Mô hình ngôn ngữ lớn (LLM) là các thuật toán Học sâu (deep learning) được đào tạo trên những bộ dữ liệu quy mô Internet với hàng trăm tỷ tham số. Các LLM có thể đọc, viết, code, vẽ và tăng cường khả năng sáng tạo của con người để cải thiện năng suất trong các ngành và giải quyết các vấn đề khó khăn nhất của thế giới.
Các LLM được sử dụng trong nhiều ngành, từ bán lẻ đến chăm sóc sức khỏe và cho một loạt các tác vụ. Chúng học ngôn ngữ của các chuỗi protein để tạo ra các hợp chất mới, khả thi – có thể giúp các nhà khoa học phát triển các loại vắc-xin đột phá, cứu người. Chúng giúp các lập trình viên phần mềm tạo code và sửa lỗi dựa trên các mô tả ngôn ngữ tự nhiên. Và chúng cung cấp những công cụ đồng hành về năng suất (co-pilots) để con người có thể làm những gì họ làm tốt nhất – sáng tạo, đặt câu hỏi và hiểu biết.
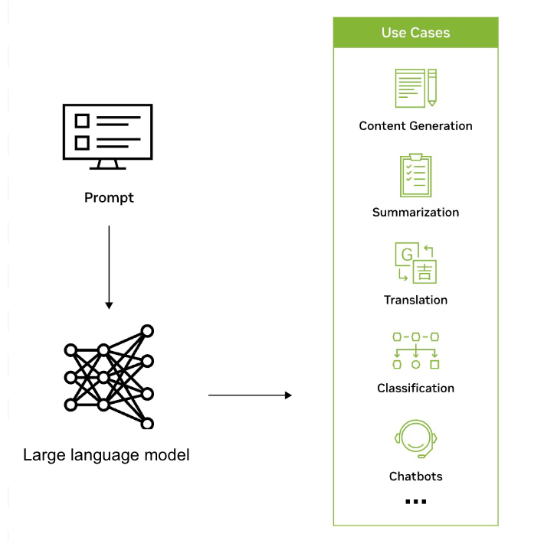
LLM được sử dụng để tạo nội dung, tóm tắt, dịch, phân loại, trả lời câu hỏi,…
Việc tận dụng hiệu quả LLM trong các ứng dụng và quy trình làm việc của doanh nghiệp đòi hỏi phải hiểu các chủ đề chính như lựa chọn mô hình, tùy chỉnh, tối ưu hóa và triển khai. Bài đăng này khám phá các chủ đề LLM doanh nghiệp sau:
- Cách các tổ chức đang sử dụng LLM
- Sử dụng, tùy chỉnh hoặc xây dựng LLM
- Bắt đầu với các mô hình nền tảng
- Xây dựng mô hình ngôn ngữ tùy chỉnh
- Kết nối LLM với dữ liệu bên ngoài
- Giữ LLM an toàn và đi đúng hướng
- Tối ưu hóa suy luận LLM trong sản xuất
- Bắt đầu sử dụng LLM
Cho dù bạn là nhà khoa học dữ liệu đang tìm cách xây dựng các mô hình tùy chỉnh hay giám đốc dữ liệu đang khám phá tiềm năng của LLM cho tổ chức của mình, hãy đọc tiếp để biết thêm thông tin hữu ích và hướng dẫn có giá trị.
Cách các tổ chức đang sử dụng LLM
LLM được sử dụng trong nhiều ứng dụng trong các ngành để nhận dạng, tóm tắt, dịch, dự đoán và tạo văn bản cũng như các hình thức khác của nội dung một cách hiệu quả dựa trên kiến thức thu được từ các bộ dữ liệu khổng lồ. Ví dụ, các công ty đang tận dụng LLM để phát triển giao diện giống chatbot có thể hỗ trợ người dùng giải đáp thắc mắc của khách hàng, đưa ra đề xuất được cá nhân hóa và hỗ trợ quản lý kiến thức nội bộ.
LLM cũng có tiềm năng mở rộng phạm vi tiếp cận của AI trong các ngành và doanh nghiệp, đồng thời tạo ra một làn sóng nghiên cứu, sáng tạo và năng suất mới. Chúng có thể giúp tạo ra các giải pháp phức tạp cho những vấn đề đầy thách thức trong các lĩnh vực như chăm sóc sức khỏe và hóa học. LLM cũng được sử dụng để tạo ra các công cụ tìm kiếm được mô phỏng lại, chatbot hướng dẫn, công cụ soạn thảo, tài liệu tiếp thị,…
Sự hợp tác giữa ServiceNow và NVIDIA sẽ giúp thúc đẩy mức độ tự động hóa mới nhằm thúc đẩy năng suất và tối đa hóa tác động kinh doanh. Các trường hợp sử dụng Generative AI đang được khám phá bao gồm phát triển các trợ lý và tác nhân ảo thông minh để giúp trả lời các câu hỏi của người dùng cũng như giải quyết các yêu cầu hỗ trợ, đồng thời sử dụng Generative AI để giải quyết vấn đề tự động, tạo bài viết về kiến thức cơ sở và tóm tắt cuộc trò chuyện.
Một tập đoàn ở Thụy Điển đang phát triển mô hình ngôn ngữ hiện đại với NVIDIA NeMo Megatron và sẽ cung cấp mô hình này cho bất kỳ người dùng nào ở khu vực Bắc Âu. Nhóm đặt mục tiêu đào tạo một LLM với con số khổng lồ là 175 tỷ tham số – có thể xử lý tất cả các loại tác vụ ngôn ngữ bằng các ngôn ngữ Bắc Âu như tiếng Thụy Điển, tiếng Đan Mạch, tiếng Na Uy và có thể là tiếng Iceland.
Dự án được coi là tài sản chiến lược, nền tảng cho chủ quyền kỹ thuật số trong một thế giới nói hàng nghìn ngôn ngữ trên gần 200 quốc gia.
Nhà cung cấp dịch vụ di động hàng đầu tại Hàn Quốc – KT, đã phát triển một LLM hàng tỷ tham số bằng việc sử dụng nền tảng NVIDIA DGX SuperPOD và NVIDIA NeMo framework. NeMo là một framework doanh nghiệp toàn diện, cloud-native, cung cấp các thành phần được dựng sẵn để xây dựng, đào tạo và chạy các LLM tùy chỉnh.
LLM của KT đã được sử dụng để nâng cao hiểu biết về loa tích hợp AI (AI-powered speaker) của công ty, GiGA Genie, có thể điều khiển TV, cung cấp thông tin cập nhật về tình hình giao thông theo thời gian thực và hoàn thành các nhiệm vụ hỗ trợ tại nhà khác dựa trên lệnh thoại.
Sử dụng, tuỳ chỉnh hoặc xây dựng LLM
Các tổ chức có thể chọn sử dụng một LLM đã có, tùy chỉnh một LLM được đào tạo trước hoặc xây dựng một LLM tùy chỉnh từ đầu. Việc sử dụng LLM đã có cung cấp giải pháp nhanh chóng và tiết kiệm chi phí, đồng thời việc tùy chỉnh LLM được đào tạo trước cho phép các tổ chức tinh chỉnh mô hình cho các tác vụ cụ thể và nhúng vào đó kiến thức độc quyền. Xây dựng một LLM từ đầu mang lại sự linh hoạt nhất nhưng đòi hỏi chuyên môn và nguồn lực đáng kể.
NeMo cung cấp nhiều lựa chọn kỹ thuật tùy chỉnh và được tối ưu hóa cho việc suy luận mô hình theo quy mô dành cho các ứng dụng ngôn ngữ và hình ảnh, với những cấu hình multi-GPU và multi-node.
NeMo giúp cho việc phát triển mô hình Generative AI trở nên dễ dàng, tiết kiệm chi phí và nhanh chóng cho các doanh nghiệp. Nó có sẵn trên tất cả các nền tảng về cloud, bao gồm Google Cloud như một phần của các A3 instance được hỗ trợ bởi NVIDIA H100 Tensor Core GPU để xây dựng, tùy chỉnh và triển khai LLM theo quy mô.
Để nhanh chóng dùng thử các mô hình GenAI như Llama 2 trực tiếp từ trình duyệt của bạn với giao diện dễ sử dụng, hãy truy cập NVIDIA AI Playground.
Bắt đầu với các mô hình nền tảng
Mô hình nền tảng (foundation model) là các mô hình AI lớn được đào tạo dựa trên số lượng lớn dữ liệu chưa được gắn nhãn thông qua quá trình học tự giám sát (self-supervised learning). Các ví dụ bao gồm Llama 2, GPT-3 và Stable Diffusion.
Các mô hình có thể xử lý nhiều tác vụ khác nhau, chẳng hạn như phân loại hình ảnh, xử lý ngôn ngữ tự nhiên (NLP) và trả lời câu hỏi với độ chính xác vượt trội.
Những mô hình nền tảng này là điểm khởi đầu để xây dựng các mô hình tùy chỉnh phức tạp và chuyên biệt hơn. Các tổ chức có thể tùy chỉnh các mô hình nền tảng bằng cách sử dụng dữ liệu được gắn nhãn theo domain cụ thể để tạo thêm mô hình chính xác và nhận biết ngữ cảnh cho các trường hợp sử dụng cụ thể.
