
Trong thập kỷ gần đây, lĩnh vực trí tuệ nhân tạo đã đạt được những đột phá ấn tượng, và một trong những thành tựu quan trọng nhất trong lĩnh vực này là Large Language Models (LLMs) – những mô hình ngôn ngữ lớn. Chúng là những “trí tuệ nhân tạo về ngôn ngữ” mạnh mẽ, có khả năng hiểu và tạo ra ngôn ngữ tự nhiên như con người.
Bạn có thể đã nghe đến thuật ngữ “Large Language Model” (LLM), nhưng liệu bạn đã thực sự hiểu rõ về chúng là gì và tại sao chúng đang gây sốt trong lĩnh vực Trí Tuệ Nhân Tạo? Đặc biệt, bạn đã biết rằng chúng có thể tạo ra văn bản tương tự như con người và thực hiện mọi tác vụ xử lý ngôn ngữ tự nhiên không? Hãy cùng tìm hiểu sâu hơn về LLMs.


Large Language Models (LLMs) – Khái Quát và Ứng Dụng
Large Language Models (LLMs), hay còn gọi là mô hình ngôn ngữ lớn, đang là xu hướng nổi bật trong lĩnh vực Trí Tuệ Nhân Tạo (AI). Được hình thành bằng cách áp dụng học sâu trên một lượng dữ liệu văn bản khổng lồ, LLMs có khả năng tạo văn bản và thực hiện các tác vụ xử lý ngôn ngữ tự nhiên tương tự con người.

Được Hình Thành Bằng Học Sâu
Large Language Model không chỉ là một thuật ngữ mới, mà còn là một cột mốc quan trọng trong sự phát triển của trí tuệ nhân tạo. Chúng là mô hình ngôn ngữ được đào tạo thông qua việc áp dụng các kỹ thuật học sâu trên một kho dữ liệu văn bản khổng lồ. Khiến chúng đặc biệt đáng chú ý là khả năng tạo ra văn bản có độ tương tự con người.
Phức Tạp Khác Nhau Nhưng không phải tất cả LLMs đều giống nhau. Chúng có độ phức tạp khác nhau, từ những mô hình đơn giản như mô hình n-gram cho đến các mô hình mạng mô phỏng cấu trúc thần kinh của con người. Tuy nhiên, khi nói về “Large Language Model”, chúng ta thường đề cập đến những mô hình sử dụng kỹ thuật học sâu và có hàng tỷ đến hàng nghìn tỷ tham số. Những mô hình này có khả năng khám phá những quy luật phức tạp trong ngôn ngữ và tạo ra văn bản đầy chất con người.
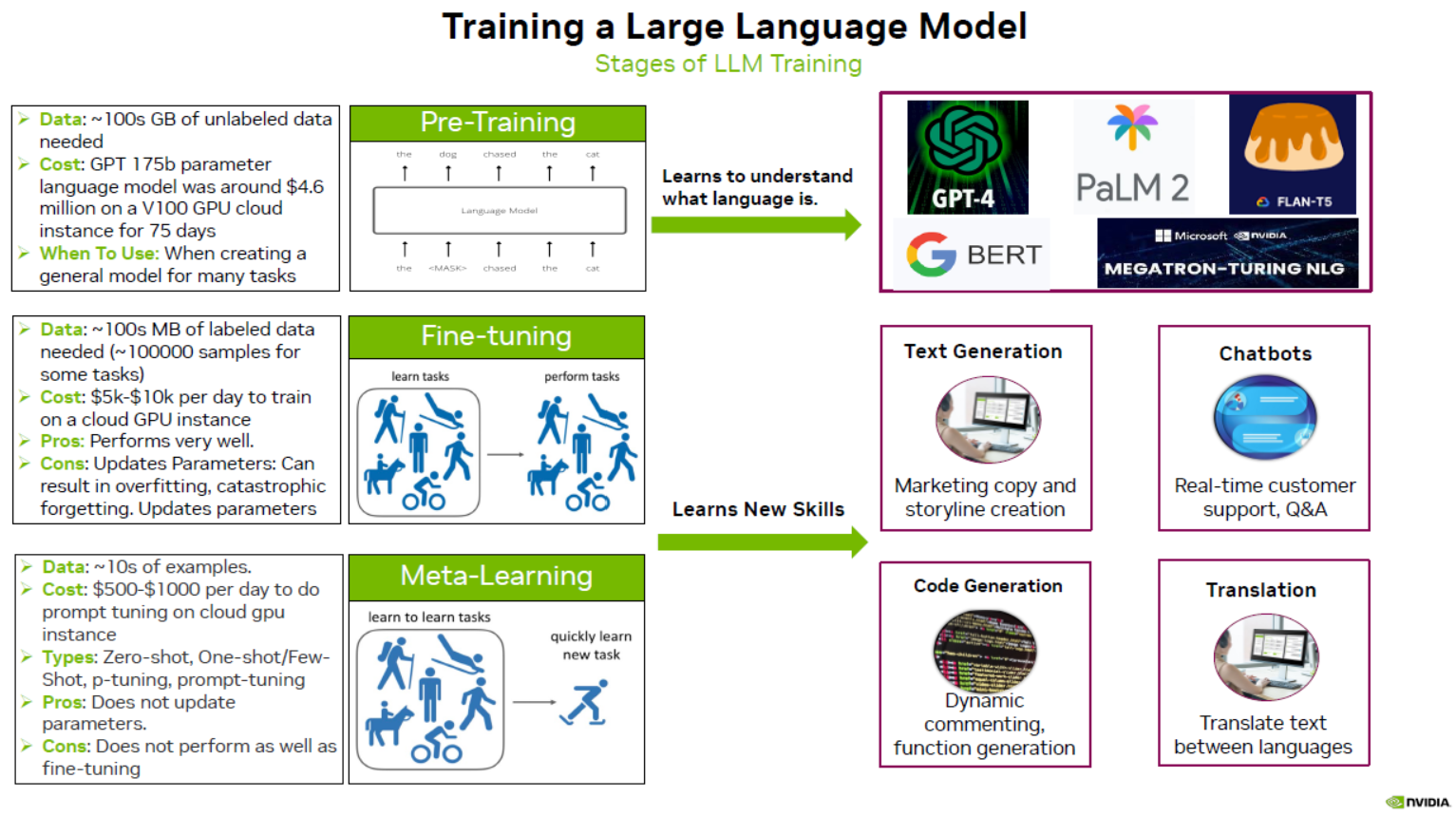
Bí Mật Trong Kiến Trúc
Nhìn vào kiến trúc của LLMs, bạn sẽ bắt gặp nhiều lớp mạng thần kinh như recurrent layers, feedforward layers, embedding layers, attention layers… Tất cả các lớp này hoạt động cùng nhau để xử lý văn bản đầu vào và dự đoán kết quả đầu ra.
- Embedding Layer: Biến đổi từng từ trong văn bản thành vectơ nhiều chiều. Điều này giúp mô hình hiểu được ngữ nghĩa và cấu trúc ngôn ngữ.
- Feedforward Layers: Kết nối đầy đủ và áp dụng biến đổi phi tuyến tính cho các vectơ embedding. Nhờ đó, mô hình có khả năng học thông tin trừu tượng từ văn bản.
- Recurrent Layers: Duyệt qua thông tin từng từ theo thứ tự. Điều này giúp mô hình nắm bắt sự phụ thuộc giữa các từ.
- Attention Layers: Tập trung vào những phần quan trọng của văn bản. Điều này giúp mô hình tạo ra dự đoán chính xác hơn.
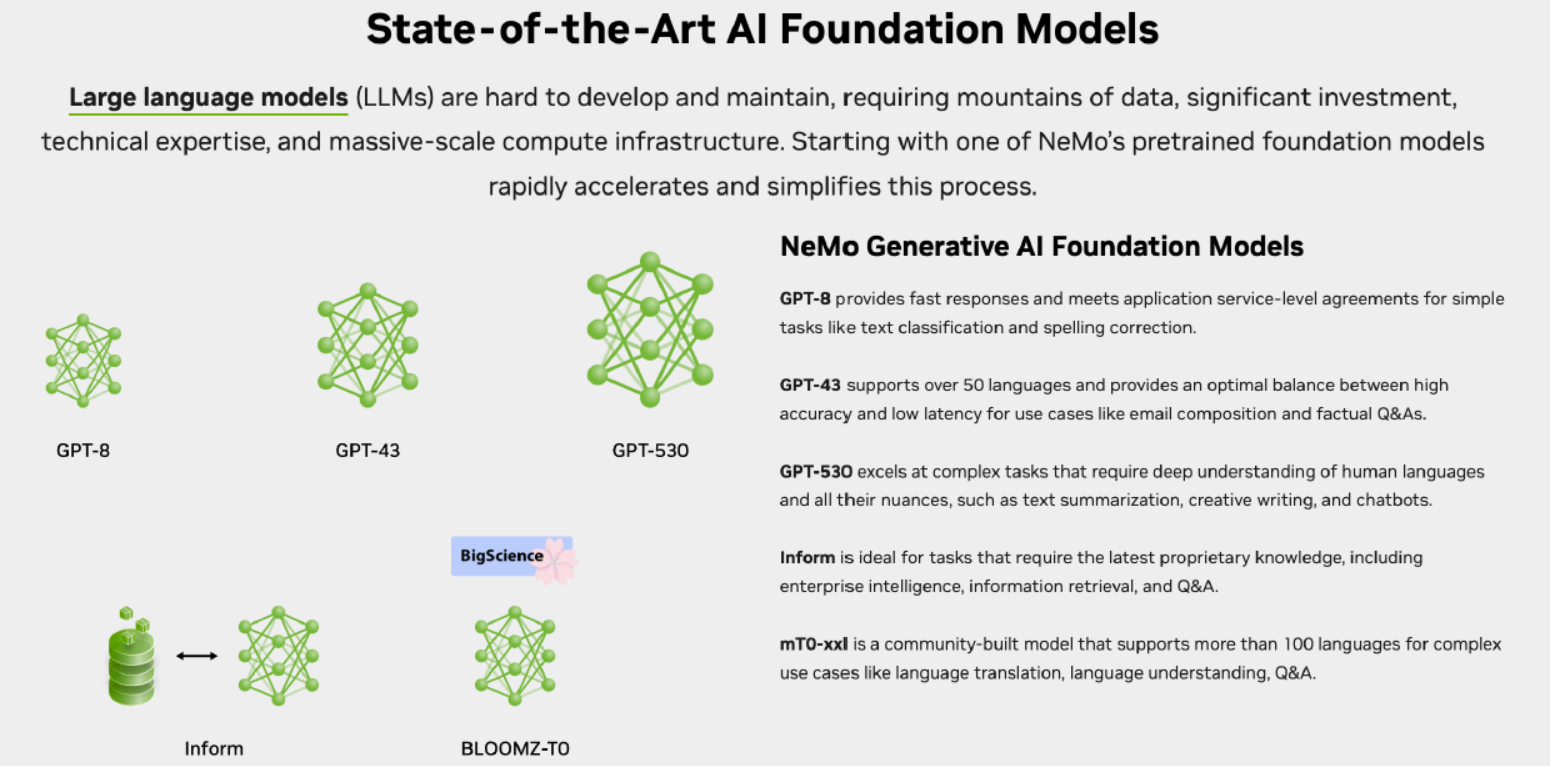
Sức Mạnh Đến Từ Dữ Liệu
LLMs học từ khối lượng dữ liệu lớn. Thực tế, chính kích thước của tập dữ liệu quyết định sức mạnh của LLMs. Ngày nay, chúng được xây dựng dựa trên bộ dữ liệu chứa hàng tỷ dòng văn bản xuất bản trên internet trong thời gian dài.
Sự Hiểu Biết Là Sức mạnh
LLMs đòi hỏi thời gian dài để học từ dữ liệu. Điều này giúp chúng nắm bắt quy luật và cấu trúc ngôn ngữ. Ví dụ, GPT-3, mô hình sử dụng trong dịch vụ ChatGPT, đã học từ hàng tỷ dữ liệu từ internet. Nhờ đó, nó có khả năng hiểu và phản hồi logic và mạch lạc.
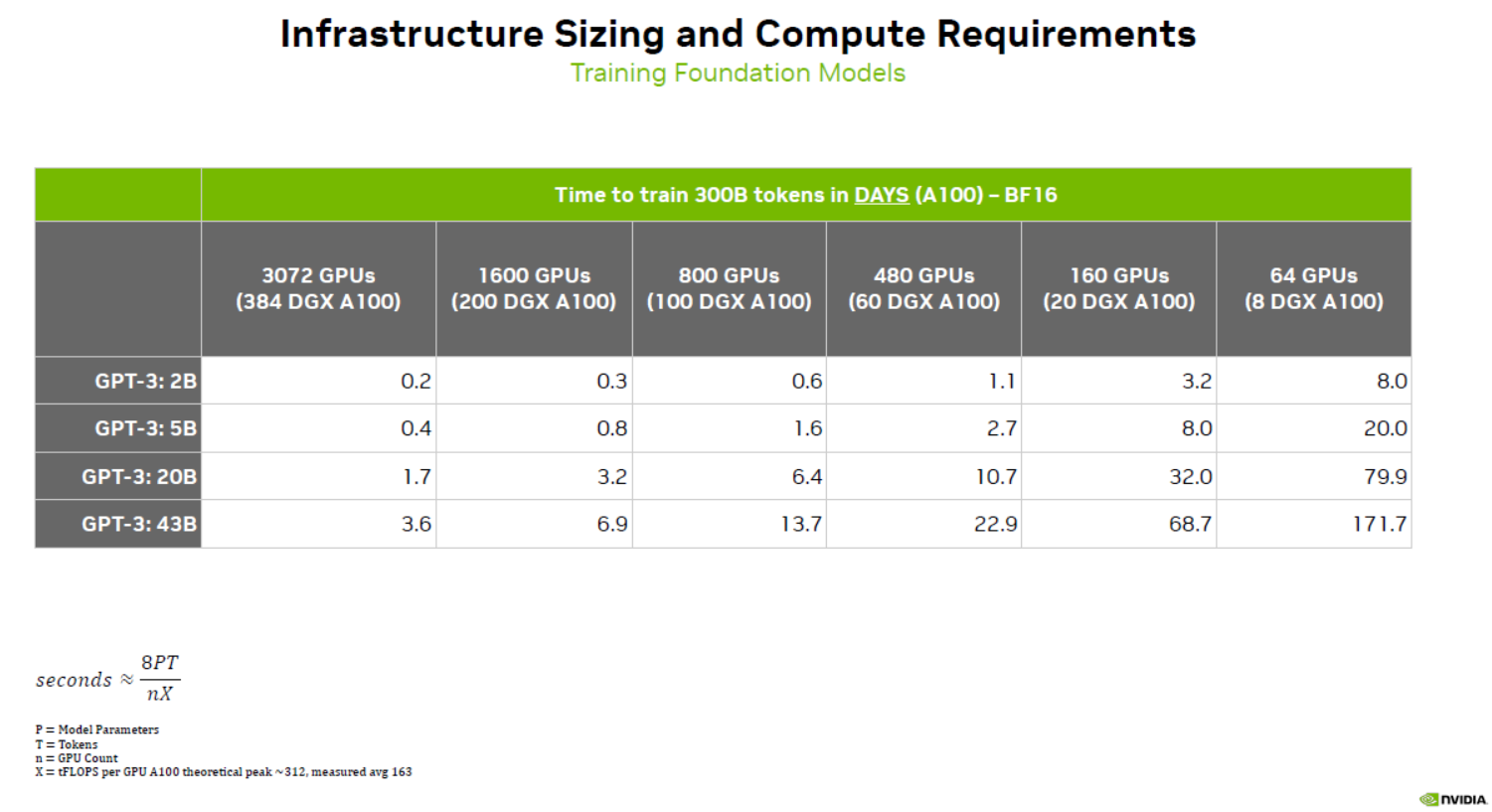
Chinh Phục Đa Dạng Ngôn Ngữ Và Chủ Đề
Nhờ sàng lọc dữ liệu lớn, GPT-3 có thể hiểu nhiều ngôn ngữ và kiến thức về nhiều chủ đề. Điều này giải thích tại sao nó có thể tạo ra văn bản theo nhiều phong cách khác nhau. Dù bạn có thể ngạc nhiên khi thấy mô hình ngôn ngữ lớn thực hiện dịch, tóm tắt và trả lời câu hỏi, điều này không phải là điều ngạc nhiên nếu bạn biết rằng nó dựa vào “ngữ pháp” đã được ghi trong dữ liệu hoặc được tạo ra thông qua kỹ thuật mồi.
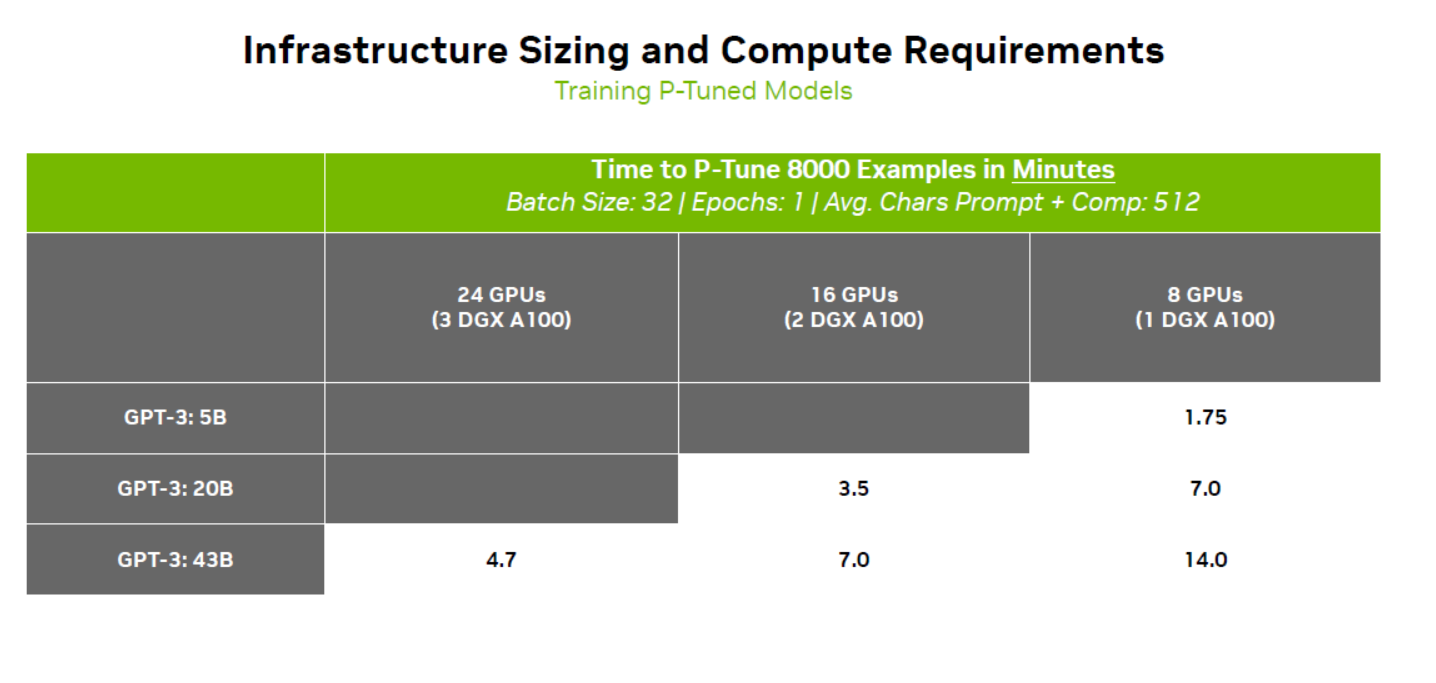
Dưới đây là một số ví dụ về LLMs thực tế:
- GPT-3 (Generative Pre-training Transformer 3): Với 175 tỷ tham số, đây là một trong những mô hình lớn nhất của OpenAI, có thể thực hiện nhiều tác vụ như tạo văn bản, dịch và tóm tắt.
- BERT (Bidirectional Encoder Representations from Transformers): Được Google phát triển, BERT là mô hình phổ biến khác với khả năng hiểu ngữ cảnh và tạo ra câu trả lời có ý nghĩa.
- XLNet: Được phát triển bởi Carnegie Mellon và Google, XLNet sử dụng phương pháp “permutation language modeling” để đạt hiệu suất cao trong nhiều tác vụ.
- T5 (Text-to-Text Transfer Transformer): Google tạo ra T5, có thể thực hiện nhiều tác vụ như chuyển đổi văn bản và tạo bản tóm tắt.
- RoBERTa (Robustly Optimized BERT Pretraining Approach): Facebook AI Research phát triển RoBERTa như một phiên bản BERT cải tiến, hoạt động hiệu quả hơn trong nhiều tác vụ ngôn ngữ.
Như bạn có thể thấy, Large Language Models không chỉ là một khái niệm. Chúng đang thay đổi cách chúng ta tương tác với ngôn ngữ và thông tin. Và để hỗ trợ cho các doanh nghiệp, người dùng dễ dàng hơn trong việc vận hành và ứng dụng Large Language Models, NVIDIA đã ra mắt một framework chuyên dụng là NEMO để tối ưu hóa cho Large Language Models nói riêng và conversational AI nói chung. Hãy cùng tìm hiểu sâu hơn về NVIDIA NeMo.
Giới Thiệu về NVIDIA NeMo
NVIDIA NeMo (Neural Modules) là một framework (khung công cụ) mã nguồn mở phát triển bởi NVIDIA dành cho việc xây dựng và triển khai các mô hình trí tuệ nhân tạo liên quan đến ngôn ngữ tự nhiên (NLP) và âm thanh. NeMo được thiết kế để giúp các nhà nghiên cứu và nhà phát triển xây dựng các mô hình phức tạp một cách dễ dàng và hiệu quả.

NeMo cung cấp các khối xây dựng (modules) đã được tối ưu hóa và chuẩn hóa để xây dựng các mô hình NLP và âm thanh phức tạp. Điều này giúp giảm thiểu thời gian và công sức cần thiết để triển khai và thử nghiệm các mô hình trí tuệ nhân tạo trong các dự án thực tế.
Khung NeMo hỗ trợ nhiều nhiệm vụ trong lĩnh vực NLP và âm thanh, bao gồm nhưng không giới hạn: xử lý ngôn ngữ tự nhiên, tạo văn bản, dịch thuật, phân tích cảm xúc, nhận dạng giọng nói, và nhiều ứng dụng khác liên quan đến xử lý ngôn ngữ và âm thanh.
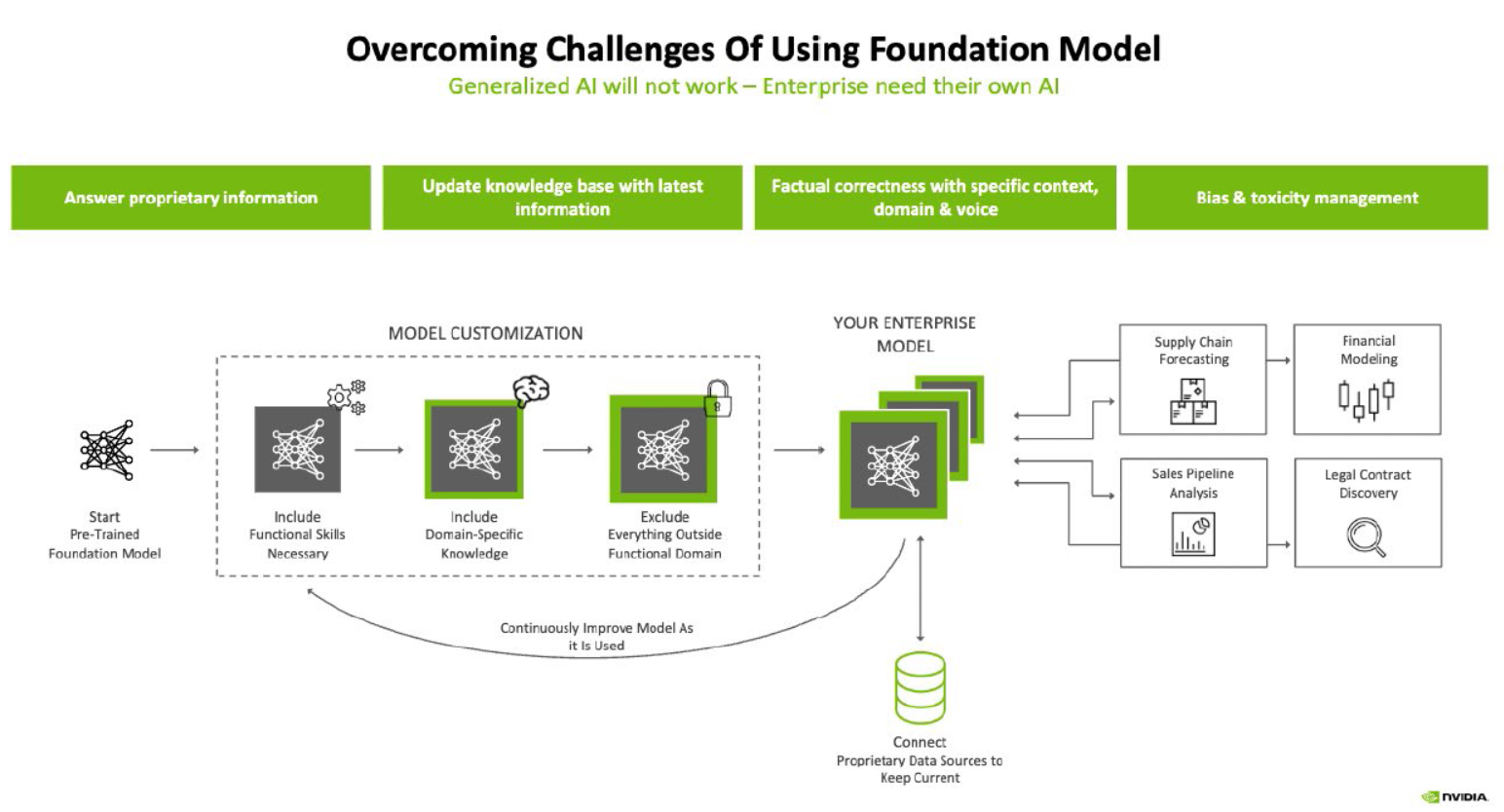
Mục tiêu của NeMo là giúp cộng đồng nghiên cứu và phát triển xây dựng các mô hình trí tuệ nhân tạo tốt hơn, nhanh hơn và dễ dàng hơn bằng cách cung cấp các khối xây dựng chuẩn hóa và các công cụ hỗ trợ liên quan đến xử lý ngôn ngữ tự nhiên và âm thanh.
Kiến Trúc Của NVIDIA NeMo
NVIDIA NeMo (Neural Modules) là một kiến trúc mô-đun hóa dựa trên PyTorch, được phát triển bởi NVIDIA Research. NeMo tập trung vào xử lý ngôn ngữ tự nhiên và âm thanh, giúp tạo ra những mô hình AI mạnh mẽ và linh hoạt. Kiến trúc của NeMo được xây dựng dựa trên các mô-đun nhỏ gọi là “neural modules”, mỗi mô-đun đóng vai trò là một phần của quy trình xử lý.
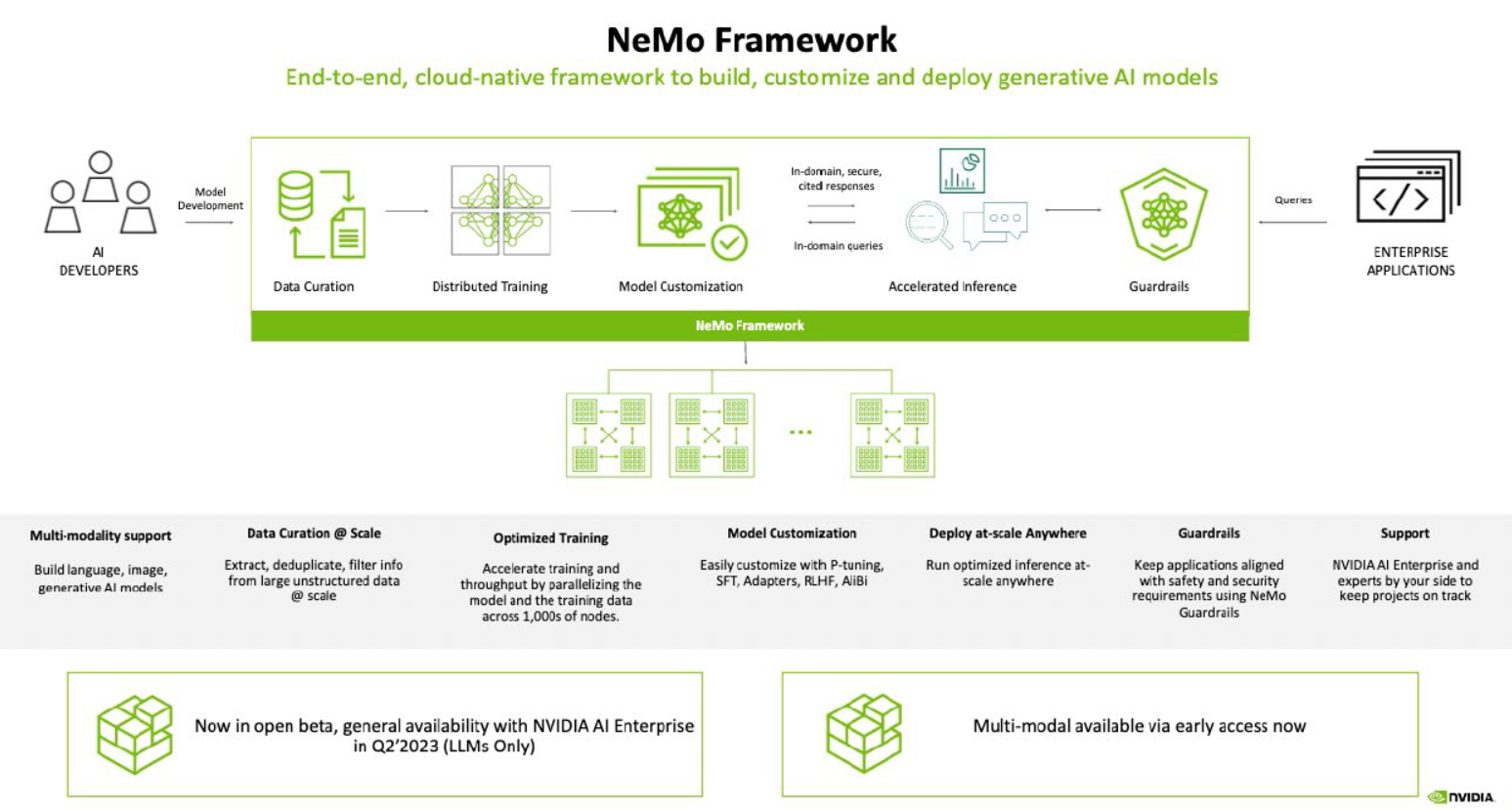
NeMo chia nhỏ các nhiệm vụ xử lý thành các mô-đun riêng biệt, từ việc xây dựng biểu đồ ngữ cảnh cho đến tạo ra âm thanh tự nhiên. Mỗi mô-đun hoạt động cùng nhau để tạo ra một quy trình hoàn chỉnh, giúp giảm thiểu thời gian phát triển và tối ưu hóa hiệu suất.
Tận Dụng Lợi Ích Tối Ưu từ NVIDIA NeMo Cho Large Language Models (LLMs)
Trong thế giới ngày càng phụ thuộc vào trí tuệ nhân tạo (AI), việc phát triển Large Language Models (LLMs) đã mang lại nhiều tiềm năng thú vị cho việc xử lý ngôn ngữ tự nhiên và tạo ra nội dung thông minh. NVIDIA NeMo (Neural Modules) đã nổi lên như một công cụ mạnh mẽ hỗ trợ việc xây dựng và triển khai LLMs, mang lại nhiều lợi ích to lớn cho cộng đồng nghiên cứu và phát triển.
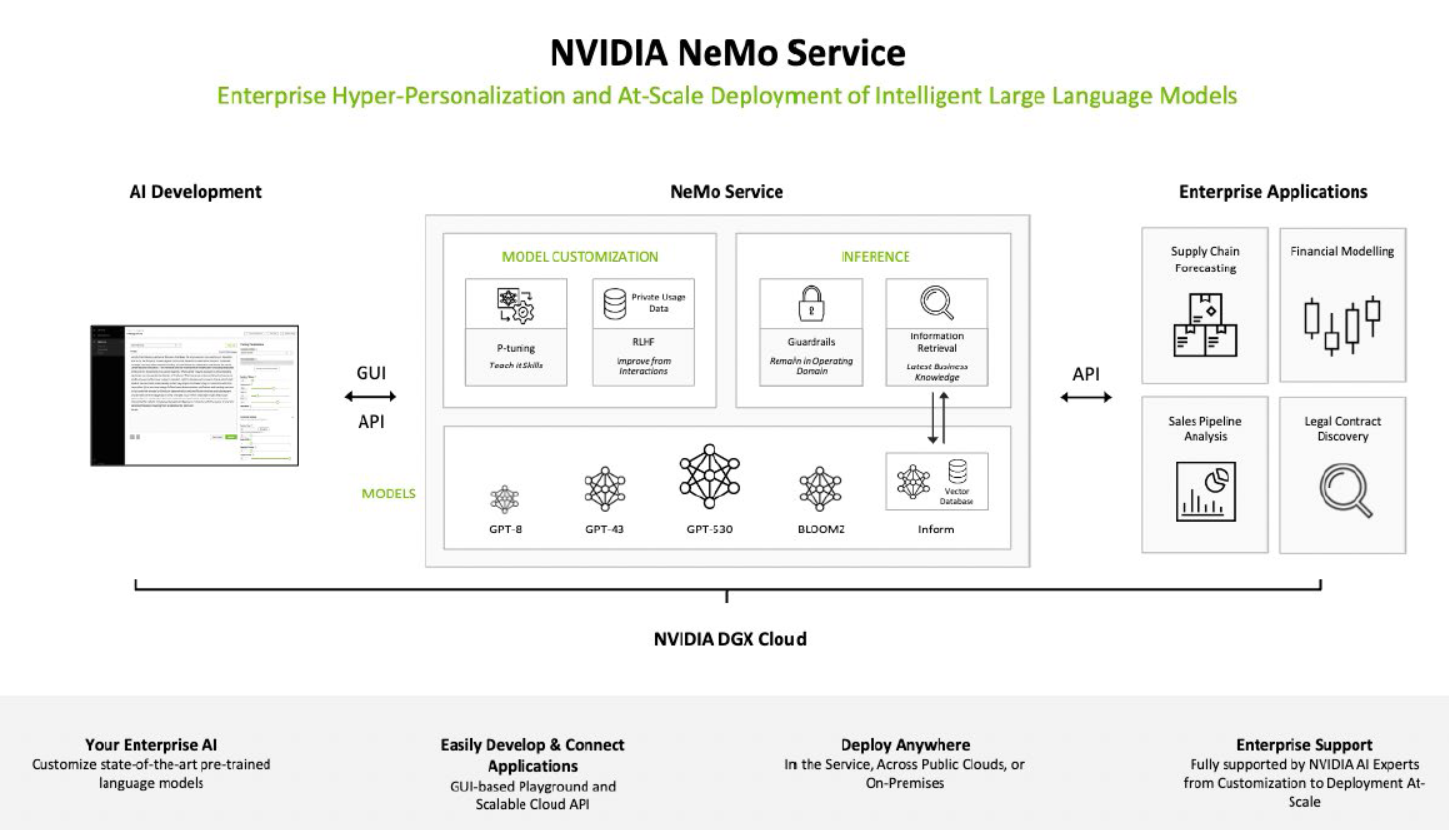
1. Tối Ưu Hóa Quá Trình Xây Dựng: NeMo cung cấp một loạt các khối xây dựng chuẩn hóa, từ mô hình transformer cho đến các phương thức trích xuất đặc trưng, giúp đơn giản hóa việc xây dựng các thành phần quan trọng trong LLMs. Điều này giúp giảm bớt thời gian và công sức cần thiết để triển khai các mô hình phức tạp.
2. Tối Ưu Hóa Hiệu Năng: NeMo đã được tối ưu hóa để tận dụng tối đa khả năng tính toán của GPU, giúp tăng cường hiệu suất và tốc độ xử lý trong quá trình huấn luyện và triển khai LLMs. Điều này đặc biệt quan trọng đối với LLMs có kích thước lớn và cần nhiều nguồn tài nguyên tính toán.
3. Đa Dạng Hóa Các Nhiệm Vụ: NeMo không chỉ hỗ trợ những nhiệm vụ cơ bản như xử lý ngôn ngữ tự nhiên và âm thanh, mà còn cung cấp các khối xây dựng cho nhiều nhiệm vụ phức tạp khác như dịch thuật, phân tích cảm xúc, và tạo văn bản. Điều này giúp LLMs có khả năng đa dạng hóa ứng dụng và mở rộng khả năng sáng tạo.
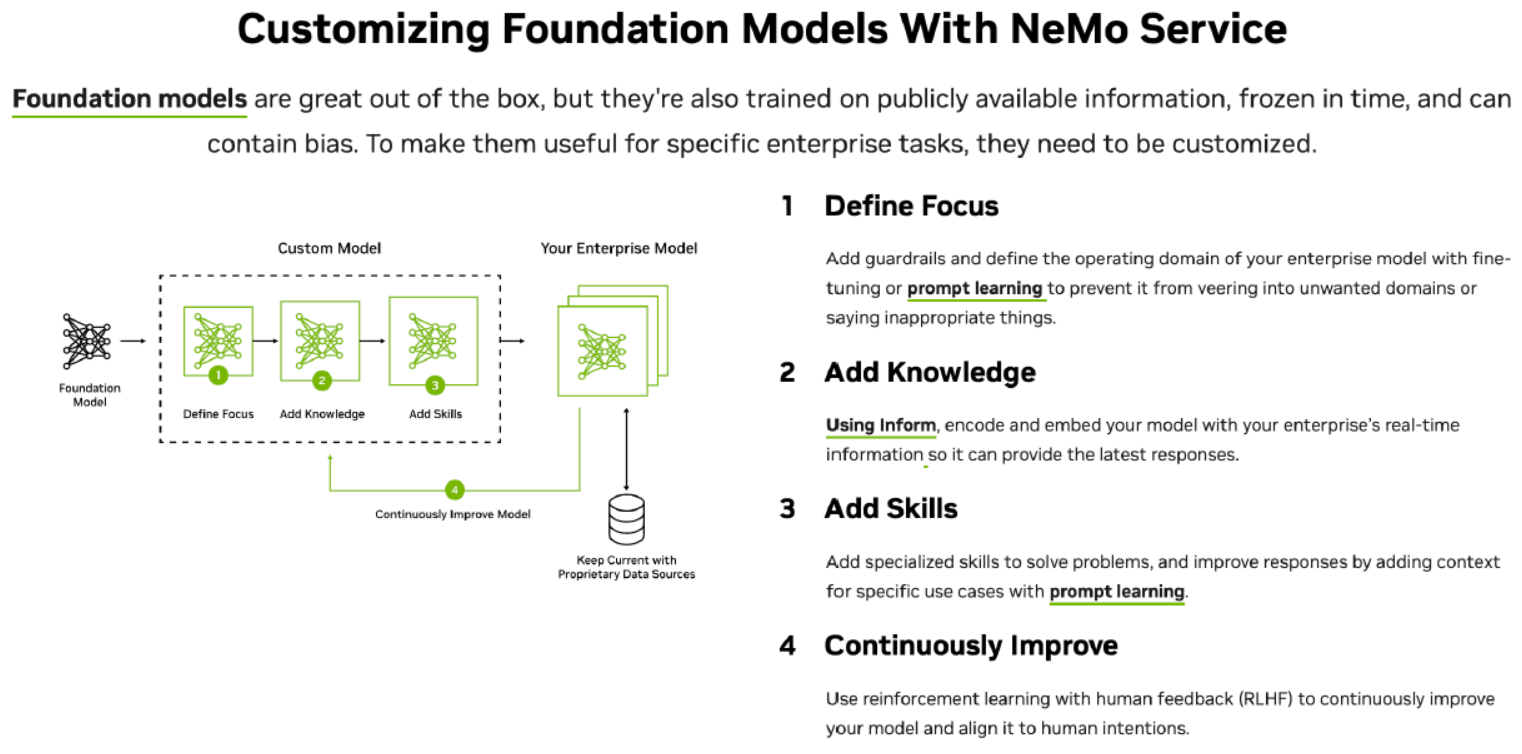
4. Dễ Dàng Tích Hợp: NeMo cung cấp các công cụ và API để tích hợp dễ dàng các mô hình đã xây dựng vào các ứng dụng thực tế. Điều này giúp việc triển khai LLMs vào các sản phẩm và dự án trở nên thuận tiện hơn, giúp hợp nhất công nghệ vào cuộc sống hàng ngày.
5. Hỗ Trợ Đa Nền Tảng: NeMo hỗ trợ nhiều loại phần cứng và nền tảng khác nhau, từ máy tính để bàn đến các hệ thống điện toán đám mây. Điều này giúp tối ưu hóa việc triển khai LLMs trên nhiều môi trường khác nhau.
6. Tạo Cơ Hội Mới Cho Nghiên Cứu và Ứng Dụng: Nhờ vào NeMo, việc xây dựng và triển khai LLMs trở nên dễ dàng hơn, mở ra cơ hội cho cộng đồng nghiên cứu và phát triển phát triển ứng dụng mới và sáng tạo trong lĩnh vực ngôn ngữ tự nhiên và trí tuệ nhân tạo.

Ứng Dụng Tuyệt Vời Của Large Language Models
Những mô hình ngôn ngữ lớn (LLMs) không chỉ là lý thuyết, chúng đã mở ra một loạt ứng dụng tuyệt vời trong nhiều lĩnh vực khác nhau. Hãy cùng khám phá những khả năng độc đáo của chúng:
1. Trong Cuộc Sống Hàng Ngày:
- Chatbot AI như ChatGPT: Các ứng dụng chatbot giúp giải quyết hàng loạt tác vụ xử lý ngôn ngữ tự nhiên một cách tự động, từ hỗ trợ khách hàng đến tương tác trò chuyện.
2. Kinh Doanh Và Tiếp Thị:
- Trải Nghiệm Khách Hàng: Nhà bán lẻ và các dịch vụ khác có thể sử dụng LLMs để cải thiện trải nghiệm khách hàng thông qua chatbot động và trợ lý AI.
- Tìm Kiếm Tối Ưu Hơn: Các công cụ tìm kiếm có thể tận dụng LLMs để cung cấp câu trả lời chính xác và tự nhiên hơn cho người dùng.
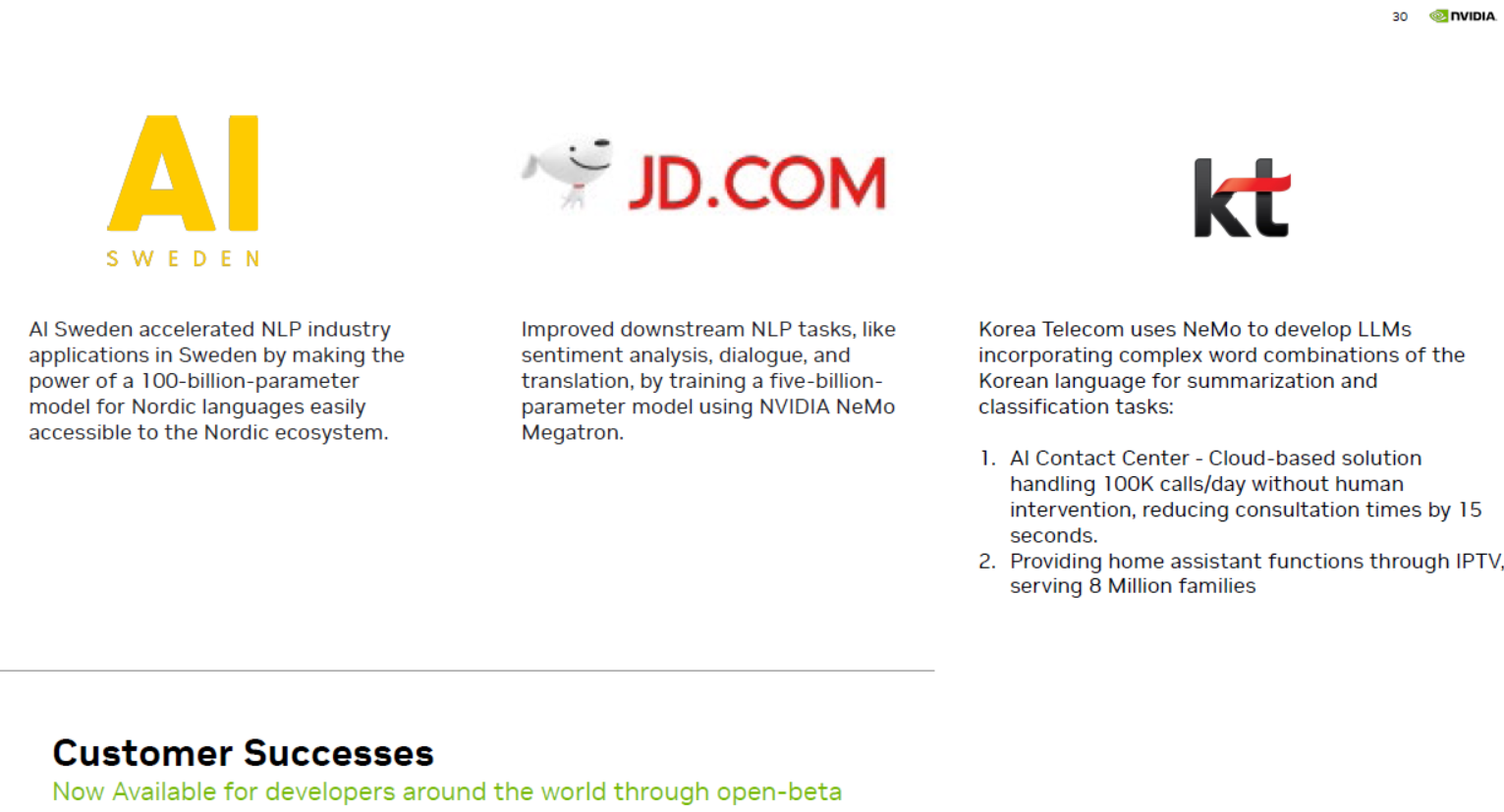
3. Khoa Học Và Y Tế:
- Hiểu Biết Về Y Học: LLMs có khả năng học về y tế từ các tài liệu và bài báo, hỗ trợ trong việc phân tích và tổng hợp thông tin y tế cho các chuyên gia y tế.
- Nghiên Cứu Và Phân Tích: Trong lĩnh vực nghiên cứu và phân tích dữ liệu, LLMs có thể hỗ trợ tổng hợp thông tin từ nhiều nguồn khác nhau và cung cấp hiểu biết sâu hơn.
4. Sáng Tạo Và Truyền Thông:
- Xuất Bản Và Sáng Tác: LLMs có thể tạo nội dung sáng tạo như tiểu thuyết, truyện ngắn và bài viết, hỗ trợ ngành xuất bản trong việc tạo nội dung đa dạng.
- Quảng Cáo Và Truyền Thông: LLMs hỗ trợ tạo nội dung quảng cáo, bài viết truyền thông và phân tích dữ liệu xã hội để cung cấp thông tin về ý kiến và xu hướng của khách hàng.
Còn đây chỉ là một phần nhỏ của tiềm năng của LLMs. Chúng đang thay đổi cách chúng ta tương tác với thông tin và đang giúp các lĩnh vực khác nhau phát triển một cách sáng tạo và hiệu quả hơn.

Kết Luận: NVIDIA NeMo là một công cụ mạnh mẽ cho việc phát triển Large Language Models, mang lại lợi ích vượt trội trong việc tối ưu hóa hiệu suất, đa dạng hóa ứng dụng và đơn giản hóa quá trình xây dựng. Nhờ vào NeMo, việc tạo ra những mô hình thông minh và sáng tạo liên quan đến ngôn ngữ tự nhiên trở nên dễ dàng hơn và hiệu quả hơn, đóng góp vào sự phát triển của lĩnh vực trí tuệ nhân tạo.
→ Tìm hiểu thêm: NVIDIA DGX H100 – siêu máy tính tối ưu cho Large Language Models https://thegioimaychu.vn/may-chu-tri-tue-nhan-tao-nvidia-dgx-h100-tm9193.html
→ Tìm hiểu thêm: NVIDIA NeMo – Frameworks tối ưu cho Large Language Models
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale