
Sự gia tăng trong việc ứng dụng AI tạo sinh (Generative AI) là rất đáng chú ý trong thời gian gần đây. Được kích hoạt bởi sự ra mắt ChatGPT của OpenAI vào năm 2022, công nghệ mới này đã thu hút hơn 100 triệu người dùng trong vòng vài tháng và thúc đẩy các hoạt động phát triển đột biến trong hầu hết mọi lĩnh vực.
Đến năm 2023, các nhà phát triển bắt đầu thực hiện PoC (xác thực cho ý tưởng) sử dụng các API và các mô hình cộng đồng nguồn mở từ Meta, Mistral, Stability,…
Bước sang năm 2024, các tổ chức đang chuyển trọng tâm sang triển khai ở cấp độ sản xuất trên quy mô toàn diện, bao gồm việc kết nối các mô hình AI với hạ tầng doanh nghiệp hiện có, tối ưu hóa về độ trễ và thông lượng của hệ thống, lưu nhật ký, giám sát và bảo mật, cùng nhiều thứ khác. Con đường dẫn đến cấp độ sản xuất này rất phức tạp và tốn thời gian – nó đòi hỏi các kỹ năng, nền tảng và quy trình chuyên biệt, đặc biệt là ở quy mô lớn.
NVIDIA NIM là gì?
NVIDIA NIM, NVIDIA Inference Microservice, là một thành phần của nền tảng NVIDIA AI Enterprise. Nó cung cấp một quy trình chuẩn để phát triển các ứng dụng doanh nghiệp được hỗ trợ bởi AI và triển khai các mô hình AI trong môi trường sản xuất.
NIM là một tập hợp các vi dịch vụ (microservice) thuần đám mây (cloud-native) được tối ưu hóa, và được thiết kế để rút ngắn thời gian đưa ra thị trường, đồng thời đơn giản hóa việc triển khai các mô hình GenAI ở mọi nơi, trên đám mây, trung tâm dữ liệu và máy trạm có GPU hỗ trợ. Nó mở rộng nhóm nhà phát triển bằng cách loại bỏ sự phức tạp của việc phát triển và đóng gói mô hình AI ở cấp độ sản xuất, sử dụng các API chuẩn của ngành.
