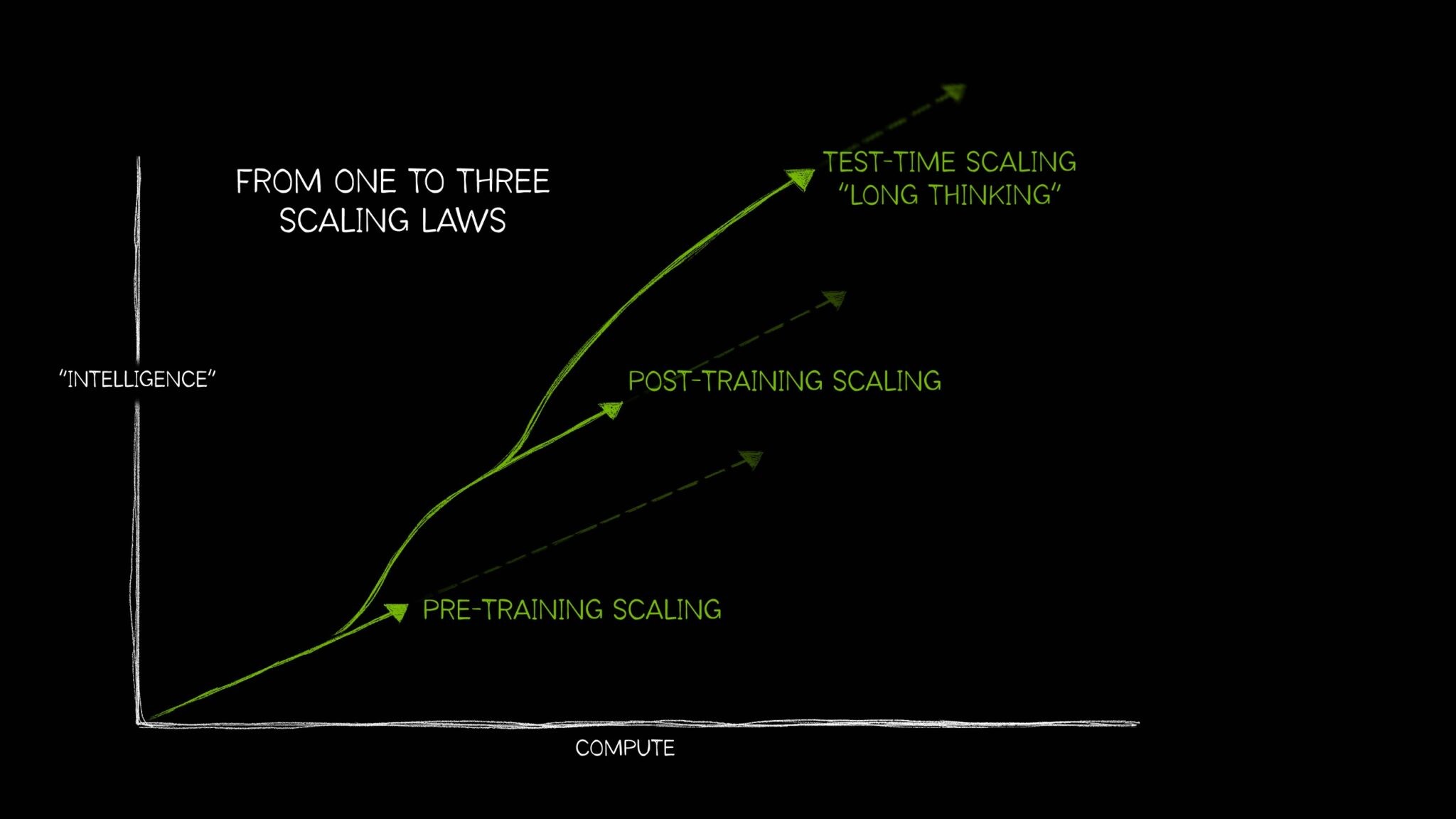
Luật mở rộng mô tả cách hiệu suất của hệ thống AI được cải thiện khi kích thước dữ liệu đào tạo, tham số mô hình hoặc tài nguyên tính toán tăng lên.
