Việc sử dụng các tầng lưu trữ khác nhau trong kiến trúc lưu trữ dữ liệu có giá trị rất lớn để đảm bảo rằng các tập dữ liệu khác nhau của bạn được lưu trữ trên loại công nghệ thích hợp. Bài viết này sẽ giới thiệu cách hệ thống Cloudian HyperStore hỗ trợ lưu trữ đối tượng với khả năng ‘tự động phân cấp’ (auto-tiering), theo đó các đối tượng có thể được tự động dịch chuyển từ bộ lưu trữ HyperStore cục bộ sang hệ thống lưu trữ đích theo lịch trình được xác định trước dựa trên chính sách vòng đời dữ liệu (data lifecycle policies).
Cloudian HyperStore có thể được tích hợp với bất kỳ nền tảng lưu trữ đám mây đích nào sau đây làm mục tiêu cho dữ liệu theo tầng:
- Amazon S3
- Amazon Glacier
- Google Cloud Platform
- Dịch vụ Any Cloud cung cấp kết nối API S3
- Một cụm Cloudian HyperStore được đặt ở xa
Kiểm soát sát sao với Cloudian HyperStore
Đối với bất kỳ hệ thống lưu trữ dữ liệu nào, mức độ chi tiết của việc kiểm soát và quản lý là cực kỳ quan trọng – các tập dữ liệu thường có các yêu cầu quản lý khác nhau với nhu cầu áp dụng các Thỏa thuận cấp dịch vụ (SLA) khác nhau sao cho phù hợp với giá trị của dữ liệu đối với một doanh nghiệp, tổ chức.

Cloudian HyperStore cung cấp khả năng quản lý dữ liệu ở cấp độ bucket (một khái niệm trong kiến trúc lưu trữ đối tượng), cung cấp tính linh hoạt ở cấp độ chi tiết để cho phép kiểm soát SLA và quản trị (lưu ý: một “bucket” là bộ chứa dữ liệu S3, tương tự như LUN trong hệ thống lưu trữ SAN hoặc File System trong hệ thống NAS). HyperStore cung cấp các thông số kiểm soát sau đây ở cấp độ bucket:
- Bảo vệ dữ liệu – Chọn từ mã hóa replication hoặc xóa dữ liệu, cộng với phân phối dữ liệu đơn hoặc đa site
- Mức độ nhất quán – Kiểm soát các kỹ thuật replication (đồng bộ so với không đồng bộ)
- Quyền truy cập – Kiểm soát quyền truy cập của người dùng và nhóm vào dữ liệu
- Khôi phục sau thảm họa – Sao chép dữ liệu lên đám mây công cộng
- Encryption – Bảo vệ dữ liệu ở trạng thái nghỉ để tuân thủ bảo mật
- Compression – Giảm dung lượng lưu trữ thô hiệu quả được sử dụng để lưu trữ các đối tượng dữ liệu
- Data size threshold – Vị trí lưu trữ dữ liệu thay đổi dựa trên kích thước đối tượng dữ liệu
- Lifecycle Policies – Quy tắc quản lý dữ liệu để phân tầng và hết hạn dữ liệu
Cloudian HyperStore quản lý phân tầng dữ liệu thông qua các chính sách vòng đời như có thể thấy trong hình bên dưới:
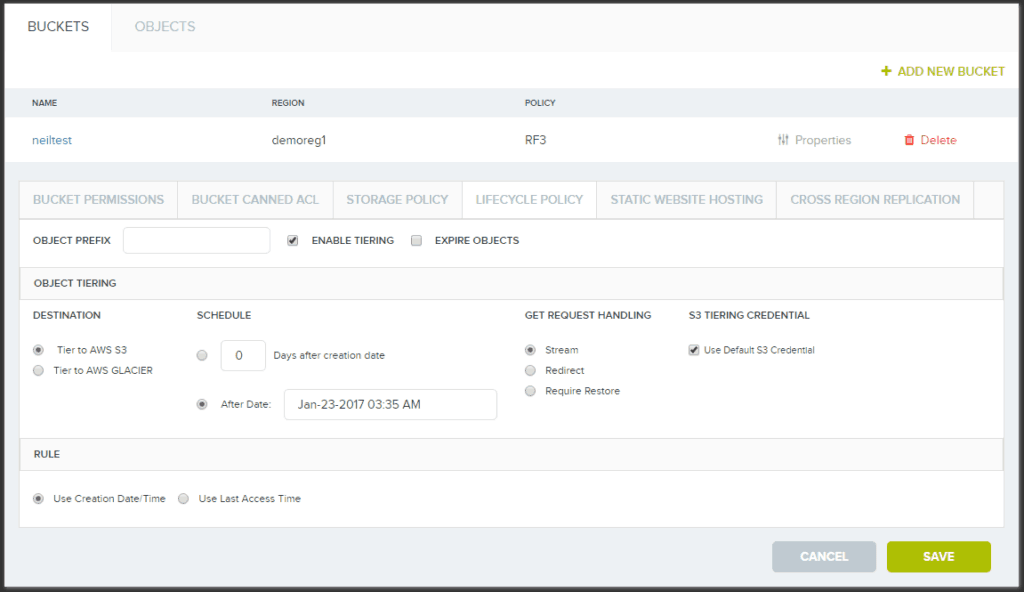
Tự động phân cấp có thể định cấu hình trên cơ sở từng nhóm, với mỗi nhóm cho phép các chính sách vòng đời khác nhau dựa trên các quy tắc. Ví dụ về những điều này bao gồm:
1. Đối tượng dữ liệu nào sẽ áp dụng quy tắc vòng đời. Điều này có thể bao gồm:
- Tất cả các đối tượng trong bucket
- Các đối tượng mà tên bắt đầu bằng một prefix cụ thể (chẳng hạn như “Cuộc họp/2015/”)
2. Lịch phân tầng, có thể được chỉ định bằng một trong ba phương pháp:
- Di chuyển các đối tượng X số ngày sau khi chúng được tạo
- Di chuyển các đối tượng nếu chúng trải qua X số ngày mà không được truy cập
- Di chuyển các đối tượng vào một ngày cố định — chẳng hạn như ngày 31 tháng 12 năm 2016
Khi một đối tượng dữ liệu trở thành một ứng viên cho việc phân tầng, một đối tượng gốc nhỏ được giữ lại trên cụm HyperStore. Dữ liệu gốc hoạt động như một con trỏ tới đối tượng dữ liệu thực tế, vì vậy đối tượng dữ liệu vẫn xuất hiện như thể nó được lưu trữ trong cụm cục bộ. Đối với người dùng cuối, không có thay đổi nào đối với việc truy cập dữ liệu, nhưng đối tượng sẽ hiển thị một biểu tượng đặc biệt cho biết thực tế là đối tượng dữ liệu đã được di chuyển.
Để tự động phân cấp đến nhà cung cấp dịch vụ đám mây như Amazon hoặc Google, cần có tài khoản cùng với thông tin xác thực quyền truy cập tài khoản được liên kết.
Truy cập dữ liệu sau khi được tự động phân tầng
Để truy cập các đối tượng sau khi chúng được tự động phân tầng đến các dịch vụ đám mây công cộng, các đối tượng có thể được truy cập trực tiếp thông qua nền tảng đám mây công cộng (sử dụng tài khoản và thông tin đăng nhập hiện hành) hoặc qua hệ thống HyperStore cục bộ. Có ba tùy chọn để truy xuất dữ liệu theo tầng:
1. Khôi phục đối tượng – Khi người dùng truy cập tệp dữ liệu, họ sẽ được chuyển hướng đến tệp gốc cục bộ được lưu trữ trên HyperStore, sau đó chuyển hướng yêu cầu người dùng đến vị trí thực tế của đối tượng dữ liệu (nền tảng đích được phân cấp).
Một bản sao của đối tượng dữ liệu được khôi phục trở lại bộ chứa HyperStore cục bộ từ bộ lưu trữ theo tầng và yêu cầu của người dùng sẽ được thực hiện trên đối tượng dữ liệu sau khi được sao chép trở lại. Có thể đặt giới hạn thời gian trong bao lâu để giữ lại đối tượng đã truy xuất cục bộ, trước khi quay lại tầng phụ.
Đây được coi là tùy chọn tốt nhất để sử dụng khi truy cập dữ liệu tương đối thường xuyên và bạn muốn tránh bất kỳ tác động nào đến hiệu suất phát sinh khi truy cập internet và mọi chi phí truy cập do nhà cung cấp dịch vụ áp dụng cho việc truy cập/truy xuất dữ liệu. Dung lượng lưu trữ phải được quản lý trên cụm HyperStore cục bộ để đảm bảo rằng có đủ “bộ nhớ đệm” để truy xuất đối tượng.
2. Truyền đối tượng – Truyền phát dữ liệu trực tiếp đến máy khách mà không cần khôi phục dữ liệu về cụm HyperStore cục bộ trước. Khi đóng tệp, mọi sửa đổi được thực hiện đối với đối tượng tại chỗ trên vị trí theo tầng. Mọi sửa đổi siêu dữ liệu sẽ được cập nhật trong cả cơ sở dữ liệu HyperStore cục bộ và trên nền tảng theo tầng.
Đây được coi là tùy chọn tốt nhất để sử dụng khi truy cập dữ liệu tương đối không thường xuyên và những lo ngại về dung lượng lưu trữ của cụm HyperStore cục bộ là một vấn đề, nhưng hiệu suất sẽ thấp hơn do các yêu cầu dữ liệu đi qua internet và dịch vụ có thể áp dụng phí truy cập nhà cung cấp mỗi khi tệp này được đọc.
3. Truy cập trực tiếp – Các đối tượng được tự động phân tầng cho các dịch vụ đám mây công cộng có thể được truy cập trực tiếp bởi một ứng dụng khác hoặc thông qua giao diện đám mây công cộng tiêu chuẩn của bạn, chẳng hạn như Bảng điều khiển quản lý AWS. Phương pháp này hoàn toàn bỏ qua cụm HyperStore. Bởi vì các đối tượng được ghi vào đám mây bằng cách sử dụng API S3 tiêu chuẩn và bao gồm một bản sao siêu dữ liệu của đối tượng, nên chúng có thể được tham chiếu trực tiếp.
Lưu trữ các đối tượng theo cách có thể truy cập mở này — với siêu dữ liệu phong phú được đặt cùng vị trí — rất hữu ích trong một số trường hợp:
- Kịch bản khắc phục thảm họa khi cụm HyperStore không khả dụng
- Tạo điều kiện di chuyển dữ liệu sang nền tảng khác
- Cho phép truy cập từ một ứng dụng dựa trên đám mây riêng biệt, chẳng hạn như phân phối nội dung
- Cung cấp quyền truy cập mở vào dữ liệu mà không phụ thuộc vào cơ sở dữ liệu riêng biệt để cung cấp chỉ mục
HyperStore cung cấp tính linh hoạt tuyệt vời để tận dụng triển khai hybrid cloud nơi bạn có thể đặt chính sách lưu trữ dữ liệu trong đám mây công cộng hoặc riêng tư. Tìm hiểu thêm về HyperStore tại đây.
Bài viết liên quan
- Các câu hỏi thường gặp về Data Lake
- Xây dựng giải pháp Data Lake cho khối truyền hình và nội dung số với Cloudian và SME
- NAS vs. Object Storage: Giải pháp nào tốt nhất cho việc lưu trữ dữ liệu phi cấu trúc?
- Đặc tính đa khách hàng trong giải pháp lưu trữ cloud
- Storage-as-a-Service: Nguồn doanh thu rạo ra lợi nhuận cho các nhà cung cấp dịch vụ đám mây