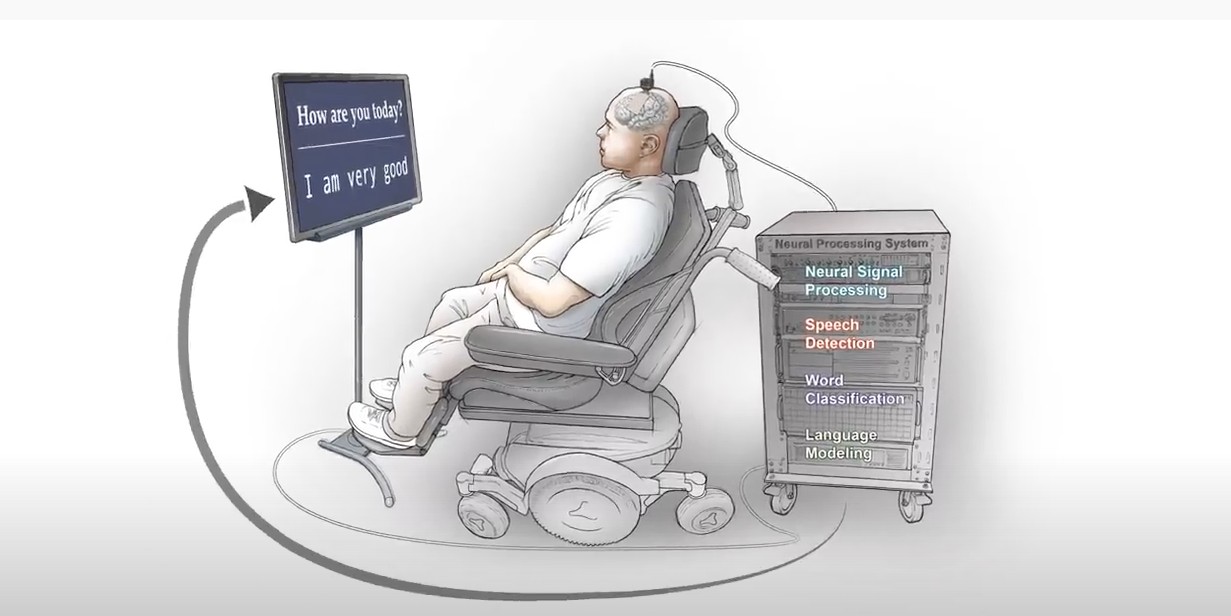
Nghiên cứu mới của Đại học California, San Francisco đã cho một người đàn ông bị liệt khả năng giao tiếp bằng cách chuyển các tín hiệu não của anh ấy thành chữ viết do máy tính tạo ra. Nghiên cứu được công bố trên tạp chí The New England Journal of Medicine, đánh dấu một cột mốc quan trọng trong việc khôi phục khả năng giao tiếp cho những người mất khả năng nói.
“Theo hiểu biết của chúng tôi, đây là minh chứng thành công đầu tiên về việc giải mã trực tiếp các từ đầy đủ từ hoạt động não của một người bị liệt và không thể nói được,” tác giả cấp cao và Chủ tịch phẫu thuật thần kinh Joan và Sanford Weill tại UCSF, Edward Chang cho biết trong một thông cáo báo chí. “Nó cho thấy sự hứa hẹn rõ nét trong việc khôi phục khả năng giao tiếp bằng cách khai thác vào cơ chế lời nói tự nhiên của bộ não”.

Một số người bị hạn chế về giọng nói sử dụng các thiết bị hỗ trợ – chẳng hạn như màn hình cảm ứng, bàn phím hoặc máy tính tạo giọng nói để giao tiếp. Tuy nhiên, hàng năm có hàng nghìn người mất khả năng nói do tê liệt hoặc tổn thương não, khiến họ không thể sử dụng các công nghệ hỗ trợ.
Người tham gia thử nghiệm bị mất khả năng nói vào năm 2003, anh bị liệt do đột quỵ não sau một tai nạn xe hơi. Các nhà nghiên cứu không chắc liệu bộ não của anh ấy có duy trì hoạt động thần kinh liên quan đến lời nói hay không. Để theo dõi các tín hiệu não của anh ấy, một thiết bị theo dõi thần kinh bao gồm các điện cực được đặt ở bên trái của não, qua một số vùng được biết đến để xử lý giọng nói.
Trong khoảng bốn tháng, nhóm bắt đầu thực hiện 50 buổi đào tạo, trong đó người tham gia được nhắc nói các từ riêng lẻ, đặt câu hoặc trả lời các câu hỏi trên màn hình hiển thị. Trong khi phản hồi các lời nhắc, thiết bị điện cực ghi lại hoạt động thần kinh và truyền thông tin đến máy tính có phần mềm tùy chỉnh.
“Các mô hình của chúng tôi cần thiết để học cách lập bản đồ giữa các mô hình hoạt động phức tạp của não và lời nói theo dự định. Điều đó đặt ra một thách thức lớn khi người tham gia không thể nói chuyện, ”David Moses, một kỹ sư sau tiến sĩ tại phòng thí nghiệm Chang và là một trong những tác giả chính của nghiên cứu, cho biết trong một thông cáo báo chí.
Để giải mã các phản ứng từ hoạt động não của cậu ấy, nhóm đã tạo ra các mô hình phát hiện giọng nói và phân loại từ. Sử dụng TensorFlow framework được tăng tốc bởi cuDNN và 32x GPU NVIDIA V100 Tensor Core, các nhà nghiên cứu đã đào tạo, tinh chỉnh, và đánh giá liên tục các mô hình được phát triển.
Sean Metzger, đồng trưởng nhóm nghiên cứu cho biết: “Việc sử dụng mạng nơ-ron là điều cần thiết để đạt được hiệu suất phân loại và phát hiện cao nhất, và sản phẩm cuối cùng của chúng tôi là kết quả của rất nhiều thử nghiệm. Vì tập dữ liệu của chúng tôi không ngừng phát triển và lớn mạnh, nên việc có thể điều chỉnh các mô hình chúng tôi đang sử dụng là rất quan trọng. GPU đã giúp chúng tôi thực hiện các thay đổi, theo dõi tiến trình và hiểu tập dữ liệu mà chúng tôi có”.
Với độ chính xác lên đến 93% và tỷ lệ trung bình là 75%, mô hình đã giải mã ngôn từ của những người tham gia thử nghiệm với tốc độ lên đến 18 từ mỗi phút.
“Chúng tôi muốn đạt đến 1.000 từ, và cuối cùng là tất cả các từ khả dụng. Đây chỉ là điểm khởi đầu”, Chang nói.
Nghiên cứu được xây dựng dựa trên công trình trước đó của Chang và các đồng nghiệp của ông, đã phát triển một phương pháp học sâu để giải mã và chuyển đổi tín hiệu não. Không giống như công trình hiện tại đề cập ở trên, những người tham gia của đợt nghiên cứu trước đây vẫn còn có khả năng phát âm.
Xem thêm nội dung của bài báo viết về công trình tại đây.
Nguồn NVIDIA Blog
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?