
NVIDIA Ampere là một trong hai thế hệ GPU mới nhất của NVIDIA. NVIDIA Ampere GPU trên VMware vSphere 7 Update 2 (hoặc cao hơn) có thể được chia sẻ giữa các máy ảo (VMs) ở một trong hai mode: Virtual GPU (vGPU) mode của VMware hoặc Multi-instance GPU (MIG) mode của NVIDIA. NVIDIA vGPU đã được kèm theo trong bộ phần mềm NVIDIA AI Enterprise, phần mềm được chứng nhận cho VMware vSphere.
Trong vGPU mode, bộ nhớ trên GPU được phân chia tĩnh nhưng tài nguyên tính toán (compute) được chia sẻ theo thời gian (time-shared) giữa các máy ảo dùng chung GPU. Ở mode này, khi một máy ảo đang chạy trên GPU, nó sở hữu tất cả khả năng tính toán của GPU nhưng chỉ có quyền truy cập vào phần bộ nhớ GPU của riêng nó.
Trong MIG mode, cả bộ nhớ và khả năng tính toán sẽ được phân chia tĩnh. Khi một máy ảo sử dụng một GPU trong MIG mode, nó chỉ có thể truy cập bộ nhớ và sử dụng các core tính toán được gán cho nó. Vì vậy, ngay cả khi các core tính toán còn lại không hoạt động (là các core không được gán cho máy ảo này) trong GPU, máy ảo cũng không thể sử dụng các core không hoạt động đó.
Bất kể máy ảo sử dụng mode nào để thực thi workload của nó, những kết quả tính toán là như nhau. Sự khác biệt duy nhất sẽ là ở hiệu suất đạt được, được đo bằng thời gian thực. Cả hai mode vGPU và MIG đều có những ưu điểm và nhược điểm tương ứng: vGPU mode chia sẻ thời gian các core tính toán, trong khi MIG mode phân chia tĩnh các core. Với sự khác biệt về cách các core được chia sẻ bởi hai mode này, câu hỏi đặt ra là chế độ nào mang lại hiệu suất tốt nhất (nghĩa là thời gian chạy thấp nhất) cho một workload nhất định. Hãy cùng tìm hiểu.
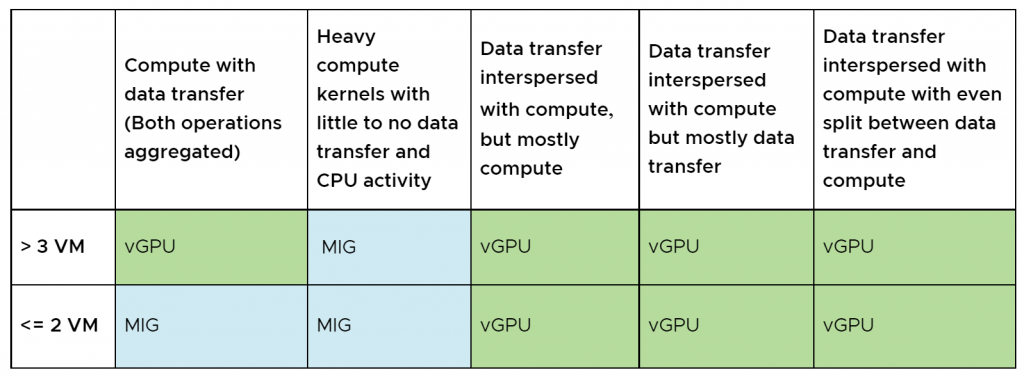 Bảng 1. Tóm tắt kết quả từ việc chạy thử nghiệm đơn vị với các profile compute và data transfer khác nhau.
Bảng 1. Tóm tắt kết quả từ việc chạy thử nghiệm đơn vị với các profile compute và data transfer khác nhau.
Chúng tôi đã chạy các thử nghiệm đơn vị – lấy cảm hứng từ ví dụ nhân ma trận (matrix multiplication) CUDA cổ điển, với các tỷ lệ tính toán (compute) cho đến truyền dữ liệu (data transfer) khác nhau từ host sang GPU và ngược lại, để xác định tiêu chí cho các workload nào sẽ cho hiệu suất tốt hơn ở MIG mode và tiêu chí nào sẽ hoạt động tốt hơn ở vGPU mode. Thử nghiệm của chúng tôi đã sử dụng 10 ma trận, mỗi ma trận có kích thước 1000×1000.
Các kết quả được trình bày trong blog này cho thấy rằng các workload thực thi CUDA kernels tính toán lớn, nặng mà không bị gián đoạn khi truyền dữ liệu hoặc tính toán CPU, cho thấy hiệu suất ở MIG mode tốt hơn so với vGPU mode. Nhưng khi CUDA kernels được xen kẽ với truyền dữ liệu hoặc gián đoạn để thực thi các tính toán của CPU, vGPU mode sẽ mang lại hiệu suất tốt hơn.
Vì vậy, các đặc điểm của workload xác định GPU mode, vGPU hay MIG, sẽ mang lại hiệu suất tốt nhất.
Môi trường test, code và kết quả
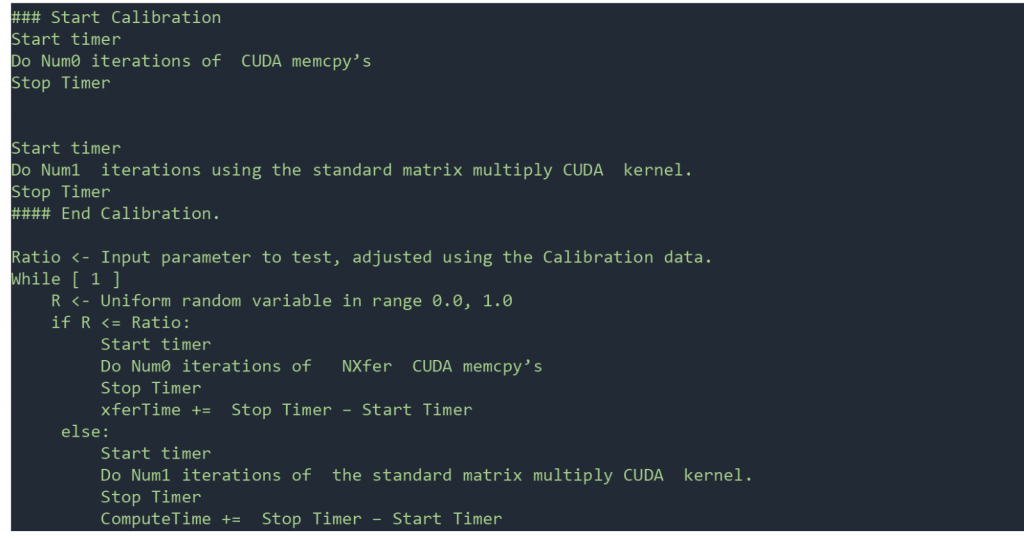 Hình 1. Pseudocode đối với thử nghiệm đơn vị – xen kẽ truyền dữ liệu với tính toán CUDA. Bài test có 10 ma trận, mỗi ma trận có kích thước 1000×1000.
Hình 1. Pseudocode đối với thử nghiệm đơn vị – xen kẽ truyền dữ liệu với tính toán CUDA. Bài test có 10 ma trận, mỗi ma trận có kích thước 1000×1000.
Các thử nghiệm đã được chạy trên Dell R740 (2 CPU Intel Xeon Gold 6140, 768GB RAM, SSD storage) với 2 GPU A100. Một GPU được cấu hình ở vGPU mode và GPU thứ hai được cấu hình ở MIG mode. Mã giả (pseudocode) cho bài test đầu tiên được hiển thị trong hình 1.
Bài test đã được chạy với các tỷ lệ truyền dữ liệu đến tính toán khác nhau. Các giá trị tỷ lệ mà chúng tôi đã test là 0% data transfer, 10% data transfer, 20% data transfer và như thế với bước nhảy là 10 cho đến 100% data transfer. Đối với mỗi tỷ lệ truyền dữ liệu đến tính toán, chúng tôi đã thay đổi số lượng máy ảo chạy đồng thời từ một cho đến mức tối đa được phép đối với profile vGPU hoặc MIG đó.
Ví dụ, với MIG profile a100-1-5c (biểu thị profile với một compute slice và bộ nhớ GPU 5 GB) nên tối đa 7 máy ảo có thể chia sẻ GPU. Vì vậy, với profile này, chúng tôi đã thay đổi số lượng máy ảo từ 1 đến 7. MIG profile a100-2-10c có thể hỗ trợ tối đa 3 máy ảo. Vì vậy, đối với profile này, chúng tôi đã thay đổi số lượng máy ảo từ 1 đến 3.
Thời gian chạy để thực hiện tính toán CUDA cho thử nghiệm này với 10% truyền dữ liệu đến 90% hoạt động tính toán được hiển thị trong Hình 2 (bên dưới). Từ hình này, chúng ta có thể thấy rằng khi truyền dữ liệu được xen kẽ với tính toán và tỷ lệ truyền dữ liệu là 10%, vGPU mode mang lại hiệu suất tốt hơn cho các tính toán CUDA.
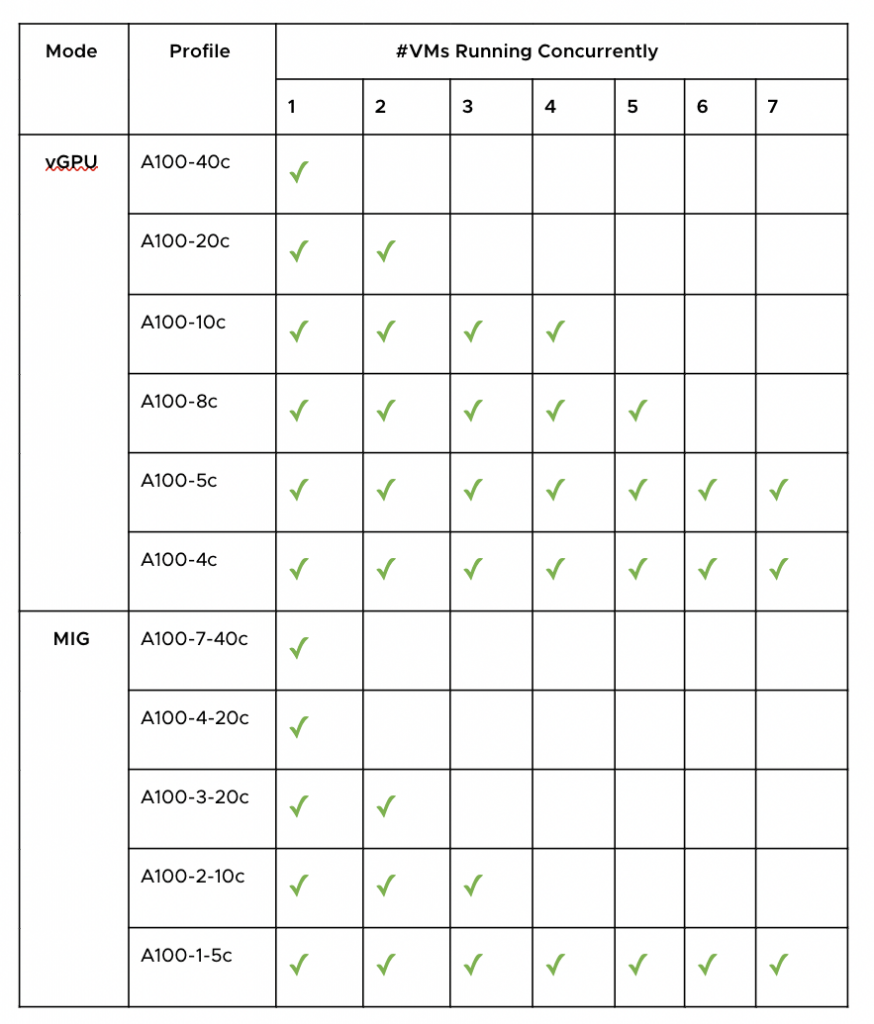 Bảng 2. Các cấu hình chúng tôi đã sử dụng cho cả ba bộ thử nghiệm. vGPU mode có thể hỗ trợ hơn 7 máy ảo chạy đồng thời trong profile A100-4c và A100-5c nhưng vì số lượng máy ảo tối đa có thể chạy đồng thời với MIG mode là 7 nên chúng tôi chỉ test với tối đa 7 máy ảo chạy đồng thời. Chúng tôi cũng không test với các mode MIG hỗn hợp, chẳng hạn như trong một VM với MIG mode A100-2-10c và VM thứ hai với A100-1-5c.
Bảng 2. Các cấu hình chúng tôi đã sử dụng cho cả ba bộ thử nghiệm. vGPU mode có thể hỗ trợ hơn 7 máy ảo chạy đồng thời trong profile A100-4c và A100-5c nhưng vì số lượng máy ảo tối đa có thể chạy đồng thời với MIG mode là 7 nên chúng tôi chỉ test với tối đa 7 máy ảo chạy đồng thời. Chúng tôi cũng không test với các mode MIG hỗn hợp, chẳng hạn như trong một VM với MIG mode A100-2-10c và VM thứ hai với A100-1-5c.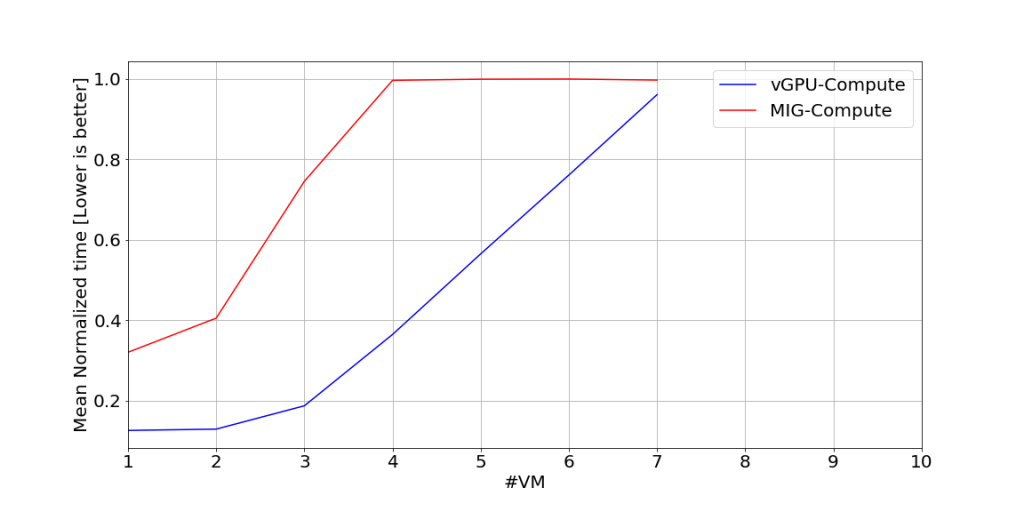 Hình 2. Thời gian chạy chuẩn hóa trung bình để thực thi các tính toán CUDA cho thử nghiệm được hiển thị trong Hình 1. Những kết quả này thu được với tỷ lệ 10% data transfer. Để chuẩn hóa thời gian chạy, chúng tôi chia thời gian chạy đo được cho bộ dữ liệu này cho thời gian tối đa trong bộ dữ liệu này.
Hình 2. Thời gian chạy chuẩn hóa trung bình để thực thi các tính toán CUDA cho thử nghiệm được hiển thị trong Hình 1. Những kết quả này thu được với tỷ lệ 10% data transfer. Để chuẩn hóa thời gian chạy, chúng tôi chia thời gian chạy đo được cho bộ dữ liệu này cho thời gian tối đa trong bộ dữ liệu này.
Trong hình 3 (bên dưới), chúng tôi hiển thị kết quả từ thử nghiệm này với tỷ lệ 50% data transfer với 50% compute. Các biểu đồ hiển thị thời gian chạy cho toàn bộ bài kiểm tra và chỉ cho các tính toán. Trong hình 2 và 3, chúng ta có thể thấy rằng vGPU hoạt động tốt hơn chế độ MIG khi truyền dữ liệu được xen kẽ với tính toán và tỷ lệ truyền dữ liệu là 50%. Từ dữ liệu ở các giá trị khác của tỷ lệ truyền dữ liệu so với tính toán (không hiển thị ở đây), vGPU hoạt động tốt hơn chế độ MIG bất cứ khi nào tính toán CUDA được xen kẽ với truyền dữ liệu bất kể tỷ lệ truyền dữ liệu so với tính toán CUDA.
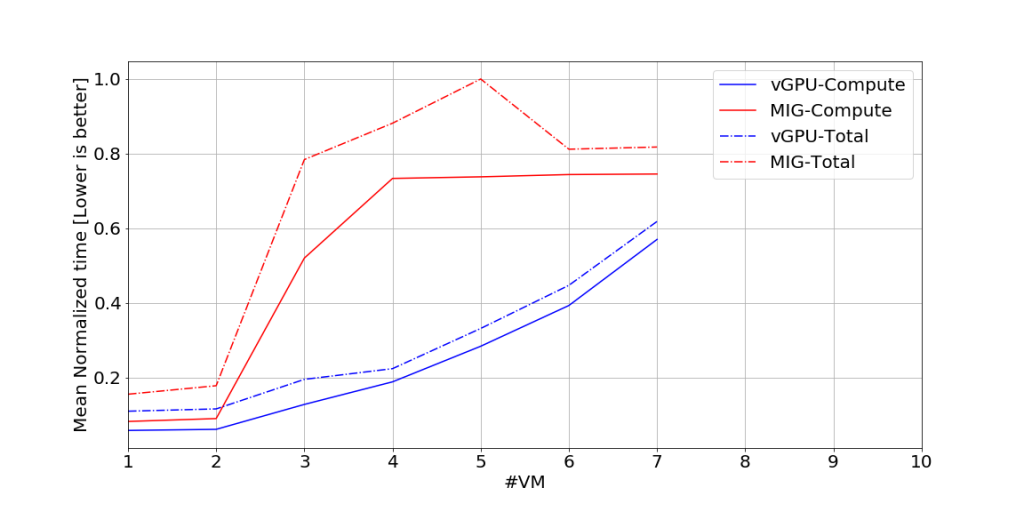 Hình 3. Thời gian chạy chuẩn hóa trung bình để thực hiện tính toán CUDA và toàn bộ thử nghiệm cho thử nghiệm được thể hiện trong hình 1. Những kết quả này thu được với tỷ lệ truyền dữ liệu 50%. Để chuẩn hóa thời gian chạy, chúng tôi chia thời gian chạy đo được cho tập dữ liệu này cho thời gian tối đa trong tập dữ liệu này.
Hình 3. Thời gian chạy chuẩn hóa trung bình để thực hiện tính toán CUDA và toàn bộ thử nghiệm cho thử nghiệm được thể hiện trong hình 1. Những kết quả này thu được với tỷ lệ truyền dữ liệu 50%. Để chuẩn hóa thời gian chạy, chúng tôi chia thời gian chạy đo được cho tập dữ liệu này cho thời gian tối đa trong tập dữ liệu này.
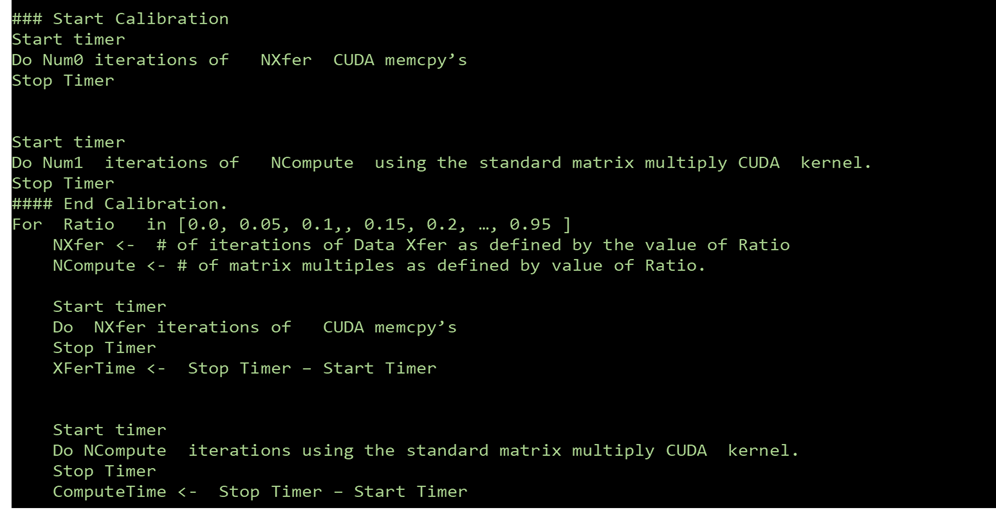
Hình 4. Mã giả cho thử nghiệm thực hiện cả truyền dữ liệu và tính toán, nhưng các hoạt động được tổng hợp; tất cả quá trình truyền dữ liệu được hoàn thành trước khi thực hiện tính toán (nghĩa là các hoạt động KHÔNG được xen kẽ). Bài kiểm tra có mười ma trận, mỗi ma trận có kích thước 1000X1000.
Trong loạt thử nghiệm thứ hai, chúng tôi đã thay đổi mã để tất cả các hoạt động truyền dữ liệu được hoàn thành trước khi chúng tôi chạy bất kỳ phép tính CUDA nào (xem mã giả trong hình 4 ở trên). Đối với loại khối lượng công việc này, chế độ MIG hoạt động tốt hơn vGPU với tối đa khoảng ba máy ảo chạy đồng thời. Với hơn ba máy ảo chạy đồng thời, sẽ có một điểm giao nhau và chế độ vGPU mang lại hiệu suất tốt hơn ở mức độ hợp nhất cao hơn (nghĩa là với nhiều hơn ba máy ảo). Hình 5 cho thấy dữ liệu từ thử nghiệm này. Dữ liệu được cắt bớt ở bốn máy ảo để làm nổi bật điểm giao nhau.
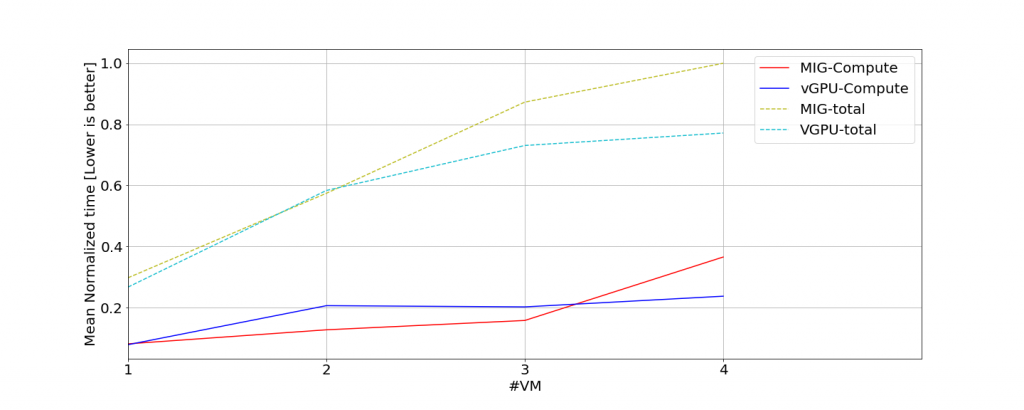 Hình 5. Thời gian chạy chuẩn hóa trung bình để thực hiện tính toán CUDA và cho toàn bộ bài kiểm tra cho bài kiểm tra được hiển thị trong hình 4. Để chuẩn hóa thời gian chạy, chúng tôi chia thời gian chạy đo được cho tập dữ liệu này cho thời gian tối đa trong tập dữ liệu này. Tổng thời gian bao gồm cả thời gian tính toán và truyền dữ liệu.
Hình 5. Thời gian chạy chuẩn hóa trung bình để thực hiện tính toán CUDA và cho toàn bộ bài kiểm tra cho bài kiểm tra được hiển thị trong hình 4. Để chuẩn hóa thời gian chạy, chúng tôi chia thời gian chạy đo được cho tập dữ liệu này cho thời gian tối đa trong tập dữ liệu này. Tổng thời gian bao gồm cả thời gian tính toán và truyền dữ liệu.
Trong loạt thử nghiệm cuối cùng, chúng tôi đã thay đổi mã để chỉ các tính toán CUDA được thực thi. Mã giả được hiển thị trong hình 6 bên dưới.
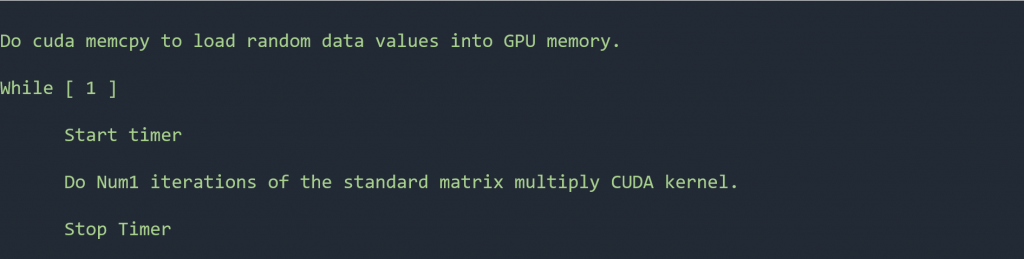 Hình 6. Mã giả cho thử nghiệm chỉ thực hiện tính toán CUDA chỉ với một lần truyền dữ liệu để tải dữ liệu khi bắt đầu. Bài kiểm tra có mười ma trận, mỗi ma trận có kích thước 1000X1000.
Hình 6. Mã giả cho thử nghiệm chỉ thực hiện tính toán CUDA chỉ với một lần truyền dữ liệu để tải dữ liệu khi bắt đầu. Bài kiểm tra có mười ma trận, mỗi ma trận có kích thước 1000X1000.
Chúng tôi đã chạy thử nghiệm này với tất cả cấu hình vGPU và MIG. Kết quả thể hiện trong hình 7 (bên dưới) cho thấy rõ ràng rằng chế độ MIG mang lại hiệu suất tốt hơn ở hầu hết mọi cấu hình và cấu hình với khối lượng công việc này.
 Hình 7. Tổng thời gian chạy thử nghiệm chỉ với tính toán CUDA. Chế độ MIG mang lại hiệu suất tốt nhất ở tất cả các cấu hình với khối lượng công việc này.
Hình 7. Tổng thời gian chạy thử nghiệm chỉ với tính toán CUDA. Chế độ MIG mang lại hiệu suất tốt nhất ở tất cả các cấu hình với khối lượng công việc này.
Kết luận
NVIDIA A100 và A30 Tensor Core GPU trên VMware vSphere hỗ trợ chia sẻ một GPU giữa nhiều máy ảo bằng hai mode: vGPU và MIG. Sự khác biệt về cách phân chia các core tính toán CUDA có thể gây ra sự khác biệt về hiệu suất đạt được khi sử dụng vGPU mode so với MIG mode cho cùng một workload.
Bài viết liên quan
- GPU NVIDIA L40S: Sự đổi mới và tính hiệu quả cho Trí Tuệ Nhân Tạo
- Vì sao ARM đang dần phổ biến hơn trong các Trung tâm dữ liệu và HPC?
- NVIDIA HGX 8x A100: Nền tảng tăng tốc mạnh mẽ cho AI và ChatGPT
- Nhu cầu GPU NVIDIA vượt quá nguồn cung khi ChatGPT và các hãng đầu tư mạnh vào AI
- GPU NVIDIA A100 đạt kết quả tốt nhất trong chỉ số Suy Luận AI cho ngành Dịch Vụ Tài Chính