NVIDIA NIM và khả năng tối ưu hóa cho suy luận AI
NVIDIA NIM được thiết kế để thu hẹp khoảng cách giữa thế giới phát triển AI phức tạp và nhu cầu hoạt động của môi trường doanh nghiệp, với số lượng nhà phát triển ứng dụng doanh nghiệp hơn gấp 10-100 lần đóng góp vào quá trình chuyển đổi AI của công ty họ.
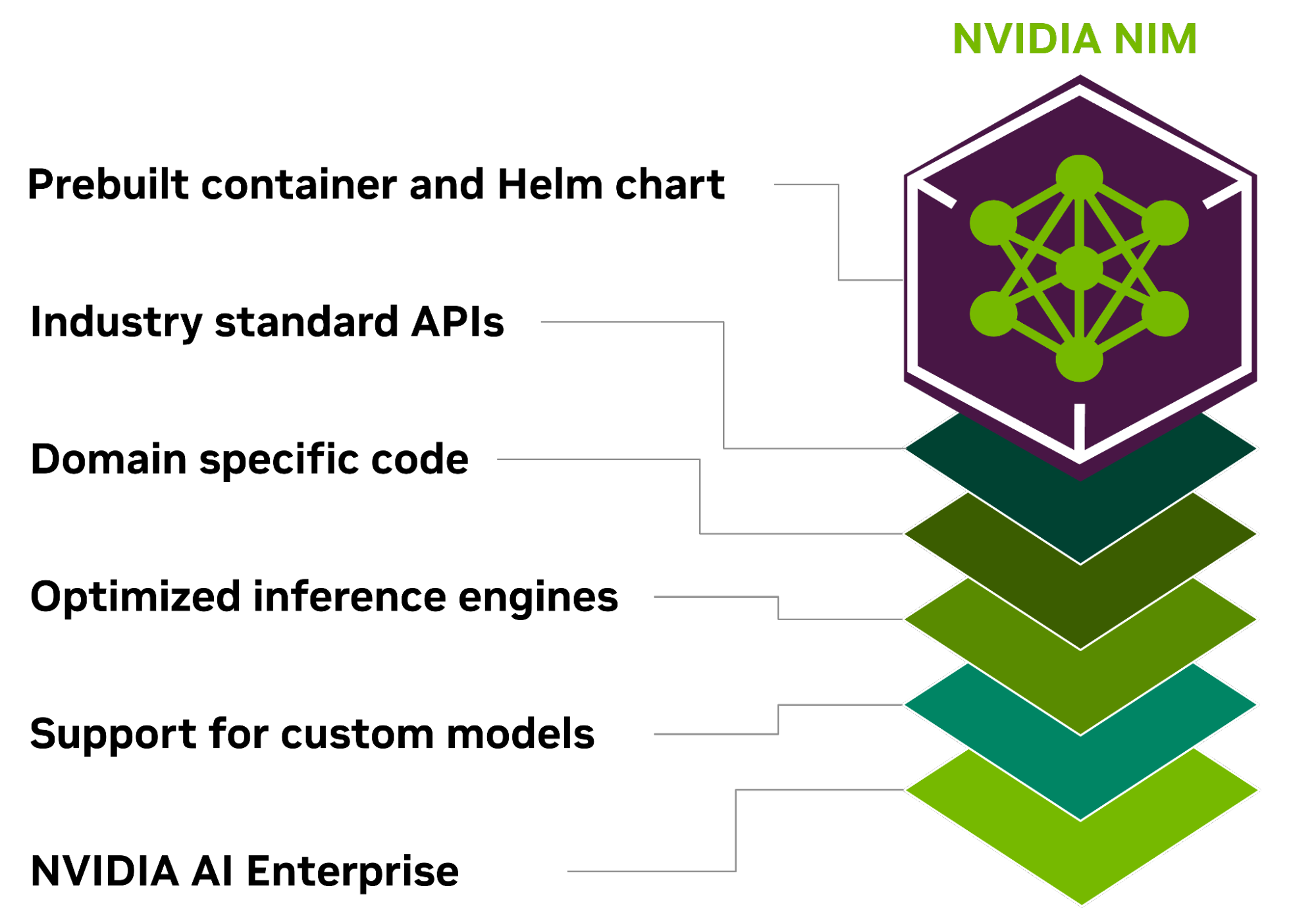 Hình 1. NVIDIA NIM là một microservice suy luận được đóng gói bao gồm các API theo chuẩn ngành, code cụ thể cho lĩnh vực, công cụ suy luận được tối ưu hóa dành cho doanh nghiệp
Hình 1. NVIDIA NIM là một microservice suy luận được đóng gói bao gồm các API theo chuẩn ngành, code cụ thể cho lĩnh vực, công cụ suy luận được tối ưu hóa dành cho doanh nghiệp
Một số lợi ích cốt lõi của NIM bao gồm:
Triển khai ở mọi nơi
NIM được xây dựng để có tính di động và kiểm soát, cho phép triển khai mô hình trên nhiều cơ sở hạ tầng khác nhau, từ máy trạm cục bộ đến đám mây hoặc trung tâm dữ liệu tại chỗ. Điều này bao gồm NVIDIA DGX, NVIDIA DGX Cloud, NVIDIA Certified Systems, NVIDIA RTX workstation và PC.
Các container dựng sẵn và Helm charts được đóng gói với các mô hình được tối ưu hóa, được xác thực và đo điểm chuẩn một cách nghiêm ngặt trên các nền tảng phần cứng NVIDIA, nhà cung cấp dịch vụ đám mây và bản phân phối Kubernetes khác nhau. Điều này cho phép hỗ trợ trên tất cả các môi trường do NVIDIA cung cấp và đảm bảo rằng các tổ chức có thể triển khai các ứng dụng GenAI của họ ở bất cứ đâu, duy trì toàn quyền kiểm soát các ứng dụng và dữ liệu họ xử lý.
Phát triển với API chuẩn
Các nhà phát triển có thể truy cập các mô hình AI thông qua các API – tuân thủ các tiêu chuẩn ngành cho từng lĩnh vực, đơn giản hóa việc phát triển các ứng dụng AI. Các API này tương thích với các quy trình triển khai chuẩn trong hệ sinh thái, cho phép các nhà phát triển cập nhật ứng dụng AI của họ một cách nhanh chóng – thường chỉ với ba dòng code. Sự tích hợp liền mạch và tính dễ sử dụng này tạo điều kiện thuận lợi cho việc triển khai và mở rộng quy mô nhanh chóng các giải pháp AI trong môi trường doanh nghiệp.
Tận dụng các mô hình dành riêng cho từng lĩnh vực
NIM cũng giải quyết nhu cầu về các giải pháp dành riêng cho từng lĩnh vực và hiệu suất được tối ưu hóa thông qua một số tính năng chính. Nó đóng gói các thư viện NVIDIA CUDA theo lĩnh vực cụ thể và code chuyên dụng được điều chỉnh cho phù hợp với nhiều lĩnh vực khác nhau như ngôn ngữ, giọng nói, xử lý video, chăm sóc sức khỏe, v.v. Cách tiếp cận này đảm bảo rằng các ứng dụng đều chính xác và phù hợp với trường hợp sử dụng cụ thể của chúng.
Chạy trên các công cụ suy luận được tối ưu hóa
NIM tận dụng các công cụ suy luận được tối ưu hóa cho từng mô hình và thiết lập phần cứng, mang lại độ trễ và thông lượng tốt nhất có thể trên cơ sở hạ tầng được tăng tốc. Điều này giúp giảm chi phí chạy tác vụ suy luận khi chúng mở rộng quy mô và cải thiện trải nghiệm của người dùng cuối. Ngoài việc hỗ trợ các mô hình cộng đồng được tối ưu hóa, các nhà phát triển còn có thể đạt được độ chính xác và hiệu suất cao hơn nữa bằng cách căn chỉnh và tinh chỉnh các mô hình với các nguồn dữ liệu độc quyền không bao giờ vượt ra khỏi ranh giới của trung tâm dữ liệu của họ.
Hỗ trợ AI cấp doanh nghiệp
Là một phần của NVIDIA AI Enterprise, NIM được xây dựng với container cơ sở cấp doanh nghiệp cung cấp nền tảng vững chắc cho phần mềm AI doanh nghiệp thông qua các nhánh tính năng, xác thực nghiêm ngặt, hỗ trợ doanh nghiệp với các thỏa thuận cấp dịch vụ và cập nhật bảo mật thường xuyên cho CVE. Cấu trúc hỗ trợ toàn diện và khả năng tối ưu hóa nhấn mạnh vai trò của NIM như một công cụ then chốt trong việc triển khai các ứng dụng AI hiệu quả, có thể mở rộng và tùy chỉnh trong sản xuất.
Các mô hình AI tăng tốc đã sẵn sàng để triển khai
Với sự hỗ trợ cho nhiều mô hình AI, chẳng hạn như mô hình cộng đồng, mô hình NVIDIA AI Foundation và mô hình AI tùy chỉnh do đối tác NVIDIA cung cấp, NIM hỗ trợ các trường hợp sử dụng AI trên nhiều lĩnh vực. Nó bao gồm các mô hình ngôn ngữ lớn (LLMs), mô hình ngôn ngữ thị giác (VLMs) và mô hình cho giọng nói, hình ảnh, video, 3D, khám phá thuốc, hình ảnh y khoa, v.v.
Các nhà phát triển có thể thử nghiệm các mô hình GenAI mới nhất bằng cách sử dụng cloud API do NVIDIA quản lý từ danh mục NVIDIA API. Hoặc họ có thể tự host các mô hình bằng cách tải xuống NIM và triển khai nhanh chóng với Kubernetes trên các nhà cung cấp đám mây lớn hoặc tại chỗ để sản xuất, cắt giảm thời gian phát triển, độ phức tạp và chi phí.
Các microservice NIM đơn giản hóa quy trình triển khai mô hình AI bằng cách đóng gói các tối ưu hóa thuật toán, hệ thống và thời gian chạy, đồng thời bổ sung các API tiêu chuẩn ngành. Điều này cho phép các nhà phát triển tích hợp NIM vào các ứng dụng và cơ sở hạ tầng hiện có của họ mà không cần tùy chỉnh chuyên sâu hoặc có chuyên môn riêng biệt.
Sử dụng NIM, các doanh nghiệp có thể tối ưu hóa cơ sở hạ tầng AI của mình để đạt hiệu quả và tiết kiệm chi phí tối đa mà không phải lo lắng về sự phức tạp trong phát triển mô hình AI và việc đóng gói. Ngoài cơ sở hạ tầng AI được tăng tốc, NIM còn giúp nâng cao hiệu suất và khả năng mở rộng, đồng thời giảm chi phí phần cứng và vận hành.
Đối với các doanh nghiệp muốn điều chỉnh mô hình cho ứng dụng doanh nghiệp, NVIDIA cung cấp các microservice để tùy chỉnh mô hình trên các lĩnh vực khác nhau. NVIDIA NeMo cung cấp khả năng tinh chỉnh bằng cách sử dụng dữ liệu độc quyền cho LLM, speech AI và các mô hình đa phương thức. NVIDIA BioNeMo tăng tốc quá trình khám phá thuốc bằng bộ sưu tập mô hình ngày càng tăng về hóa học, sinh học tổng hợp và dự đoán phân tử.
NVIDIA Picasso cho phép quy trình làm việc sáng tạo nhanh hơn với các mô hình Edify. Các mô hình này được đào tạo trên các thư viện được cấp phép từ các nhà cung cấp nội dung trực quan, cho phép triển khai các mô hình AI tạo sinh tùy chỉnh để tạo nội dung trực quan.
Bắt đầu với NVIDIA NIM
Bắt đầu với NVIDIA NIM thật dễ dàng và đơn giản. Trong danh mục NVIDIA API, các nhà phát triển có quyền truy cập vào nhiều mô hình AI có thể được sử dụng để xây dựng và triển khai các ứng dụng AI của riêng họ.
Bắt đầu tạo mẫu trực tiếp trong danh mục bằng giao diện người dùng đồ họa hoặc tương tác trực tiếp với API miễn phí. Để triển khai microservice trên hạ tầng của bạn, chỉ cần đăng ký NVIDIA AI Enterprise evaluation license 90 ngày và làm theo các bước sau.
- Tải xuống mô hình bạn muốn triển khai từ NVIDIA NGC. Trong ví dụ này, chúng tôi sẽ tải xuống phiên bản của model Llama-2 7B được xây dựng cho một GPU A100.
ngc registry model download-version “ohlfw0olaadg/ea-participants/llama-2-7b:LLAMA-2-7B-4K-FP16-1-A100.24.01”
Nếu bạn có GPU khác, bạn có thể liệt kê các phiên bản có sẵn của mô hình với ngc registry model list “ohlfw0olaadg/ea-participants/llama-2-7b:*”
2. Giải nén tạo phẩm đã tải xuống vào kho lưu trữ mô hình:
tar -xzf llama-2-7b_vLLAMA-2-7B-4K-FP16-1-A100.24.01/LLAMA-2-7B-4K-FP16-1-A100.24.01.tar.gz
3. Khởi chạy container NIM với kiểu model bạn mong muốn:
docker run –gpus all –shm-size 1G -v $(pwd)/model-store:/model-store –net=host nvcr.io/ohlfw0olaadg/ea-participants/nemollm-inference-ms:24.01 nemollm_inference_ms –model llama-2-7b –num_gpus=1
4. Sau khi NIM được triển khai, bạn có thể bắt đầu thực hiện requests bằng REST API tiêu chuẩn:
import requests endpoint = 'http://localhost:9999/v1/completions' headers = { 'accept': 'application/json', 'Content-Type': 'application/json' } data = { 'model': 'llama-2-7b', 'prompt': "The capital of France is called", 'max_tokens': 100, 'temperature': 0.7, 'n': 1, 'stream': False, 'stop': 'string', 'frequency_penalty': 0.0 } response = requests.post(endpoint, headers=headers, json=data) print(response.json())
NVIDIA NIM là một công cụ mạnh mẽ giúp các tổ chức đẩy nhanh hành trình đối với AI trong sản xuất. Hãy bắt đầu hành trình AI của bạn ngay hôm nay.
NVIDIA Developer
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale