
Điểm Benchmark NVIDIA RTX 3090 cho TensorFlow
Ở bài này, chúng tôi đã tiến hành đánh giá hiệu suất học sâu cho TensorFlow trên GPU NVIDIA GeForce RTX 3090.
Máy trạm Deep Learning của chúng tôi được trang bị hai GPU RTX 3090 và chúng tôi đã chạy tập lệnh điểm chuẩn “tf_cnn_benchmarks.py” tiêu chuẩn được tìm thấy trong github chính thức của TensorFlow. Chúng tôi đã thử nghiệm trên các mạng sau: ResNet50, ResNet152, Inception v3, Inception v4. Hơn nữa, chúng tôi đã chạy các thử nghiệm tương tự bằng cách sử dụng cấu hình GPU 1, 2 và 4 (đối với phần 2x RTX 3090 so với 4x 2080Ti). Kích thước lô được xác định là kích thước lớn nhất có thể vừa với bộ nhớ GPU có sẵn.
Các điểm chính và kết quả thấy được
- Các NVIDIA RTX 3090 vượt trội so với tất cả các GPU (hình ảnh / giây) trên tất cả các mô hình.
- Hệ thống có 2x RTX 3090> 4x RTX 2080 Ti.
- Đối với học sâu, RTX 3090 là GPU có giá trị tốt nhất trên thị trường và làm giảm đáng kể chi phí của một máy trạm AI.
RTX 3090 ResNet 50 TensorFlow Benchmark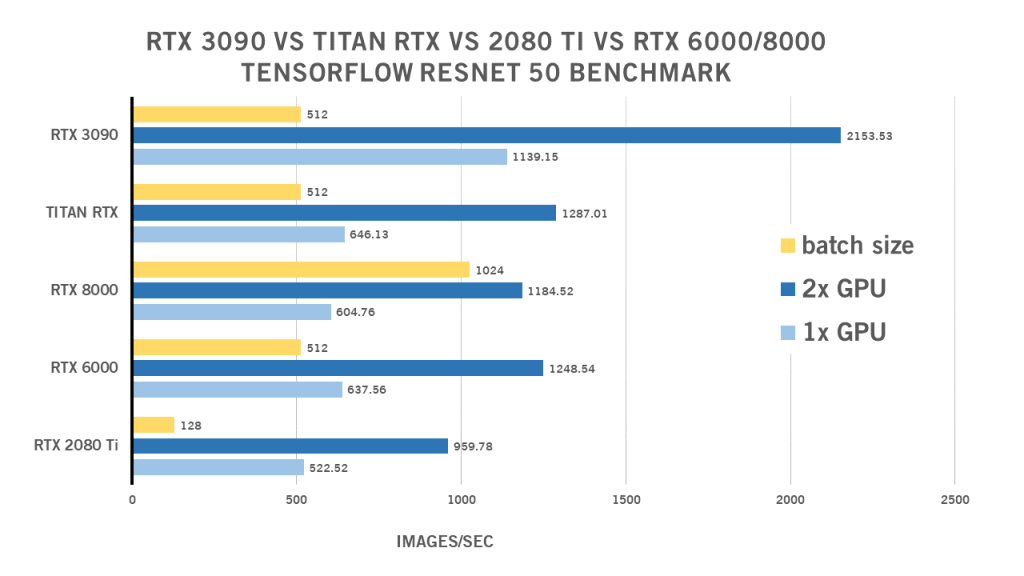
| 1x GPU | 2x GPU | kích thước lô | |
| RTX 2080 Ti | 522,52 | 959,78 | 128 |
| RTX 6000 | 637,56 | 1248,54 | 512 |
| RTX 8000 | 604,76 | 1184,52 | 1024 |
| TITAN RTX | 646,13 | 1287.01 | 512 |
| RTX 3090 | 1139.15 | 2153,53 | 512 |
RTX 3090 ResNet 152 TensorFlow Benchmark
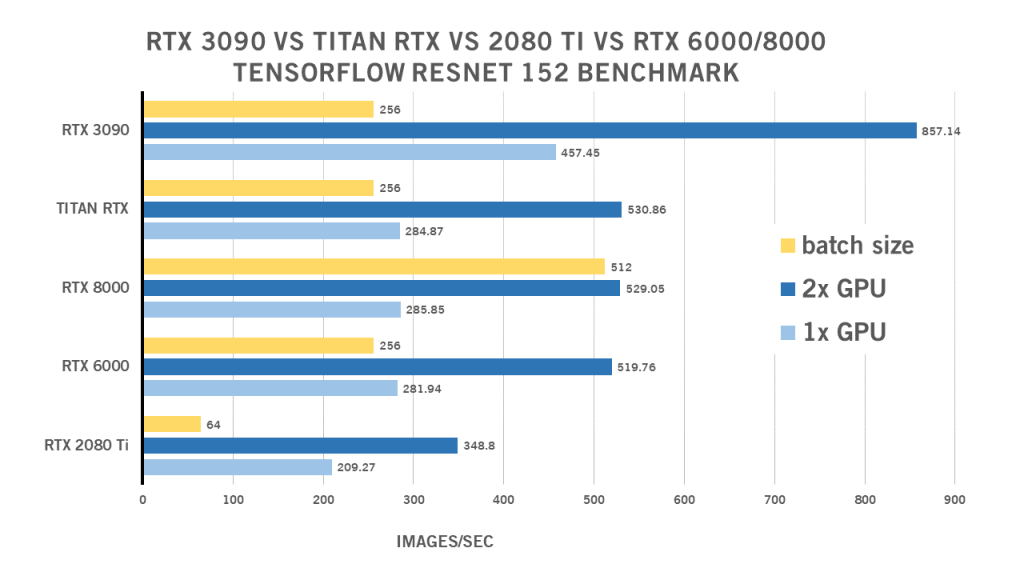
| 1x GPU | 2x GPU | kích thước lô | |
| RTX 2080 Ti | 209,27 | 348,8 | 64 |
| RTX 6000 | 281,94 | 519,76 | 256 |
| RTX 8000 | 285,85 | 529.05 | 512 |
| TITAN RTX | 284,87 | 530,86 | 256 |
| RTX 3090 | 457,45 | 857,14 | 256 |
RTX 3090 Inception V3 TensorFlow Benchmark
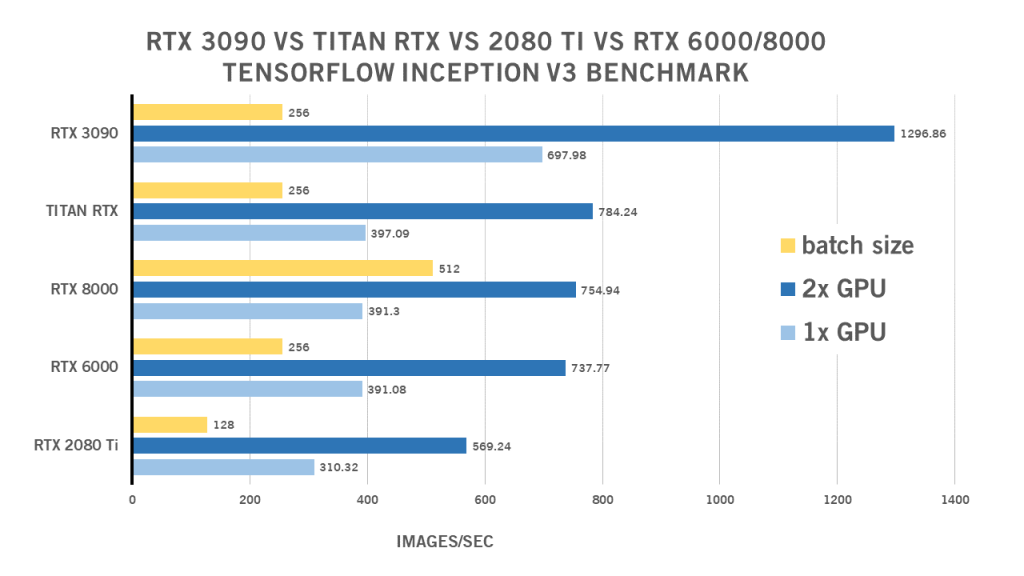
| 1x GPU | 2x GPU | Batch size | |
| RTX 2080 Ti | 310.32 | 569,24 | 128 |
| RTX 6000 | 391.08 | 737,77 | 256 |
| RTX 8000 | 391,3 | 754,94 | 512 |
| TITAN RTX | 397.09 | 784,24 | 256 |
| RTX 3090 | 697,98 | 1296,86 | 256 |
RTX 3090 Inception V4 TensorFlow Benchmark
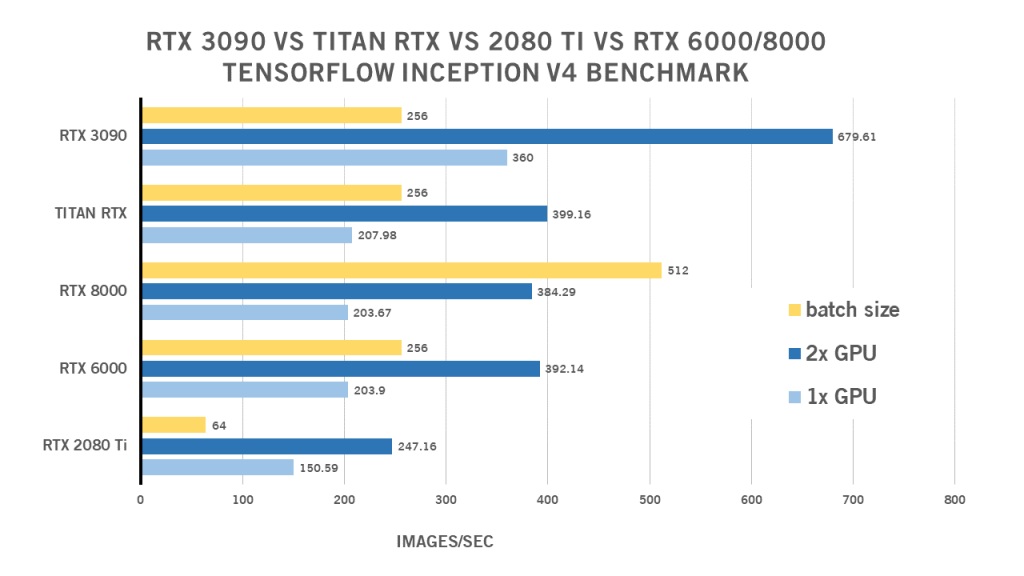
| 1x GPU | 2x GPU | Batch size | |
| RTX 2080 Ti | 150,59 | 247,16 | 64 |
| RTX 6000 | 203,9 | 392,14 | 256 |
| RTX 8000 | 203,67 | 384,29 | 512 |
| TITAN RTX | 207,98 | 399,16 | 256 |
| RTX 3090 | 360 | 679,61 | 256 |
2x NVIDIA RTX 3090 Vs. 4x RTX 2080 Ti – Cấu hình nào tốt hơn?
Nhiều người tò mò không chỉ về sự kết hợp hiệu suất 1:1 của RTX 3090 và RTX 2080 Ti mà còn về hiệu suất của cấu hình đa GPU. Như hiện tại, RTX 3090 có 3 khe cắm PCIe (so với 2 khe cắm thông thường như 2080 Ti có) trên một bo mạch chủ thông thường. Do kích thước của nó, một máy trạm thông thường hiện chỉ có khả năng chứa 2 RTX 3090 (không có sửa đổi tùy chỉnh mở rộng. Cấu hình 2x RTX 3090 có tương ứng với cấu hình hướng đến hiệu năng 4x 2080 Ti không? Nói một cách đơn giản là “có”. Hãy xem kết quả cụ thể dưới đây.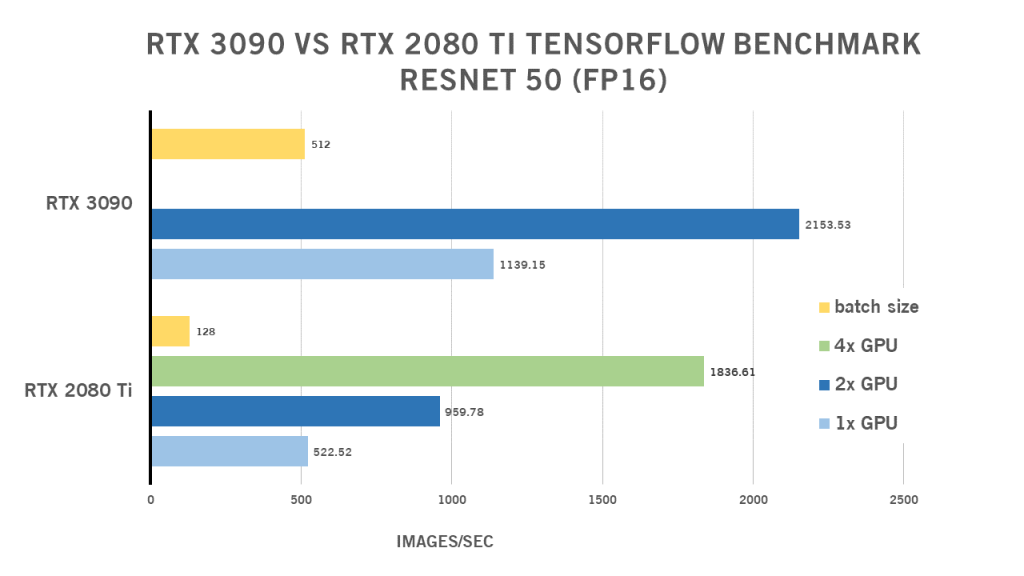
| 1x GPU | 2x GPU | GPU 4x | Batch size | |
| RTX 2080 Ti | 522,52 | 959,78 | 1836,61 | 128 |
| RTX 3090 | 1139.15 | 2153,53 | N / A | 512 |
Tham số Benchmark TF CNN
| Description | Type |
| Number of Batches | 100 |
| Number of Epochs | 0.01 |
| Data Format | NCHW |
| Optimizer | Momentum |
| Variables | parameter_server |
NVIDIA RTX 3090 có bộ nhớ 24GB GDDR6X và được xây dựng với lõi RT và lõi Tensor nâng cao, bộ xử lý đa xử lý phát trực tuyến mới và bộ nhớ G6X siêu nhanh để tăng hiệu suất đáng kinh ngạc.
Thông tin thêm về NVIDIA RTX 3090
So với 4352 lõi CUDA của RTX 2080 Ti, RTX 3090 tăng hơn gấp đôi với 10496 lõi CUDA. CUDA Core là GPU tương đương với lõi CPU và được tối ưu hóa để chạy một số lượng lớn các phép tính đồng thời (xử lý song song). Nhiều lõi CUDA hơn thường có nghĩa là hiệu suất tốt hơn và xử lý đồ họa chuyên sâu nhanh hơn.
Nguồn Exxt
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale