
NVIDIA DGX A100 là hệ thống phổ quát cho tất cả các AI workload, cung cấp mật độ tính toán, hiệu suất và tính linh hoạt chưa từng có trong hệ thống AI 5 petaFLOPS đầu tiên trên thế giới. NVIDIA DGX A100 có bộ tăng tốc tiên tiến nhất thế giới, đó là GPU NVIDIA A100 Tensor Core dựa trên kiến trúc Ampere, cho phép các doanh nghiệp hợp nhất Training, Inference và Analytics thành một cơ sở hạ tầng AI thống nhất, dễ triển khai, bao gồm quyền truy cập trực tiếp vào cộng đồng các chuyên gia AI của NVIDIA.
Những ưu điểm của hệ thống DGX A100
DGX A100 mang lại những ưu điểm trên 04 building-block thiết yếu của một trung tâm dữ liệu AI.


Hệ thống phổ quát cho mọi AI workload
NVIDIA DGX A100 là hệ thống phổ quát cho tất cả các cơ sở hạ tầng AI, từ phân tích (analytics), đào tạo (training) đến suy luận (inference). Nó đóng gói mật độ cao các compute với hiệu suất xử lý AI lên đến 5 petaFLOPS trong một khung máy 6U, thay thế một tháp cơ sở hạ tầng chỉ bằng một nền tảng cho mọi AI workload.
DGXperts: Tích hợp quyền truy cập vào cộng đồng chuyên nghiệp AI
NVIDIA DGXperts là một nhóm toàn cầu gồm hơn 14.000 chuyên gia và lập trình viên thông thạo AI, những người đã có nhiều kinh nghiệm trong thập kỷ qua để giúp bạn tối đa hóa giá trị của khoản đầu tư cho hệ thống DGX của mình.
Thời gian nhanh nhất để giải quyết bài toán và dự án AI của bạn
DGX A100 là hệ thống AI đầu tiên trên thế giới được xây dựng trên GPU NVIDIA A100 Tensor Core. Tích hợp 8 GPU A100, hệ thống cung cấp khả năng tăng tốc chưa từng có và được tối ưu hóa hoàn toàn cho phần mềm NVIDIA CUDA-X™ và các lớp giải pháp end-to-end cho trung tâm dữ liệu NVIDIA.
Khả năng mở rộng cho trung tâm dữ liệu chưa từng có
Mở rộng trung tâm dữ liệu AI khi dữ liệu và bài toán bùng nổ là một yêu cầu không tránh khỏi. NVIDIA DGX A100 tích hợp Mellanox ConnectX-6 VPI HDR InfiniBand/Ethernet network adapters với 450GB/s băng thông hai chiều cao nhất. Đây là một trong nhiều tính năng giúp DGX A100 trở thành khối xây dựng nền tảng cho các cụm AI lớn như NVIDIA DGX SuperPOD – môt bản thiết kế Enterpise cho cơ sở hạ tầng AI có thể mở rộng.
Một số so sánh về thay đổi hiệu năng xử lý
Phân tích
PageRank – Phân tích nhanh hơn nghĩa là nắm bắt sâu sắc hơn để đẩy mạnh phát triển AI.
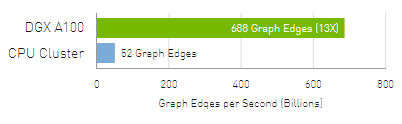
Máy chủ 3000x CPU so với 4x DGX A100. Tập dữ liệu thu thập chung đã được xuất bản: 128 tỷ edges, 2.6TB dữ liệu graph.
Đào tạo
NLP: BERT-Large – Đào tạo nhanh hơn cho phép triển khai các mô hình AI tiên tiến nhất.
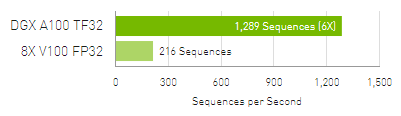
BERT Pre-Training Throughput sử dụng PyTorch bao gồm (2/3) Giai đoạn 1 và (1/3) Giai đoạn 2. Giai đoạn 1 Seq Len = 128, Giai đoạn 2 Seq Len = 512. V100: DGX-1 với 8x V100 sử dụng độ chính xác FP32. DGX A100: DGX A100 với 8x A100 sử dụng độ chính xác TF32.
Suy luận
Peak Compute – Suy luận nhanh hơn làm tăng ROI thông qua việc sử dụng hệ thống tối đa.

Máy chủ CPU: 2x Intel Platinum 8280 sử dụng INT8. DGX A100: DGX A100 với 8x A100 sử dụng INT8 với Structural Sparsity.
KHÁM PHÁ CÁC THÀNH PHẦN MẠNH MẼ CỦA DGX A100
- GPU NVIDIA A100 8 x VỚI TỔNG BỘ NHỚ GPU 320GB, 12 NVLinks / GPU, Bi-directional Bandwidth GPU-to-GPU 600 GB/s
- 6X NVIDIA NVSWITCH 4,8 TB/s
4.8 TB/s Bi-directional Bandwidth, gấp 2 lần NVSwitch thế hệ trước - 9x MELLANOX CONNECTX-6 Giao diện MẠNG 200Gb/s MẠNG 450 GB/s
450 GB/s Peak Bi-directional Bandwidth - 2x 64-CORE AMD CPU, 1TB SYSTEM MEMORY
Gấp 3.2 lần số core, để chạy cho hầu hết các job AI nặng nề nhất - 15TB GEN4 NVME SSD
25GB/s Peak Bandwidth, nhanh hơn 2x so với NVME SSD Gen3
Công nghệ bên trong NVidia DGX A100
NVIDIA A100 – Tensor Core GPU
GPU NVIDIA A100 Tensor Core mang đến khả năng tăng tốc chưa từng có cho AI, phân tích dữ liệu và tính toán hiệu năng cao (HPC) để giải quyết các thách thức điện toán khó khăn nhất của thế giới. Với NVIDIA Tensor Cores thế hệ thứ ba mang lại hiệu suất vượt trội, GPU A100 có thể mở rộng hiệu quả lên đến hàng nghìn hoặc, với Multi-Instance GPU, được phân chia thành 7x GPU nhỏ hơn, chuyên dụng để tăng tốc cho các workload ở mọi kích thước.

Multi-Instance GPU (MIG)
Với MIG, tám GPU A100 trong DGX A100 có thể được cấu hình thành tối đa 56 phiên bản GPU, mỗi GPU được cách ly hoàn toàn với bộ nhớ băng thông cao, bộ nhớ cache và lõi tính toán. Điều này cho phép quản trị viên GPU kích thước phù hợp với chất lượng dịch vụ (QoS) được đảm bảo cho nhiều khối lượng công việc.

NVLink thế hệ tiếp theo và NVSwitch
Thế hệ thứ ba của NVIDIA ® NVLink ™ trong DGX A100 tăng gấp đôi băng thông trực tiếp từ GPU đến GPU lên 600 gigabyte mỗi giây (GB / s), cao hơn gần 10 lần so với PCIe Gen4. DGX A100 cũng có NVIDIA NVSwitch ™ thế hệ tiếp theo, nhanh gấp 2 lần so với thế hệ trước.

Mellanox ConnectX-6 VPI HDR InfiniBand
DGX A100 có bộ điều hợp Mellanox ConnectX-6 VPI HDR InfiniBand / Ethernet mới nhất, mỗi bộ chạy với tốc độ 200 gigabit mỗi giây (Gb / s) để tạo ra một loại vải tốc độ cao cho khối lượng công việc AI quy mô lớn.

Tối ưu hóa software stack
DGX A100 tích hợp ngăn xếp phần mềm DGX đã được thử nghiệm và tối ưu hóa, bao gồm hệ điều hành cơ sở được điều chỉnh bằng AI, tất cả phần mềm hệ thống cần thiết và các ứng dụng được tăng tốc GPU, các mô hình được đào tạo trước và hơn thế nữa từ NGC .
Bảo mật tích hợp
DGX A100 mang đến tư thế bảo mật mạnh mẽ nhất cho việc triển khai AI, với cách tiếp cận nhiều lớp trải dài trên bộ điều khiển quản lý ván chân tường (BMC), bo mạch CPU, bo mạch GPU, ổ đĩa tự mã hóa và khởi động an toàn.
Thông số kỹ thuật NVidia DGX A100
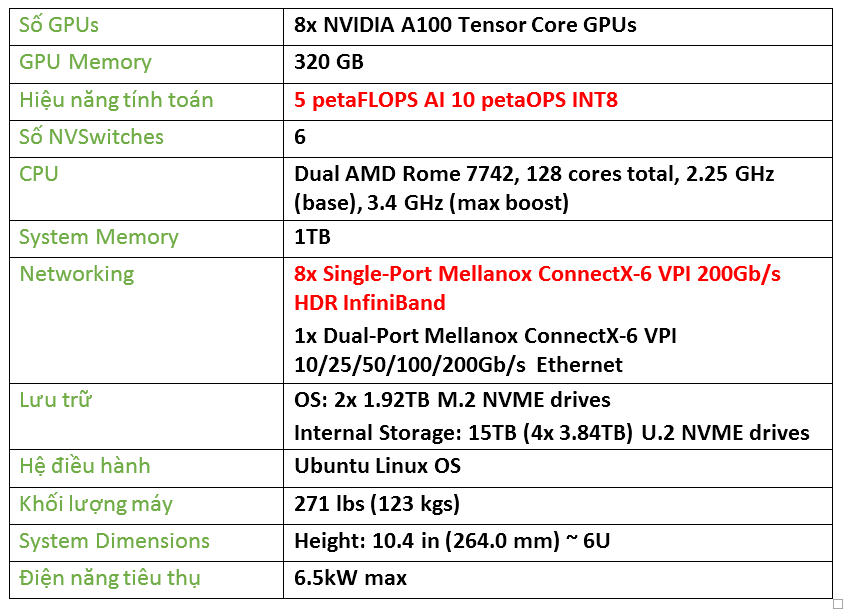
Download: DGX A100 DataSheet
Cập nhật từ các trang công nghệ
tomshardware
DGX A100 là một hệ thống cực kỳ mạnh mẽ có nhiều dấu ấn của Nvidia ở bên ngoài, và bên trong còn có AMD. Một cặp bộ xử lý AMD Epyc 7742 (tên mã Rome) là cốt lõi của sự sáng tạo ở tầm giá 199.000 USD của Nvidia.
DGX A100 sử dụng tới tám GPU trung tâm dữ liệu A100 được hỗ trợ bởi Ampere, cung cấp tới 320GB tổng bộ nhớ GPU và cung cấp khoảng 5 petaflop hiệu năng AI. A100 có thể thực hiện hầu hết các công việc nặng nhọc, phân khúc điện toán này vẫn cần một nhà dẫn đầu.
A100 tận dụng PCIe 4.0, nhưng Intel hiện không có bộ xử lý nào hỗ trợ giao diện này. AMD, mặt khác, đã công khai chấp nhận tiêu chuẩn PCIe 4.0 trên phần lớn các CPU hiện đại của nó. Nvidia cuối cùng đã tìm thấy sự thoải mái trong vòng tay của AMD, cụ thể hơn là các sản phẩm EPYC thế hệ thứ hai của AMD.
DGX A100 có hai bộ xử lý 7nm EPYC 7742. Mỗi bộ xử lý Zen 2 đi kèm với 64 lõi và 128 luồng chạy với xung nhịp cơ bản 2,25 GHz và xung nhịp tăng 3,4 GHz. Bộ đôi Epyc 7742 chiếm 128 lõi và 256 luồng trên DGX A100.
Epyc 7742 không chỉ hào phóng với lõi; Nó cũng khá nặng về bộ đệm , cung cấp tới 256 MB bộ đệm L3. Quan trọng hơn, phần 64 lõi đặt 128 làn PCIe 4.0 tốc độ cao theo ý của Nvidia.
Một hệ thống DGX A100 thông thường cũng có bộ nhớ 1TB (có thể nâng cấp lên 2TB), hai ổ SSD NVMe M.2 1.92TB trong một mảng RAID 1 cho hệ điều hành (Ubuntu Linux) và lên đến bốn 3.84TB PCIe 4.0 NVMe U.2 ổ đĩa trong một mảng RAID 0 cho kho thứ cấp. Nvidia cũng cung cấp tùy chọn thêm bốn ổ SSD bổ sung để tăng dung lượng RAID 0 từ 15TB lên đến 30TB.
DGX A100 được thiết kế với công nghệ mạng tiên tiến nhất. Nvidia gần đây đã mua lại Mellanox Technologies trong một thỏa thuận trị giá 6,9 tỷ USD và nó đã được đền đáp. DGX A100 gói tám bộ điều hợp Mellanox ConnectX-6 VPI HDR InfiniBand một cổng để phân cụm và một bộ điều hợp Ethernet ConnectX-6 VPI hai cổng để lưu trữ và sử dụng mạng. Các bộ điều hợp đã nói ở trên có khả năng cung cấp thông lượng lên tới 200 Gbps.
Liên hệ tư vấn và chào giá dự án
Hotline: +84-96-8888-388
Email: presales@nhattienchung.vn
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent
- Kiến trúc NVIDIA Blackwell với GB200 NVL72: Định nghĩa lại điện toán AI cấp độ Exascale