
NVIDIA H100 và H200 đều là những “quái vật” GPU được thiết kế cho các tác vụ điện toán hiệu năng cao (HPC) và trí tuệ nhân tạo (AI), đặc biệt là các mô hình ngôn ngữ lớn (LLM) và các ứng dụng AI tạo sinh. Ra mắt trong khoảng thời gian tương đối gần nhau, H200 được xem là một bản nâng cấp “giữa chu kỳ” của kiến trúc Hopper đình đám, trước khi thế hệ Blackwell hoàn toàn mới nắm giữ vị trí dẫn đầu.
Bài viết này sẽ đi sâu vào so sánh sự khác biệt cốt lõi giữa H100 và H200, lý do NVIDIA ra mắt H200, và định vị của chúng trong bối cảnh phát triển chóng mặt của AI và HPC, đặc biệt khi thế hệ Blackwell đã xuất hiện.
NVIDIA H100: Người khai mở kỷ nguyên Hopper
Được ra mắt vào tháng 3 năm 2022, NVIDIA H100 Tensor Core GPU là GPU đầu tiên dựa trên kiến trúc Hopper. Ngay lập tức, H100 đã tạo ra một cuộc cách mạng trong lĩnh vực AI và HPC với những cải tiến vượt bậc so với thế hệ tiền nhiệm Ampere (A100).

Những điểm nổi bật của H100:
- Kiến trúc Hopper: Với Streaming Multiprocessors (SMs) được thiết kế lại, nâng cao hiệu suất xử lý Tensor Cores.
- Tensor Cores thế hệ thứ 4: Tăng tốc độ tính toán ma trận, hỗ trợ nhiều định dạng dữ liệu hơn.
- Transformer Engine: Một tính năng đột phá được thiết kế đặc biệt để tăng tốc huấn luyện và suy luận các mô hình Transformer, trụ cột của các LLM hiện đại.
- NVLink thế hệ thứ 4: Cung cấp băng thông kết nối GPU cực cao (900 GB/s), cho phép mở rộng hệ thống AI lên quy mô hàng ngàn GPU.
- HBM3/HBM2e Memory: Tùy chọn 80GB bộ nhớ HBM3 hoặc HBM2e với băng thông lên tới 3.35 TB/s.
H100 nhanh chóng trở thành lựa chọn hàng đầu cho các trung tâm dữ liệu, viện nghiên cứu và doanh nghiệp phát triển AI nhờ khả năng xử lý mạnh mẽ các khối lượng công việc khổng lồ, từ huấn luyện LLM đến mô phỏng khoa học phức tạp.
NVIDIA H200: Nâng cấp bộ nhớ, đẩy mạnh hiệu năng LLM
NVIDIA H200 Tensor Core GPU được công bố vào tháng 11 năm 2023 tại hội nghị Supercomputing (SC23) và bắt đầu xuất xưởng rộng rãi từ quý 2 năm 2024. H200 không phải là một kiến trúc hoàn toàn mới mà là một bản nâng cấp trực tiếp của H100, với trọng tâm chính là cải thiện đáng kể về bộ nhớ.

Điểm khác biệt cốt lõi: Bộ nhớ HBM3e
Đây chính là “át chủ bài” của H200. Trong khi H100 sử dụng HBM3 (hoặc HBM2e), H200 được trang bị bộ nhớ HBM3e (High Bandwidth Memory 3 Extended) tiên tiến hơn.
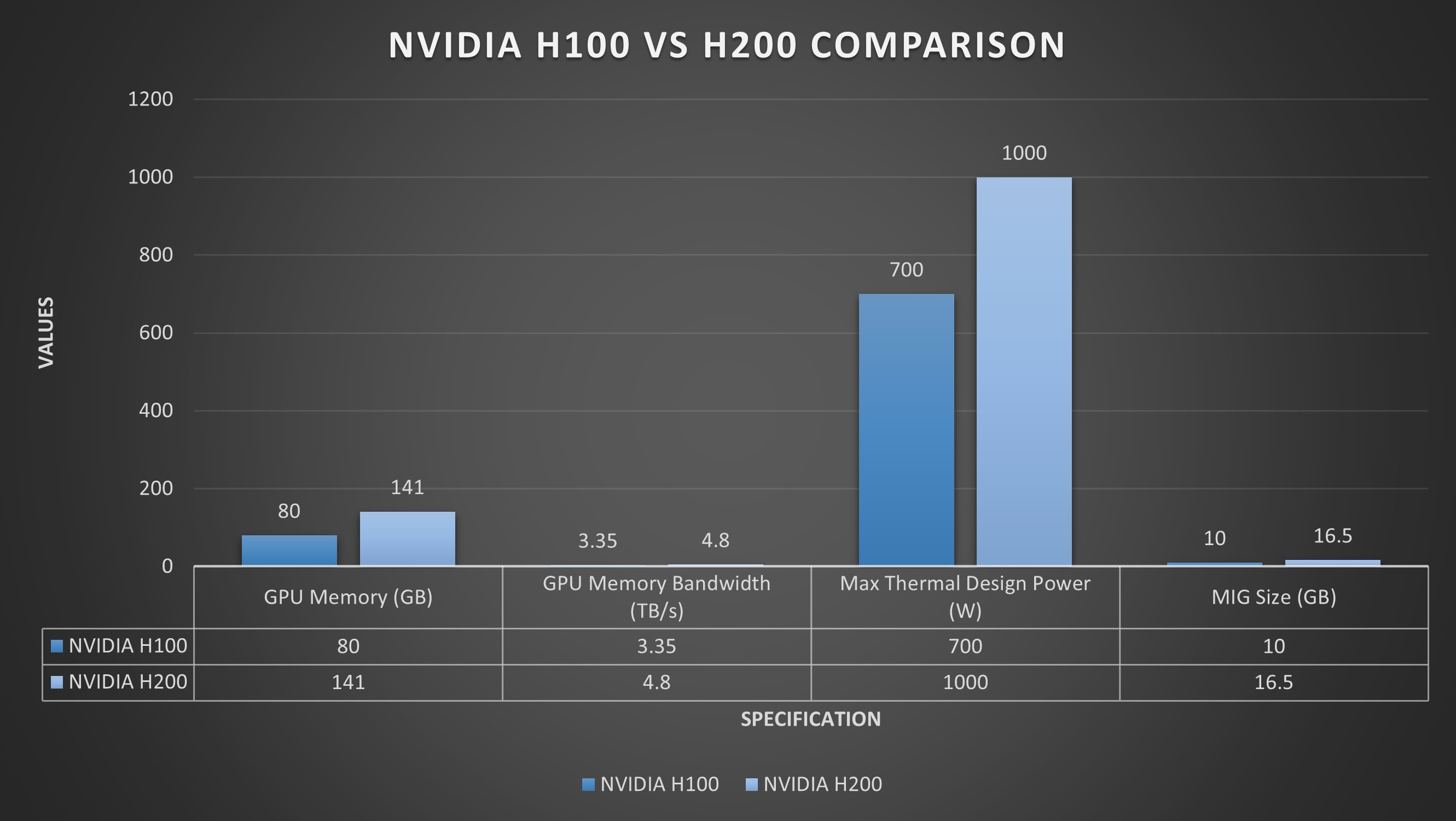
NVIDIA H100 (SXM) |
NVIDIA H200 (SXM) |
|
| Kiến trúc | Hopper | Hopper |
| Bộ nhớ (VRAM) | 80GB HBM3 hoặc HBM2e | 141GB HBM3e |
| Băng thông bộ nhớ | 3.35 TB/s (HBM3) | 4.8 TB/s |
| Số lượng chip HBM | 8 | 6 |
| Tốc độ xung nhịp HBM | 5.2 Gbps | 6.4 Gbps |
| NVLink Bandwidth | 900 GB/s | 900 GB/s |
| TDP | 700W | 1000W (có phiên bản 700W cho PCIe) |
| Công nghệ AI chính | Tensor Cores thế hệ 4, Transformer Engine | Tensor Cores thế hệ 4, Transformer Engine |
| Tăng tốc LLM (so với H100) | N/A | ~1.6 lần (cho các mô hình lớn như Llama 2 70B) |
| Vai trò | Flagship AI/HPC GPU (2022-2023) | Nâng cấp tập trung vào bộ nhớ, bước đệm |
Tại sao H200 lại quan trọng với chỉ nâng cấp bộ nhớ?
Trong thế giới AI hiện đại, đặc biệt là với các mô hình ngôn ngữ lớn (LLM) và các ứng dụng AI tạo sinh, dung lượng và băng thông bộ nhớ (VRAM) là yếu tố cực kỳ quan trọng, đôi khi còn hơn cả sức mạnh tính toán thuần túy.
- “Đói” bộ nhớ: Các LLM khổng lồ với hàng tỷ tham số cần một lượng lớn VRAM để tải toàn bộ mô hình vào GPU, đặc biệt là trong giai đoạn suy luận (inference) để giảm độ trễ.
- Thắt nút cổ chai băng thông: Quá trình đọc/ghi dữ liệu từ bộ nhớ là một điểm thắt nút cổ chai phổ biến. Băng thông HBM3e cao hơn 44% so với HBM3 trên H100 giúp cung cấp dữ liệu cho các nhân xử lý nhanh hơn, từ đó tăng cường hiệu suất tổng thể.
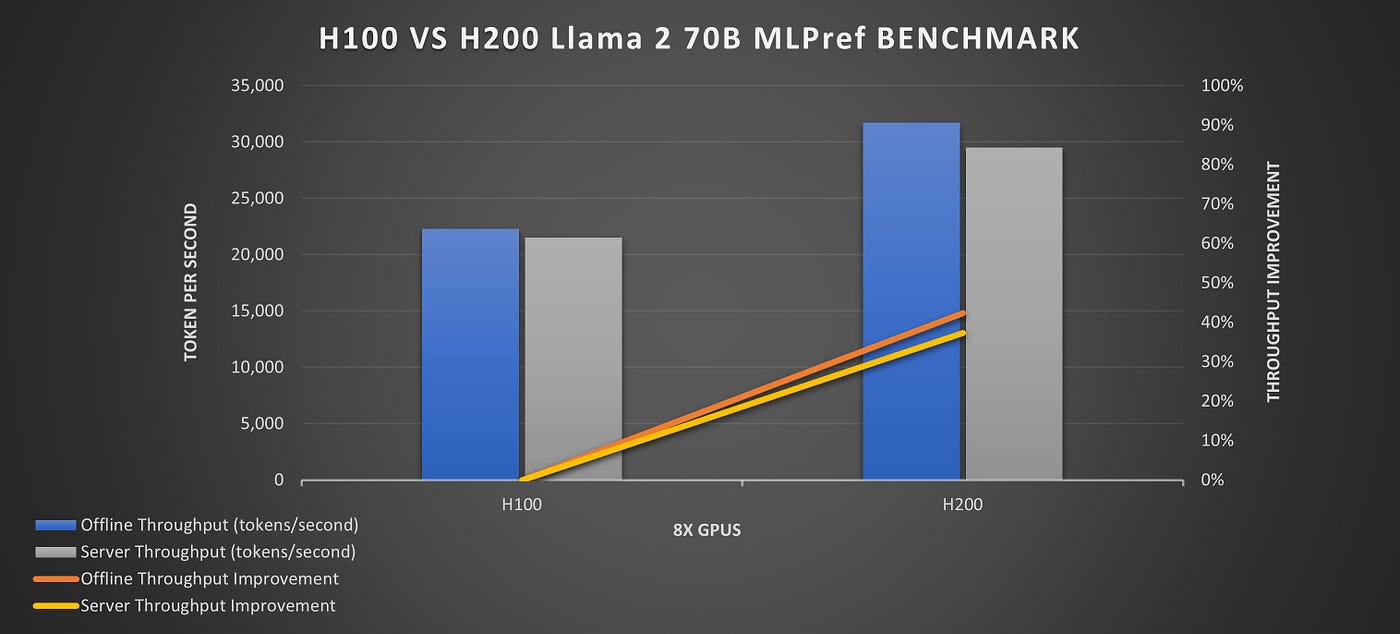
Nhờ những cải tiến này, H200 mang lại hiệu suất suy luận LLM nhanh hơn khoảng 1.6 lần so với H100 đối với các mô hình lớn như Llama 2 70B. Điều này trực tiếp giảm chi phí vận hành và tăng tốc độ phản hồi cho các ứng dụng AI dựa trên LLM.
Định vị H200 trong bối cảnh thị trường và sự xuất hiện của Blackwell
H200 không phải là sự thay thế hoàn toàn cho H100 mà là một bản nâng cấp có mục đích, giúp NVIDIA duy trì lợi thế cạnh tranh trong bối cảnh nhu cầu AI bùng nổ, đồng thời chuẩn bị cho sự ra mắt của thế hệ tiếp theo.
- Bước đệm: H200 được xem là một “bước đệm” chiến lược, giúp giải quyết nhu cầu cấp bách về bộ nhớ cho LLM trong khi NVIDIA hoàn thiện kiến trúc Blackwell hoàn toàn mới.
- Tối ưu hóa chi phí/hiệu năng: Đối với một số workload cụ thể, nơi bộ nhớ là yếu tố giới hạn chính, H200 mang lại sự tăng cường hiệu năng đáng kể mà không cần tái thiết kế toàn bộ kiến trúc như Blackwell.
- Giá cả & Khả năng sẵn có:
- Giá: NVIDIA không công bố giá bán lẻ trực tiếp cho các GPU cấp độ trung tâm dữ liệu. Giá của H200 được xác định qua các đối tác OEM và nhà cung cấp dịch vụ đám mây (CSP). Tuy nhiên, có thể ước tính rằng giá của H200 cao hơn đáng kể so với H100, phản ánh chi phí của bộ nhớ HBM3e đắt đỏ và hiệu năng vượt trội.
- Khả năng sẵn có: Sau khi được công bố vào cuối năm 2023, H200 đã bắt đầu được xuất xưởng cho các khách hàng lớn và nhà cung cấp dịch vụ đám mây từ Quý 2 năm 2024, và hiện tại (giữa năm 2025) đã có sẵn rộng rãi trên các nền tảng đám mây lớn và thông qua các nhà sản xuất hệ thống.
Hướng tới kỷ nguyên Blackwell: Tương lai của AI Compute
Ngay cả khi H200 đang dần phổ biến, NVIDIA đã công bố kiến trúc Blackwell vào tháng 3 năm 2024, đánh dấu thế hệ GPU tiếp theo và là một bước nhảy vọt lớn hơn nhiều so với Hopper.
Các sản phẩm Blackwell đầu tiên như GPU B200 và đặc biệt là GB200 Superchip (kết hợp hai GPU B200 và một CPU Grace) hứa hẹn hiệu năng và khả năng mở rộng chưa từng có, với những cải tiến về:
- AI Superchip: Tích hợp sâu hơn GPU và CPU.
- NVLink thế hệ mới: Tăng cường băng thông liên kết GPU lên mức phi thường.
- Tensor Cores thế hệ 5: Với khả năng tính toán FP4, mang lại hiệu quả năng lượng và hiệu suất cao hơn nữa cho AI.
- Engine giải nén dữ liệu: Giúp tăng tốc tải dữ liệu cho các mô hình lớn.
Vậy nên chọn H100, H200 hay chờ Blackwell?
- H100: Vẫn là một GPU cực kỳ mạnh mẽ và tiết kiệm chi phí hơn nếu workload của bạn không quá “đói” bộ nhớ hoặc bạn đang tìm kiếm các giải pháp đã có sẵn và ổn định trên thị trường.
- H200: Là lựa chọn lý tưởng nếu bạn đang phát triển hoặc vận hành các LLM lớn, các mô hình AI tạo sinh phức tạp, hoặc các tác vụ HPC yêu cầu băng thông bộ nhớ cực cao và dung lượng VRAM lớn để giảm thiểu việc phải “swap” dữ liệu hay chạy trên nhiều GPU. H200 mang lại hiệu suất vượt trội cho các workload này so với H100.
- Blackwell (B200/GB200): Là tương lai của AI. Nếu bạn đang lên kế hoạch cho các dự án dài hạn, yêu cầu hiệu năng cực đỉnh và khả năng mở rộng tối đa cho các mô hình AI thế hệ mới nhất, hoặc xây dựng hạ tầng AI quy mô lớn, việc đầu tư vào Blackwell sẽ mang lại lợi ích lâu dài. Tuy nhiên, chi phí ban đầu sẽ cao hơn và thời gian triển khai có thể kéo dài hơn so với các giải pháp Hopper đã trưởng thành.
Kết luận
H100 đã mở đường, H200 nâng cao giới hạn về bộ nhớ và hiệu suất cho các ứng dụng LLM quan trọng, đồng thời đóng vai trò là cầu nối quan trọng. Với sự xuất hiện của Blackwell, NVIDIA tiếp tục khẳng định vị thế dẫn đầu trong cuộc đua AI, mang đến những giải pháp GPU ngày càng mạnh mẽ và chuyên biệt, đáp ứng nhu cầu điện toán đang bùng nổ trên toàn cầu. Việc lựa chọn GPU phù hợp sẽ phụ thuộc vào nhu cầu cụ thể của từng dự án, ngân sách và chiến lược phát triển dài hạn của tổ chức.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- Đánh giá chi tiết NVIDIA RTX Pro 6000 Blackwell Workstation: GPU máy trạm với 96GB GDDR7
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn