
GPU NVIDIA A30 được xây dựng trên Kiến trúc NVIDIA Ampere mới nhất để tăng tốc các tải công việc chuyên sâu như đào tạo và suy luận AI trên quy mô lớn, các ứng dụng HPC cho các máy chủ mainstream trong trung tâm dữ liệu. GPU A30 PCIe kết hợp các Tensor Core thế hệ thứ ba với bộ nhớ HBM2 lớn (24 GB) và băng thông bộ nhớ GPU cao (933 GB/s) trong một thiết kế nhỏ gọn low profile và năng lượng thấp (tối đa 165 W).

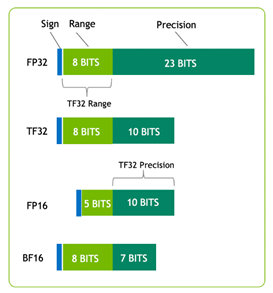
NVIDIA A30 hỗ trợ đa dạng các phép toán học:
- double-precision (FP64)
- single-precision (FP32)
- half-precision (FP16)
- Brain Float 16 (BF16)
- Integer (INT8)
Nó cũng hỗ trợ các cải tiến như Tensor Float 32 (TF32) và Tensor Core FP64, cung cấp một bộ tăng tốc duy nhất để tăng tốc mọi khối lượng công việc.
Hình 1 cho thấy TF32, có phạm vi FP32 và độ chính xác là FP16. TF32 là tùy chọn mặc định trong PyTorch, TensorFlow và MXNet, vì vậy không cần thay đổi mã để tăng tốc độ trên Kiến trúc NVIDIA Volta thế hệ mới nhất.
Một tính năng quan trọng khác của A30 là khả năng thiết lập đa GPU / Multi-Instance GPU (MIG). MIG có thể tối đa hóa việc sử dụng GPU trên các tải công việc từ lớn đến nhỏ và đảm bảo chất lượng dịch vụ (QoS). Một A30 duy nhất có thể được phân vùng tối đa bốn đơn vị MIGs để chạy bốn ứng dụng đồng thời, mỗi ứng dụng được cô lập hoàn toàn với khả năng đa xử lý trực tuyến (SM), bộ nhớ, bộ đệm L2, băng thông DRAM và bộ giải mã. Để biết thêm thông tin, hãy xem các profile MIG được hỗ trợ .

Về mặt kết nối, A30 hỗ trợ cả PCIe Gen4 (64 GB/s) và NVLink thế hệ thứ ba tốc độ cao (tối đa 200 GB/s). Mỗi A30 có thể hỗ trợ một kết nối cầu NVLink với một thẻ A30 liền kề. Bất cứ nơi nào tồn tại một cặp thẻ A30 liền kề trong máy chủ, cặp này phải được kết nối bằng cầu NVLink kéo dài hai khe PCIe để có hiệu suất tốt nhất và cấu trúc liên kết cầu cân bằng.
| NVIDIA T4 | NVIDIA A30 | |
| Design | Small Footprint Data Center & Edge Inference | AI Inference & Mainstream Compute |
| Form Factor | x16 PCIe Gen3 1 slot LP |
x16 PCIe Gen4 2 Slot FHFL 1 NVLink bridge |
| Memory | 16GB GDDR6 | 24GB HBM2 |
| Memory Bandwidth | 320 GB/s | 933 GB/s |
| Multi-Instance GPU | No support | Up to 4 |
| Media Acceleration | 1 Video Encoder 2 Video Decoder | 1 JPEG Decoder 4 Video Decoder |
| Fast FP64 | No | Yes |
| Ray Tracing | Yes | No |
| Power | 70W | 165W |

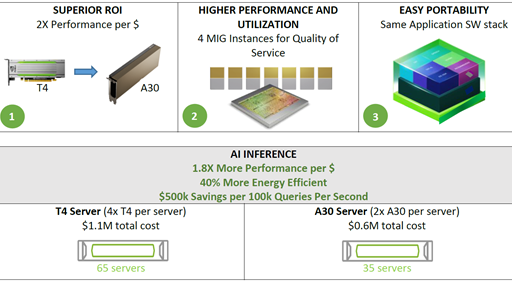
Ngoài những lợi ích phần cứng được tóm tắt trong Bảng 1, A30 có thể đạt được hiệu suất cao hơn trên mỗi đô la so với GPU T4. A30 cũng hỗ trợ các giải pháp ngăn xếp phần mềm end-to-end:
- Thư viện
- Các khung học tập sâu được tăng tốc bằng GPU như PyTorch, TensorFlow và MXNet
- Các mô hình học sâu được tối ưu hóa
- Hơn 2.000 ứng dụng HPC và AI, có thể nhận được từ NGC
Phân tích hiệu suất
Để phân tích sự cải thiện hiệu suất của A30 so với T4 và CPU, một thử nghiệm đã được thực hiện với việc đánh giá sáu mô hình từ MLPerf Inference v1.1 với các bộ dữ liệu:
- ResNet-50 v1.5 (ImageNet)
- SSD-Large ResNet-34 (COCO)
- 3D-Unet (BraTS 2019)
- DLRM (1TB Click Logs, offline scenario)
- BERT (SQuAD v1.1, seq-len: 384)
- RNN-T (LibriSpeech)
Bộ tiêu chuẩn MLPerf bao gồm một loạt các trường hợp sử dụng suy luận, từ phân loại hình ảnh và phát hiện đối tượng cho đến các khuyến nghị và xử lý ngôn ngữ tự nhiên (NLP).
Hình 2 cho thấy kết quả so sánh hiệu suất của A30 với T4 và CPU trên khối lượng công việc suy luận AI. A30 nhanh hơn khoảng 300 lần so với CPU cho phép suy luận BERT.
So với T4, A30 mang lại tốc độ hiệu suất gấp khoảng 3-4 lần để suy luận bằng cách sử dụng sáu kiểu máy. Việc tăng tốc hiệu suất là do kích thước bộ nhớ lớn hơn A30. Điều này cho phép kích thước lô lớn hơn cho các mô hình và băng thông bộ nhớ GPU nhanh hơn (gần 3 lần T4), có thể gửi dữ liệu đến các lõi tính toán trong thời gian ngắn hơn nhiều.
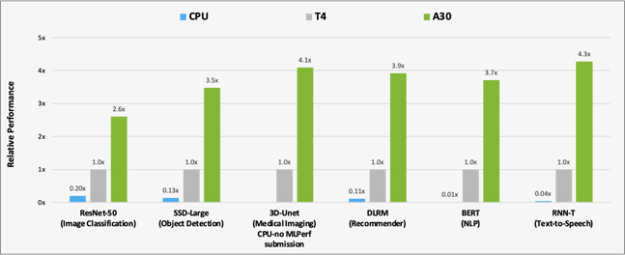
CPU: 8380H (không gửi trên 3D-Unet)
Ngoài suy luận AI, GPU A30 có thể đào tạo trước nhanh chóng các mô hình AI như BERT Large với TF32, cũng như tăng tốc các ứng dụng HPC bằng cách sử dụng FP64 Tensor Cores. A30 với Lõi Tensor TF32 cung cấp hiệu suất cao hơn gấp 10 lần so với T4 mà không yêu cầu bất kỳ thay đổi nào trong mã của bạn. Chúng cũng cung cấp khả năng tăng gấp 2 lần với độ chính xác hỗn hợp tự động, mang lại mức tăng thông lượng tổng hợp 20 lần.
Bộ giải mã phần cứng
Trong khi xây dựng phân tích video hoặc đường dẫn xử lý video, có một số hoạt động phải được xem xét:
- Tính toán các yêu cầu cho mô hình của bạn hoặc các bước tiền xử lý. Điều này liên quan đến Tensor Cores, GPU DRAM và các thành phần phần cứng khác giúp tăng tốc các mô hình hoặc các nhân tiền xử lý khung.
- Mã hóa luồng video trước khi truyền. Điều này được thực hiện để giảm thiểu băng thông cần thiết trên mạng. Để tăng tốc khối lượng công việc này, hãy sử dụng bộ giải mã phần cứng NVIDIA.
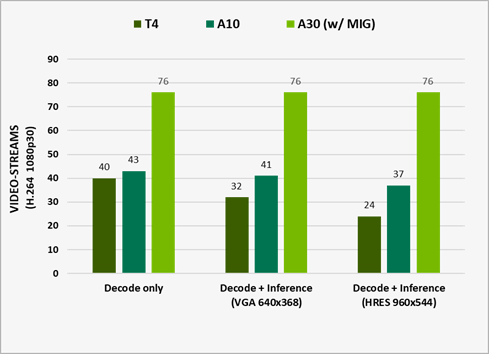
A30 được thiết kế để tăng tốc phân tích video thông minh (IVA) bằng cách cung cấp bốn bộ giải mã video, một bộ giải mã JPEG và một bộ giải mã luồng quang. Để sử dụng các bộ giải mã này cùng với các tài nguyên máy tính để phân tích video, hãy sử dụng NVIDIA DeepStream SDK, cung cấp bộ công cụ phân tích phát trực tuyến hoàn chỉnh để hiểu video, âm thanh và hình ảnh dựa trên AI.
Tiếp theo?
Là đại diện cho nền tảng AI và HPC end-to-end mạnh mẽ nhất cho các trung tâm dữ liệu, A30 cho phép các nhà nghiên cứu, kỹ sư và nhà khoa học dữ liệu cung cấp kết quả trong thế giới thực và triển khai các giải pháp vào sản xuất trên quy mô lớn. Với NVIDIA GPU A30, các doanh nghiệp có thể triển khai AI và HPC linh động và hiệu quả trên nền tảng Data Center mà lại tối ưu hơn về chi phí đầu tư, TCO…
→ Xem thêm: Các máy chủ Supermicro được chứng nhận cho GPU NVIDIA A30, A100
→ Xem thêm: Các sản phẩm GPU NVIDIA
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?