu AI.
Lưu trữ Hiệu Suất Cao
Nền tảng của VAST Data được xây dựng trên một tầng lưu trữ flash duy nhất gọi là VAST DataStore, được thiết kế để xử lý lượng dữ liệu khổng lồ mà các ứng dụng AI yêu cầu. Nền tảng này cung cấp một không gian tên toàn cầu cho tất cả dữ liệu, hỗ trợ nhiều giao thức truy cập như NFS và GPUDirect để đảm bảo truy xuất dữ liệu liền mạch với tốc độ cao. Kiến trúc của nền tảng cho phép truy cập hiệu quả vào cả dữ liệu có cấu trúc và phi cấu trúc, phù hợp với các tác vụ AI đa dạng.
Giảm Thiểu Dữ Liệu Tiến Tiến
Một trong những điểm nổi bật của giải pháp VAST là khả năng giảm thiểu dữ liệu thông qua tính năng Similarity. Bằng cách sử dụng kỹ thuật loại bỏ dữ liệu trùng lặp ở mức độ tinh vi, VAST có thể giảm đáng kể dung lượng lưu trữ cần thiết cho các tập dữ liệu AI. Điều này không chỉ giảm chi phí lưu trữ mà còn tăng tốc quá trình xử lý dữ liệu, vì lượng dữ liệu cần thiết ở mỗi giai đoạn trong hệ thống dữ liệu được tối thiểu hóa.
Khả Năng Mở Rộng Linh Hoạt
Các dự án AI thường đòi hỏi khả năng mở rộng để đáp ứng sự gia tăng của dữ liệu và nhu cầu tính toán. Kiến trúc DASE (Disaggregated, Shared Everything) của VAST được xây dựng để mở rộng một cách dễ dàng, cho phép khả năng lưu trữ và xử lý được phát triển độc lập, đồng thời loại bỏ các rào cản về hiệu suất, khả năng hoạt động và dung lượng. Các mô hình AI có thể được huấn luyện trên các tập dữ liệu lớn hơn mà không ảnh hưởng đến hiệu suất.
Khả Năng Quản Lý và Nền Tảng Dữ Liệu
Phần lớn quá trình xử lý trong ví dụ này đều được thực hiện nhờ vào nền tảng VAST Data. Điều này bao gồm VAST DataBase, các kết nối Spark, hỗ trợ Apache Arrow, và SDK Python của VAST, mang đến một nền tảng độc đáo và linh hoạt để phát triển hệ thống dữ liệu nhanh chóng và lặp đi lặp lại. Các tính năng bảo mật mạnh mẽ như đa người dùng, mã hóa, kiểm tra toàn diện, ảnh chụp không thay đổi, và gắn thẻ metadata tạo nên một hệ sinh thái hấp dẫn cho thế giới AI.
Hoàn Thiện Quy Trình
Trong lĩnh vực AI, chất lượng và hiệu quả của các hệ thống dữ liệu đóng vai trò quyết định. VAST Data cung cấp khả năng lưu trữ hiệu suất cao, cho phép truy cập và lấy dữ liệu nhanh chóng, cần thiết cho việc phát triển và huấn luyện mô hình AI. Các tính năng như giảm thiểu dữ liệu dựa trên Similarity đảm bảo tối ưu hóa tài nguyên để xử lý nhanh hơn, tối đa hóa hiệu quả và tốc độ của các quy trình AI ở mọi giai đoạn trong hệ thống dữ liệu.
Ngoài ra, nền tảng VAST được thiết kế để mở rộng linh hoạt thông qua kiến trúc DASE, cho phép mở rộng hạ tầng dữ liệu dễ dàng, đáp ứng nhu cầu phát triển của các dự án AI. Điều này giúp các nhà khoa học dữ liệu quản lý và xử lý khối lượng dữ liệu tăng theo cấp số nhân mà không làm giảm hiệu suất hoặc độ tin cậy.

VAST cũng nhấn mạnh vào quản lý dữ liệu, đảm bảo rằng các chuyên gia AI có thể duy trì kiểm soát và tuân thủ nghiêm ngặt đối với dữ liệu của họ trong suốt vòng đời xử lý. Bằng cách tuân thủ các thực tiễn quản lý dữ liệu mạnh mẽ, VAST giúp các tổ chức bảo vệ tính toàn vẹn, bảo mật và tuân thủ quy định, tạo dựng niềm tin và sự tin cậy trong các quyết định dựa trên AI.
Tóm lại, dù đang phát triển các mô hình LLM hay khám phá các ứng dụng AI khác, VAST cung cấp một bộ công cụ và khả năng phong phú, đáp ứng các yêu cầu phức tạp của việc phát triển và triển khai AI. Đây là một cơ hội hấp dẫn cho những ai đang tìm kiếm thành công trong lĩnh vực AI. Ở mọi giai đoạn của hệ thống này, VAST luôn đặt dữ liệu là trung tâm của hệ sinh thái AI.
Để tìm hiểu cách chúng tôi có thể thực hiện điều này cho bạn, hãy tham gia sự kiện trực tuyến Cosmos vào ngày 1 và 2 tháng 10 năm 2024, hoặc tham gia chuyến lưu diễn của chúng tôi. Hãy đăng ký ngay và tham gia vào cuộc phiêu lưu vĩ đại tiếp theo trong lĩnh vực AI tại đây
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi hiện là đối tác phân phối giải pháp nền tảng dữ liệu doanh nghiệp VAST Data chuyên cho AI, Deep Learning.
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi hiện là đối tác phân phối giải pháp nền tảng dữ liệu doanh nghiệp VAST Data chuyên cho AI, Deep Learning.
Chúng tôi cũng là nhà phân phối chính thức của NVIDIA cho các hệ thống điện toán hiệu năng cao dựa trên GPU như siêu máy tính Trí tuệ Nhân tạo NVIDIA DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh xử lý của các dòng GPU Data Center tối tân nhất, cùng hệ thống lưu trữ dựa trên VAST Data và mạng tốc độ cao từ Mellanox (thuộc NVIDIA).
Bạn muốn trở thành đối tác bán hàng VAST của NTC?
Bài viết liên quan
- NVIDIA: Công nghệ Silicon Photonics và Co-Packaged Optics – Thay đổi cuộc chơi trong kỷ nguyên AI và HPC
- Giải pháp tích hợp AI vào hệ thống lưu trữ dữ liệu doanh nghiệp: Tương lai đã đến!
- 5 điều bạn cần biết về NVIDIA DGX Spark – Chiếc máy tính mơ ước của các nhà phát triển AI
- NVIDIA NVLink Thế hệ thứ 5: Bước nhảy vọt về băng thông cho kỷ nguyên AI nghìn tỷ tham số
- SLM và AI tại biên: Bình minh của một kỷ nguyên mới hay chỉ là cơn sốt nhất thời?
- Lựa chọn hạ tầng lưu trữ cho AI: NAS, SAN, hay Object Storage – Đâu là nền tảng tối ưu?