
Bài phát biểu quan trọng của NVIDIA GTC 2025 vừa được CEO NVIDIA Jensen Huang thực hiện vào khuya hôm qua (0:00AM ngày 19/3, giờ Việt Nam). Những điểm chính được ông đề cập trong bài phát biểu của mình bao gồm:
- Chúng ta đang ở điểm uốn cong của ngành điện toán trị giá 1 nghìn tỷ đô la. Nhu cầu điện toán AI đang tăng tốc nhanh chóng, được thúc đẩy bởi sự gia tăng của AI lý luận và agentic AI. Quy mô và độ phức tạp của khối lượng công việc AI đang chuyển đổi các khoản đầu tư vào trung tâm dữ liệu trên toàn thế giới.
- NVIDIA Blackwell đang trong giai đoạn sản xuất toàn diện, mang lại hiệu suất gấp 40 lần Hopper. Kiến trúc Blackwell cải thiện đáng kể khả năng đào tạo và suy luận mô hình AI, cho phép các ứng dụng AI hiệu quả và có khả năng mở rộng hơn. Và sự phát triển tiếp theo của nền tảng nhà máy AI NVIDIA Blackwell, Blackwell Ultra, sẽ ra mắt trên các hệ thống vào nửa cuối năm nay.
- NVIDIA sẽ tuân theo nhịp độ hàng năm để xây dựng cơ sở hạ tầng AI. Mỗi năm sẽ có GPU, CPU mới và những tiến bộ về điện toán được tăng tốc, bao gồm kiến trúc NVIDIA Vera Rubin sắp ra mắt, được thiết kế để thúc đẩy hiệu suất tăng và cải thiện hiệu quả trong các trung tâm dữ liệu AI.
- Cơ sở hạ tầng AI, bao gồm quang tử và lưu trữ được tối ưu hóa bằng AI, được thiết lập để cách mạng hóa ngành công nghiệp. Các giải pháp lưu trữ và mạng tiên tiến sẽ cải thiện khả năng mở rộng, hiệu quả và mức tiêu thụ năng lượng của AI trong các trung tâm dữ liệu quy mô lớn.
- AI vật lý cho công nghiệp và robot là cơ hội trị giá 50 nghìn tỷ đô la. Robot và tự động hóa hỗ trợ AI sẽ chuyển đổi sản xuất, hậu cần, chăm sóc sức khỏe và các ngành công nghiệp khác, với nền tảng NVIDIA Isaac và Cosmos dẫn đầu.
Xem lại toàn bộ video tường thuật:
Dưới đây là phần ghi nhận trực tiếp toàn bộ diễn biến của buổi Keynote do đội ngũ phóng viên của chuyên trang STH thực hiện.
Tại bài phát biểu quan trọng, chúng tôi mong đợi một số lượng lớn các thông báo về GPU, AI, mạng và robot. Kỳ vọng đây sẽ là một bài phát biểu quan trọng đông đúc vì NVIDIA đã chứng kiến sự tăng trưởng mạnh mẽ với sự bùng nổ của AI, trở thành một trong những công ty có giá trị nhất trên thế giới và là công ty dẫn đầu rõ ràng trong các danh mục sản phẩm dịch vụ cho các trung tâm dữ liệu lớn.
Bài phát biểu quan trọng năm nay được tổ chức tại Trung tâm SAP, một địa điểm chuyên tổ chức sự kiện thể thao tại San Jose. Chương trình đã phát triển vượt quá khả năng sắp xếp mọi người ở hội trường chính của Trung tâm Hội nghị San Jose cho bài phát biểu chính – mặc dù các phiên họp thực tế của chương trình vẫn diễn ra ở đó – vì vậy NVIDIA phải tổ chức bên ngoài Trung tâm SAP.
Thật không may, khả năng thu sóng tại Trung tâm SAP với hơn 10.000 chuyên gia công nghệ không tốt lắm – cả WiFi và mạng di động đều gần như bị tắt nghẽn, một phần là do mọi người cố gắng đăng tin tức từ bài phát biểu quan trọng – vì vậy có thể nói vui, chỗ ngồi tốt nhất là ngay tại nhà bạn, với luồng phát trực tiếp bài phát biểu quan trọng của NVIDIA. Đó là nơi tôi đang ở, trong khi Patrick đang ở Trung tâm SAP để xem bài phát biểu quan trọng của NVIDIA trực tiếp.
Tường thuật trực tiếp sự kiện NVIDIA GTC 2025 Keynote
Chỉ còn vài phút nữa là đến 10 giờ sáng giờ địa phương và chúng ta chỉ đang chờ bài phát biểu quan trọng của NVIDIA bắt đầu.
 Hình ảnh từ GTC 2025
Hình ảnh từ GTC 2025
Như thường lệ, NVIDIA về cơ bản có hai cấp độ thông báo được lên kế hoạch. Báo chí đã được thông báo trước về một số mục sẽ được tiết lộ trong bài phát biểu quan trọng, trong khi các chi tiết quan trọng và một số thông báo đặc biệt khác được giữ lại để các thông báo quan trọng nhất của công ty không bị rò rỉ (vô tình hay cố ý) trước. Có thể nói, triển lãm năm nay sẽ rất đông đúc.
Theo chính thức, thời lượng diễn thuyết chính theo lời mời trong lịch của NVIDIA là 2 giờ, nhưng các diễn thuyết chính của GTC thường kéo dài hơn. Yếu tố hạn chế duy nhất là gì? Đây là diễn thuyết chính vào buổi sáng năm nay, thay vì buổi chiều, vì vậy nếu diễn thuyết chính kéo dài quá lâu, điều đó có nghĩa là sẽ làm gián đoạn bữa trưa của mọi người!
Và có vẻ như bài phát biểu quan trọng sẽ bắt đầu hơi chậm một chút: lúc này đã 5 phút trôi qua và mọi thứ vẫn chưa bắt đầu.
Xin nhắc lại, các bài phát biểu quan trọng của GTC hôm nay liên quan đến phần mềm nhiều cũng như với phần cứng, nếu không muốn nói là nhiều hơn. Trong khi NVIDIA đầu tư hàng tỷ đô la vào phát triển phần cứng, họ cũng đầu tư số tiền lớn tương tự vào phát triển phần mềm – và chính nó ngày càng trở thành lĩnh vực quan trọng của họ trong thập kỷ qua, vì họ đã cung cấp hàng trăm thư viện hoàn chỉnh, API và các công cụ khác cho các nhà phát triển. Do đó, việc tìm ra một phần mềm tối ưu hóa để cắt giảm lượng thời gian cần thiết để tạo các token LLM có thể mang lại lợi nhuận rất lớn. Và với tốc độ cải tiến phần cứng (tăng số lượng bóng bán dẫn) đang chậm lại, điều này khiến phần mềm trở nên quan trọng hơn bao giờ hết.
Và chúng ta bắt đầu thôi!
Chủ đề năm nay: Nhà máy AI (AI Factory)
 Đoạn giới thiệu mở đầu bài phát biểu quan trọng của GTC 2025
Đoạn giới thiệu mở đầu bài phát biểu quan trọng của GTC 2025
Và token. Trong thế giới của NVIDIA, token là đơn vị tính toán cho AI (và những gì khách hàng của họ có thể tính phí)
“Token không chỉ dạy robot cách di chuyển mà còn cách mang lại niềm vui”
“Và đây là nơi mọi thứ bắt đầu”
 GTC 2025 Jensen Trên Sân Khấu
GTC 2025 Jensen Trên Sân Khấu
“Năm nay chúng tôi muốn đưa bạn đến trụ sở chính của NVIDIA”
“Chúng ta có rất nhiều điều đáng kinh ngạc để nói”
Jensen muốn cho khán giả biết rằng anh ấy đang làm điều này mà không cần kịch bản hay máy nhắc chữ.
“GTC bắt đầu với GeForce”
Jensen cầm trên tay GeForce RTX 5090 và RTX 4090 để so sánh.
 GeForce RTX 5090
GeForce RTX 5090
Jensen đang giới thiệu một môi trường theo dõi đường đi – với AI đáng kể để cung cấp khả năng nâng cấp, giảm nhiễu, v.v.
“AI tạo ra đã thay đổi cơ bản cách thức tính toán được thực hiện”
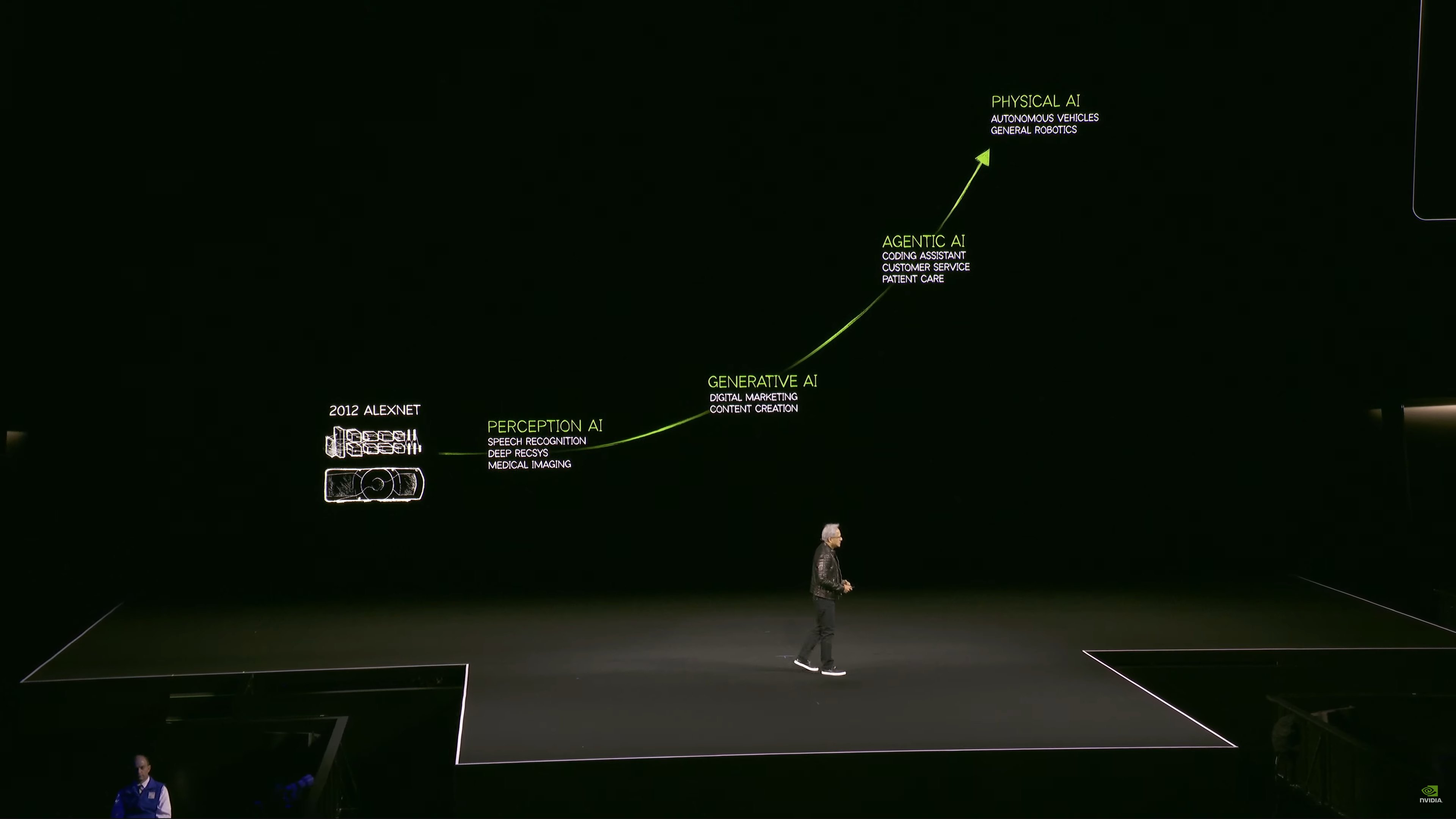 Sơ đồ tăng trưởng AI
Sơ đồ tăng trưởng AI
AI hiện có khả năng tự chủ – cái mà Jensen gọi là AI “Agentic”. Các mô hình có thể lấy nội dung từ các trang web, vừa để đào tạo, vừa để lấy thông tin tức thời hơn.
Jensen cho biết ngày nay họ cũng sẽ nói nhiều về khả năng lý luận của AI.
Cũng như “AI vật lý”, sử dụng AI để giúp mô phỏng và đào tạo các mô hình AI khác.
“Cách duy nhất để GTC lớn mạnh hơn là mở rộng San Jose. Chúng tôi đang thực hiện điều đó!”
Mỗi năm, ngày càng có nhiều người tham gia vì AI có khả năng giải quyết nhiều vấn đề hơn cho nhiều người và công ty hơn.
