
Các thiết kế chip mới nhất phản ánh chiều rộng và chiều sâu của những đổi mới trong nền tảng của NVIDIA ở các lĩnh vực AI, Edge và HPC.
Trong bốn buổi tọa đàm trong hai ngày, các kỹ sư cấp cao của NVIDIA sẽ mô tả những đổi mới trong lĩnh vực Điện toán tăng tốc cho các trung tâm dữ liệu hiện đại và các hệ thống tại rìa mạng.
Phát biểu tại một sự kiện ảo của Hot Chips, một hội nghị thường niên của các kiến trúc sư hệ thống và vi xử lý, họ sẽ tiết lộ các thông số hiệu suất và các chi tiết kỹ thuật khác đối với CPU máy chủ đầu tiên của NVIDIA, GPU Hopper, phiên bản mới nhất của chip kết nối nội bộ NVSwitch và System-on-Module (SoM) NVIDIA Jetson Orin.

Các bài thuyết trình cung cấp thông tin chi tiết mới về cách nền tảng NVIDIA sẽ đạt được các cấp độ hiệu suất, tính hiệu quả, quy mô và khả năng bảo mật mới.
Đặc biệt, các buổi trình bày thể hiện triết lý thiết kế đổi mới trên toàn bộ chip, hệ thống và phần mềm nơi các GPU, CPU và DPU hoạt động như các vi xử lý ngang hàng. Chúng cùng nhau tạo nên một nền tảng cho AI, phân tích dữ liệu và các tác vụ của Điện toán hiệu suất cao (HPC) bên trong các nhà cung cấp dịch vụ đám mây, các trung tâm siêu máy tính, trung tâm dữ liệu và các hệ thống tự động hóa.
Bên trong CPU máy chủ đầu tiên của NVIDIA
Các trung tâm dữ liệu yêu cầu các cụm CPU, GPU linh hoạt và các bộ tăng tốc khác chia sẻ các pool bộ nhớ khổng lồ để mang lại hiệu suất về tiết kiệm năng lượng cho nhu cầu của các tải công việc ngày nay.
Để đáp ứng nhu cầu đó, Jonathon Evans, một kỹ sư xuất sắc, làm việc 15 năm tại NVIDIA, sẽ mô tả NVIDIA NVLink-C2C. Nó kết nối các CPU và GPU ở tốc độ 900GB/s với hiệu quả năng lượng gấp 5 lần tiêu chuẩn PCIe Gen 5 hiện giờ, nhờ vào việc truyền dữ liệu chỉ tiêu thụ 1.3 picojoules/bit.
NVLink-C2C kết nối hai chip CPU để tạo ra NVIDIA Grace CPU với 144 nhân Arm Neoverse. Đó là một bộ vi xử lý được xây dựng để giải quyết các vấn đề tính toán lớn nhất của thế giới.
Để đạt hiệu quả tối đa, Grace CPU sử dụng bộ nhớ LPDDR5X. Nó cung cấp 1TB/s băng thông bộ nhớ trong khi vẫn giữ mức tiêu thụ điện năng cho toàn bộ tổ hợp ở mức 500W.
Một liên kết, nhiều công dụng
NVLink-C2C cũng liên kết các chip Grace CPU và Hopper GPU để chia sẻ bộ nhớ ngang hàng trong NVIDIA Grace Hopper Superchip, mang lại khả năng tăng tốc tối đa cho các job đòi hỏi hiệu suất như đào tạo AI.
Bất kỳ ai cũng có thể xây dựng các chiplet tùy chỉnh bằng cách sử dụng NVLink-C2C để kết nối liền mạch với các GPU, CPU, DPU và SoC của NVIDIA, mở rộng loại sản phẩm tích hợp mới này. Kết nối nội bộ này sẽ hỗ trợ các giao thức AMBA CHI và CXL được sử dụng bởi các vi xử lý Arm và x86 tương ứng.

Điểm chuẩn bộ nhớ đầu tiên của Grace và Grace Hopper
Để mở rộng quy mô ở cấp hệ thống, NVIDIA NVSwitch mới kết nối nhiều máy chủ thành một siêu máy tính AI. Nó sử dụng NVLink, kết nối nội bộ chạy ở tốc độ 900GB/s, gấp hơn 7 lần băng thông của PCIe Gen 5.
NVSwitch cho phép người dùng liên kết 32 hệ thống NVIDIA DGX H100 thành một siêu máy tính AI cung cấp 1 exaflop hiệu suất đỉnh AI.
Alexander Ishii và Ryan Wells, cả hai kỹ sư kỳ cựu của NVIDIA, sẽ mô tả cách NVLink Switch cho phép người dùng xây dựng các hệ thống lên đến 256 GPU để giải quyết các khối lượng công việc đòi hỏi khắt khe như đào tạo các mô hình AI có hơn 1 nghìn tỷ thông số.
NVLink Switch bao gồm các engine tăng tốc độ truyền dữ liệu bằng NVIDIA SHARP. SHARP là một khả năng tính toán trong mạng đã ra mắt trên các thiết bị mạng NVIDIA Quantum InfiniBand. Nó có thể tăng gấp đôi thông lượng dữ liệu trên các ứng dụng AI chuyên sâu về giao tiếp.

NVSwitch giúp tạo nên các siêu máy tính ở cấp độ exaflop
Jack Choquette, một kỹ sư ưu tú cao cấp với 14 năm làm việc tại công ty, sẽ cung cấp những thông tin chi tiết hơn về NVIDIA H100 Tensor Core GPU, hay còn gọi là Hopper.
Ngoài việc sử dụng các kết nối nội bộ mới để mở rộng quy mô lên những tầm cao mới, nó còn có nhiều tính năng nâng cao giúp tăng hiệu suất, hiệu quả và bảo mật của bộ tăng tốc.
Transformer Engine mới của Hopper và Tensor Cores được nâng cấp cung cấp tốc độ tăng gấp 30 lần so với thế hệ trước về suy luận AI với các mô hình mạng nơ-ron lớn nhất thế giới. Và nó sử dụng hệ thống bộ nhớ HBM3 đầu tiên trên thế giới để cung cấp băng thông bộ nhớ khổng lồ 3TB, mức tăng theo thế hệ lớn nhất từ trước đến nay của NVIDIA.
Trong số các tính năng mới khác:
- Hopper bổ sung hỗ trợ ảo hóa cho các cấu hình multi-tenant, multi-user.
- Các tập lệnh DPX mới tăng tốc các vòng lặp định kỳ cho các ứng dụng lập bảng chọn, phân tích DNA và protein.
- Hopper đóng gói hỗ trợ cho bảo mật nâng cao với điện toán an toàn.
Choquette, một trong những nhà thiết kế chip hàng đầu trên Nintendo64 console thuở mới vào nghề, cũng sẽ mô tả các kỹ thuật tính toán song song dưới một số tiến bộ của Hopper.
Michael Ditty, kiến trúc sư trưởng của Orin và có 17 năm làm việc tại công ty, sẽ cung cấp các thông số kỹ thuật hiệu suất mới cho NVIDIA Jetson AGX Orin, một engine dành cho edge AI, robot và các máy tự động tiên tiến.
Nó tích hợp 12 nhân Arm Cortex-A78 và GPU kiến trúc NVIDIA Ampere để cung cấp tới 275 nghìn tỷ hoạt động mỗi giây trên các job suy luận AI. Đó là hiệu suất cao hơn gấp 8 lần ở mức hiệu quả năng lượng cao hơn 2.3 lần so với thế hệ trước.
Mô-đun sản xuất mới nhất có bộ nhớ lên đến 32GB và là một phần của dòng sản phẩm tương thích với bộ công cụ dành cho nhà phát triển kích thước bỏ túi 5W Jetson Nano.
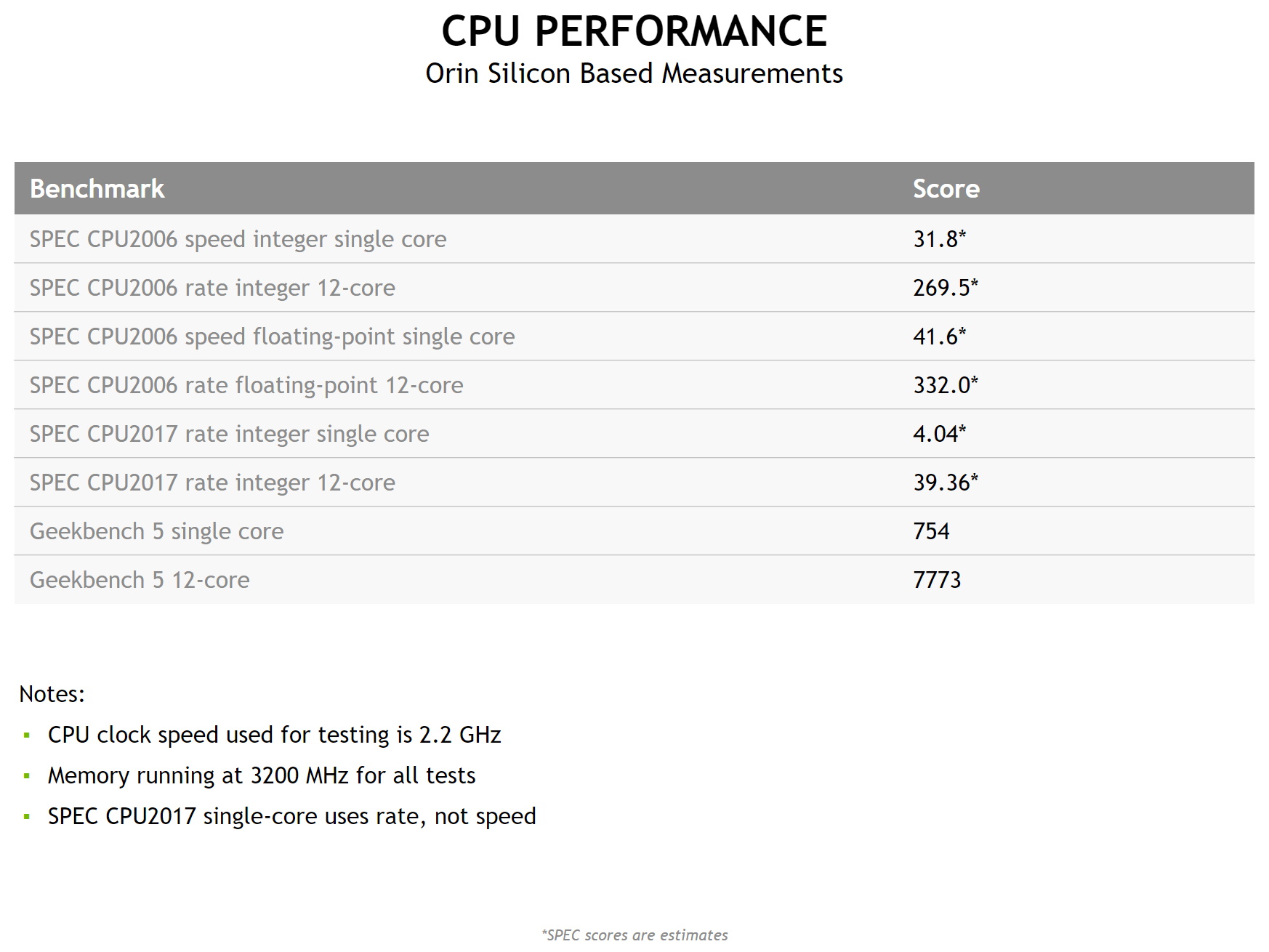
Điểm chuẩn hiệu suất cho NVIDIA Orin
Tất cả các chip mới đều hỗ trợ stack phần mềm NVIDIA giúp tăng tốc hơn 700 ứng dụng và được sử dụng bởi 2.5 triệu nhà phát triển.
Dựa trên mô hình lập trình CUDA, nó bao gồm hàng chục NVIDIA SDK cho các thị trường dọc như ô tô (DRIVE) và chăm sóc sức khỏe (Clara) cũng như các công nghệ như hệ thống khuyến nghị (Merlin) và AI hội thoại (Riva).
Theo NVIDIA
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale