
Hợp tác với OpenAI, NVIDIA đã tối ưu hóa các mô hình mở gpt-oss mới của công ty cho GPU NVIDIA, mang lại khả năng suy luận hiệu quả và nhanh chóng, từ đám mây đến cả các PC tại bàn làm việc. Các mô hình suy luận mới này cho phép các ứng dụng AI như tìm kiếm web, nghiên cứu chuyên sâu và nhiều ứng dụng khác.
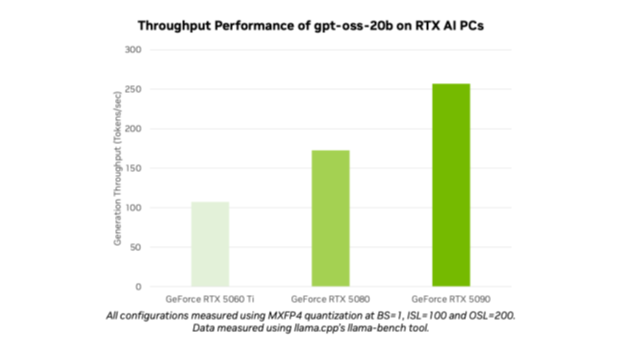
Với việc ra mắt gpt-oss-20b và gpt-oss-120b, OpenAI đã mở ra những mô hình tiên tiến cho hàng triệu người dùng. Những người đam mê AI và các nhà phát triển có thể sử dụng các mô hình được tối ưu hóa trên máy tính cá nhân và máy trạm NVIDIA RTX AI thông qua các công cụ và nền tảng phổ biến như Ollama, llama.cpp và Microsoft AI Foundry Local, và họ có thể kỳ vọng mức hiệu suất lên tới 256 token mỗi giây trên GPU NVIDIA GeForce RTX 5090.
“OpenAI đã cho thế giới thấy những gì có thể được xây dựng trên NVIDIA AI — và giờ đây họ đang thúc đẩy đổi mới trong phần mềm nguồn mở”, Jensen Huang, nhà sáng lập kiêm CEO của NVIDIA, cho biết. “Các mô hình gpt-oss cho phép các nhà phát triển ở khắp mọi nơi xây dựng trên nền tảng nguồn mở tiên tiến đó, củng cố vị thế dẫn đầu công nghệ của Hoa Kỳ trong lĩnh vực AI — tất cả đều trên cơ sở hạ tầng tính toán AI lớn nhất thế giới”.
Việc phát hành các mô hình này làm nổi bật vị thế dẫn đầu về AI của NVIDIA từ đào tạo đến suy luận và từ đám mây đến AI PC.
Mở cho tất cả
Cả gpt-oss-20b và gpt-oss-120b đều là các mô hình suy luận linh hoạt, trọng số mở với khả năng liên kết chuỗi suy nghĩ và mức độ nỗ lực suy luận có thể điều chỉnh bằng kiến trúc hỗn hợp chuyên gia phổ biến. Các mô hình này được thiết kế để hỗ trợ các tính năng như làm theo hướng dẫn và sử dụng công cụ, và được đào tạo trên GPU NVIDIA H100. Các nhà phát triển AI có thể tìm hiểu thêm và bắt đầu sử dụng hướng dẫn tại đây.
Các mô hình này có thể hỗ trợ tới 131.072 độ dài ngữ cảnh, một trong những độ dài ngữ cảnh dài nhất hiện có khi suy luận tại chỗ. Nó có nghĩa là các mô hình có thể suy luận thông qua các bài toán ngữ cảnh, lý tưởng cho các tác vụ như tìm kiếm trên web, hỗ trợ mã hóa, hiểu tài liệu và nghiên cứu chuyên sâu.
Các mô hình mở OpenAI là những mô hình MXFP4 đầu tiên được hỗ trợ trên NVIDIA RTX. MXFP4 cho phép tạo ra mô hình chất lượng cao, mang lại hiệu suất nhanh chóng, hiệu quả trong khi yêu cầu ít tài nguyên hơn so với các loại mô hình chính xác khác.
Chạy các mô hình OpenAI trên NVIDIA RTX với Ollama
Cách dễ nhất để kiểm tra các mô hình này trên PC RTX AI, trên GPU có ít nhất 24GB VRAM, là sử dụng ứng dụng Ollama mới. Ollama được những người đam mê AI và các nhà phát triển ưa chuộng nhờ khả năng tích hợp dễ dàng, và giao diện người dùng (UI) mới bao gồm hỗ trợ sẵn sàng cho các mô hình open-weight của OpenAI. Ollama được tối ưu hóa hoàn toàn cho RTX, lý tưởng cho người dùng muốn trải nghiệm sức mạnh của AI cá nhân trên PC hoặc máy trạm của họ.
Sau khi cài đặt, Ollama cho phép chat nhanh chóng và dễ dàng với các mô hình. Chỉ cần chọn mô hình từ menu thả xuống và gửi lời nhắc. Vì Ollama được tối ưu hóa cho RTX, bạn không cần cấu hình hoặc đặt lệnh bổ sung nào để đảm bảo hiệu suất tối đa trên các GPU được hỗ trợ.

Ứng dụng mới của Ollama bao gồm các tính năng mới khác, như hỗ trợ dễ dàng cho tệp PDF hoặc văn bản trong các cuộc trò chuyện, hỗ trợ đa phương thức trên các mô hình áp dụng để người dùng có thể đưa hình ảnh vào lời nhắc của họ và dễ dàng tùy chỉnh độ dài ngữ cảnh khi làm việc với các tài liệu hoặc đoạn chat dài.
Các nhà phát triển cũng có thể sử dụng Ollama thông qua giao diện dòng lệnh hoặc bộ công cụ phát triển phần mềm (SDK) của ứng dụng để hỗ trợ ứng dụng và quy trình làm việc của họ.
Những cách khác để sử dụng các mô hình OpenAI mới trên RTX
Những người đam mê và nhà phát triển cũng có thể thử các mô hình gpt-oss trên PC RTX AI thông qua nhiều ứng dụng và framework khác, tất cả đều được hỗ trợ bởi RTX, trên GPU có ít nhất 16GB VRAM.
NVIDIA tiếp tục hợp tác với cộng đồng nguồn mở trên cả llama.cpp và thư viện tensor GGML để tối ưu hóa hiệu suất trên GPU RTX. Những đóng góp gần đây bao gồm việc triển khai CUDA Graphs để giảm thiểu chi phí và bổ sung các thuật toán giúp giảm thiểu chi phí CPU. Hãy xem kho lưu trữ GitHub của llama.cpp để bắt đầu.
Các nhà phát triển Windows cũng có thể truy cập các mô hình mới của OpenAI thông qua Microsoft AI Foundry Local, hiện đang trong giai đoạn đánh giá công khai. Foundry Local là một giải pháp suy luận AI trên thiết bị, tích hợp vào quy trình làm việc thông qua dòng lệnh, SDK hoặc giao diện lập trình ứng dụng. Foundry Local sử dụng ONNX Runtime, được tối ưu hóa thông qua CUDA, với hỗ trợ NVIDIA TensorRT cho RTX sắp ra mắt. Việc bắt đầu với nó rất dễ dàng: cài đặt Foundry Local và gọi lệnh “Foundry model run gpt-oss-20b” trong terminal.
Việc phát hành các mô hình nguồn mở này sẽ mở đầu cho làn sóng đổi mới AI tiếp theo từ những người đam mê và nhà phát triển muốn bổ sung khả năng lập luận vào các ứng dụng Windows được tăng tốc bằng AI của họ.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale