

Tính khả dụng và kết quả điểm chuẩn hàng đầu
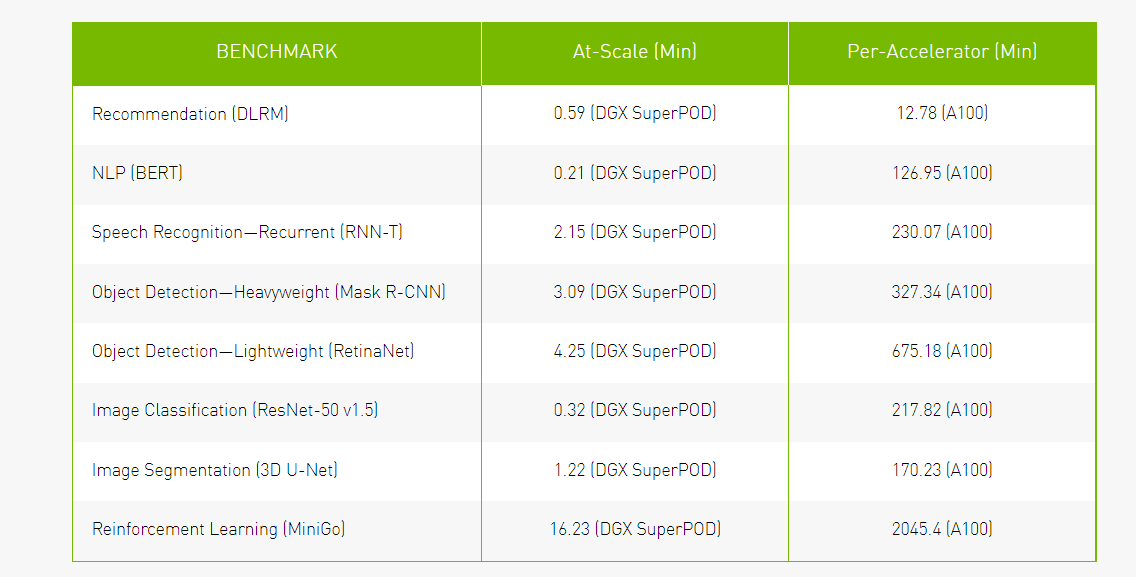
Trong lần đệ trình Đào tạo MLPerf thứ tư liên tiếp, GPU NVIDIA A100 Tensor Core dựa trên kiến trúc NVIDIA Ampere tiếp tục nổi trội.

Selene – siêu máy tính AI nội bộ của chúng tôi dựa trên NVIDIA DGX SuperPOD mô-đun và được hỗ trợ bởi GPU NVIDIA A100, ngăn xếp phần mềm NVIDIA Stack và mạng NVIDIA InfiniBand – đã xuất hiện trong thời gian nhanh nhất để đào tạo bốn trong số tám bài kiểm tra.

NVIDIA A100 cũng tiếp tục dẫn đầu trên mỗi chip, chứng tỏ tốc độ nhanh nhất trong sáu trong số tám bài kiểm tra. Tổng cộng có 16 đối tác đã gửi kết quả trong vòng này bằng cách sử dụng nền tảng NVIDIA AI. Chúng bao gồm ASUS, Baidu, CASIA (Viện Tự động hóa, Viện Khoa học Trung Quốc), Dell Technologies, Fujitsu, GIGABYTE, H3C, Hewlett Packard Enterprise, Inspur, KRAI, Lenovo, Microsoft Azure, MosaicML, Nettrix và Supermicro.

Hầu hết các đối tác OEM của NVIDIA đã gửi kết quả bằng Hệ thống được chứng nhận của NVIDIA, các máy chủ được xác nhận bởi NVIDIA để cung cấp hiệu suất tuyệt vời, khả năng quản lý, bảo mật và khả năng mở rộng cho việc triển khai doanh nghiệp.
Nhiều mô hình cung cấp sức mạnh thực sự cho các ứng dụng AI
Một ứng dụng AI có thể cần hiểu yêu cầu bằng giọng nói của người dùng, phân loại hình ảnh, đưa ra đề xuất và gửi phản hồi dưới dạng tin nhắn nói.

Các tác vụ này yêu cầu nhiều loại mô hình AI hoạt động theo trình tự, còn được gọi là đường ống. Người dùng cần thiết kế, đào tạo, triển khai và tối ưu hóa các mô hình này một cách nhanh chóng và linh hoạt.
Đó là lý do tại sao cả tính linh hoạt – khả năng chạy mọi mô hình trong MLPerf và hơn thế nữa – cũng như hiệu suất hàng đầu đều rất quan trọng để đưa AI trong thế giới thực vào sản xuất.
Cung cấp ROI với AI
Đối với khách hàng, nhóm kỹ thuật và khoa học dữ liệu là tài nguyên quý giá nhất của họ và năng suất của họ quyết định lợi tức đầu tư cho cơ sở hạ tầng AI. Khách hàng phải xem xét chi phí của các nhóm khoa học dữ liệu đắt đỏ, vốn thường đóng một phần đáng kể trong tổng chi phí triển khai AI, cũng như chi phí tương đối nhỏ cho việc triển khai cơ sở hạ tầng AI.
Năng suất của nhà nghiên cứu AI phụ thuộc vào khả năng nhanh chóng thử nghiệm các ý tưởng mới, đòi hỏi cả tính linh hoạt để đào tạo bất kỳ mô hình nào cũng như tốc độ có được khi đào tạo các mô hình đó ở quy mô lớn nhất. nền tảng – một cái nhìn toàn diện hơn thể hiện chính xác hơn chi phí thực sự của việc triển khai AI.
Ngoài ra, việc sử dụng cơ sở hạ tầng AI của họ dựa vào khả năng thay thế của nó hoặc khả năng tăng tốc toàn bộ quy trình làm việc của AI – từ chuẩn bị dữ liệu đến đào tạo đến suy luận – trên một nền tảng duy nhất.

Với NVIDIA AI, khách hàng có thể sử dụng cùng một cơ sở hạ tầng cho toàn bộ hệ thống AI, định vị lại nó để phù hợp với các nhu cầu khác nhau giữa chuẩn bị, đào tạo và suy luận dữ liệu, giúp tăng đáng kể việc sử dụng, dẫn đến ROI rất cao. Và khi các nhà nghiên cứu khám phá ra những đột phá mới của AI, việc hỗ trợ các cải tiến mô hình mới nhất là chìa khóa để tối đa hóa tuổi thọ hữu ích của cơ sở hạ tầng AI.
NVIDIA AI mang lại năng suất cao nhất trên mỗi đô la vì nó phổ biến và hiệu quả cho mọi mô hình, mở rộng đến bất kỳ kích thước nào và tăng tốc AI từ đầu đến cuối – từ chuẩn bị dữ liệu đến đào tạo đến suy luận. Kết quả hôm nay cung cấp minh chứng mới nhất về chuyên môn AI sâu rộng của NVIDIA được thể hiện trong mọi khóa đào tạo, suy luận và HPC của MLPerf cho đến nay.
Hiệu suất gấp 23 lần trong 3,5 năm
Trong hai năm kể từ lần gửi MLPerf đầu tiên của chúng tôi với A100, nền tảng của chúng tôi đã mang lại hiệu suất gấp 6 lần. Các tối ưu hóa liên tục cho ngăn xếp phần mềm của chúng tôi đã giúp thúc đẩy những lợi ích đó.
Kể từ khi MLPerf ra đời, nền tảng NVIDIA AI đã mang lại hiệu suất cao hơn 23 lần trong 3,5 năm theo tiêu chuẩn – kết quả của sự đổi mới toàn ngăn xếp bao gồm GPU, phần mềm và các cải tiến trên quy mô lớn. Chính cam kết đổi mới liên tục này đảm bảo với khách hàng rằng nền tảng AI mà họ đầu tư vào ngày hôm nay và duy trì hoạt động trong 3 đến 5 năm, sẽ tiếp tục phát triển để hỗ trợ nền tảng tiên tiến nhất.
Ngoài ra , kiến trúc NVIDIA Hopper , được công bố vào tháng 3, hứa hẹn một bước nhảy vọt khác về hiệu suất trong các vòng MLPerf trong tương lai.
NVIDIA đã làm điều này như thế nào?
Sự đổi mới phần mềm tiếp tục mang lại hiệu suất cao hơn trên kiến trúc NVIDIA Ampere .Ví dụ: Đồ thị CUDA – phần mềm giúp giảm thiểu chi phí khởi chạy đối với các công việc chạy trên nhiều trình tăng tốc – được sử dụng rộng rãi trong các bài nộp của chúng tôi. Các hạt nhân được tối ưu hóa trong các thư viện của chúng tôi như cuDNN và tiền xử lý trong DALI đã mở khóa tốc độ bổ sung. Chúng tôi cũng triển khai các cải tiến toàn diện trên phần cứng, phần mềm và mạng như NVIDIA Magnum IO và SHARP, giúp giảm tải một số chức năng AI vào mạng để thúc đẩy hiệu suất cao hơn nữa, đặc biệt là ở quy mô lớn.
Tất cả phần mềm chúng tôi sử dụng đều có sẵn từ kho lưu trữ MLPerf, vì vậy mọi người đều có thể nhận được kết quả đẳng cấp thế giới của chúng tôi. Chúng tôi liên tục gấp những tối ưu hóa này vào các vùng chứa có sẵn trên NGC , trung tâm phần mềm của chúng tôi dành cho các ứng dụng GPU và cung cấp NVIDIA AI Enterprise để cung cấp phần mềm được tối ưu hóa, được NVIDIA hỗ trợ đầy đủ.
Hai năm sau khi ra mắt A100, nền tảng NVIDIA AI tiếp tục mang lại hiệu suất cao nhất trong MLPerf 2.0 và là nền tảng duy nhất có thể đáp ứng mọi tiêu chuẩn. Kiến trúc Hopper thế hệ tiếp theo của chúng tôi hứa hẹn một bước nhảy vọt khổng lồ khác trong các vòng MLPerf trong tương lai. Nền tảng của NVIDIA là phổ biến cho mọi mô hình và khuôn khổ ở mọi quy mô và cung cấp khả năng thay thế để xử lý mọi phần của khối lượng công việc AI. Nó có sẵn từ mọi nhà sản xuất máy chủ và đám mây lớn.
→ Tìm hiểu thêm về hiệu suất của đào tạo và suy luận trung tâm dữ liệu của NVIDIA tại đây
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale