
Sự ra mắt của NVIDIA Jetson Thor đã tạo nên một cơn địa chấn trong cộng đồng AI và robotics, với tuyên bố về hiệu suất lên đến 2070 TFLOPS, một con số vốn chỉ thấy ở các hệ thống data center. Điều này không thể không dẫn đến sự so sánh trực tiếp với các GPU máy chủ mạnh mẽ như NVIDIA L4 và L40S. Tuy nhiên, đằng sau cuộc đua AI TOPS là một câu chuyện về kiến trúc, mục đích thiết kế và hệ sinh thái hoàn toàn khác biệt.
Đây không phải là một cuộc chiến “AI hơn AI“, mà là một phân tích về việc “chọn đúng công cụ cho đúng việc“. Hãy cùng “mổ xẻ” xem Jetson Thor, L4, và L40S thực sự dành cho ai.
Edge AI (AI Biên) vs Data Center (Trung Tâm Dữ Liệu)
Trước khi đi vào chi tiết, chúng ta cần phân định rõ hai “chiến trường” mà các sản phẩm này thống trị:
- Data Center (Nơi ở của L4/L40S): Đây là “bộ não” trung tâm, nơi có nguồn điện dồi dào, hệ thống làm mát chuyên dụng và không gian không giới hạn. Các máy chủ ở đây xử lý các tác vụ khổng lồ, huấn luyện các mô hình AI phức tạp, và phục vụ hàng triệu yêu cầu cùng lúc.
- Edge (Nơi ở của Jetson Thor): Đây là “hệ thần kinh” tại chỗ, hoạt động ngay trên thiết bị như robot, xe tự hành, hoặc thiết bị y tế. Chúng bị giới hạn nghiêm ngặt về năng lượng (thường dùng pin), không gian (phải nhỏ gọn), và yêu cầu phản hồi thời gian thực (real-time) mà không thể chờ dữ liệu gửi về data center.
Jetson Thor là một “bộ não” AI hoàn chỉnh được thiết kế để nhúng vào máy móc. L4 và L40S là các “bộ tăng tốc” (accelerator) cắm vào máy chủ. Đây là khác biệt cơ bản nhất.
So Sánh: Jetson Thor vs L4/L40S
| NVIDIA Jetson AGX Thor | NVIDIA L4 | NVIDIA L40S | |
| Mục Tiêu Chính | AI Vật Lý (Physical AI), Robotics, Máy móc Tự hành | AI Inference Hiệu Suất Cao, Video, Đồ họa | Universal GPU Data Center, Huấn luyện & Suy luận GenAI, HPC |
| Kiến Trúc | System-on-Chip (SoC) | GPU PCIe (Rời rạc) | GPU PCIe (Rời rạc) |
| GPU | NVIDIA Blackwell | NVIDIA Ada Lovelace | NVIDIA Ada Lovelace |
| CPU | 14-core Arm Neoverse | Không có | Không có |
| Bộ Nhớ | 128 GB LPDDR5X (Hợp nhất)
273 GB/s |
24 GB GDDR6 (Rời rạc)
300 GB/s |
48 GB GDDR6 (Rời rạc)
864 GB/s |
| Hiệu Suất AI | 2070 FP4 TFLOPS | 485 TFLOPS (FP8) | 1466 TFLOPS (FP8) |
| Công Suất (TDP) | 40W – 130W | 72W | 350W |
| Hệ Sinh Thái | JetPack 7, NVIDIA Isaac, Holoscan | NVIDIA AI Enterprise, CUDA, TensorRT | NVIDIA AI Enterprise, CUDA, TensorRT |
| Kết Nối Chính | 4x 25GbE (Sensor Fusion), I/O cho robot | 2x 10GbE (Kết nối mạng) | 3x DisplayPort (Đồ họa/Omniverse) |
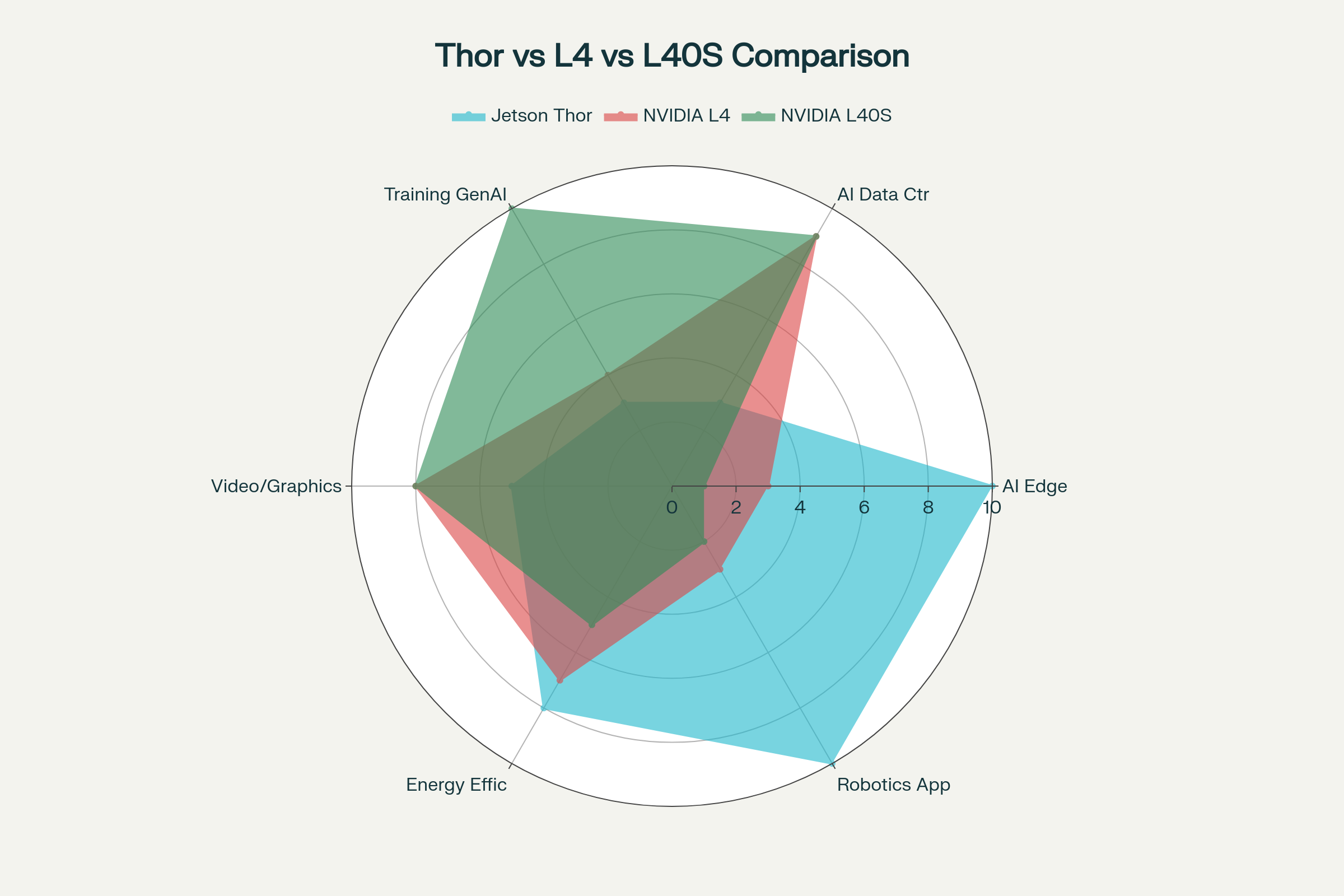
Phân Tích: “Bộ Não” vs “Cơ Bắp”
Bảng so sánh cho thấy rõ: Jetson Thor không phải là đối thủ cạnh tranh, mà là một đối tác bổ trợ cho L4/L40S trong một hệ sinh thái AI toàn diện.
Kiến Trúc: SoC Toàn Diện vs. GPU Chuyên Dụng
Đây là điểm khác biệt “chí mạng” nhất.
- Jetson Thor là một SoC (System-on-Chip): Nó là một chiếc máy tính hoàn chỉnh. Bên trong con chip là cả CPU, GPU, và bộ nhớ. CPU Arm 14 nhân không chỉ để “chạy cho có”, mà là một bộ xử lý mạnh mẽ để chạy hệ điều hành, xử lý các tác vụ I/O phức tạp và các thuật toán robotics (như lập kế hoạch, điều khiển) theo thời gian thực.
- L4/L40S là GPU PCIe: Chúng là những “cỗ máy” tăng tốc chuyên dụng, chỉ làm một việc: tính toán song song. Chúng hoàn toàn “mù” nếu không có một CPU chủ (thường là Intel Xeon hoặc AMD EPYC) ra lệnh.
Điểm mấu chốt: Bộ nhớ 128GB LPDDR5X của Thor là bộ nhớ hợp nhất (Unified Memory). CPU và GPU “nhìn” thấy chung một vùng nhớ, cho phép sao chép dữ liệu gần như bằng không. Đây là yếu tố sống còn cho các ứng dụng robot, nơi dữ liệu từ cảm biến (do CPU xử lý) phải được đưa đến GPU để suy luận AI ngay lập tức.
Hiệu Suất AI: PetaFLOPs Thời Gian Thực vs. PetaFLOPs Huấn Luyện
Tại sao một con chip 130W lại có hiệu suất “PetaFLOPs” ngang ngửa một card 350W?
- Jetson Thor 2070 TFLOPS: Con số này đến từ kiến trúc Blackwell mới , hỗ trợ các định dạng số mới như FP4/FP8 và Transformer Engine. Đây là hiệu suất được tối ưu cho suy luận (Inference). Webinar cũng chỉ rõ Jetson Thor có thể tăng tốc GenAI lên 7 lần nhờ vLLM và speculative decoding. Mục tiêu là chạy các mô hình GenAI, VLM (Vision Language Models) phức tạp ngay trên robot để nó có thể “hiểu” lệnh bằng ngôn ngữ tự nhiên (“lấy cho tôi chai nước màu đỏ”) .
- L40S 1485 TFLOPS: Đây là hiệu suất (FP8) cho cả huấn luyện (Training) và suy luận (Inference). Với băng thông bộ nhớ 864 GB/s (gấp 3 lần Thor), L40S được sinh ra để “nghiền” hàng Terabyte dữ liệu, huấn luyện các mô hình ngôn ngữ lớn (LLM) từ đầu.
- L4 485 TFLOPS: L4 không đua TFLOPs. Nó là “vua” về hiệu quả/watt, được tối ưu cho suy luận mật độ cao, đặc biệt là xử lý (decode/encode) hàng chục luồng video AI cùng lúc.
Hệ Sinh Thái: Robot (Isaac) vs. Máy Chủ (NVIDIA AI Enterprise)
Phần mềm quyết định tất cả.
- Jetson Thor: Chạy JetPack 7 , một HĐH hoàn chỉnh với Jetson Linux. Quan trọng hơn, nó là nền tảng của NVIDIA Isaac để mô phỏng và triển khai robot, và NVIDIA Holoscan cho các thiết bị y tế và cảm biến thời gian thực. Thor được thiết kế để kết nối trực tiếp với cảm biến qua Holoscan Sensor Bridge (HSB) với độ trễ cực thấp.
- L4/L40S: Chạy trên HĐH máy chủ (Linux/Windows) và được quản lý bởi bộ phần mềm NVIDIA AI Enterprise. Chúng là nền tảng cho các mô hình nền tảng (Foundation Models), Omniverse (tạo Digital Twin) và các ứng dụng data center.
Kết luận
Việc so sánh Jetson Thor với L4/L40S giống như so sánh bộ não của một vận động viên Olympic với một nhà máy sản xuất giày. Cả hai đều liên quan đến “chạy”, nhưng ở hai thái cực hoàn toàn khác nhau.
Hãy chọn NVIDIA L4/L40S nếu bạn:
- Cần xây dựng, huấn luyện (L40S) hoặc tinh chỉnh (fine-tune) các mô hình AI/GenAI lớn.
- Cần một “nhà máy” AI để xử lý hàng ngàn yêu cầu inference từ xa (L4, L40S).
- Xây dựng một Digital Twin phức tạp trong Omniverse.
- Đang xây dựng một hệ thống máy chủ trong Data Center.
Hãy chọn NVIDIA Jetson Thor nếu bạn:
- Đang chế tạo một robot hình người , robot tự hành (AMR) , drone, hoặc thiết bị phẫu thuật.
- Cần chạy các mô hình GenAI/VLM phức tạp ngay trên thiết bị mà không có kết nối mạng.
- Cần xử lý và tổng hợp dữ liệu từ nhiều cảm biến (camera, LiDAR) với độ trễ siêu thấp (nhờ 4x 25GbE và HSB ).
- Cần một hệ thống “tất-cả-trong-một” (CPU + GPU + Memory) mạnh mẽ nhưng tiết kiệm điện.
Bạn đang xây dựng một robot hình người, hay một siêu máy tính AI trong data center? Hãy chia sẻ dự án của bạn để chúng tôi sẽ giúp bạn chọn “vũ khí” phù hợp nhất!
Bài viết liên quan
- QNAP QAI-h1290FX – Máy chủ Edge AI All-Flash cho LLM riêng, RAG và AI tạo sinh
- GoodVision Real-time Traffic Video Analytics: Tối Ưu Hoá Giao Thông Thông Minh Với Lanner Edge AI
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- QNAP ra mắt Máy chủ Lưu trữ Edge AI: Cuộc cách mạng triển khai trí tuệ nhân tạo tại chỗ cho doanh nghiệp