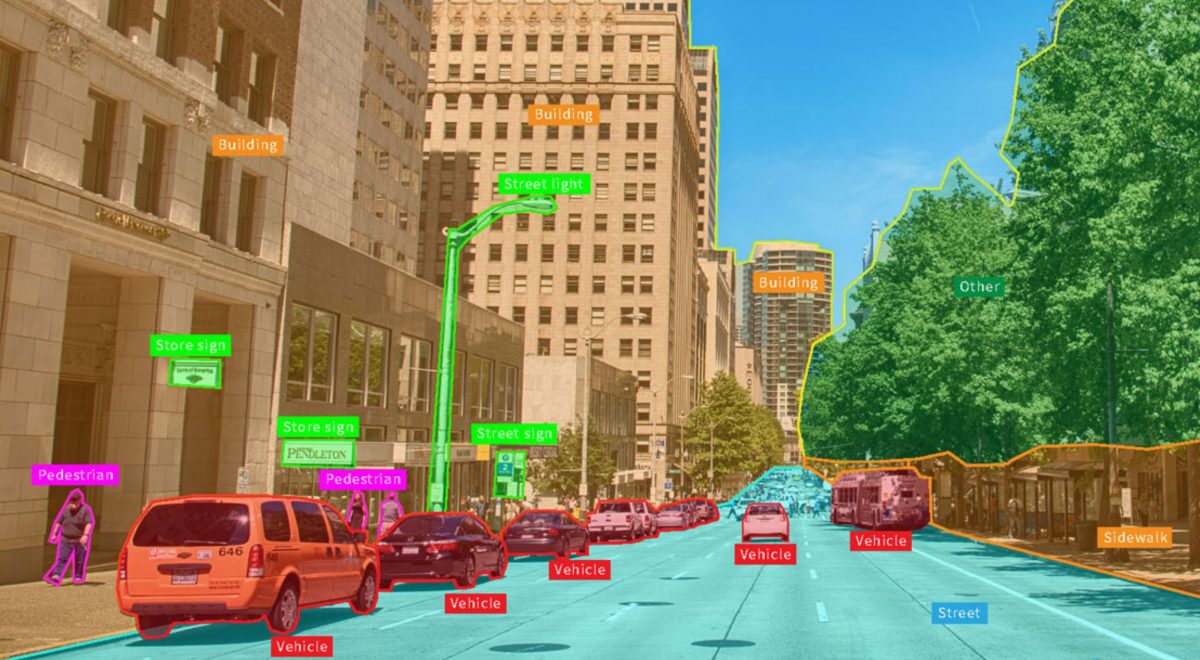
Thị giác máy tính (Computer Vision) là một trong những lĩnh vực hot nhất của khoa học máy tính và nghiên cứu trí tuệ nhân tạo. Dù chúng vẫn chưa thể cạnh tranh với sức mạnh thị giác của mắt người, đã có rất nhiều ứng dụng hữu ích được tạo ra khai thác tiềm năng của chúng.
Khi bạn nhìn vào hình ảnh sau đây, bạn sẽ thấy người, vật thể và các tòa nhà. Nó mang đến những ký ức về những trải nghiệm trong quá khứ, những tình huống tương tự bạn gặp phải. Đám đông đang đối mặt cùng hướng và giơ điện thoại lên, điều này cho bạn biết rằng đây là một loại sự kiện. Người đứng gần máy ảnh đang mặc áo thun gợi ý về sự kiện có thể xảy ra. Khi bạn nhìn vào các chi tiết nhỏ khác, bạn có thể suy ra nhiều thông tin hơn từ hình ảnh.

Nhưng đối với máy tính, hình ảnh này giống như tất cả các hình ảnh khác, đó là một mảng các pixel, các giá trị số đại diện cho các sắc độ của màu đỏ, xanh lá cây và xanh dương. Một trong những thách thức mà các nhà khoa học máy tính phải vật lộn từ những năm 1950s là tạo ra những cỗ máy có thể hiểu được hình ảnh và video như con người. Lĩnh vực thị giác máy tính từ đó đã trở thành một trong những lĩnh vực nghiên cứu hot nhất về khoa học máy tính và trí tuệ nhân tạo.
Nhiều thập kỷ sau, chúng ta đã đạt được tiến bộ lớn trong việc tạo ra các phần mềm có thể hiểu và mô tả nội dung của dữ liệu một cách trực quan. Nhưng chúng ta cũng đã nhận ra rằng cần phải đi xa đến mức nào trước khi có thể hiểu và tái tạo một trong những chức năng cơ bản của bộ não con người.

Sơ lược về lịch sử thị giác máy tính
Năm 1966, Seymour Papert và Marvin Minsky, hai nhà tiên phong về trí tuệ nhân tạo, đã khởi động một dự án mang tên “Summer Vision Project“, một nỗ lực kéo dài hai tháng và kéo theo 10 người để tạo ra một hệ thống máy tính có thể nhận dạng các vật thể trong ảnh.
Để hoàn thành nhiệm vụ, một chương trình máy tính phải có khả năng xác định pixel nào thuộc về đối tượng nào. Đây là một vấn đề mà hệ thống thị giác của con người, được cung cấp bởi kiến thức rộng lớn của chúng ta về thế giới thực và hàng tỷ năm tiến hóa, có thể giải quyết một cách dễ dàng. Nhưng đối với máy tính, thế giới chỉ bao gồm các con số, đó là một nhiệm vụ đầy thách thức.
Vào thời điểm của dự án này, phân nhánh thống trị chủ lực của trí tuệ nhân tạo là symbollic AI, còn được gọi là AI dựa trên quy tắc (rule-based AI): Các lập trình viên tự chỉ định các quy tắc để phát hiện các đối tượng trong hình ảnh. Nhưng vấn đề là các vật thể trong ảnh có thể xuất hiện từ các góc khác nhau và trong nhiều điều kiện ánh sáng khác nhau. Đối tượng có thể xuất hiện trên một loạt các nền khác nhau hoặc bị các đối tượng khác che khuất một phần. Mỗi kịch bản này tạo ra các giá trị pixel khác nhau và thực tế không thể tạo quy tắc thủ công cho từng cái một trong số chúng.
Hẳn nhiên, Summer Vision Project đã không đi xa và mang lại kết quả khá hạn chế. Vài năm sau đó, vào năm 1979, nhà khoa học Nhật Bản Kunihiko Fukushima đã đề xuất neocognitron , một hệ thống thị giác máy tính dựa trên nghiên cứu khoa học thần kinh được thực hiện trên vỏ não về thị giác của con người. Mặc dù neocognitron của Fukushima không thể thực hiện bất kỳ nhiệm vụ trực quan phức tạp nào, nhưng nó đã đặt nền tảng cho một trong những phát triển quan trọng nhất trong lịch sử thị giác máy tính.
Cuộc cách mạng học sâu – Deep Learning
Vào những năm 1980s, nhà khoa học máy tính người Pháp Yan LeCun đã giới thiệu mạng thần kinh tích chập (convolutional neural network, CNN), một hệ thống AI lấy cảm hứng từ neocognitron của Fukushima. Một CNN bao gồm nhiều lớp tế bào thần kinh nhân tạo, các thành phần toán học mô phỏng gần giống hoạt động của các phiên bản sinh học của chúng.

Khi một CNN xử lý một hình ảnh, mỗi lớp của nó sẽ trích xuất các đặc trưng cụ thể từ các pixel. Lớp đầu tiên phát hiện những thứ rất cơ bản, chẳng hạn như các cạnh dọc và ngang. Khi bạn di chuyển sâu hơn vào mạng thần kinh, các lớp sẽ phát hiện các đặc trưng phức tạp hơn, bao gồm các góc và hình dạng. Các lớp cuối cùng của CNN phát hiện những thứ cụ thể như khuôn mặt, cánh cửa và xe hơi. Lớp đầu ra của CNN cung cấp một bảng các giá trị số biểu thị xác suất mà một đối tượng cụ thể được phát hiện trong ảnh.
Mạng thần kinh tích chập của LeCun rất tuyệt vời và cho thấy rất nhiều hứa hẹn, nhưng chúng bị cản trở bởi một vấn đề nghiêm trọng: Điều chỉnh và sử dụng chúng đòi hỏi một lượng lớn dữ liệu và tài nguyên tính toán không có sẵn tại thời điểm đó. CNN cuối cùng đã tìm thấy việc sử dụng thương mại trong một số lĩnh vực hạn chế như ngân hàng và dịch vụ bưu chính, nơi chúng được sử dụng để xử lý các chữ số và chữ viết tay trên phong bì và các tờ séc. Nhưng trong lĩnh vực nhận diện đối tượng, họ đã thất bại và nhường chỗ cho các kỹ thuật học máy khác, như ‘support vector machines’ và ‘random forests’.
Vào năm 2012, các nhà nghiên cứu AI từ Toronto đã phát triển AlexNet, một mạng thần kinh tích chập chiếm ưu thế trong cuộc thi nhận dạng hình ảnh ImageNet nổi tiếng. Chiến thắng của AlexNet cho thấy với sự gia tăng sẵn có của dữ liệu và tài nguyên điện toán, có lẽ đã đến lúc phải trở lại với CNN. Sự kiện này đã làm hồi sinh sự quan tâm đến các CNN và tạo ra một cuộc cách mạng trong Deep Learning, phân nhánh của Machine Learning liên quan đến việc sử dụng các mạng thần kinh nhân tạo nhiều lớp.
Nhờ những tiến bộ trong mạng thần kinh tích chập và học sâu, từ đó, lĩnh vực thị giác máy tính đã phát triển nhờ những bước nhảy vọt.
Ứng dụng của Thị giác Máy tính
Nhiều ứng dụng bạn sử dụng hàng ngày sử dụng công nghệ thị giác máy tính. Google sử dụng nó để giúp bạn tìm kiếm các đối tượng và cảnh vật như là, “con chó” hoặc “hoàng hôn” trong một thư viện hình ảnh của bạn. Các công ty khác sử dụng thị giác máy tính để giúp nâng cao hình ảnh. Một ví dụ là Adobe Lightroom CC, sử dụng thuật toán Machine Learning để tăng cường chi tiết của hình ảnh được phóng to. Cơ chế phóng to (zoom in) truyền thống sử dụng các kỹ thuật nội suy để tô màu các khu vực được phóng to, nhưng Lightroom sử dụng thị giác máy tính để phát hiện các đối tượng trong hình ảnh và làm sắc nét các đặc trưng của chúng sau khi được phóng to.
Một lĩnh vực đã đạt được tiến bộ rõ rệt nhờ những tiến bộ trong thị giác máy tính là nhận diện khuôn mặt. Apple sử dụng thuật toán nhận dạng khuôn mặt để mở khóa iPhone. Facebook sử dụng nhận dạng khuôn mặt để phát hiện người dùng trong ảnh bạn đăng lên mạng (mặc dù không phải ai cũng thích điều này). Tại Trung Quốc, nhiều nhà bán lẻ hiện cung cấp công nghệ thanh toán qua nhận diện khuôn mặt, giúp khách hàng không cần phải tiếp cận với túi tiền của họ.
Những tiến bộ trong nhận dạng khuôn mặt cũng gây ra lo lắng cho những người ủng hộ quyền riêng tư, đặc biệt là khi các cơ quan chính phủ ở các quốc gia khác nhau đang sử dụng nó để giám sát công dân của họ.
Chuyển sang các lĩnh vực chuyên biệt hơn, thị giác máy tính nhanh chóng trở thành một công cụ không thể thiếu trong y học. Các thuật toán học sâu đang cho thấy độ chính xác ấn tượng trong việc phân tích hình ảnh y tế. Các bệnh viện và trường đại học đang sử dụng thị giác máy tính để dự đoán các loại ung thư khác nhau bằng cách kiểm tra tia X và quét MRI.
Xe tự lái cũng phụ thuộc rất nhiều vào thị giác máy tính để hiểu được môi trường xung quanh. Các thuật toán học sâu phân tích các nguồn cấp dữ liệu video từ các camera được cài đặt trên xe và phát hiện người, xe hơi, mặt đường và các vật thể khác để giúp chiếc xe di chuyển trong môi trường của nó.
Những hạn chế của Thị giác Máy tính
Các hệ thống thị giác máy tính hiện tại thực hiện tốt việc phân loại hình ảnh và bản địa hóa các đối tượng trong ảnh, khi chúng được đào tạo đầy đủ với các ví dụ. Nhưng ở phần cốt lõi của chúng, các thuật toán học sâu cung cấp sức mạnh cho các ứng dụng thị giác máy tính chính là việc đối chiếu các mẫu pixel. Chúng không hiểu những gì đang diễn ra trong các hình ảnh.
Việc hiểu mối quan hệ giữa người và đối tượng trong dữ liệu trực quan đòi hỏi phải có các cảm nhận và các kiến thức cơ bản chung. Đó là lý do tại sao các thuật toán thị giác máy tính được sử dụng bởi các mạng xã hội có thể phát hiện các nội dung khỏa thân, nhưng thường phải khó khăn để phân biệt sự khác biệt giữa ảnh khoả thân an toàn (ví dụ cho con bú hoặc nghệ thuật Phục hưng) và nội dung bị cấm như nội dung khiêu dâm. Tương tự như vậy, thật khó để các thuật toán này nói lên sự khác biệt giữa tuyên truyền cực đoan và một phim tài liệu về các nhóm cực đoan!
Con người có thể khai thác kiến thức rộng lớn về thế giới của mình để lấp đầy những lỗ hổng khi họ đối mặt với một tình huống mà họ chưa từng thấy trước đây. Không giống như con người, các thuật toán thị giác máy tính cần phải được hướng dẫn kỹ lưỡng về các loại đối tượng mà chúng phải phát hiện. Ngay khi môi trường của chúng chứa những thứ đi chệch khỏi các ví dụ đã được đào tạo, chúng bắt đầu hành động theo những cách phi lý, chẳng hạn như không phát hiện ra các phương tiện khẩn cấp dừng đỗ ở những vị trí khác thường.
Hiện tại, giải pháp duy nhất để giải quyết những vấn đề này là đào tạo các thuật toán AI trên với ngày càng nhiều các ví dụ, với hy vọng lượng dữ liệu bổ sung sẽ bao quát mọi tình huống mà AI sẽ gặp phải. Nhưng những kinh nghiệm cho thấy, nếu không có sự nhận thức theo tình huống, sẽ luôn có những góc khuất trong những tình huống hiếm hoi làm rối loạn thuật toán AI.
Nhiều chuyên gia tin rằng chúng ta sẽ chỉ đạt được thị giác máy tính thực sự khi chúng ta tạo ra trí thông minh chung nhân tạo (artificial general intelligence), AI có thể giải quyết các vấn đề theo cách tương tự như con người. Như nhà khoa học máy tính và nhà nghiên cứu AI Melanie Mitchell đã nói trong cuốn sách Trí thông minh nhân tạo: Hướng dẫn về tư duy con người: “Dường như trí thông minh thị giác không dễ tách rời khỏi phần còn lại của trí thông minh, đặc biệt là kiến thức chung, sự trừu tượng và kỹ năng ngôn ngữ. Thêm vào đó, có thể các kiến thức cần thiết cho trí thông minh thị giác của con người không thể học được từ hàng triệu bức ảnh được tải xuống từ web, nhưng phải được trải nghiệm theo một cách nào đó trong thế giới thực”.
Lược dịch từ PCMag
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- Hướng dẫn lựa chọn GPU phù hợp cho AI, Machine Learning
- Phân tích video thông minh – Intelligent Video Analytics: Tương lai của mọi ngành
- 5 điều bạn cần biết về NVIDIA DGX Spark – Chiếc máy tính mơ ước của các nhà phát triển AI