Cũng giống như các quy luật thực nghiệm được hiểu rộng rãi về tự nhiên — ví dụ, cái gì tăng lên thì phải giảm xuống, hoặc mọi hành động đều có phản hồi tương ứng và đối nghịch — lĩnh vực AI từ lâu đã được định nghĩa bởi một ý tưởng duy nhất: càng nhiều tài nguyên điện toán, càng nhiều dữ liệu đào tạo và càng nhiều tham số thì mô hình AI sẽ càng tốt hơn.
Tuy nhiên, AI đã phát triển để cần ba quy luật riêng biệt mô tả cách áp dụng tài nguyên điện toán theo những cách khác nhau tác động đến hiệu suất mô hình. Cùng với nhau, các luật mở rộng AI này — mở rộng trước khi đào tạo, mở rộng sau khi đào tạo và mở rộng trong thời gian thử nghiệm, còn được gọi là suy nghĩ dài hạn — phản ánh cách lĩnh vực này đã phát triển với các kỹ thuật sử dụng tính toán bổ sung trong nhiều trường hợp sử dụng AI ngày càng phức tạp.
Sự gia tăng gần đây của việc mở rộng quy mô theo thời gian thử nghiệm — sử dụng nhiều tài nguyên điện toán hơn vào thời điểm suy luận để cải thiện độ chính xác — đã cho phép các mô hình suy luận AI, một lớp mô hình ngôn ngữ lớn (LLM) mới thực hiện nhiều lần suy luận để giải quyết các vấn đề phức tạp, đồng thời mô tả các bước cần thiết để giải quyết một nhiệm vụ. Việc mở rộng quy mô theo thời gian thử nghiệm đòi hỏi lượng lớn tài nguyên tính toán để hỗ trợ suy luận AI, điều này sẽ thúc đẩy nhu cầu về điện toán tăng tốc hơn nữa.
Pretraining Scaling là gì?
Pretraining Scaling là quy luật ban đầu của quá trình phát triển AI. Nó chứng minh rằng bằng cách tăng kích thước tập dữ liệu đào tạo, số lượng tham số mô hình và tài nguyên tính toán, các nhà phát triển có thể mong đợi những cải tiến có thể dự đoán được về trí thông minh và độ chính xác của mô hình.
Mỗi một trong ba yếu tố này — dữ liệu, kích thước mô hình, tài nguyên điện toán — đều có mối quan hệ với nhau. Theo quy luật pretraining scaling, được nêu trong bài nghiên cứu này, khi các mô hình lớn hơn được cung cấp nhiều dữ liệu hơn, hiệu suất chung của các mô hình sẽ được cải thiện. Để thực hiện điều này khả thi, các nhà phát triển phải mở rộng quy mô tính toán của họ — tạo ra nhu cầu về các tài nguyên điện toán tăng tốc mạnh mẽ để chạy các khối lượng công việc đào tạo lớn hơn đó.
Nguyên lý mở rộng pretraining này dẫn đến các mô hình lớn đạt được khả năng đột phá. Nó cũng thúc đẩy những đổi mới lớn trong kiến trúc mô hình, bao gồm sự gia tăng của các mô hình biến đổi tham số hàng tỷ và nghìn tỷ, sự kết hợp của các mô hình chuyên gia và các kỹ thuật đào tạo phân tán mới — tất cả đều đòi hỏi tài nguyên điện toán đáng kể.
Và sự liên quan của quy luật pretraining scaling vẫn tiếp tục — khi con người tiếp tục tạo ra ngày càng nhiều dữ liệu đa phương thức, kho thông tin văn bản, hình ảnh, âm thanh, video và cảm biến này sẽ được sử dụng để đào tạo các mô hình AI mạnh mẽ trong tương lai.
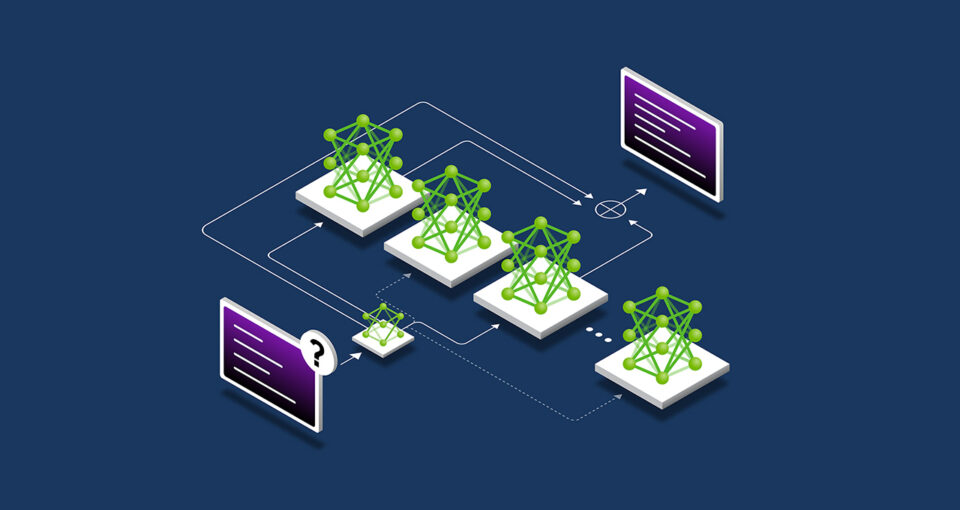 Pretraining scaling là nguyên tắc cơ bản của phát triển AI, liên kết kích thước của mô hình, tập dữ liệu và tính toán với lợi tức AI. Kết hợp các chuyên môn, được mô tả ở trên, là một kiến trúc mô hình phổ biến để đào tạo AI.
Pretraining scaling là nguyên tắc cơ bản của phát triển AI, liên kết kích thước của mô hình, tập dữ liệu và tính toán với lợi tức AI. Kết hợp các chuyên môn, được mô tả ở trên, là một kiến trúc mô hình phổ biến để đào tạo AI.
Post-training Scaling là gì?
Việc đào tạo trước một mô hình nền tảng lớn không dành cho tất cả mọi người — nó đòi hỏi đầu tư đáng kể, các chuyên gia lành nghề và các tập dữ liệu. Nhưng một khi một tổ chức đào tạo trước và phát hành một mô hình, họ sẽ giảm rào cản đối với việc áp dụng AI bằng cách cho phép những người khác sử dụng mô hình được đào tạo trước của họ làm nền tảng để điều chỉnh cho các ứng dụng của riêng họ.
Quá trình đào tạo sau này thúc đẩy nhu cầu tích lũy bổ sung cho điện toán tăng tốc trên khắp các doanh nghiệp và cộng đồng nhà phát triển rộng lớn hơn. Các mô hình nguồn mở phổ biến có thể có hàng trăm hoặc hàng nghìn mô hình phái sinh, được đào tạo trên nhiều lĩnh vực.
Việc phát triển hệ sinh thái các mô hình phái sinh này cho nhiều trường hợp sử dụng khác nhau có thể tốn nhiều điện năng tính toán hơn khoảng 30 lần so với việc đào tạo trước mô hình nền tảng ban đầu.
Việc phát triển hệ sinh thái các mô hình phái sinh này cho nhiều trường hợp sử dụng khác nhau có thể tốn nhiều sức mạnh tính toán hơn khoảng 30 lần so với việc đào tạo trước mô hình nền tảng ban đầu.
Các kỹ thuật sau đào tạo có thể cải thiện thêm tính đặc thù và tính liên quan của mô hình đối với trường hợp sử dụng mong muốn của tổ chức. Trong khi đào tạo trước giống như gửi một mô hình AI đến trường để học các kỹ năng cơ bản, đào tạo sau nâng cao mô hình bằng các kỹ năng áp dụng cho công việc dự định của nó. Ví dụ, một LLM có thể được đào tạo sau để giải quyết một nhiệm vụ như phân tích tình cảm hoặc dịch thuật — hoặc hiểu thuật ngữ chuyên ngành của một lĩnh vực cụ thể, như chăm sóc sức khỏe hoặc luật pháp.
Quy luật mở rộng sau đào tạo cho rằng hiệu suất của mô hình được đào tạo trước có thể được cải thiện hơn nữa — về hiệu quả tính toán, độ chính xác hoặc tính đặc thù của lĩnh vực — bằng cách sử dụng các kỹ thuật bao gồm tinh chỉnh, cắt tỉa, lượng tử hóa, chưng cất, học tăng cường và tăng cường dữ liệu tổng hợp.
- Tinh chỉnh sử dụng dữ liệu đào tạo bổ sung để điều chỉnh mô hình AI cho các lĩnh vực và ứng dụng cụ thể. Điều này có thể được thực hiện bằng cách sử dụng các tập dữ liệu nội bộ của tổ chức hoặc với các cặp đầu vào và đầu ra của mô hình mẫu.
- Chưng cất đòi hỏi một cặp mô hình AI: một mô hình giáo viên lớn, phức tạp và một mô hình học viên nhẹ. Trong kỹ thuật chưng cất phổ biến nhất, được gọi là chưng cất ngoại tuyến, mô hình học viên học cách bắt chước đầu ra của mô hình giáo viên được đào tạo trước.
- Học tăng cường, hay RL, là một kỹ thuật học máy sử dụng mô hình phần thưởng để đào tạo một tác nhân đưa ra quyết định phù hợp với một trường hợp sử dụng cụ thể. Tác nhân hướng đến việc đưa ra các quyết định tối đa hóa phần thưởng tích lũy theo thời gian khi tương tác với môi trường — ví dụ, một chatbot LLM được củng cố tích cực bằng phản ứng “ngón tay cái hướng lên” từ người dùng. Kỹ thuật này được gọi là học tăng cường từ phản hồi của con người (RLHF). Một kỹ thuật mới hơn khác, học tăng cường từ phản hồi AI (RLAIF), thay vào đó sử dụng phản hồi từ các mô hình AI để hướng dẫn quá trình học, hợp lý hóa các nỗ lực sau đào tạo.
- Lấy mẫu Best-of-n tạo ra nhiều đầu ra từ một mô hình ngôn ngữ và chọn đầu ra có điểm thưởng cao nhất dựa trên mô hình thưởng. Nó thường được sử dụng để cải thiện đầu ra của AI mà không cần sửa đổi các tham số mô hình, cung cấp một giải pháp thay thế cho việc tinh chỉnh bằng học tăng cường.
- Các phương pháp tìm kiếm khám phá một loạt các đường dẫn quyết định tiềm năng trước khi chọn đầu ra cuối cùng. Kỹ thuật sau đào tạo này có thể cải thiện phản hồi của mô hình theo từng bước.
Để hỗ trợ sau đào tạo, các nhà phát triển có thể sử dụng dữ liệu tổng hợp để tăng cường hoặc bổ sung cho tập dữ liệu tinh chỉnh của họ. Việc bổ sung dữ liệu do AI tạo ra vào các tập dữ liệu thực tế có thể giúp các mô hình cải thiện khả năng xử lý các trường hợp ngoại lệ không được thể hiện đầy đủ hoặc bị thiếu trong dữ liệu đào tạo ban đầu.
 Việc mở rộng sau đào tạo sẽ tinh chỉnh các mô hình được đào tạo trước bằng các kỹ thuật như tinh chỉnh, cắt tỉa và chắt lọc để nâng cao hiệu quả và tính liên quan của nhiệm vụ.
Việc mở rộng sau đào tạo sẽ tinh chỉnh các mô hình được đào tạo trước bằng các kỹ thuật như tinh chỉnh, cắt tỉa và chắt lọc để nâng cao hiệu quả và tính liên quan của nhiệm vụ.
Test-time Scaling là gì?
LLM tạo ra phản hồi nhanh cho các prompt nhập liệu. Mặc dù quy trình này rất phù hợp để có được câu trả lời đúng cho các câu hỏi đơn giản, nhưng nó có thể không hiệu quả khi người dùng đặt ra các truy vấn phức tạp. Trả lời các câu hỏi phức tạp — một khả năng thiết yếu đối với khối lượng công việc AI của tác nhân — yêu cầu LLM phải suy luận thông qua câu hỏi trước khi đưa ra câu trả lời.
Tương tự như cách suy nghĩ của hầu hết mọi người — khi được yêu cầu cộng hai cộng hai, họ đưa ra câu trả lời ngay lập tức, mà không cần phải nói về những điều cơ bản của phép cộng hoặc số nguyên. Nhưng nếu được yêu cầu lập tức lập kế hoạch kinh doanh có thể tăng lợi nhuận của công ty lên 10%, một người có thể sẽ lý luận qua nhiều lựa chọn khác nhau và đưa ra câu trả lời gồm nhiều bước.
Việc mở rộng thời gian thử nghiệm, còn được gọi là suy nghĩ dài, diễn ra trong quá trình suy luận. Thay vì các mô hình AI truyền thống tạo ra câu trả lời một lần cho lời nhắc của người dùng, các mô hình sử dụng kỹ thuật này phân bổ thêm nỗ lực tính toán trong quá trình suy luận, cho phép chúng suy luận qua nhiều phản hồi tiềm năng trước khi đưa ra câu trả lời tốt nhất.
Đối với các tác vụ như tạo mã phức tạp, tùy chỉnh cho nhà phát triển, quá trình suy luận AI này có thể mất nhiều phút hoặc thậm chí nhiều giờ — và có thể dễ dàng yêu cầu khả năng tính toán gấp 100 lần cho các truy vấn đầy thách thức so với một lần suy luận duy nhất trên LLM truyền thống, điều này rất khó có thể đưa ra câu trả lời đúng để giải quyết một vấn đề phức tạp ngay trong lần thử đầu tiên.
Quá trình suy luận AI này có thể mất nhiều phút, thậm chí nhiều giờ — và dễ dàng yêu cầu khả năng tính toán gấp 100 lần cho các truy vấn khó so với một lần suy luận duy nhất trên LLM truyền thống.
Khả năng tính toán thời gian thử nghiệm này cho phép các mô hình AI khám phá các giải pháp khác nhau cho một vấn đề và chia nhỏ các yêu cầu phức tạp thành nhiều bước — trong nhiều trường hợp, hiển thị công việc của chúng cho người dùng khi họ lý luận. Các nghiên cứu đã phát hiện ra rằng việc mở rộng thời gian thử nghiệm dẫn đến phản hồi chất lượng cao hơn khi các mô hình AI được đưa ra lời nhắc mở đòi hỏi một số bước lý luận và lập kế hoạch.
Phương pháp tính toán thời gian thử nghiệm có nhiều cách tiếp cận, bao gồm:
- Gợi ý chuỗi suy nghĩ : Chia nhỏ các vấn đề phức tạp thành một loạt các bước đơn giản hơn.
- Lấy mẫu với biểu quyết đa số : Tạo nhiều phản hồi cho cùng một lời nhắc, sau đó chọn câu trả lời thường xuyên xuất hiện nhất làm đầu ra cuối cùng.
- Tìm kiếm : Khám phá và đánh giá nhiều con đường hiện diện trong cấu trúc phản ứng dạng cây.
Các phương pháp sau đào tạo như lấy mẫu tốt nhất trong n cũng có thể được sử dụng để suy nghĩ lâu dài trong quá trình suy luận nhằm tối ưu hóa phản hồi phù hợp với sở thích của con người hoặc các mục tiêu khác.
 Việc mở rộng thời gian thử nghiệm giúp tăng cường suy luận bằng cách phân bổ thêm năng lực tính toán để cải thiện khả năng suy luận của AI, cho phép các mô hình giải quyết hiệu quả các vấn đề phức tạp, nhiều bước.
Việc mở rộng thời gian thử nghiệm giúp tăng cường suy luận bằng cách phân bổ thêm năng lực tính toán để cải thiện khả năng suy luận của AI, cho phép các mô hình giải quyết hiệu quả các vấn đề phức tạp, nhiều bước.
Cách thức mở rộng thời gian thử nghiệm cho phép suy luận AI
Sự gia tăng của tính toán thời gian thử nghiệm mở ra khả năng AI đưa ra những phản hồi hợp lý, hữu ích và chính xác hơn cho các truy vấn phức tạp, mở của người dùng. Những khả năng này sẽ rất quan trọng đối với các tác vụ lý luận chi tiết, nhiều bước được mong đợi của AI tác nhân tự động và các ứng dụng AI vật lý . Trong các ngành công nghiệp, chúng có thể thúc đẩy hiệu quả và năng suất bằng cách cung cấp cho người dùng những trợ lý có năng lực cao để đẩy nhanh công việc của họ.
Trong chăm sóc sức khỏe, các mô hình có thể sử dụng thang đo thời gian thử nghiệm để phân tích lượng lớn dữ liệu và suy ra cách một căn bệnh sẽ tiến triển, cũng như dự đoán các biến chứng tiềm ẩn có thể phát sinh từ các phương pháp điều trị mới dựa trên cấu trúc hóa học của một phân tử thuốc. Hoặc, nó có thể sàng lọc qua cơ sở dữ liệu các thử nghiệm lâm sàng để đề xuất các lựa chọn phù hợp với hồ sơ bệnh của một cá nhân, chia sẻ quá trình lý luận của nó về ưu và nhược điểm của các nghiên cứu khác nhau.
Trong hậu cần bán lẻ và chuỗi cung ứng, suy nghĩ lâu dài có thể giúp đưa ra quyết định phức tạp cần thiết để giải quyết các thách thức hoạt động trong ngắn hạn và các mục tiêu chiến lược dài hạn. Các kỹ thuật lý luận có thể giúp doanh nghiệp giảm thiểu rủi ro và giải quyết các thách thức về khả năng mở rộng bằng cách dự đoán và đánh giá nhiều kịch bản cùng lúc — điều này có thể cho phép dự báo nhu cầu chính xác hơn, hợp lý hóa các tuyến đường di chuyển trong chuỗi cung ứng và các quyết định tìm nguồn cung ứng phù hợp với các sáng kiến phát triển bền vững của tổ chức.
Đối với các doanh nghiệp toàn cầu, kỹ thuật này có thể được áp dụng để soạn thảo kế hoạch kinh doanh chi tiết, tạo mã phức tạp để gỡ lỗi phần mềm hoặc tối ưu hóa lộ trình di chuyển cho xe tải giao hàng, robot kho và taxi robot.
Các mô hình lý luận AI đang phát triển nhanh chóng. OpenAI o1-mini và o3-mini, DeepSeek R1 và Gemini 2.0 Flash Thinking của Google DeepMind đều đã được giới thiệu trong vài tuần qua và các mô hình mới bổ sung dự kiến sẽ sớm ra mắt.
Các mô hình như thế này đòi hỏi nhiều khả năng tính toán hơn để suy luận trong quá trình suy luận và tạo ra câu trả lời đúng cho các câu hỏi phức tạp — điều đó có nghĩa là các doanh nghiệp cần mở rộng các nguồn lực điện toán được tăng tốc của mình để cung cấp thế hệ công cụ suy luận AI tiếp theo có thể hỗ trợ giải quyết vấn đề phức tạp, lập trình và lập kế hoạch nhiều bước.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Phần mềm NVIDIA mới cho nền tảng Blackwell chạy AI Factory với tốc độ ánh sáng
- Physical AI là gì? Cách thức hoạt động như thế nào?
- AI Factory là gì và tại sao NVIDIA lại đặt cược vào nó?
- NVIDIA DGX B300: Kiến tạo cho kỷ nguyên AI Factory thế hệ mới
- NVIDIA Dynamo – Thư viện nguồn mở tăng tốc và mở rộng các mô hình lý luận AI