Các mô hình nền tảng tạo ra một số lượng lớn phản hồi độc đáo từ một lời nhắc đơn lẻ (single prompt) bằng cách tạo phân phối xác suất trên tất cả các kết quả có thể tuân theo đầu vào và sau đó chọn ngẫu nhiên đầu ra tiếp theo từ phân phối đó. Sự ngẫu nhiên hóa được khuếch đại nhờ việc sử dụng bối cảnh của mô hình. Mỗi lần mô hình tạo ra phân phối xác suất, nó sẽ xem xét kết quả được tạo cuối cùng, nghĩa là mỗi dự đoán sẽ tác động đến mọi dự đoán tiếp theo.
NeMo hỗ trợ các mô hình nền tảng do NVIDIA đào tạo cũng như các mô hình cộng đồng như Llama 2, Falcon LLM và MPT. Bạn có thể trải nghiệm miễn phí nhiều cộng đồng được tối ưu hóa và các mô hình nền tảng do NVIDIA xây dựng trực tiếp từ trình duyệt của bạn trên NVIDIA AI Playground. Sau đó, bạn có thể tùy chỉnh mô hình nền tảng bằng cách sử dụng dữ liệu doanh nghiệp độc quyền của mình. Kết quả mang lại có thể là một mô hình hoạt động như một chuyên gia trong lĩnh vực và doanh nghiệp của bạn.
Xây dựng mô hình ngôn ngữ tùy chỉnh
Các doanh nghiệp thường sẽ cần các mô hình tùy chỉnh để điều chỉnh khả năng xử lý ngôn ngữ cho phù hợp với các trường hợp sử dụng cụ thể và chuyên môn của họ. Các LLM tùy chỉnh cho phép doanh nghiệp tạo và hiểu văn bản hiệu quả và chính xác hơn trong bối cảnh một ngành hoặc tổ chức nhất định.
Chúng trao quyền cho các doanh nghiệp để tạo các giải pháp được cá nhân hóa phù hợp với tiếng nói thương hiệu của họ, tối ưu hóa quy trình làm việc, cung cấp thông tin chi tiết chính xác hơn và mang lại trải nghiệm nâng cao cho người dùng, cuối cùng là thúc đẩy lợi thế cạnh tranh trên thị trường.
NVIDIA NeMo là một framework mạnh mẽ cung cấp các thành phần để xây dựng và đào tạo LLM tùy chỉnh tại chỗ, trên tất cả các nhà cung cấp dịch vụ đám mây hàng đầu hoặc trong NVIDIA DGX Cloud. Nó bao gồm một bộ kỹ thuật tùy chỉnh từ học nhanh (prompt learning) đến tinh chỉnh tham số hiệu quả cho đến học tăng cường (reinforcement learning) thông qua phản hồi của con người (RLHF). NVIDIA cũng phát hành một kỹ thuật tùy chỉnh mở, mới có tên là SteerLM cho phép điều chỉnh trong quá trình suy luận.
Khi đào tạo một LLM, luôn có nguy cơ nó trở thành “garbage in, garbage out”. Phần lớn nỗ lực là thu thập và quản lý dữ liệu sẽ được sử dụng để đào tạo hoặc tùy chỉnh LLM.
NeMo Data Curator là một công cụ quản lý dữ liệu có thể mở rộng, cho phép bạn quản lý các bộ dữ liệu đa ngôn ngữ có hàng nghìn tỷ token để đào tạo trước LLM. Công cụ này cho phép bạn tiền xử lý và chống trùng lặp các bộ dữ liệu, nhờ đó, bạn có thể đảm bảo rằng các mô hình được đào tạo trên các tài liệu độc nhất, có khả năng giúp giảm đáng kể chi phí đào tạo.
Kết nối LLM với dữ liệu bên ngoài
Việc kết nối một LLM với các nguồn dữ liệu doanh nghiệp bên ngoài sẽ nâng cao khả năng của nó. Điều này cho phép LLM thực hiện các nhiệm vụ phức tạp hơn và tận dụng dữ liệu đã được tạo kể từ lần đào tạo gần đây nhất.
Retrieval Augmented Generation (RAG) là kiến trúc cung cấp cho một LLM với khả năng sử dụng các nguồn dữ liệu hiện tại, được quản lý, theo miền cụ thể – dễ dàng thêm, xóa và cập nhật. Với RAG, các nguồn dữ liệu bên ngoài được xử lý thành các vectơ (sử dụng một embedding model) và được đặt vào một cơ sở dữ liệu vectơ để truy xuất nhanh tại thời điểm suy luận.
Ngoài việc giảm chi phí tính toán và tài chính, RAG còn tăng độ chính xác và hỗ trợ các ứng dụng có tích hợp AI đáng tin cậy hơn. Tăng tốc tìm kiếm vectơ là một trong những chủ đề nóng nhất trong bối cảnh AI do các ứng dụng của nó trong LLM và Generative AI.
Giữ LLM an toàn và đi đúng hướng
Để đảm bảo hành vi của một LLM phù hợp với kết quả mong muốn, điều quan trọng là phải thiết lập các nguyên tắc, giám sát hiệu suất của LLM và tùy chỉnh khi cần thiết. Điều này liên quan đến việc xác định ranh giới đạo đức, giải quyết các thiên vị trong dữ liệu đào tạo và thường xuyên đánh giá kết quả đầu ra của mô hình theo các số liệu được xác định trước, thường phối hợp với khả năng của guardrails.
Để giải quyết nhu cầu này, NVIDIA đã phát triển NeMo Guardrails, một bộ công cụ nguồn mở giúp các nhà phát triển đảm bảo các ứng dụng GenAI của họ là chính xác, phù hợp, an toàn. Nó cung cấp một framework hoạt động với tất cả LLM, bao gồm cả ChatGPT của OpenAI, để giúp các nhà phát triển dễ dàng xây dựng các hệ thống đàm thoại LLM an toàn và đáng tin cậy hơn để tận dụng các mô hình nền tảng.
Việc giữ an toàn cho LLM là điều hết sức quan trọng đối với các ứng dụng được hỗ trợ bởi GenAI. NVIDIA cũng đã giới thiệu Confidential Computing được tăng tốc, một tính năng bảo mật đột phá giúp giảm thiểu các mối đe dọa đồng thời cung cấp quyền truy cập vào khả năng tăng tốc chưa từng có của NVIDIA H100 Tensor Core GPU cho tác vụ AI. Tính năng này đảm bảo rằng dữ liệu nhạy cảm vẫn an toàn và được bảo vệ, ngay cả trong quá trình xử lý.
Tối ưu hóa suy luận LLM trong sản xuất
Tối ưu hóa suy luận LLM bao gồm các kỹ thuật như lượng tử hóa mô hình, tăng tốc phần cứng và chiến lược triển khai hiệu quả. Lượng tử hóa mô hình làm giảm mức chiếm dụng bộ nhớ của mô hình, trong khi khả năng tăng tốc phần cứng tận dụng phần cứng chuyên dụng như GPU để suy luận nhanh hơn. Chiến lược triển khai hiệu quả đảm bảo khả năng mở rộng và độ tin cậy trong các môi trường sản xuất.
NVIDIA TensorRT-LLM là thư viện phần mềm nguồn mở giúp tăng cường khả năng suy luận LLM lớn trên điện toán tăng tốc (accelerated computing) của NVIDIA. Nó cho phép người dùng chuyển đổi trọng lượng mô hình của họ sang định dạng FP8 mới và biên dịch mô hình của họ để tận dụng các kernel FP8 được tối ưu hóa với NVIDIA H100 GPU. TensorRT-LLM có thể tăng tốc hiệu suất suy luận lên 4.6 lần so với NVIDIA A100 GPU. Nó cung cấp một cách nhanh hơn và hiệu quả hơn để chạy LLM, giúp chúng dễ tiếp cận hơn và tiết kiệm chi phí hơn.
Các quy trình GenAI tùy chỉnh này bao gồm việc tập hợp các mô hình, framework, bộ công cụ,… Nhiều công cụ trong số này là nguồn mở, đòi hỏi thời gian và năng lượng để duy trì các dự án phát triển. Quá trình này có thể trở nên cực kỳ phức tạp và tốn thời gian, đặc biệt là khi cố gắng cộng tác và triển khai trên nhiều môi trường và nền tảng.
NVIDIA AI Workbench giúp đơn giản hóa quy trình này bằng cách cung cấp một nền tảng duy nhất để quản lý dữ liệu, mô hình, tài nguyên và nhu cầu tính toán. Điều này cho phép các nhà phát triển cộng tác và triển khai liền mạch để nhanh chóng tạo ra các mô hình GenAI có khả năng mở rộng và tiết kiệm chi phí.
NVIDIA và VMware đang hợp tác cùng nhau để chuyển đổi trung tâm dữ liệu hiện đại được xây dựng trên VMware Cloud Foundation và đưa AI đến mọi doanh nghiệp. Bằng cách sử dụng bộ NVIDIA AI Enterprise cũng như các GPU và DPU tiên tiến nhất của NVIDIA, khách hàng của VMware có thể chạy một cách an toàn các tác vụ hiện đại, được tăng tốc cùng với các ứng dụng doanh nghiệp hiện có, trên các Hệ thống được NVIDIA chứng nhận.
Bắt đầu sử dụng LLM
Bắt đầu với LLM đòi hỏi phải cân nhắc các yếu tố như chi phí, nỗ lực, tính sẵn có của dữ liệu đào tạo và mục tiêu kinh doanh. Các tổ chức nên đánh giá sự cân bằng giữa việc sử dụng các mô hình hiện có và tùy chỉnh chúng bằng kiến thức chuyên môn cụ thể so với việc xây dựng các mô hình tùy chỉnh từ đầu trong hầu hết các trường hợp. Việc chọn các công cụ và framework phù hợp với các trường hợp sử dụng cụ thể và yêu cầu kỹ thuật là điều quan trọng, bao gồm cả những yêu cầu được liệt kê bên dưới.
Lab Generative AI Knowledge Base Chatbot chỉ cho bạn cách điều chỉnh mô hình nền tảng AI hiện có để tạo ra phản hồi chính xác cho use case cụ thể của bạn. Lab miễn phí này cung cấp trải nghiệm thực tế về việc tùy chỉnh mô hình sử dụng học nhanh, nhập dữ liệu vào cơ sở dữ liệu vectơ và xâu chuỗi tất cả các thành phần để tạo một chatbot.
NVIDIA AI Enterprise, có sẵn trên tất cả các nền tảng trung tâm dữ liệu và cloud lớn, là bộ phần mềm phân tích dữ liệu và AI cloud-native, cung cấp hơn 50 framework, bao gồm cả NeMo framework, các mô hình được đào tạo trước và các công cụ phát triển được tối ưu hóa cho hạ tầng GPU được tăng tốc. Bạn có thể dùng thử bộ phần mềm toàn diện dành cho doanh nghiệp này với bản dùng thử miễn phí 90 ngày.
NeMo là một framework doanh nghiệp cloud-native, toàn diện dành cho các nhà phát triển để xây dựng, tùy chỉnh và triển khai các mô hình GenAI với hàng tỷ tham số. Nó được tối ưu hóa cho khả năng suy luận theo quy mô của các mô hình với những cấu hình multi-GPU và multi-node. Framework này giúp cho việc phát triển mô hình GenAI trở nên dễ dàng, tiết kiệm chi phí và nhanh chóng cho các doanh nghiệp. Khám phá hướng dẫn về NeMo để bắt đầu.
NVIDIA Training giúp các tổ chức đào tạo nhân lực của họ về công nghệ mới nhất và thu hẹp khoảng cách kỹ năng bằng cách cung cấp các khóa học và hội thảo thực hành kỹ thuật toàn diện. Lộ trình học tập LLM do các chuyên gia trong lĩnh vực của NVIDIA phát triển bao gồm các chủ đề từ cơ bản đến nâng cao, phù hợp với nhóm vận hành IT và kỹ sư phần mềm. NVIDIA Training Advisors luôn sẵn sàng giúp phát triển các kế hoạch đào tạo tùy chỉnh và đưa ra mức giá học theo nhóm phù hợp.
Kết luận
Khi các doanh nghiệp chạy đua để bắt kịp với những tiến bộ của AI, việc xác định cách tiếp cận tốt nhất để áp dụng LLM là điều cần thiết. Các mô hình nền tảng giúp khởi động quá trình phát triển. Việc sử dụng các công cụ và môi trường chính để xử lý và lưu trữ dữ liệu cũng như tùy chỉnh các mô hình một cách hiệu quả có thể tăng tốc đáng kể năng suất và nâng cao các mục tiêu kinh doanh.
Theo NVIDIA
Bài viết liên quan
- Giới thiệu giải pháp Training AI trên các máy chủ thông dụng
- PowerScale: Nền tảng kiến trúc cho các tác vụ Generative AI
- NVIDIA Hopper tiếp tục dẫn đầu hiệu suất Generative AI trong MLPerf
- NVIDIA hỗ trợ hành trình hướng tới Generative AI thuận lợi hơn cho các doanh nghiệp
- NVIDIA NIM: Vi dịch vụ suy luận tối ưu hóa cho triển khai mô hình AI quy mô lớn
- Đơn giản hóa phát triển Generative AI tuỳ chỉnh với NVIDIA NeMo Microservices