Ba định luật tỷ lệ cơ bản:
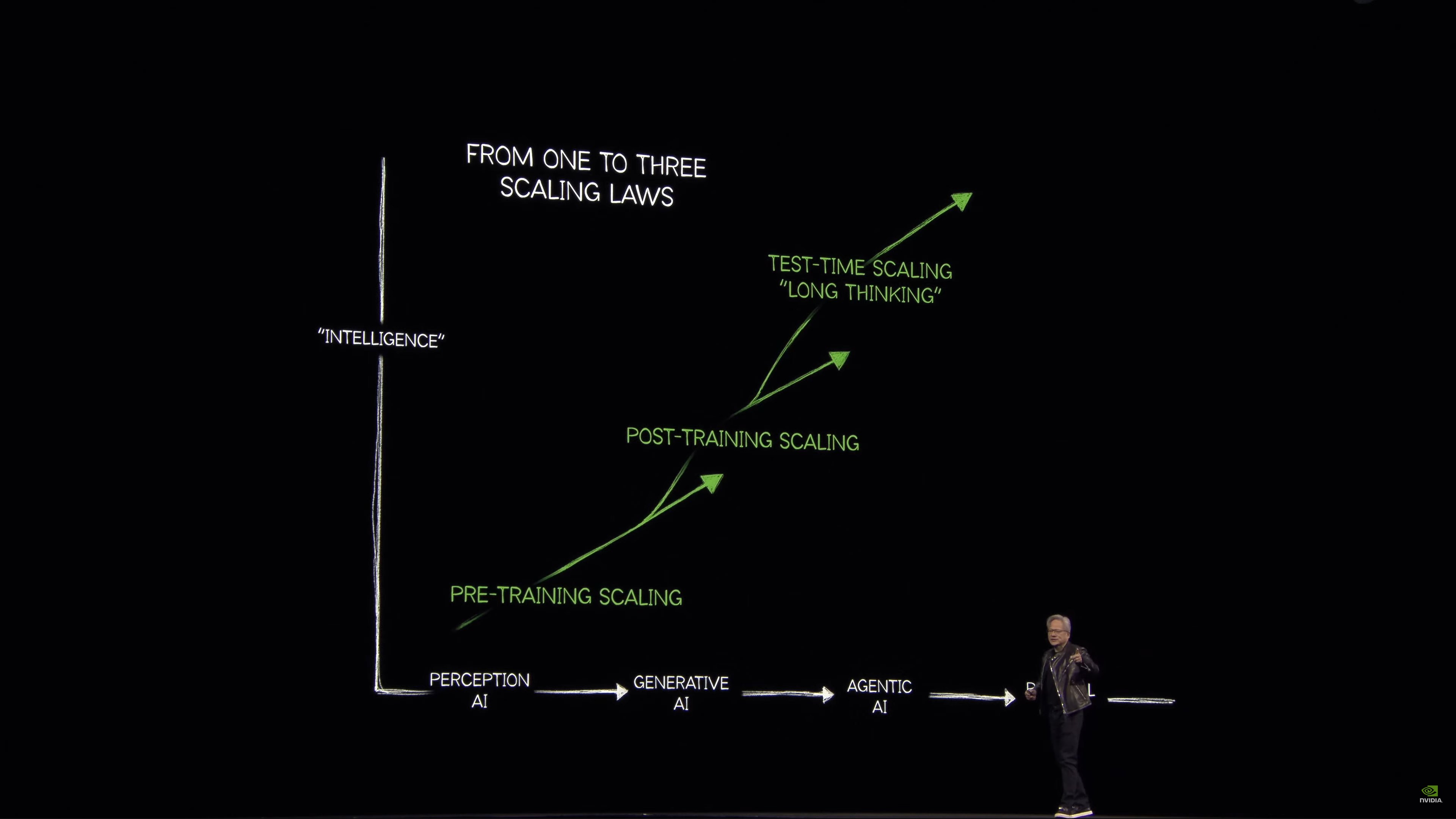 Luật mở rộng AI
Luật mở rộng AI
Mở rộng trước khi đào tạo, mở rộng sau khi đào tạo và mở rộng theo thời gian thử nghiệm. Làm thế nào để tạo, làm thế nào để đào tạo và làm thế nào để mở rộng?
Scaling: đây là nơi mà hầu như toàn bộ thế giới đã sai vào năm ngoái. Lượng tính toán mà chúng ta cần do suy luận dễ dàng gấp 100 lần so với những gì thế giới nghĩ rằng họ sẽ cần vào năm ngoái.
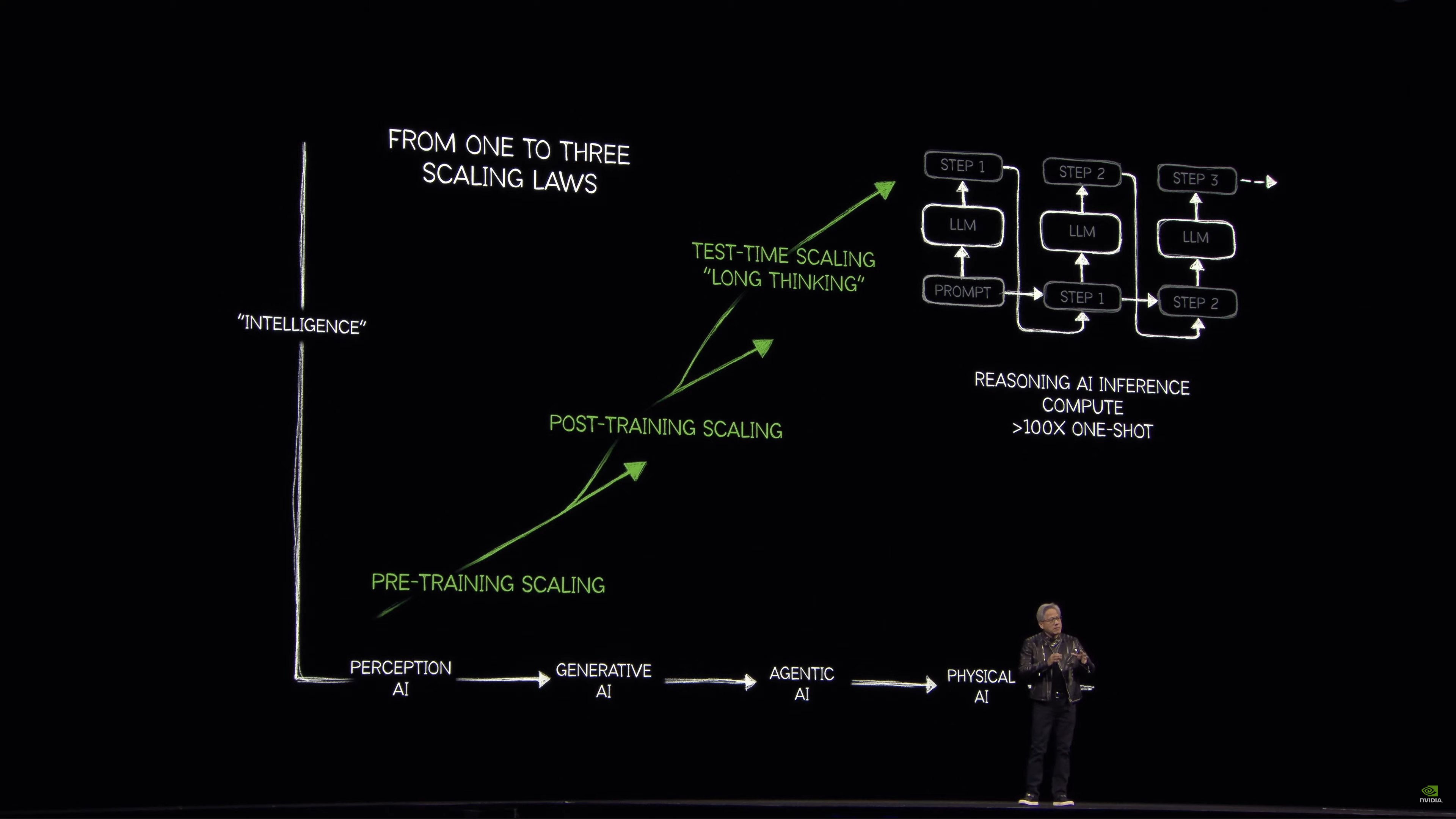 Luật mở rộng với khả năng Lý luận
Luật mở rộng với khả năng Lý luận
Bây giờ chúng ta có AI có thể suy luận từng bước nhờ vào chuỗi suy nghĩ và các kỹ thuật khác. Nhưng quá trình cơ bản để tạo ra token vẫn không thay đổi. Thay vào đó, loại suy luận này đòi hỏi nhiều token hơn – cao hơn đáng kể, “dễ dàng gấp 100 lần”.
Để duy trì khả năng phản hồi của mô hình, lượng tính toán cần thiết mỗi giây cũng cao như vậy.
Học tăng cường là bước đột phá lớn trong vài năm trở lại đây. Cung cấp cho AI hàng triệu ví dụ khác nhau để giải quyết vấn đề từng bước một và thưởng (tăng cường) AI khi AI làm tốt hơn. Điều đó tương đương với hàng nghìn tỷ token để đào tạo mô hình đó. Nói cách khác: tạo dữ liệu tổng hợp để đào tạo AI.
Jensen cho biết ngành công nghiệp đã chấp nhận điều này thông qua việc bán phần cứng.
Các lô hàng Hopper hàng đầu cho các nhà cung cấp dịch vụ đám mây. Năm cao điểm của Hopper so với năm đầu tiên của Blackwell.
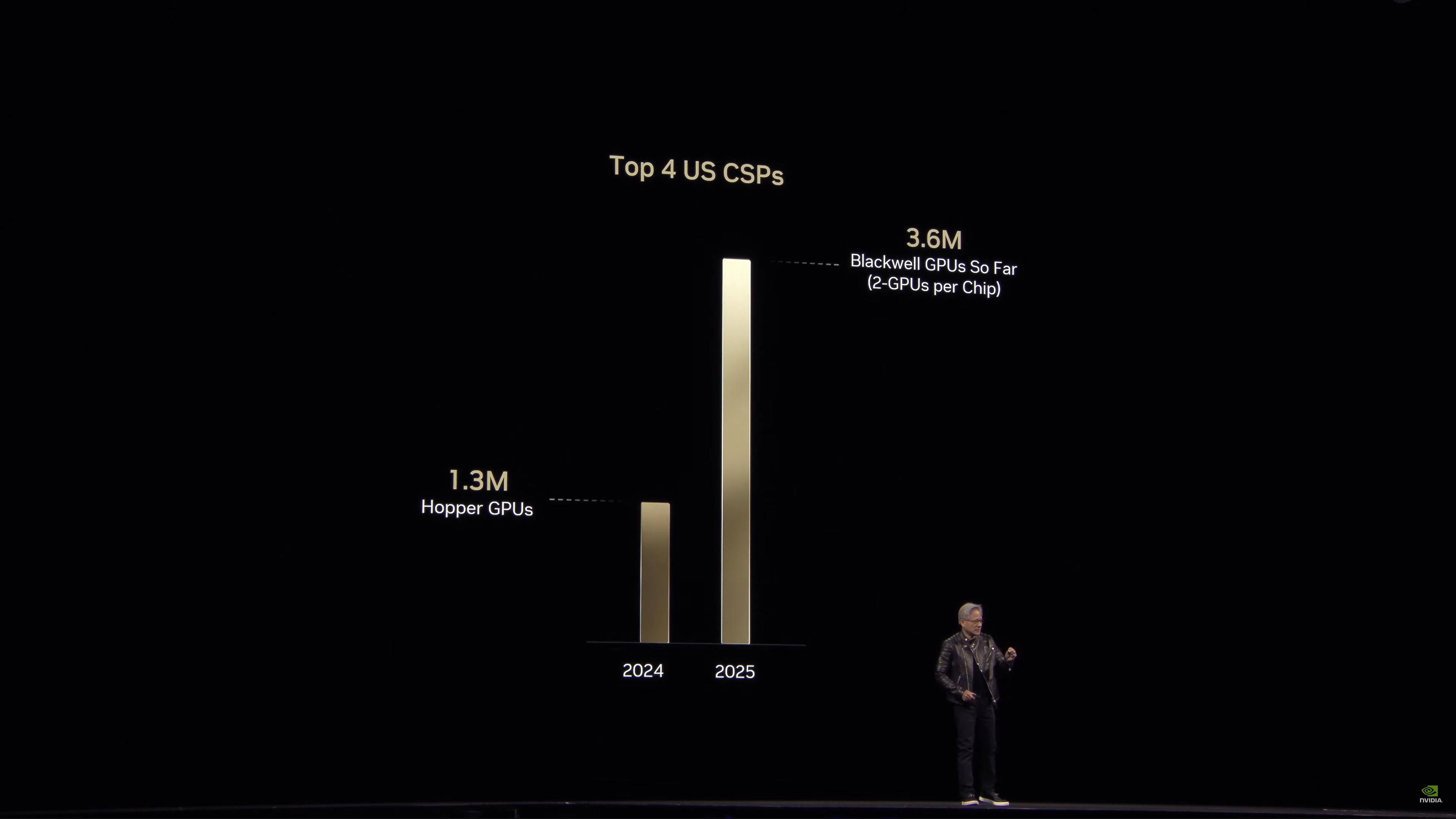 Doanh số Hopper so với Blackwell
Doanh số Hopper so với Blackwell
Chỉ trong một năm – và Blackwell vừa mới bắt đầu được xuất xưởng – NVIDIA đã báo cáo mức tăng trưởng đáng kể về doanh số bán GPU cho doanh nghiệp.
Jensen dự kiến việc xây dựng trung tâm dữ liệu sẽ sớm đạt tới con số một nghìn tỷ đô la.
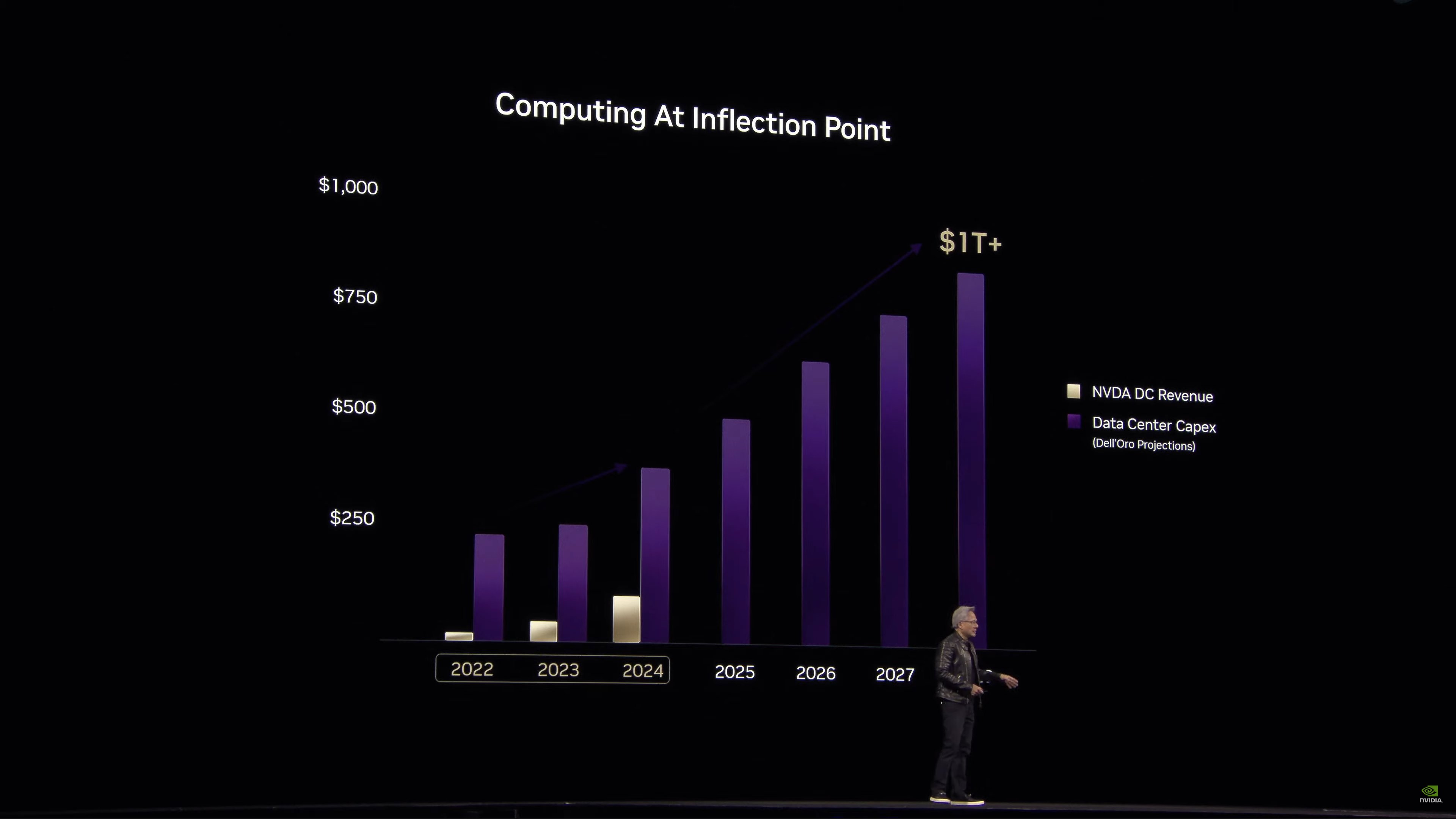 Doanh thu mảng điện toán
Doanh thu mảng điện toán
Jensen tin rằng chúng ta đang chứng kiến bước ngoặt trong việc xây dựng trung tâm dữ liệu theo hướng điện toán tăng tốc (tức là GPU và các bộ tăng tốc khác thay vì chỉ CPU).
“Máy tính đã trở thành một máy tạo ra các token, thay vì là một máy thu thập các tập tin”. Đây chính là thứ mà NVIDIA gọi là Nhà máy AI.
Mặc dù mọi thứ trong trung tâm dữ liệu sẽ được tăng tốc, nhưng không phải tất cả đều là AI.
 NVIDIA CUDA-X
NVIDIA CUDA-X
Bạn cũng cần các khuôn khổ cho vật lý, sinh học và các lĩnh vực khoa học khác. NVIDIA đã cung cấp tất cả những thứ này như một phần của thư viện CUDA-X của họ. cuLitho cho quang khắc tính toán, cuPynumeric cho tính toán số, Aerial cho xử lý tín hiệu, v.v. Đây là “hào” của NVIDIA trong ngành công nghiệp lớn hơn.
“Chúng tôi sẽ tổ chức Ngày lượng tử đầu tiên tại GTC” vào thứ năm.
“Cơ sở cài đặt CUDA hiện đã có mặt ở khắp mọi nơi” Bằng cách sử dụng các thư viện này, phần mềm của nhà phát triển có thể tiếp cận được với mọi người.
Bây giờ Jensen sẽ dành 5 phút để NVIDIA chạy một đoạn video ngắn về CUDA và cảm ơn nhiều nhà phát triển tại triển lãm.
 Video quảng cáo CUDA
Video quảng cáo CUDA
Blackwell nhanh hơn 50.000 lần so với GPU CUDA đầu tiên.
Và quay lại với Jensen.
“Tôi thích những gì chúng tôi làm. Tôi còn thích hơn những gì bạn làm với nó.”
 AI cho mọi ngành công nghiệp
AI cho mọi ngành công nghiệp
Các CSP rất thích các nhà phát triển CUDA là khách hàng của CSP.
Nhưng giờ đây khi họ chuẩn bị đưa AI ra toàn thế giới, mọi thứ đang thay đổi một chút. GPU đám mây, điện toán biên, v.v., đều có những yêu cầu riêng.
Trong số nhiều thông báo nhỏ hơn của NV, một số công ty (Cisco, T-Mobile và các công ty khác) đang xây dựng một ngăn xếp đầy đủ cho các mạng vô tuyến tại Hoa Kỳ bằng cách sử dụng các công nghệ của NVIDIA (Ariel-Sionna, v.v.).
Nhưng đó chỉ là một ngành công nghiệp. Còn có xe tự lái nữa. AlexNet đã thuyết phục NVIDIA dốc toàn lực vào công nghệ xe tự lái. Và giờ đây công nghệ của họ đang được sử dụng trên toàn thế giới. NVIDIA xây dựng máy tính để đào tạo, mô phỏng và máy tính xe tự lái.
NVIDIA thông báo rằng GM sẽ hợp tác với NVIDIA để xây dựng đội xe tự lái trong tương lai.
“Thời đại của xe tự hành đã đến”
(Tôi hy vọng điều này là sự thật, nhưng tôi cảm thấy mình đã nghe điều gì đó rất giống khi tôi lái một chiếc xe tự hành chạy bằng động cơ NV tại CES 2018)
NVIDIA đã có tất cả 7 triệu dòng mã được đánh giá an toàn bởi bên thứ ba. An toàn có vẻ là từ ngữ chính cho những nỗ lực trong lĩnh vực ô tô của NVIDIA trong năm nay.
Bây giờ chúng ta sẽ xem một video khác, lần này nói về công nghệ và kỹ thuật mà NVIDIA đang sử dụng để tạo ra xe tự hành.
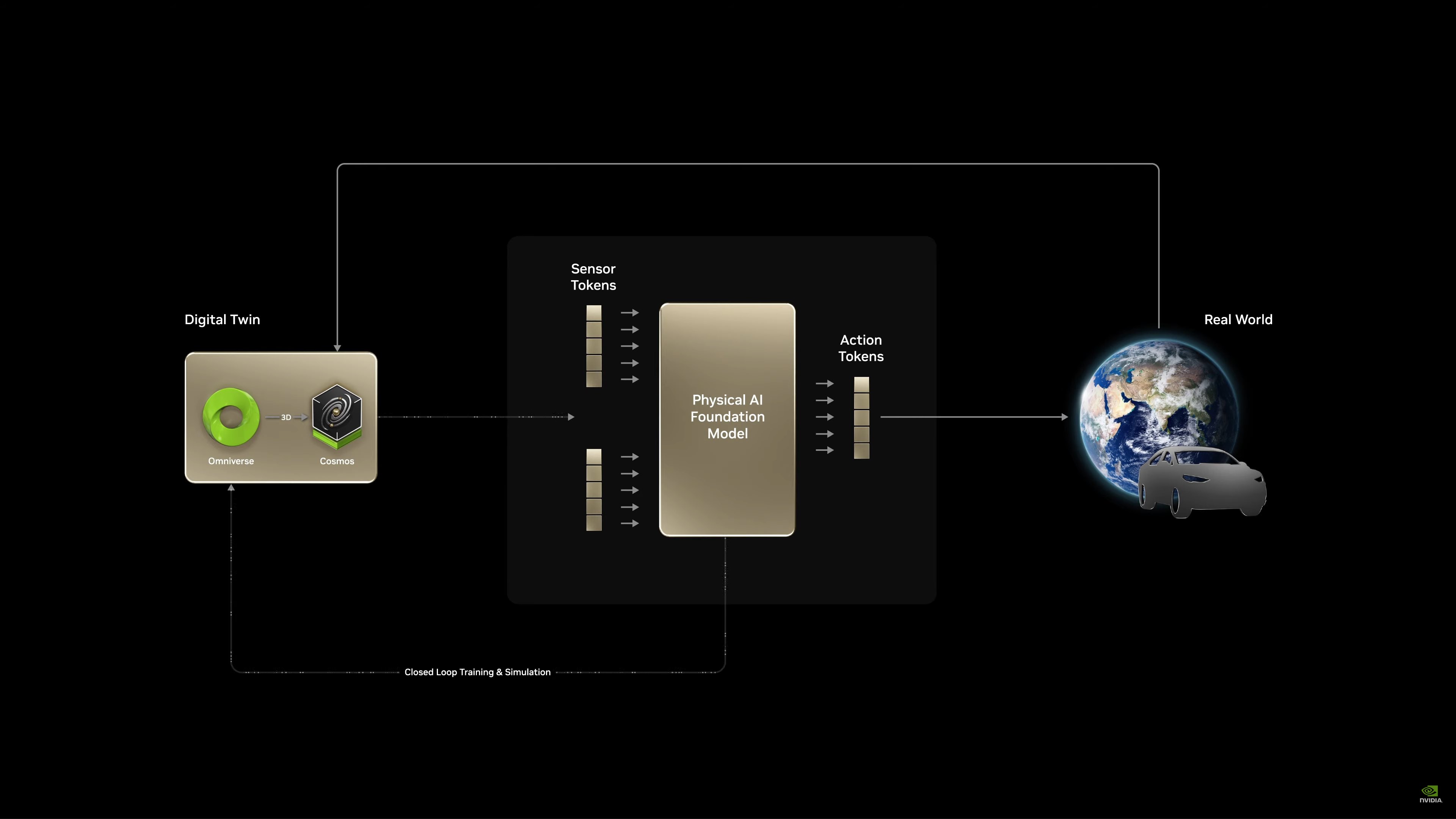 Vòng lặp đào tạo xe tự hành
Vòng lặp đào tạo xe tự hành
Bản sao kỹ thuật số, học tăng cường, tạo ra nhiều kịch bản khác nhau, v.v. Tất cả đều được xây dựng xung quanh NVIDIA Cosmos. Sử dụng AI để tạo ra nhiều AI hơn.
Bây giờ đến phần trung tâm dữ liệu.
 Grace Blackwell trong quá trình sản xuất đầy đủ
Grace Blackwell trong quá trình sản xuất đầy đủ
Grace Blackwell hiện đang trong giai đoạn sản xuất toàn diện. Jensen đang giới thiệu các hệ thống giá đỡ khác nhau do các đối tác cung cấp.
NVIDIA đã dành rất nhiều thời gian để nghiên cứu về điện toán phân tán – cách mở rộng quy mô, rồi cách mở rộng quy mô. Mở rộng quy mô rất khó; vì vậy NVIDIA phải mở rộng quy mô trước với cấu hình HGX và GPU 8 chiều.
 HGX và Blackwell
HGX và Blackwell
Jensen đang trình bày một hệ thống NVL8 được xây dựng. Với sự nhấn mạnh vào quá khứ.
Để vượt qua điều đó, NVIDIA đã phải thiết kế lại cách thức hoạt động của hệ thống NVLink để mở rộng quy mô hơn nữa. NVIDIA đã di chuyển NVLink chuyển mạch ra khỏi khung máy và chuyển nó đến một thiết bị đơn vị giá đỡ. “NVLInk không tập trung”
 Chuyển mạch phân tách NVLink
Chuyển mạch phân tách NVLink
Hiện nay NVIDIA có thể cung cấp một ExaFLOP (có độ chính xác thấp) trong một giá đỡ.
 GPU Blackwell
GPU Blackwell
GPU Blackwell hiện đang mở rộng giới hạn về lưới ngắm, do đó NVIDIA đã mở rộng quy mô bằng cách chuyển sang các hệ thống có kích thước lớn thay vì các máy chủ riêng lẻ.
Tất cả những điều này, đến lượt nó, sẽ giúp cung cấp hiệu suất tính toán cho AI. Và không chỉ để đào tạo mà còn để suy luận nữa.
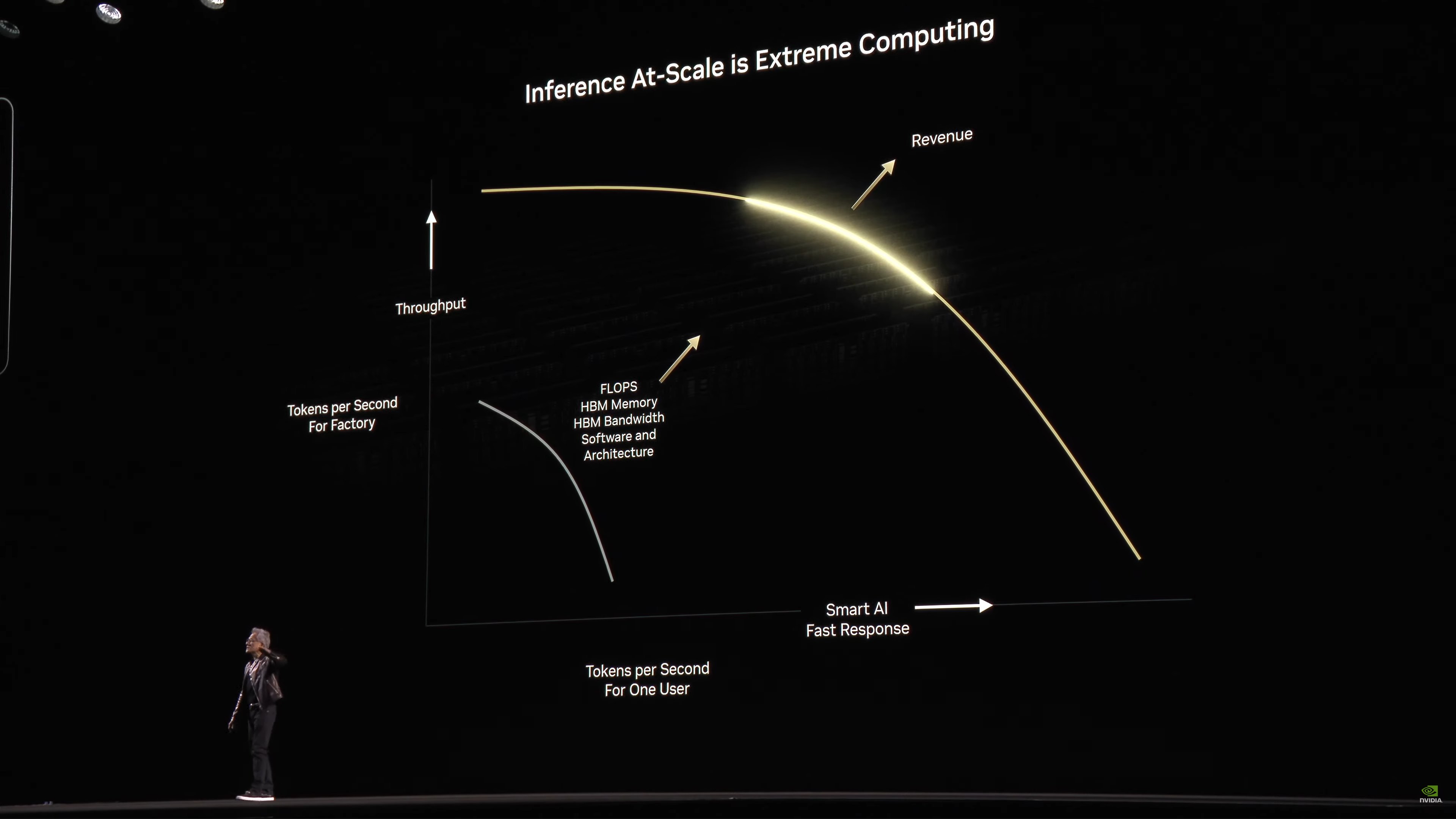 Đường cong hiệu suất suy luận
Đường cong hiệu suất suy luận
Jensen đang trình bày một đường cong hiệu suất suy luận cho máy tính quy mô lớn. Nói tóm lại, đó là sự cân bằng giữa tổng thông lượng và khả năng phản hồi. Giữ cho hệ thống bão hòa sẽ tối đa hóa thông lượng mã thông báo, nhưng sẽ mất nhiều thời gian để tạo ra một mã thông báo riêng lẻ. Mất quá nhiều thời gian và người dùng sẽ chuyển sang nơi khác.
Đây là sự đánh đổi kinh điển giữa độ trễ và thông lượng.
Vì vậy, đối với các đối tác CSP của NVIDIA và các khách hàng khác đang sử dụng phần cứng NV để suy luận, để tối đa hóa doanh thu của họ, họ cần phải cẩn thận chọn một điểm trên đường cong. Nhìn chung, điểm lý tưởng sẽ ở trên và bên phải – thông lượng và khả năng phản hồi cao nhất mà không làm giảm đáng kể điểm này để cải thiện nhỏ điểm kia.
Tất cả những điều này đòi hỏi FLOPS, băng thông bộ nhớ và nhiều thứ khác nữa. Vì vậy, NVIDIA đã xây dựng phần cứng để cung cấp điều đó.
Bây giờ chúng ta sẽ chạy một video khác, cho thấy tiện ích và nhu cầu tính toán của các mô hình suy luận.
 Lý luận AI (AI Reasoning)
Lý luận AI (AI Reasoning)
LLM truyền thống nhanh, hiệu quả và sai trong trường hợp sử dụng ghế ngồi tiệc cưới của NVIDIA. 439 token bị lãng phí. Mô hình lý luận có thể xử lý được, nhưng cần hơn 8.000 token.
Để thực hiện được tất cả những điều này một cách hiệu quả không chỉ cần nhiều phần cứng mà còn cần rất nhiều phần mềm được tối ưu hóa, bao gồm cả hệ điều hành để xử lý các tối ưu hóa cơ bản như xử lý hàng loạt.
Điền trước – tiêu hóa thông tin – rất tốn FLOPS. Bước tiếp theo, giải mã, tốn nhiều băng thông bộ nhớ vì mô hình cần được kéo vào từ bộ nhớ; hàng nghìn tỷ tham số. Tất cả những điều này để tạo ra 1 mã thông báo.
Đây chính là lý do cơ bản tại sao bạn muốn có NVLink. Để lấy nhiều GPU và biến chúng thành một GPU lớn.
Và sau đó điều này cho phép tối ưu hóa thêm. Sẽ sử dụng bao nhiêu GPU để làm việc trên pre-fill so với decode?
Thông báo: NVIDIA Dynamo, một thư viện phục vụ suy luận phân tán. Hệ điều hành của AI Factory.
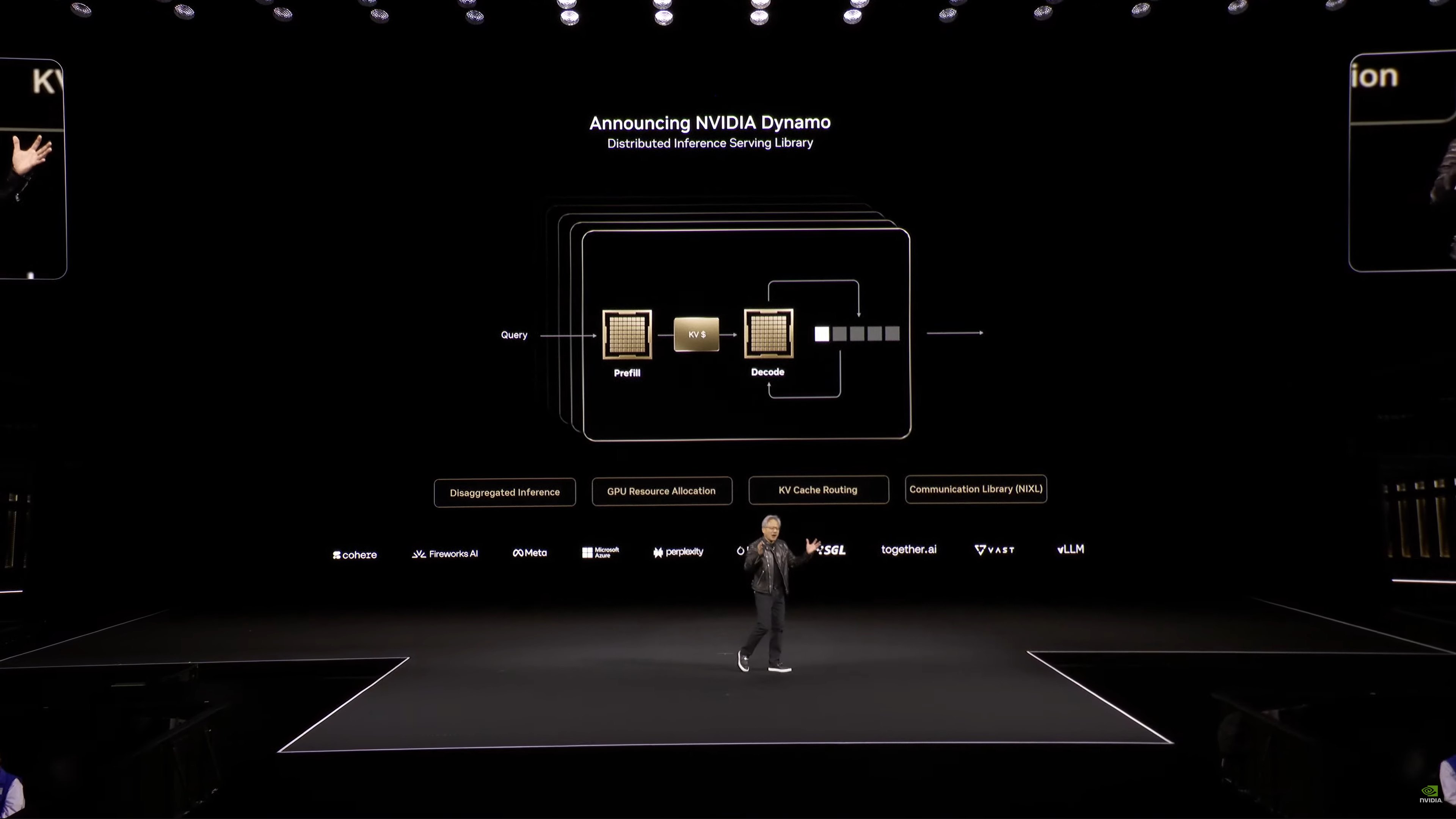 NVIDIA Dynamo
NVIDIA Dynamo
Jensen đang so sánh Dynamo với VMWare về mặt phạm vi. Trong khi VMWare được bố trí trên hệ thống CPU, Dynamo được bố trí trên hệ thống GPU.
Dynamo là mã nguồn mở.
Bây giờ quay lại phần cứng và hiệu suất. Jensen đang so sánh thiết lập NVL8 Hopper với Blackwell. Tokens per Second trên Megawatt được biểu diễn so với Tokens per Second trên mỗi Người dùng.
“Chỉ có ở NVIDIA bạn mới bị tra tấn bằng toán học”
Đối với các nhà cung cấp dịch vụ, nhiều token trong nhiều thời gian sẽ chuyển thành nhiều doanh thu. Hãy ghi nhớ sự đánh đổi giữa thông lượng và khả năng phản hồi. Đây là đường cong mà NVIDIA đang cố gắng uốn cong.
Blackwell cải thiện điều này bằng phần cứng tốt hơn và hỗ trợ các định dạng dữ liệu có độ chính xác thấp hơn (FP4). Sử dụng ít năng lượng hơn để làm giống như trước đây, để làm được nhiều hơn.
“Mọi trung tâm dữ liệu trong tương lai sẽ bị giới hạn về nguồn điện.” “Chúng ta hiện là một ngành công nghiệp bị giới hạn về nguồn điện”
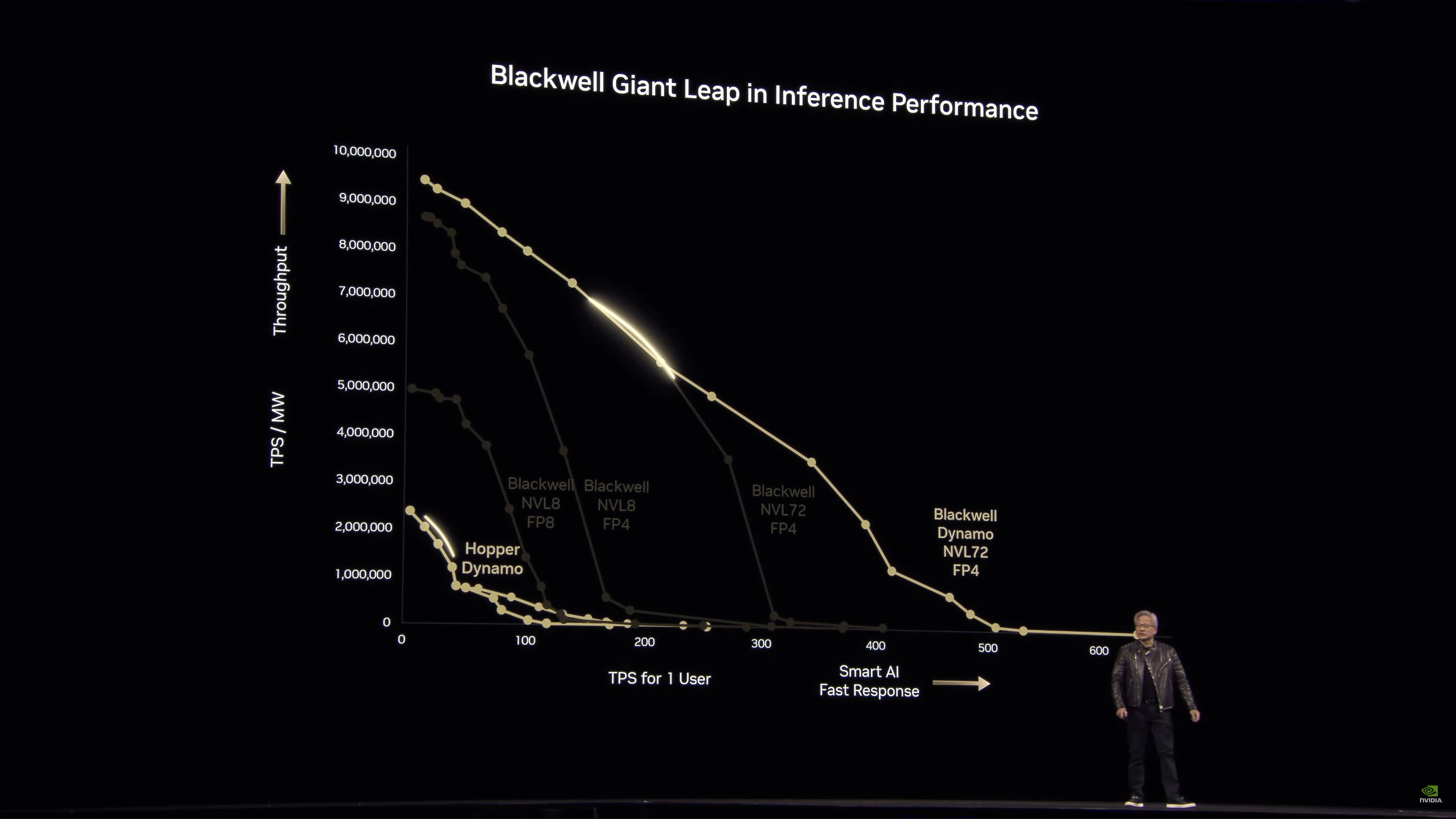 Đường cong hiệu suất NVIDIA Dynamo
Đường cong hiệu suất NVIDIA Dynamo
Dynamo giúp Blackwell NVL72 thậm chí còn nhanh hơn. Và đây là ở iso-power, không phải iso-chip. 25x trong một thế hệ.
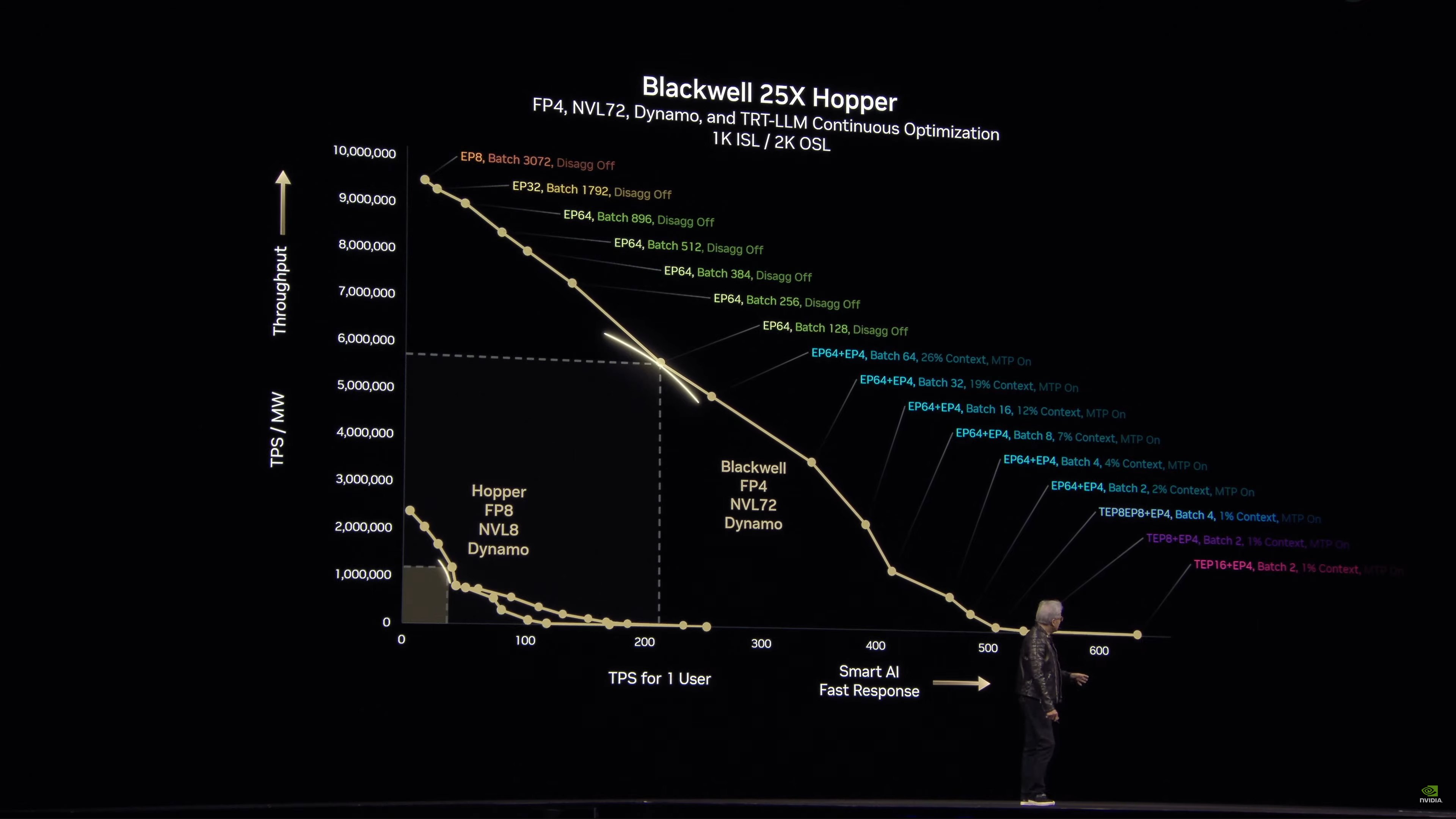 Các điểm trên Đường cong Hiệu suất
Các điểm trên Đường cong Hiệu suất
Bây giờ chúng ta sẽ nói một chút về ranh giới Pareto và tính tối ưu Pareto, cũng như cách các cấu hình mô hình khác nhau tác động đến các điểm khác nhau trên đường cong.
Và trong những tình huống khác, Blackwell có thể đạt hiệu suất gấp 40 lần (iso-power) của Hopper.
“Tôi là người phá hoại doanh thu chính.” “Có những trường hợp mà Hopper vẫn ổn.”
 Doanh số Token của Hopper so với Blackwell
Doanh số Token của Hopper so với Blackwell
Và câu đó là: “Bạn mua càng nhiều, bạn càng tiết kiệm được nhiều.” “Bạn mua càng nhiều, bạn càng kiếm được nhiều.”
Quay một video khác. Lần này nói về cách NVIDIA đang xây dựng bản sao kỹ thuật số cho các trung tâm dữ liệu của mọi thứ. (Trong thế giới của NV, sau cùng thì đó chỉ là một nhà máy khác)
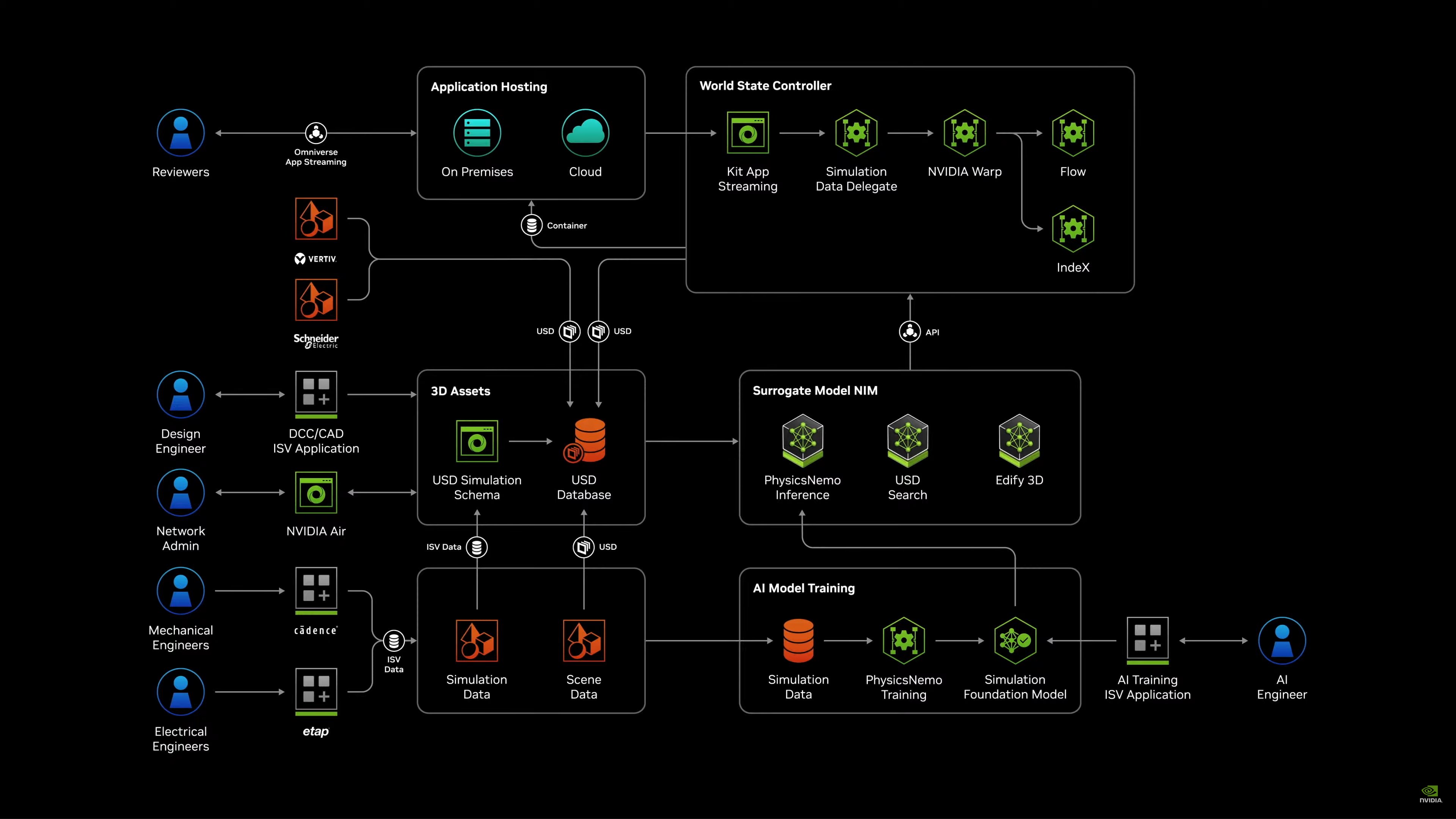 Bản thiết kế trung tâm dữ liệu Omniverse
Bản thiết kế trung tâm dữ liệu Omniverse
Cuối cùng, việc sử dụng bản sao kỹ thuật số cho phép tất cả những điều này được lên kế hoạch và tối ưu hóa trước, sau đó cuối cùng được xây dựng một lần và nhanh chóng.
 Blackwell Ultra NVL72
Blackwell Ultra NVL72
Jensen sắp hết thời gian và sẽ phải tăng tốc!
Blackwell Ultra NVL72, sẽ được bán ra vào nửa cuối năm nay. 1,1 Exaflops suy luận FP4 dày đặc. Băng thông mạng tăng gấp 2 lần. Bộ nhớ hệ thống HBM 20TB. Và một lệnh chú ý mới có thể tăng gấp đôi hiệu suất ở đó.
Ngành công nghiệp hiện đang ở giai đoạn cần phải lên kế hoạch chi tiêu. Các công ty đang thực hiện các cam kết nhiều năm đối với phần cứng, cơ sở vật chất và hệ sinh thái của NVIDIA. Đó là lý do tại sao Jensen muốn làm rõ lộ trình của NVIDIA.
Tiếp theo Blackwell là Vera Rubin, người phát hiện ra vật chất tối.
 Vera Rubin
Vera Rubin
Vera Rubin NVL144, nửa cuối năm 2026. CPU Vera Arm + GPU Rubin.
Trong tương lai, NVIDIA hiện đang đếm số lượng GPU die thay vì từng chip GPU riêng lẻ khi nói về miền NVLink. Vì vậy, NVL144 là 144 die, không phải 144 chip.
 Rubin Ultra NVL576
Rubin Ultra NVL576
Và sau đó là Rubin Ultra NVL576 vào nửa cuối năm 2027. 600KW cho một giá đỡ. 15 ExaFLOP. Bộ nhớ HBM4e 1TB cho mỗi gói GPU.
 NVIDIA Rubin đang mở rộng quy mô
NVIDIA Rubin đang mở rộng quy mô
 Nền kinh tế của Nhà máy AI (AI Factory)
Nền kinh tế của Nhà máy AI (AI Factory)
Rubin sẽ giảm đáng kể chi phí tính toán AI.
Và đó là quá trình mở rộng quy mô. Bây giờ là lúc nói về quá trình mở rộng quy mô và các sản phẩm mạng của NVIDIA.
Jensen đang tóm tắt lại quyết định mua Mellanox và tham gia vào thị trường mạng của NVIDIA.
 NVIDIA Spectrum-X
NVIDIA Spectrum-X
CX-8 và CX-9 sắp ra mắt. NVIDIA muốn mở rộng quy mô lên hàng trăm nghìn GPU trong kỷ nguyên Rubin.
Scale-out có nghĩa là các trung tâm dữ liệu có kích thước bằng một sân vận động. Kết nối bằng đồng sẽ không đủ. Cần có kết nối quang. Và kết nối quang có thể tiêu tốn rất nhiều năng lượng. Vì vậy, NVIDIA có kế hoạch làm cho mạng quang hiệu quả hơn với các photonic silicon được đóng gói chung.
 NVIDIA Photonics
NVIDIA Photonics
Dựa trên công nghệ có tên là Micro Ring Modulators (MRM). Được xây dựng tại TSMC trên quy trình xếp chồng 3D mới mà họ đang nghiên cứu cùng với nhà máy.
 Jensen – The Cable Guy
Jensen – The Cable Guy
(Gỡ rối dây cáp) “Ôi trời ơi”
Jensen đang nói về cách thức hoạt động của mạng quang hiện tại, với các bộ thu phát riêng cho mỗi cổng ở cả hai bên. Điều này đáng tin cậy và hiệu quả, nhưng việc chuyển đổi từ tín hiệu điện sang quang (và ngược lại) làm tiêu thụ thêm điện năng.
“Mỗi GPU sẽ có 6 bộ thu phát”. Điều này sẽ cần 180 Watt (30W mỗi cái) và hàng ngàn đô la tiền mua bộ thu phát.
Toàn bộ điện năng tiêu thụ bởi bộ thu phát là điện năng không thể sử dụng cho GPU. Điều này khiến NVIDIA không thể bán cho khách hàng nhiều GPU hơn nữa.
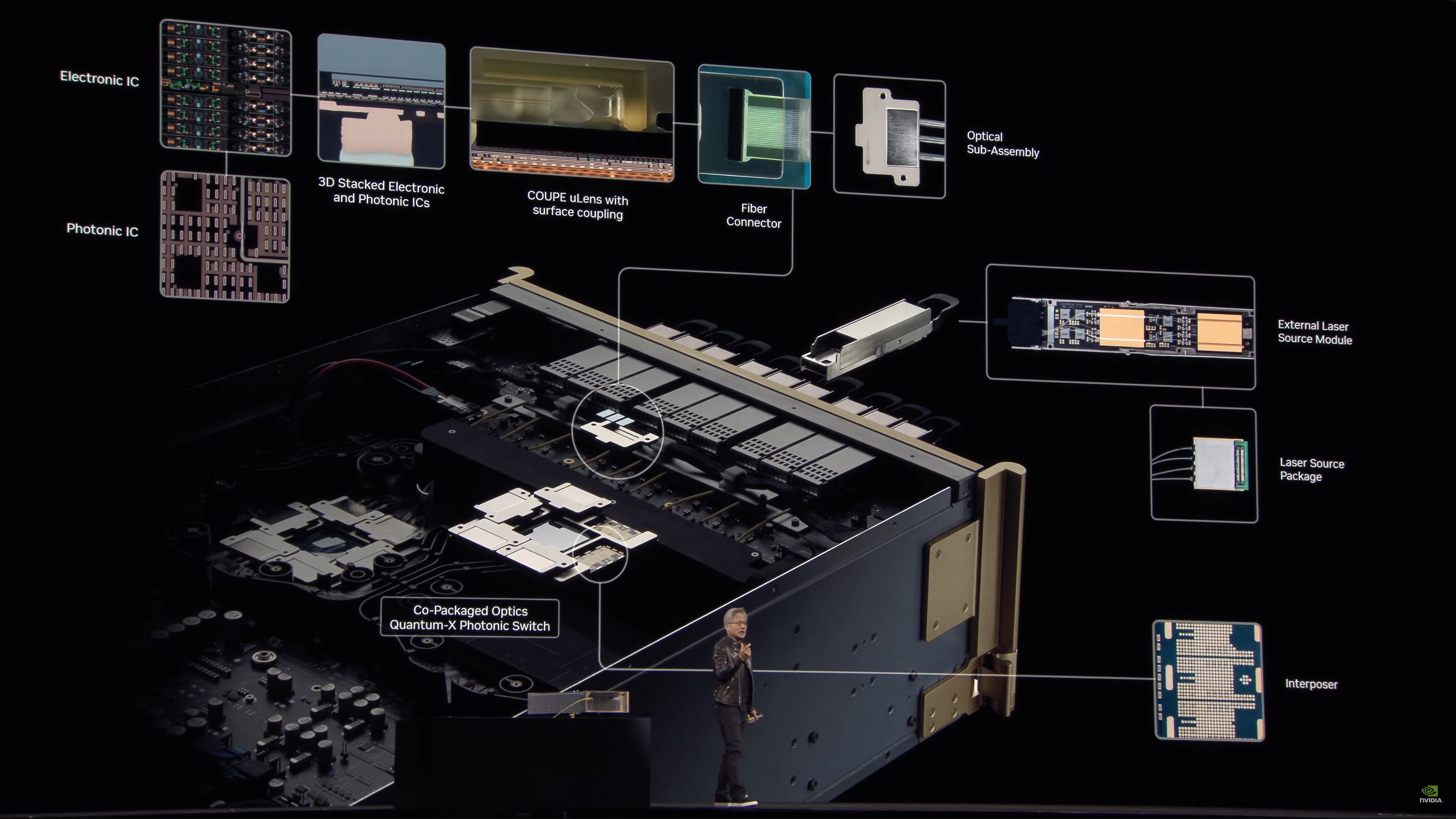 Mô-đun đa vòng (MRM)
Mô-đun đa vòng (MRM)
Được đóng gói như TSMC sử dụng COUPE .
Bây giờ chúng ta sẽ xem một video khác cho thấy cách hệ thống quang tử hoạt động chi tiết hơn.
 Laser quang tử
Laser quang tử
NVIDIA sẽ tung ra thị trường bộ chuyển mạch silicon photonics Quantum-X (InfiniBand) vào cuối năm 2025 và sau đó là bộ chuyển mạch Specturm-X (Ethernet) vào nửa cuối năm 2026.
Không cần bộ thu phát – kết nối trực tiếp bằng cáp quang. Tối đa 512 cổng trên bộ chuyển mạch Spectrum-X.
Một trung tâm dữ liệu có thể thêm 10 giá đỡ Rubin Ultra để tiết kiệm 6 MW.
 Lộ trình của NVIDIA
Lộ trình của NVIDIA
Mỗi năm một nền tảng mới.
Thế hệ GPU tiếp theo sau Rubin là gì? Đó chính là Richard Feynman huyền thoại.
Bây giờ chuyển sang hệ thống.
100% kỹ sư phần mềm NVIDIA sẽ được hỗ trợ bởi AI vào cuối năm nay. Chúng ta cần một dòng máy tính mới.
Công bố DGX Spark. Đây là tên cuối cùng của mini-PC Project DIGITS mà NVIDIA đã công bố trước đó.
Thật không may, có vẻ như đường truyền phát trực tiếp vừa bị hỏng… Chờ.
 NVIDIA DGX Spark
NVIDIA DGX Spark
Sau vài phút gián đoạn, chúng tôi đã trở lại.
DGX Spark và trạm DGX.
 DGX Station
DGX Station
GPU cũng tăng tốc lưu trữ. NVIDIA đã làm việc với tất cả các nhà cung cấp lưu trữ lớn.
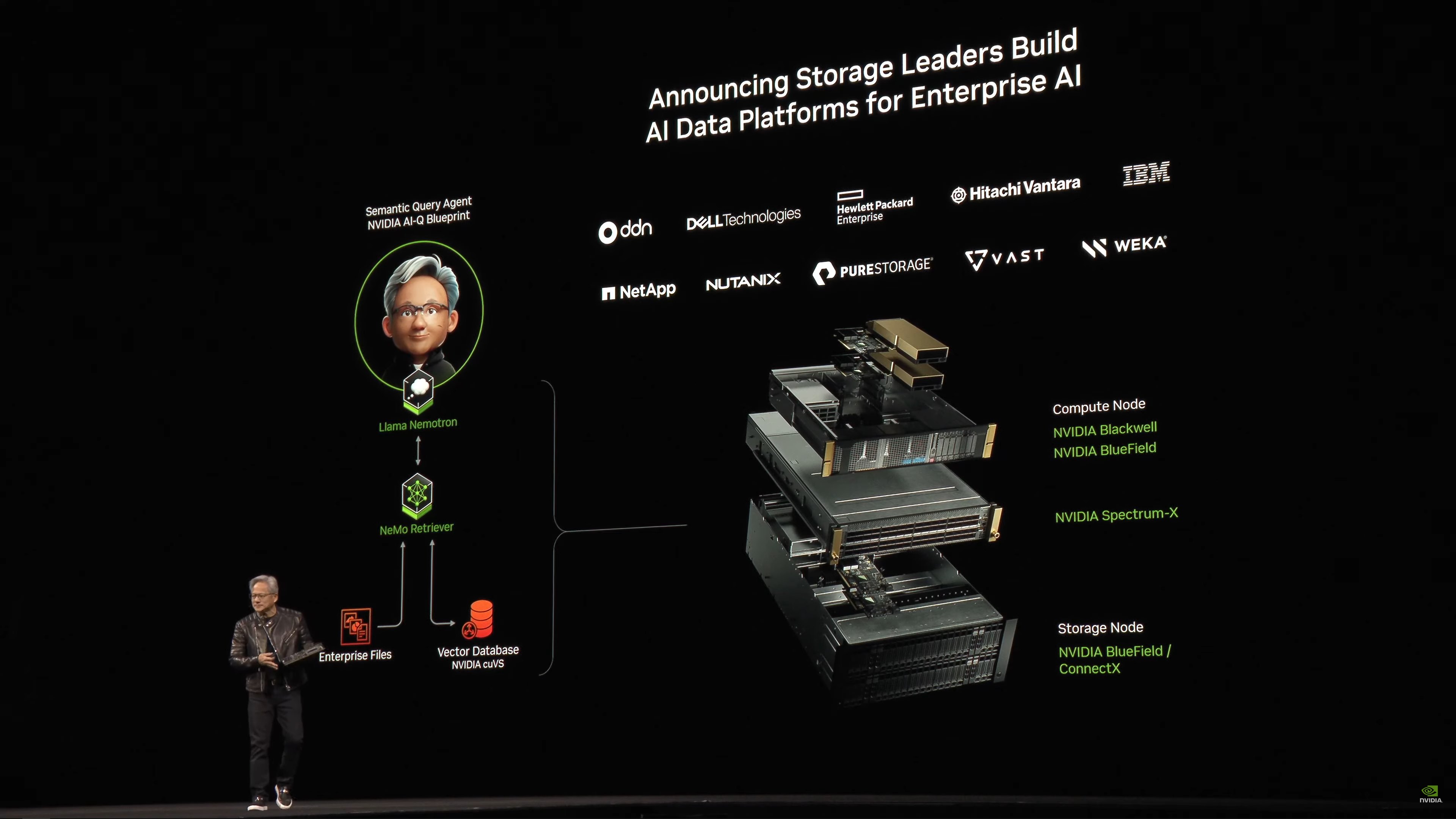 Hệ thống lưu trữ được tăng tốc bởi GPU
Hệ thống lưu trữ được tăng tốc bởi GPU
Dell sẽ cung cấp toàn bộ dòng hệ thống dựa trên NVIDIA.
NVIDIA cũng đang công bố một mô hình nguồn mở mới: NVIDIA Nemo Llame Nemotron Reasoning.
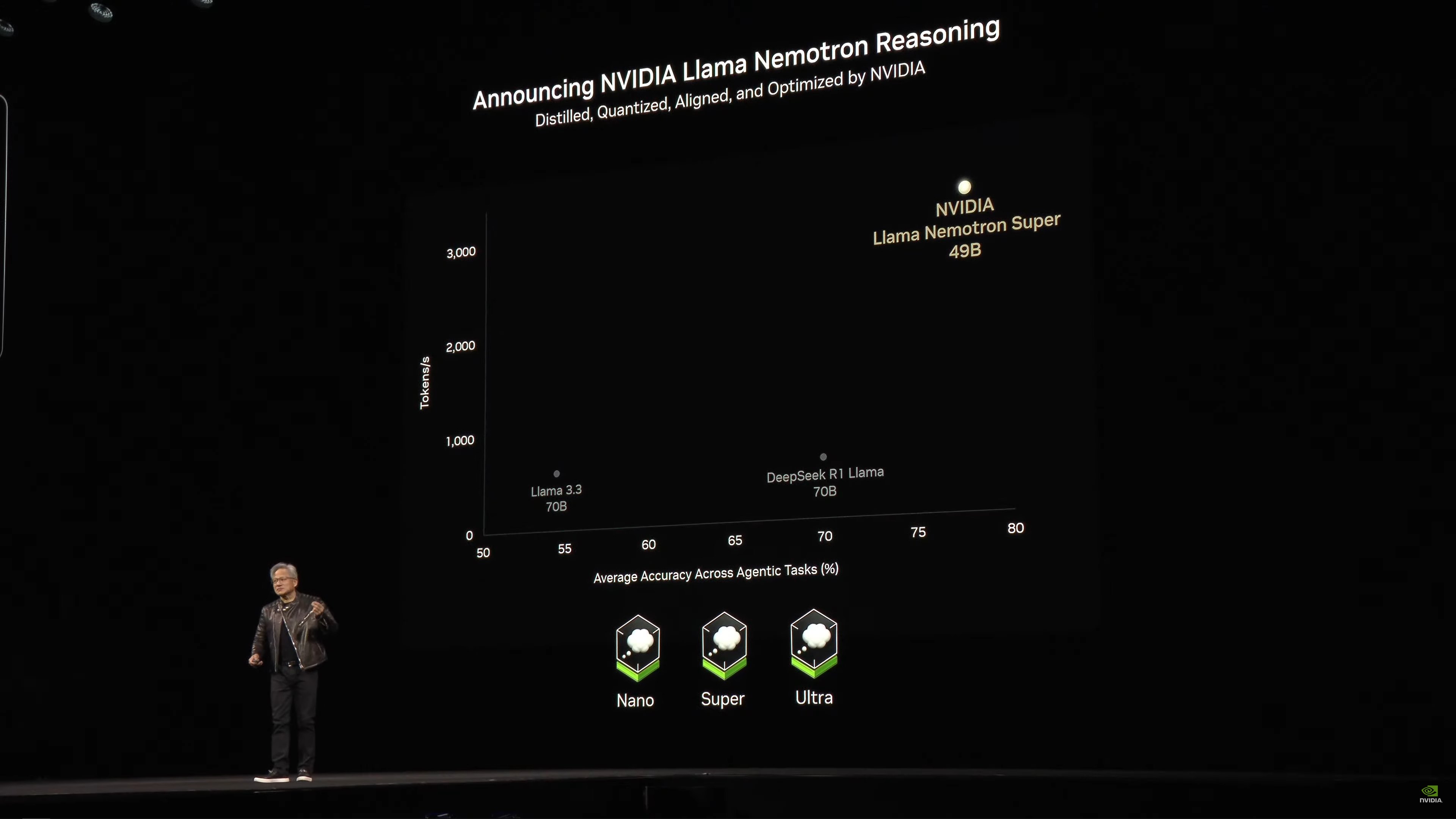 Llama Nemotron
Llama Nemotron
Bây giờ chúng ta sẽ nhanh chóng xem qua các slide về tất cả khách hàng của NVIDIA đang tích hợp công nghệ NVIDIA vào khuôn khổ của họ.
Bây giờ đến phần robot.
“Thế giới đang thiếu hụt nghiêm trọng nguồn lao động”
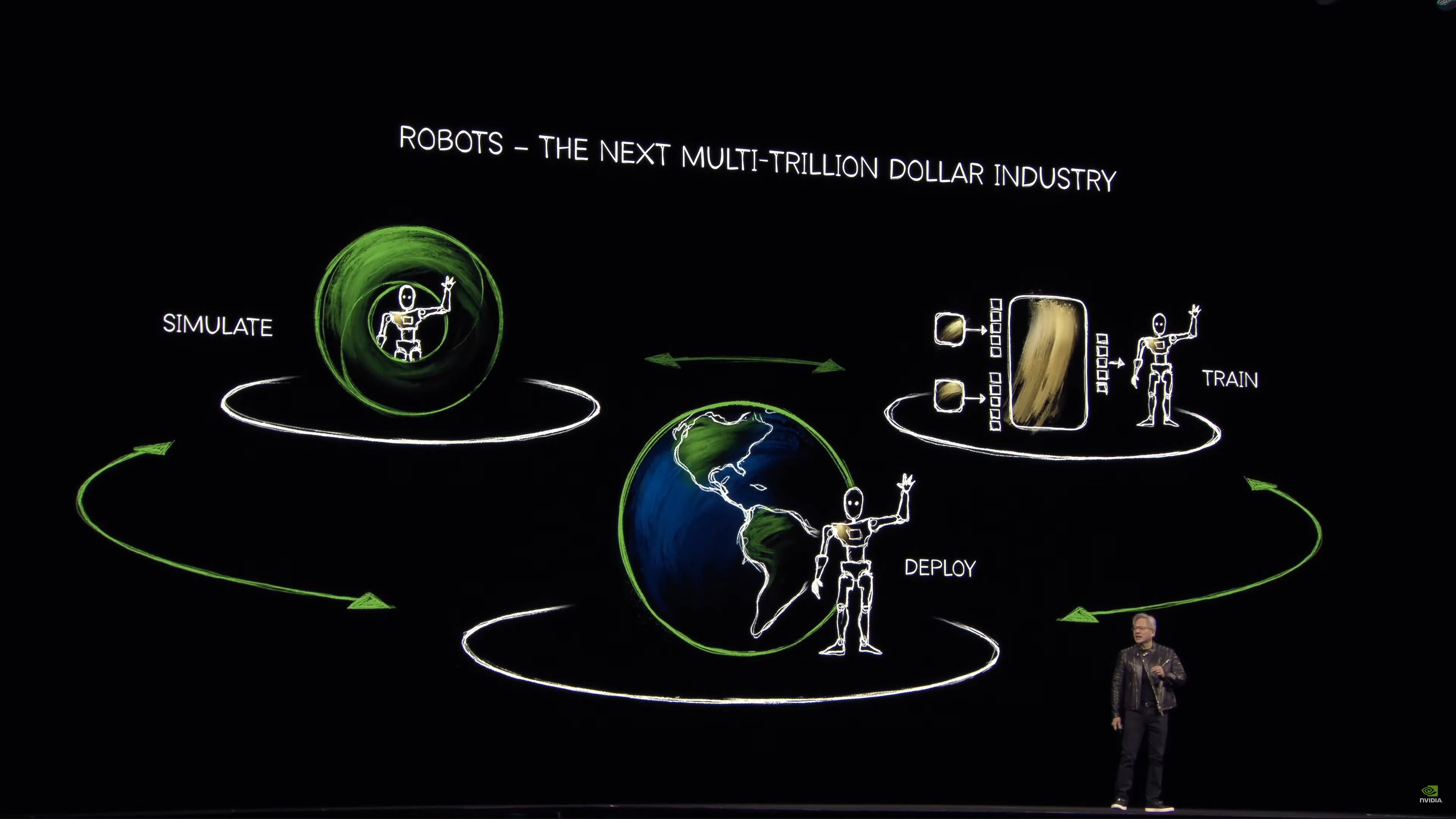 Kỳ vọng từ NVIDIA Robotics
Kỳ vọng từ NVIDIA Robotics
Bây giờ chúng ta sẽ xem một video về robot.
Những robot đó sẽ được đào tạo thông qua mô phỏng AI về thế giới vật lý.
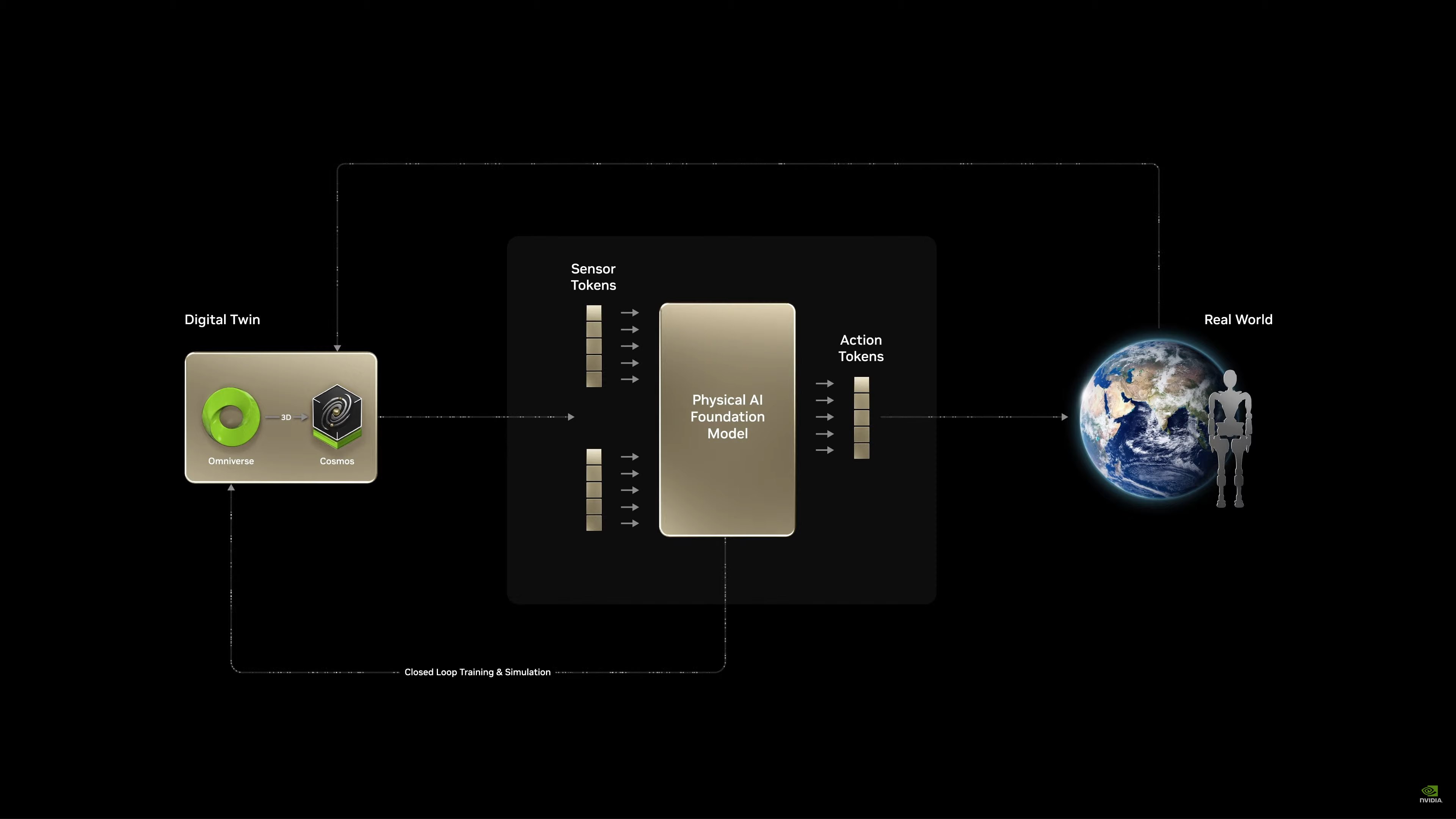 Quy trình làm việc của NVIDIA Robotics
Quy trình làm việc của NVIDIA Robotics
 Đào tạo Robot hình người
Đào tạo Robot hình người
Phần lớn video này là tóm tắt lại những gì NVIDIA đã thảo luận trước đó. Sử dụng bản sao kỹ thuật số để tạo ra một cơ sở ảo giúp đào tạo robot. (Khi robot mắc lỗi trong thế giới ảo, không có gì bị hỏng)
Giới thiệu NVIDIA Isaac GROOT N1.
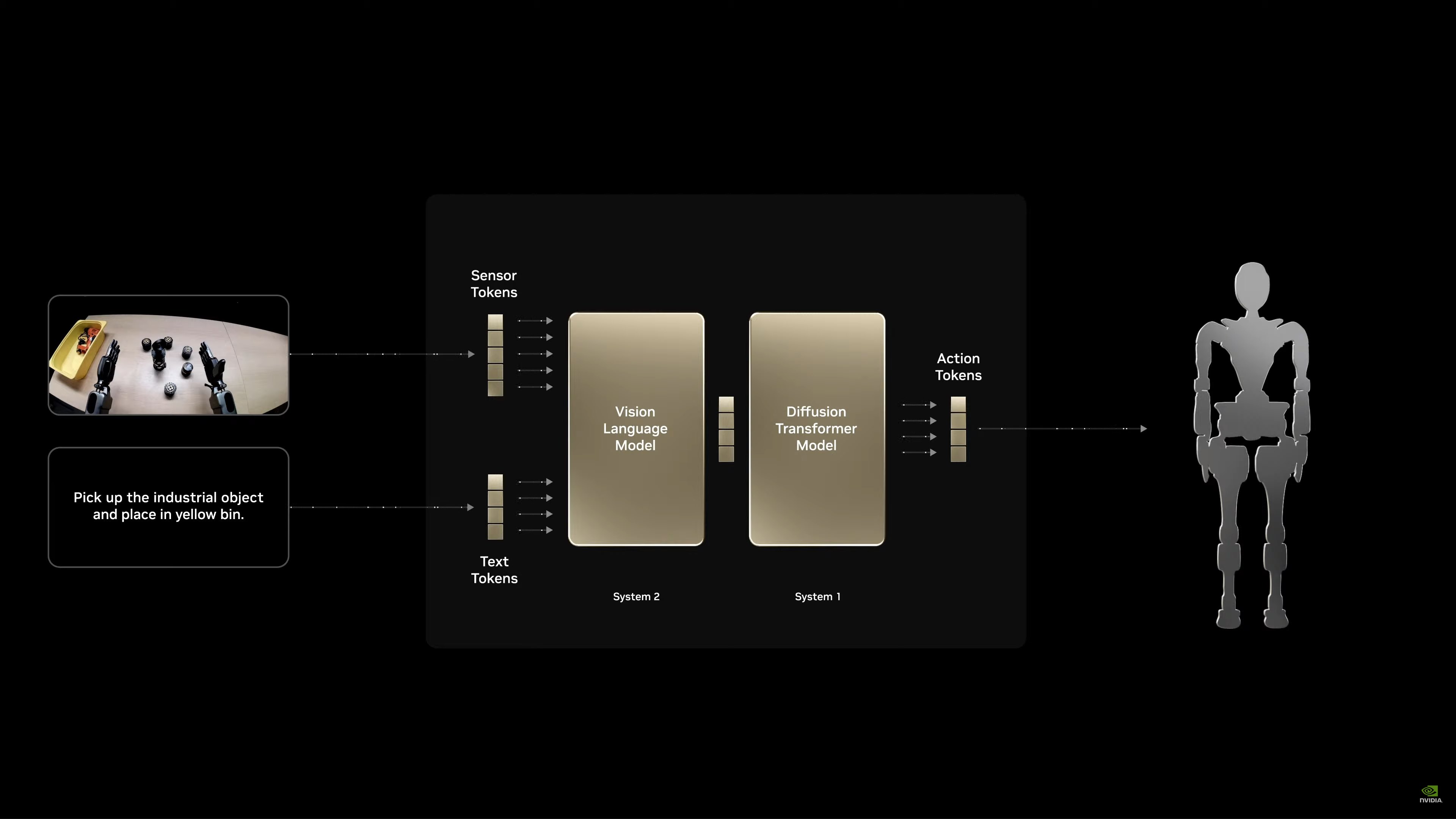 NVIDIA Isaac GROOT N1
NVIDIA Isaac GROOT N1
 Mô phỏng Groot N1
Mô phỏng Groot N1
“AI vật lý và robot đang phát triển rất nhanh. Mọi người đều chú ý đến không gian này. Đây rất có thể là ngành công nghiệp lớn nhất trong tất cả.”
Jensen đang tóm tắt cách hoạt động của mô phỏng Omniverse + Cosmos. Sử dụng Cosmos để tạo ra nhiều môi trường khác nhau để hỗ trợ đào tạo.
Phần thưởng có thể xác minh được trong robot là gì? Vật lý. Nếu một robot hành xử theo cách vật lý chính xác, thì điều đó có thể được xác minh là chính xác.
Bây giờ chúng ta sẽ xem một video khác, lần này là về một công cụ vật lý mới có tên là Newton.
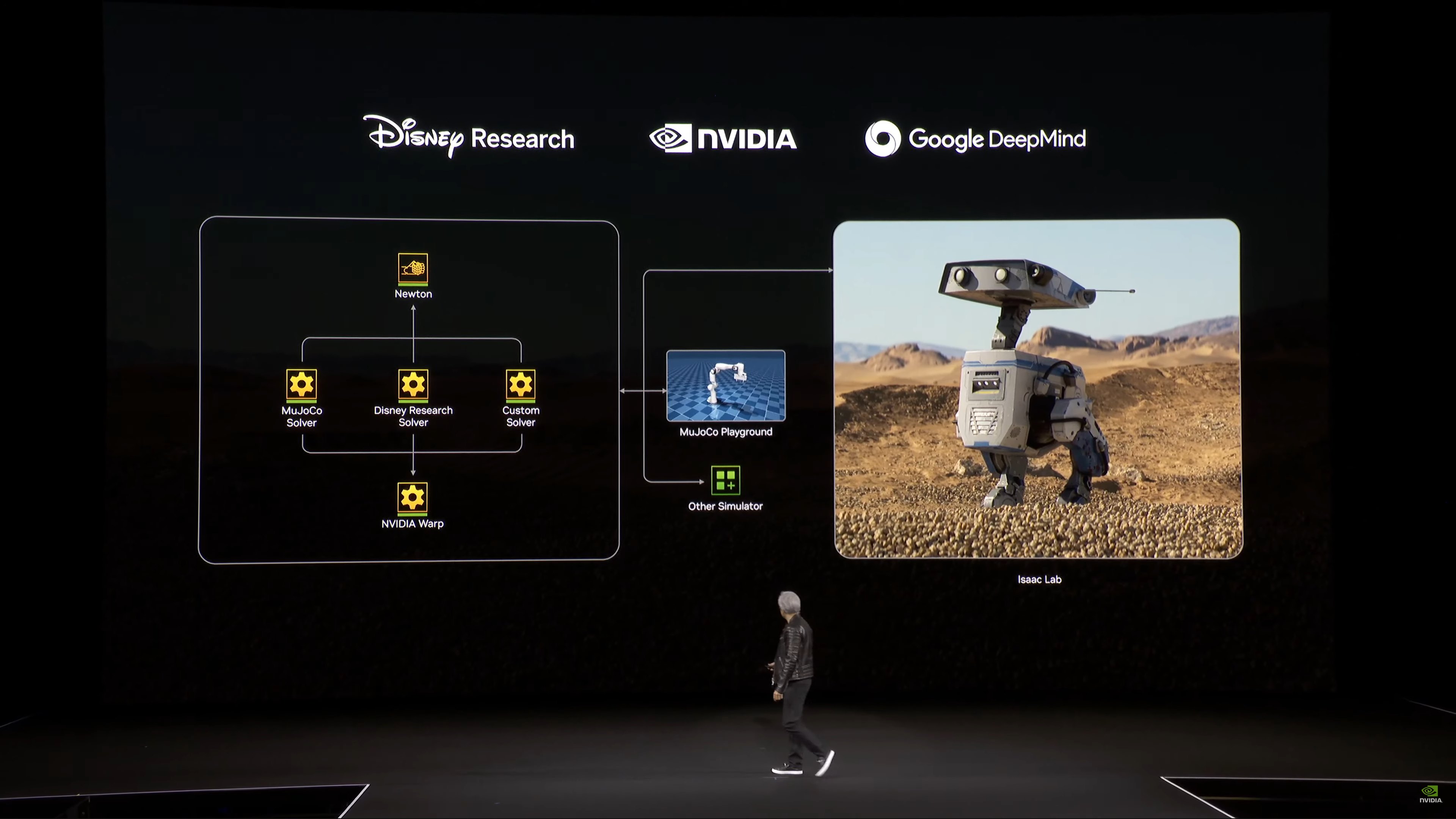 Động cơ vật lý Newton
Động cơ vật lý Newton
 Đoạn phim giới thiệu Newton
Đoạn phim giới thiệu Newton
 Robot “Xanh”
Robot “Xanh”
Chuyển từ kỹ thuật số sang thực tế. Robot trong video, Blue, là một robot thực sự.
“Chúng ta hãy kết thúc bài phát biểu quan trọng này. Giờ ăn trưa đã đến rồi”
Hôm nay cũng thông báo rằng Gr00t N1 là mã nguồn mở.
Bây giờ chúng ta kết thúc mọi việc.
 Tổng kết GTC 2025
Tổng kết GTC 2025
Blackwell đang trong giai đoạn tăng tốc, nhưng NVIDIA đã để mắt tới Blackwell Ultra vào cuối năm 2025, Vera Rubin vào năm 2026, Rubin Ultra vào năm 2027 và Feynman vào năm 2028.
Thêm một điều thú vị nữa:
 Video phát biểu quan trọng của GTC
Video phát biểu quan trọng của GTC
Và đến đây là hết. Cảm ơn bạn đã tham gia blog trực tiếp của chúng tôi về bài phát biểu quan trọng của GTC 2025.
Lời cuối cùng
Trong khi phân khúc kinh doanh GPU quan trọng của NVIDIA hiện đang ở giữa thế hệ, GTC 2025 đang khẳng định rõ ràng rằng nó không ngăn cản phần còn lại của công ty tiến lên hết tốc lực. Nhìn vào một thế giới mà công ty kỳ vọng nhu cầu về phần cứng AI sẽ tăng trưởng hơn nữa nhờ các mô hình lý luận chuyên sâu về tính toán, NVIDIA đang tiến lên trên cả mặt trận phần cứng và phần mềm để cung cấp các công cụ mới và hiệu suất tốt hơn. Và cuối cùng là hiệu quả năng lượng cao hơn cho một thời đại kinh doanh đang trở nên hạn chế hơn về năng lượng.
Về mặt phần cứng, trong khi Blackwell về mặt kỹ thuật vẫn đang trong quá trình tăng tốc, NVIDIA đã để mắt đến những gì tiếp theo. Và trong nửa cuối năm 2025, đó sẽ là GPU B300 Blackwell Ultra lớn hơn và tốt hơn, đây là sản phẩm thế hệ giữa của gia đình Blackwell được cho là sẽ mang lại hiệu suất được cải thiện. Thông tin chi tiết từ NVIDIA vẫn còn ít ỏi, nhưng điểm bán hàng chính của nó là, đối với một gói GPU duy nhất, hiệu suất FP4 tốt hơn 50% (15TFLOPS) và hỗ trợ 288GB bộ nhớ HBM3e trên gói, cải thiện 50% so với GPU B200. Giống như người tiền nhiệm của nó, đây là chip hai đế, với hai GPU “kích thước lưới” được đóng gói trong một đế duy nhất.
Blackwell Ultra, đến lượt nó, cũng sẽ được sử dụng để xây dựng siêu chip Grace Blackwell GB300 mới hơn, được sử dụng làm khối xây dựng cho các sản phẩm NVIDIA tiếp theo, đáng chú ý nhất là hệ thống rack Blackwell Ultra NVL72, để tăng cường cho sản phẩm GB200 NVL72 hiện tại của NVIDIA.
Trong khi đó, NVIDIA cũng lần đầu tiên cung cấp lộ trình phần cứng mới cho công ty, đưa công ty đến năm 2028. Họ nhận thấy rằng NVIDIA hiện là một công ty lớn với khách hàng cần đầu tư lớn vào phần cứng và dòng sản phẩm của công ty, NVIDIA hiện đang hướng đến mục tiêu minh bạch hơn về các kế hoạch phần cứng trong tương lai của mình – ít nhất là ở cấp độ rất cao với tên sản phẩm và một số thông số kỹ thuật rất cơ bản.
Để đạt được mục đích đó, vào nửa cuối năm 2026, chúng ta sẽ thấy sự ra mắt của CPU Arm thế hệ tiếp theo của NVIDIA, có tên mã là Vera, trong khi phía GPU sẽ cung cấp kiến trúc GPU Rubin. Cuối năm 2027, họ Rubin sẽ được làm mới với Rubin Ultra, một GPU 4 die. Và năm 2028, CPU Vera sẽ được ghép nối với GPU dựa trên kiến trúc GPU Feynman mới được công bố, kiến trúc này sẽ sử dụng công nghệ bộ nhớ thế hệ tiếp theo (sau HBM4e?).
Đối với mảng kinh doanh network của NVIDIA, nhóm Mellanox trước đây sẽ tăng cường nỗ lực AI của NVIDIA bằng cách giới thiệu silicon photonics đồng đóng gói vào các hệ thống switch của NVIDIA. Được thiết kế để cắt giảm lượng điện năng cần thiết cho mạng bằng cách loại bỏ các bộ thu phát quang chuyên dụng, NVIDIA sẽ sử dụng silicon photonics để điều khiển trực tiếp hơn các tia laser cần thiết. Nửa cuối năm 2025 sẽ chứng kiến sự ra mắt của dòng switch Quantum-X (InfiniBand), trong khi nửa cuối năm 2026 sẽ mang đến một bộ đôi switch Spectrum-X (Ethernet) sử dụng công nghệ này. Nhìn chung, NVIDIA kỳ vọng rằng khách hàng sẽ có thể tái đầu tư khoản tiết kiệm điện năng từ các bộ switch silicon photonics của họ vào việc mua và cài đặt thêm các hệ thống GPU.
Và cuối cùng nhưng không kém phần quan trọng, NVIDIA có mặt tại triển lãm với một số thông báo về phần mềm. Dynamo hứa hẹn sẽ giúp cân bằng tải và tối ưu hóa việc thực hiện suy luận trên các hệ thống GPU lớn, giúp khách hàng là nhà cung cấp dịch vụ của NVIDIA cân bằng thông lượng với khả năng phản hồi để tối đa hóa khối lượng công việc – và doanh thu – mà họ nhận được từ các dịch vụ GPU cho thuê của mình. Trong khi đó, các dịch vụ khác như GR00T N1 và Llama Nemotron lần lượt nhắm vào cộng đồng robot và AI.
Tổng hợp từ STH
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale