
Để hiểu được tiến bộ mới nhất trong Generative AI (GenAI), bạn hãy tưởng tượng bối cảnh tại một phòng xử án như sau.
Các thẩm phán nghe và quyết định các vụ án dựa trên sự hiểu biết chung của họ về luật pháp. Đôi khi, một vụ án – chẳng hạn như một vụ kiện về hành vi sai trái hoặc tranh chấp lao động – đòi hỏi chuyên môn đặc biệt nên thẩm phán sẽ cử thư ký tòa án đến thư viện luật, tìm kiếm các tiền lệ và các vụ việc cụ thể mà họ có thể viện dẫn.
Giống như một thẩm phán giỏi, các Mô hình ngôn ngữ lớn (LLMs) có thể trả lời nhiều truy vấn khác nhau của con người. Nhưng để đưa ra những câu trả lời đáng tin cậy có trích dẫn nguồn, mô hình cần một trợ lý thực hiện một số nghiên cứu.
Thư ký tòa án của AI là một quá trình được gọi là Retrieval-Augmented Generation, hay viết tắt là RAG.
Câu chuyện về cái tên

Patrick Lewis, tác giả chính của bài báo năm 2020 đặt ra thuật ngữ này, đã xin lỗi về từ viết tắt không mấy hay ho hiện mô tả một nhóm phương pháp đang phát triển trên hàng trăm bài báo và hàng chục dịch vụ thương mại mà ông tin rằng sẽ đại diện cho tương lai của GenAI.
Lewis cho biết trong một cuộc phỏng vấn từ Singapore, nơi ông đang chia sẻ ý tưởng của mình với một hội nghị khu vực của các nhà phát triển cơ sở dữ liệu: “Chúng tôi chắc chắn sẽ suy nghĩ nhiều hơn về cái tên nếu biết công việc của mình sẽ trở nên phổ biến đến vậy”.
Lewis, người hiện đang lãnh đạo nhóm RAG tại công ty khởi nghiệp AI Cohere, cho biết: “Chúng tôi luôn lên kế hoạch để có một cái tên nghe hay hơn, nhưng đến lúc viết bài báo, không ai có ý tưởng nào hay hơn”.
Vậy Retrieval-Augmented Generation là gì?
RAG là một kỹ thuật nhằm nâng cao độ chính xác và độ tin cậy của các mô hình GenAI với các dữ kiện được lấy từ các nguồn bên ngoài.
Nói cách khác, nó lấp đầy khoảng trống trong cách thức hoạt động của LLM. Về cơ bản, các LLM là mạng lưới thần kinh nhân tạo (neural networks), thường được đo bằng số lượng tham số mà chúng chứa. Các tham số của một LLM về cơ bản thể hiện các mẫu chung về cách con người sử dụng các từ để tạo thành câu.
Sự hiểu biết sâu sắc đó, đôi khi được gọi là kiến thức được tham số hóa, làm cho LLM trở nên hữu ích trong việc đáp ứng các prompt chung ở tốc độ ánh sáng. Tuy nhiên, nó không phục vụ những người dùng muốn tìm hiểu sâu hơn về một chủ đề hiện tại hoặc cụ thể hơn.
Kết hợp tài nguyên bên trong, bên ngoài
Lewis và các đồng nghiệp đã phát triển Retrieval-Augmented Generation để liên kết các dịch vụ GenAI với các tài nguyên bên ngoài, đặc biệt là những dịch vụ có nhiều chi tiết kỹ thuật mới nhất.
Bài báo, với các đồng tác giả từ Facebook AI Research trước đây (nay là Meta AI), Đại học London và Đại học New York, đã gọi RAG là “một công thức tinh chỉnh cho mục đích chung” vì nó có thể được hầu hết mọi LLM sử dụng để kết nối với bất kỳ tài nguyên bên ngoài nào.
Xây dựng niềm tin của người dùng
RAG cung cấp cho mô hình các nguồn mà chúng có thể trích dẫn, chẳng hạn như chú thích cuối trang trong tài liệu nghiên cứu, để người dùng có thể kiểm tra mọi xác nhận quyền sở hữu. Điều đó tạo dựng niềm tin.
Hơn nữa, kỹ thuật này có thể giúp các mô hình làm sáng tỏ sự mơ hồ trong truy vấn của người dùng. Nó cũng làm giảm khả năng mô hình đoán sai, một hiện tượng đôi khi được gọi là ảo giác.
Một ưu điểm lớn khác của RAG là nó tương đối dễ dàng. Một bài blog của Lewis và ba đồng tác giả cho biết các nhà phát triển có thể triển khai quy trình này chỉ với năm dòng code.
Nó làm cho phương pháp này nhanh hơn và ít tốn kém hơn so với việc đào tạo lại một mô hình với các bộ dữ liệu bổ sung. Và nó cho phép người dùng trao đổi nhanh các nguồn mới một cách nhanh chóng.
Mọi người đang sử dụng RAG như thế nào?
Với RAG, về cơ bản người dùng có thể trò chuyện với các kho dữ liệu, mở ra những loại trải nghiệm mới. Điều này có nghĩa là ứng dụng cho RAG có thể gấp nhiều lần số lượng bộ dữ liệu có sẵn.
Ví dụ, một mô hình GenAI được bổ sung với chỉ số y tế có thể là trợ lý đắc lực cho bác sĩ hoặc y tá. Các nhà phân tích tài chính sẽ được hưởng lợi từ một trợ lý liên kết với dữ liệu thị trường.
Trên thực tế, hầu hết mọi doanh nghiệp đều có thể biến các hướng dẫn, video hoặc log về kỹ thuật hoặc chính sách của mình thành các tài nguyên được gọi là cơ sở kiến thức có thể nâng cao LLM. Những nguồn này có thể hỗ trợ các trường hợp sử dụng như hỗ trợ khách hàng hoặc lĩnh vực, đào tạo nhân viên và năng suất của nhà phát triển.
Tiềm năng rộng lớn là lý do tại sao các công ty bao gồm AWS, IBM, Glean, Google, Microsoft, NVIDIA, Oracle và Pinecone đang áp dụng RAG.
Bắt đầu với RAG
Để giúp người dùng bắt đầu, NVIDIA đã phát triển một kiến trúc tham chiếu dành cho RAG. Nó bao gồm một chatbot mẫu và các thành phần mà người dùng cần để tạo ứng dụng của riêng họ bằng phương pháp mới này.
Quy trình làm việc sử dụng NVIDIA NeMo, một framework để phát triển và tùy chỉnh các mô hình GenAI, cũng như phần mềm như NVIDIA Triton Inference Server và NVIDIA TensorRT-LLM để chạy các mô hình GenAI trong sản xuất.
Tất cả các thành phần phần mềm đều là một phần của NVIDIA AI Enterprise, một nền tảng phần mềm giúp đẩy nhanh quá trình phát triển và triển khai AI sẵn sàng cho sản xuất với khả năng bảo mật , sự hỗ trợ và tính ổn định mà doanh nghiệp cần.
Để có được hiệu suất tốt nhất cho quy trình làm việc RAG đòi hỏi lượng bộ nhớ và tính toán lớn để di chuyển và xử lý dữ liệu. Siêu chip NVIDIA GH200 Grace Hopper với 288GB bộ nhớ HBM3e nhanh và 8 petaflops tính toán là lý tưởng – nó có thể tăng tốc gấp 150 lần so với việc sử dụng một CPU.
Khi các công ty đã quen với RAG, họ có thể kết hợp nhiều loại LLM có sẵn hoặc tùy chỉnh với nền tảng kiến thức nội bộ hoặc bên ngoài để tạo ra nhiều trợ lý giúp đỡ nhân viên và khách hàng của họ.
RAG không yêu cầu một trung tâm dữ liệu. Các LLM đang ra mắt trên Windows PC, nhờ vào phần mềm NVIDIA cho phép tất cả các loại ứng dụng mà người dùng có thể truy cập ngay cả trên laptop của họ.
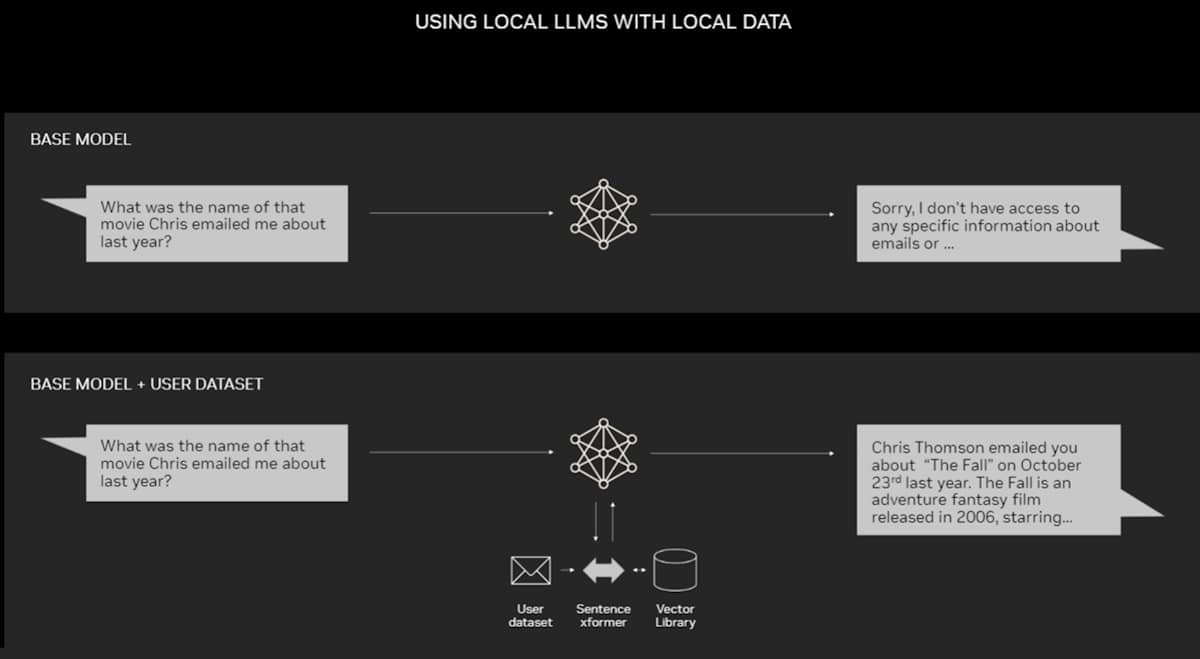 Một ví dụ về ứng dụng cho RAG trên PC
Một ví dụ về ứng dụng cho RAG trên PC
Các PC được trang bị GPU NVIDIA RTX hiện có thể chạy cục bộ một số mô hình AI. Bằng cách sử dụng RAG trên PC, người dùng có thể liên kết tới nguồn kiến thức riêng tư – cho dù đó là email, ghi chú hay bài viết – để cải thiện phản hồi. Sau đó, người dùng có thể cảm thấy tự tin rằng nguồn dữ liệu, lời nhắc (prompt) và phản hồi của họ đều được giữ kín và an toàn.
Một blog gần đây cung cấp ví dụ về RAG được tăng tốc bởi TensorRT-LLM dành cho Windows để nhanh chóng nhận được kết quả tốt hơn.
Lịch sử của RAG
Nguồn gốc của kỹ thuật này ít nhất đã có từ đầu những năm 1970. Đó là khi các nhà nghiên cứu về truy xuất thông tin tạo nguyên mẫu cho cái mà họ gọi là hệ thống trả lời câu hỏi, ứng dụng sử dụng xử lý ngôn ngữ tự nhiên (NLP) để truy cập văn bản, ban đầu là trong các chủ đề hẹp chẳng hạn như bóng chày.
Các khái niệm đằng sau kiểu khai thác văn bản này vẫn khá ổn định trong nhiều năm. Nhưng các công cụ Học máy (ML) điều khiển chúng đã phát triển đáng kể, làm tăng tính hữu dụng và mức độ phổ biến của chúng.
Vào giữa những năm 1990, dịch vụ Ask Jeeves, nay là Ask.com, đã phổ biến tính năng trả lời câu hỏi với linh vật là một người phục vụ ăn mặc lịch sự. Watson của IBM đã trở thành một celebrity trên TV vào năm 2011 khi đánh bại hai nhà vô địch con người trong gameshow Jeopardy!.
Ngày nay, các LLM đang đưa hệ thống trả lời câu hỏi lên một tầm cao mới.
Thông tin chi tiết từ phòng thí nghiệm ở London
Bài báo quan trọng năm 2020 được đưa ra khi Lewis đang theo đuổi bằng tiến sĩ về NLP tại trường University College London và làm việc cho Meta tại một phòng thí nghiệm AI mới ở London. Nhóm đang tìm cách đưa thêm kiến thức vào các tham số của LLM và sử dụng điểm chuẩn mà nó đã phát triển để đo lường tiến trình của nó.
Xây dựng dựa trên các phương pháp trước đó và lấy cảm hứng từ một bài báo của các nhà nghiên cứu của Google, nhóm “đã có tầm nhìn hấp dẫn về một hệ thống được đào tạo có chỉ mục truy xuất ở giữa nó, để nó có thể học và tạo ra bất kỳ đầu ra văn bản nào bạn muốn,” Lewis nhớ lại.
 Hệ thống trả lời câu hỏi IBM Watson đã trở nên nổi tiếng khi giành chiến thắng lớn trên chương trình trò chơi truyền hình Jeopardy!
Hệ thống trả lời câu hỏi IBM Watson đã trở nên nổi tiếng khi giành chiến thắng lớn trên chương trình trò chơi truyền hình Jeopardy!
Khi Lewis bắt tay vào công việc trong tiến trình của một hệ thống truy xuất đầy hứa hẹn từ một nhóm Meta khác, kết quả đầu tiên ấn tượng đến không ngờ.
“Tôi đã cho người giám sát của mình xem và anh ấy nói, ‘Ồ, hãy giành chiến thắng’. Điều này không xảy ra thường xuyên, bởi vì những quy trình công việc này có thể khó thiết lập chính xác ngay lần đầu tiên,” ông nói.
Lewis cũng ghi nhận những đóng góp to lớn của các thành viên nhóm Ethan Perez và Douwe Kiela, lúc đó thuộc Đại học New York và Facebook AI Research.
Khi hoàn thành, tác phẩm chạy trên một cụm các GPU NVIDIA đã cho thấy cách làm cho các mô hình GenAI trở nên có thẩm quyền và đáng tin cậy hơn. Kể từ đó, nó đã được trích dẫn bởi hàng trăm bài báo nhằm khuếch đại và mở rộng các khái niệm trong lĩnh vực vẫn tiếp tục là một lĩnh vực nghiên cứu tích cực.
Cách thức hoạt động của RAG
Ở cấp độ cao, đây là cách bản tóm tắt kỹ thuật của NVIDIA mô tả quy trình RAG.
Khi người dùng đặt câu hỏi cho LLM, mô hình AI sẽ gửi truy vấn đến một mô hình khác để chuyển đổi nó thành định dạng số để các máy có thể đọc được. Phiên bản số của truy vấn đôi khi được gọi là nhúng hoặc vectơ.
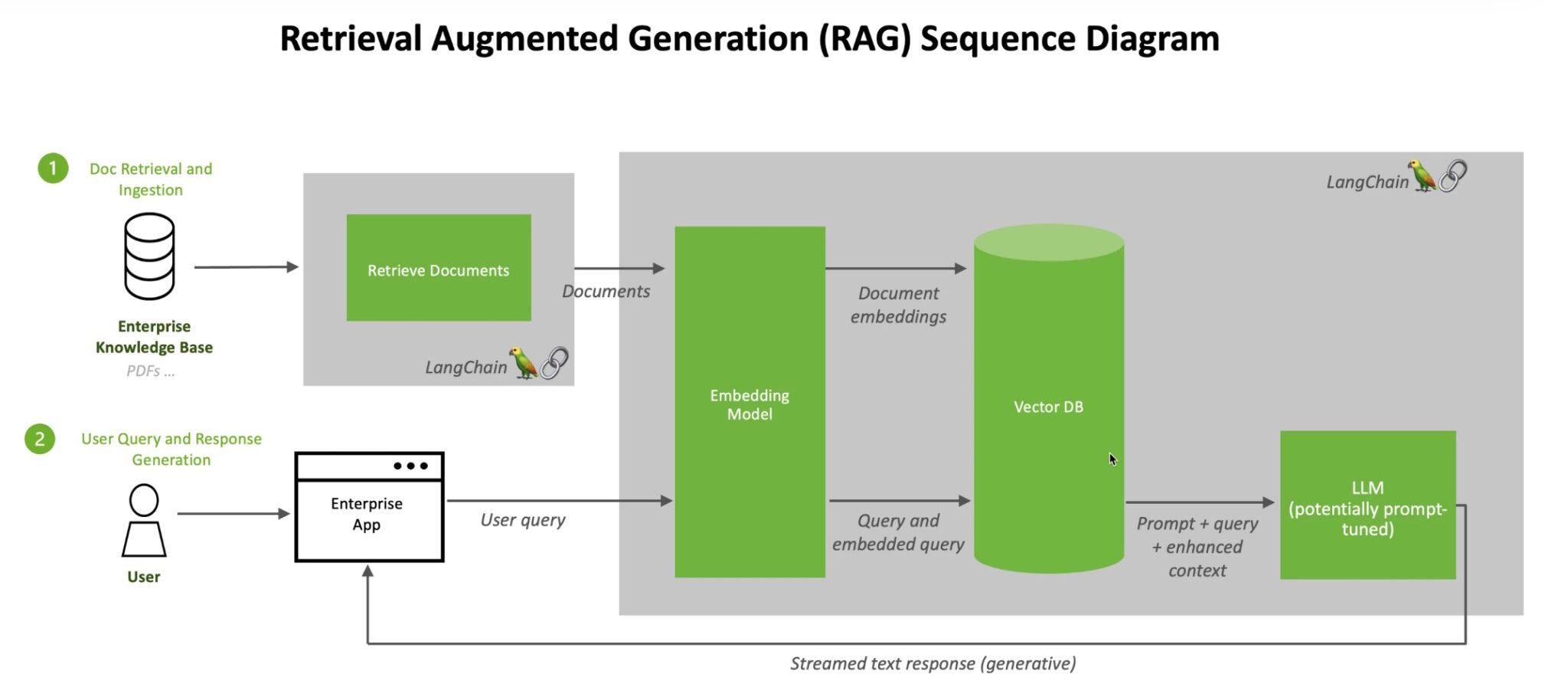 RAG kết hợp LLM với các mô hình nhúng và cơ sở dữ liệu vectơ
RAG kết hợp LLM với các mô hình nhúng và cơ sở dữ liệu vectơ
Sau đó, mô hình nhúng sẽ so sánh các giá trị số này với các vectơ trong chỉ mục mà máy có thể đọc được của cơ sở kiến thức sẵn có. Khi tìm thấy một hoặc nhiều kết quả trùng khớp, nó sẽ truy xuất dữ liệu liên quan, chuyển đổi nó thành các từ mà con người có thể đọc được và chuyển lại cho LLM.
Cuối cùng, LLM kết hợp các từ được truy xuất và phản hồi của chính nó đối với truy vấn thành câu trả lời cuối cùng mà nó đưa ra cho người dùng, có khả năng trích dẫn các nguồn mà mô hình nhúng tìm thấy.
Giữ các nguồn hiện tại
Ở background, mô hình nhúng liên tục tạo và cập nhật các chỉ mục mà máy có thể đọc được, đôi khi được gọi là cơ sở dữ liệu vectơ, cho các cơ sở kiến thức mới và cập nhật khi chúng có sẵn.
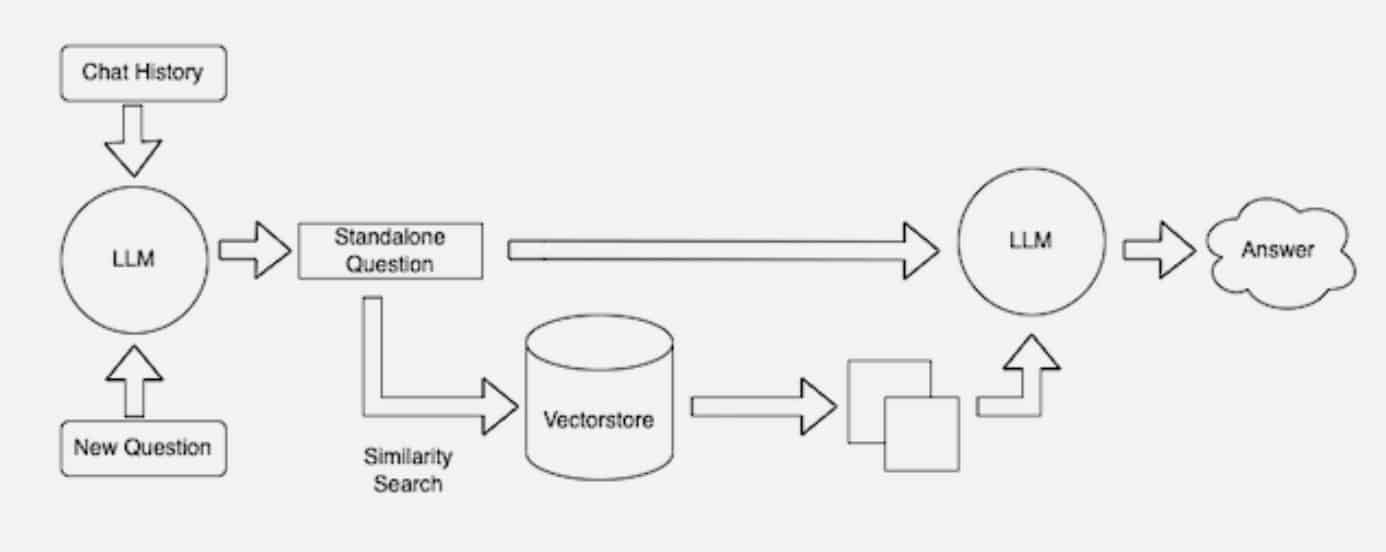
Nhiều nhà phát triển nhận thấy LangChain, một thư viện nguồn mở, có thể đặc biệt hữu ích trong việc kết nối các LLM, các mô hình nhúng và cơ sở kiến thức lại với nhau. NVIDIA sử dụng LangChain trong kiến trúc tham chiếu của mình đối với RAG.
Cộng đồng LangChain cung cấp mô tả riêng về quy trình RAG.
Nhìn về phía trước, tương lai của GenAI nằm ở việc kết hợp một cách sáng tạo tất cả các loại LLM và cơ sở kiến thức lại với nhau để tạo ra các loại trợ lý mới mang lại kết quả đáng tin cậy mà người dùng có thể xác minh.
Bắt tay sử dụng RAG với chatbot AI trong NVIDIA LaunchPad lab này.
Bài viết liên quan
- Từ “Sáng tạo” Đến “Hành động”: Khám phá sự khác biệt giữa Generative AI và Agentic AI
- Mở rộng quy mô cho hạ tầng GenAI on-premise
- Sovereign AI là gì?
- LLM: Lịch sử và tương lai của các mô hình ngôn ngữ lớn
- LM Studio – Chạy Generative AI trên máy tính của riêng bạn
- Hướng đến tương lai: Generative AI dành cho các giám đốc điều hành