
Đại học Cambridge Vương quốc Anh cùng với hệ thống NVIDIA DGX SuperPOD hướng đến thế hệ tiếp theo của đám mây HPC hiệu quả, an toàn.
Cloud-native Supercomputing (Siêu máy tính được thiết kế cho đám mây từ gốc) là điều quan trọng tiếp theo trong lĩnh vực siêu máy tính và nó đã xuất hiện ở đây ngày hôm nay, sẵn sàng giải quyết các workload HPC và AI khó khăn nhất.
Đại học Cambridge đang xây dựng một siêu máy tính thiết kế cho đám mây ở Vương quốc Anh. Hai nhóm nhà nghiên cứu ở Mỹ đang phát triển riêng biệt các yếu tố phần mềm quan trọng cho Cloud-native Supercomputing này.

Phòng thí nghiệm Quốc gia Los Alamos, là một phần của sự hợp tác liên tục với UCF Consortium, đang giúp cung cấp các khả năng đẩy nhanh các thuật toán dữ liệu. Đại học Bang Ohio đang cập nhật phần mềm Message Passing Interface để tăng cường các mô phỏng khoa học.
NVIDIA đang cung cấp Cloud-native Supercomputing cho người dùng trên toàn thế giới dưới dạng DGX SuperPOD mới nhất của mình. Nó đóng gói các thành phần chính như bộ xử lý dữ liệu NVIDIA BlueField-2 (DPU) hiện đang được sản xuất.
Vậy, Cloud-native Supercomputing là gì?
Giống như món ăn của Reese bọc bơ đậu phộng trong sô cô la, Cloud-native Supercomputing kết hợp những gì tốt nhất của hai thế giới.
Cloud-native Supercomputing kết hợp sức mạnh của điện toán hiệu suất cao với tính bảo mật và dễ sử dụng của các dịch vụ điện toán đám mây.
Nói cách khác, Cloud-native Supercomputing cung cấp một đám mây HPC với một hệ thống mạnh mẽ như siêu máy tính TOP500 mà nhiều người dùng có thể chia sẻ một cách an toàn mà không làm giảm hiệu suất của các ứng dụng của họ.
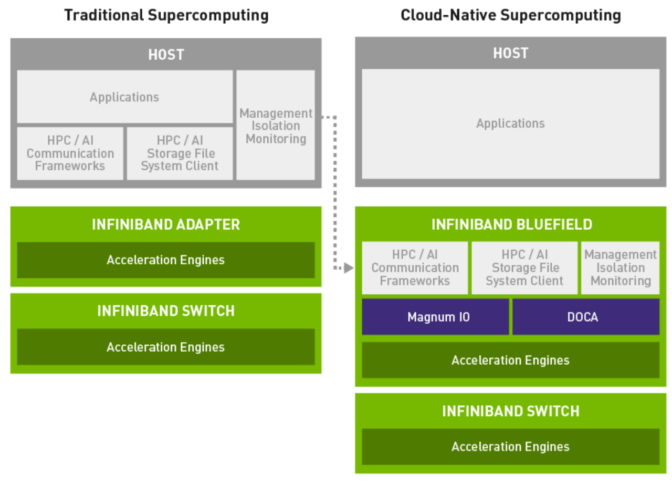 BlueField DPU hỗ trợ giảm tải các tác vụ bảo mật, truyền thông và quản lý để tạo ra một Cloud-native Supercomputing hiệu quả.
BlueField DPU hỗ trợ giảm tải các tác vụ bảo mật, truyền thông và quản lý để tạo ra một Cloud-native Supercomputing hiệu quả.
Cloud-native Supercomputing có thể làm gì?
Cloud-native Supercomputing có hai tính năng chính.
Đầu tiên, họ cho phép nhiều người dùng chia sẻ một siêu máy tính trong khi đảm bảo các workload của mỗi người dùng vẫn an toàn và riêng tư. Đó là một khả năng được gọi là “cách ly nhiều người thuê” (multi-tenant isolation) có sẵn trong các dịch vụ điện toán đám mây thương mại hiện nay. Nhưng nó thường không được tìm thấy trong các hệ thống HPC được sử dụng cho các workload kỹ thuật và khoa học, nơi hiệu suất thô là ưu tiên hàng đầu và các dịch vụ bảo mật khi hoạt động bị chậm lại.
Thứ hai, Cloud-native Supercomputing sử dụng các DPU để xử lý các tác vụ như lưu trữ, bảo mật để cách ly đối tượng thuê và quản lý hệ thống. Điều này giúp CPU giảm tải để tập trung vào các tác vụ xử lý, tối đa hóa hiệu suất tổng thể của hệ thống.
Kết quả là một siêu máy tính cho phép các dịch vụ đám mây nguyên bản mà không bị giảm hiệu suất. Trong tương lai, các DPU có thể xử lý các tác vụ giảm tải bổ sung, do đó các hệ thống duy trì hiệu suất cao nhất khi chạy các workload cho HPC và AI.
Cloud-native Supercomputing hoạt động như thế nào?
Về cơ bản, các siêu máy tính ngày nay kết hợp hai loại bộ não – CPU và bộ tăng tốc, điển hình là GPU.
Bộ tăng tốc đóng gói hàng nghìn lõi xử lý để tăng tốc các hoạt động song song ở trung tâm của nhiều workload AI và HPC. CPU được xây dựng cho các phần của thuật toán yêu cầu xử lý nối tiếp nhanh. Nhưng theo thời gian, chúng đã trở thành gánh nặng với các lớp tác vụ dẫn truyền ngày càng tăng, cần thiết để quản lý các hệ thống ngày càng lớn và phức tạp.
Cloud-native Supercomputing bao gồm bộ não thứ ba để xây dựng các hệ thống nhanh hơn, hiệu quả hơn. Chúng được thêm các DPU giúp giảm tải về bảo mật, truyền thông, lưu trữ và các công việc khác mà hệ thống hiện đại cần quản lý.
Làn đường di chuyển cho siêu máy tính
Trong các siêu máy tính truyền thống, một công việc tính toán đôi khi phải đợi trong khi CPU xử lý một tác vụ truyền dẫn. Đó là một vấn đề quen thuộc mà chúng tạo ra cái gọi là “sự ồn ào của hệ thống”.
Trong Cloud-native Supercomputing, xử lý và truyền dẫn diễn ra song song. Nó giống như việc mở một làn đường thứ ba trên đường cao tốc để giúp mọi phương tiện lưu thông thuận lợi hơn.
Các thử nghiệm ban đầu cho thấy các Cloud-native Supercomputing có thể thực hiện các công việc HPC nhanh hơn 1,4 lần so với các máy tính truyền thống, theo công việc tại phòng thí nghiệm MVAPICH tại Bang Ohio, một chuyên gia về truyền dẫn của HPC. Phòng thí nghiệm cũng cho thấy các Cloud-native Supercomputing đạt được sự chồng chéo 100% của các hoạt động xử lý và truyền dẫn, cao hơn 99% so với các hệ thống HPC hiện có.
Chuyên gia nói gì về Cloud-native Supercomputing?
Đó là lý do tại sao trên khắp thế giới, Cloud-native Supercomputing đang dần xuất hiện.
Paul Calleja, giám đốc điện toán tại Đại học Cambridge, cho biết: “Chúng tôi đang xây dựng Cloud-native Supercomputing cho học thuật đầu tiên ở châu Âu để cung cấp hiệu suất như bare-metal với các dịch vụ của InfiniBand trên nền tảng đám mây,” Paul Calleja, giám đốc điện toán tại Đại học Cambridge.
Ông nói thêm: “Hệ thống này, sẽ được xếp hạng trong top 100 trong danh sách TOP500 tháng 11 năm 2020, sẽ cho phép các nhà nghiên cứu của chúng tôi tối ưu hóa các ứng dụng của họ bằng cách sử dụng những tiến bộ mới nhất trong kiến trúc siêu máy tính.
Các chuyên gia của HPC đang mở đường cho những tiến bộ hơn nữa trong Cloud-native Supercomputing.
Steve Poole, phát biểu trong vai trò giám đốc của Khung giao tiếp hợp nhất , với các thành viên: “Tập đoàn UCF gồm các nhà lãnh đạo công nghiệp và học thuật đang tạo ra các khuôn khổ giao tiếp cấp sản xuất và các tiêu chuẩn mở cần thiết để tạo ra tương lai cho Cloud-native Supercomputing. bao gồm đại diện của Arm, IBM, NVIDIA, các phòng thí nghiệm quốc gia Hoa Kỳ và các trường đại học Hoa Kỳ.
“Các thử nghiệm của chúng tôi cho thấy Cloud-native Supercomputing có hiệu quả về mặt kiến trúc để nâng siêu máy tính lên cấp độ hiệu suất HPC tiếp theo đồng thời kích hoạt các tính năng bảo mật mới”, Dhabaleswar K. (DK) Panda, giáo sư khoa học máy tính và kỹ thuật tại Bang Ohio và dẫn đầu. của Phòng thí nghiệm Máy tính Dựa trên Mạng của nó.
Tìm hiểu thêm về Cloud-native Supercomputing
Để tìm hiểu thêm, hãy xem tổng quan kỹ thuật về Cloud-native Supercomputing. Bạn cũng có thể tìm thêm thông tin trực tuyến về hệ thống mới tại Đại học Cambridge và Cloud-native Supercomputing mới của NVIDIA .
Và để có được bức tranh toàn cảnh về những tiến bộ mới nhất trong HPC, AI và hơn thế nữa, hãy xem toàn bộ các thông tin từ GTC21 tại đây.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale