
Nhận diện khuôn mặt là một trong những ứng dụng phổ biến nhất của thị giác máy tính, được sử dụng trong nhiều lĩnh vực như giám sát an ninh, kiểm soát truy cập, điểm danh, và tương tác người–máy. Trong bài viết này, chúng ta sẽ tìm hiểu cách cài đặt môi trường và huấn luyện mô hình nhận diện khuôn mặt FaceDetect – một mô hình đã được NVIDIA huấn luyện trước (pretrained), tối ưu cho bài toán phát hiện khuôn mặt trong nhiều điều kiện khác nhau.
Chúng ta sẽ sử dụng TAO Toolkit – nền tảng huấn luyện chuyển giao (Transfer Learning) chính thức của NVIDIA, chạy trong Docker, giúp tăng tốc quá trình huấn luyện mô hình AI mà không cần viết lại từ đầu.
Yêu cầu hệ thống
Trước khi bắt đầu chúng ta hãy cùng xem qua yêu cầu của hệ thống cái đã nhé:
Về phần mềm
Lần này mình sẽ tiếp tục hướng dẫn các bạn với hệ điều hành Ubuntu phiên bản 24.04.1. Ngoài ra các bạn vui lòng kiểm tra xem thử máy mình có đủ điều kiện sau đây không:
- Driver NVIDIA: >= 525.xx
*Đây là điều kiện bắt buộc các bạn phải có mới có thể sử dụng được các thư viện và công cụ của NVIDIA - Python: >= 3.7 (bạn nên cài đặt Python trước để sử dụng cho những phần sau)
- Docker: >= 20.10
- NVIDIA Container Toolkit: để docker có thể truy cập GPU
Về phần cứng
Nếu các bạn đang còn là học sinh, sinh viên hoặc là các nhà nghiên cứu đơn lẻ muốn tìm hiểu về AI cụ thể là các mô hình của NVIDIA thì dưới đây là đề xuất về phần cứng của các bạn:
- GPU: ít nhất là 1 GPU có thể thuộc các dòng GeForce RTX 2060 trở lên
- VRAM: >= 6GB
- RAM: >= 8GB ( đề xuất 16GB )
- CPU: >= 4 nhân
- SSD: >= 30GB trống
Nếu các bạn là doanh nghiệp hoặc là một tổ chức đang triển khai thực tế thì dưới đây là đề xuất của mình về phần cứng dành cho bạn:
- GPU: ít nhất là 1 GPU ví dụ như A100, A30, RTX 6000 Ada
- VRAM: >= 24GB
- RAM: >= 64GB
- CPU: 16 nhân
- SSD: >= 1TB trống
Lí do mình đưa ra đề xuất về phần cứng và phần mềm như này vì đối với học sinh, sinh viên hay các nhà nghiên cứu độc lập việc có một chiếc máy tính có GPU rời dòng RTX từ 2060 trở lên là hoàn toàn có thể chạy ổn. Điều quan trọng nhất là GPU cần có 6GB VRAM trở lên để tránh lỗi khi nạp mô hình. RAM hệ thống tầm 8GB vẫn chạy được nhưng nếu bạn mở thêm notebook hay 1 tác vụ khác như xử lý dữ liệu song song thì 16GB sẽ thoải mái hơn. SSD đã được chứng minh là có tốc độ truy xuất nhanh hơn nhiều so với HDD nên khi tải mô hình hay log huấn luyện sẽ giúp cho việc huấn luyện trở nên nhanh hơn.
Còn về doanh nghiệp và các tổ chức đang triển khai thực tế thì sẽ khác. Các GPU như A100, A30 hoặc dòng RTX 6000 Ada có hiệu suất cao và được tối ưu cho deep learning. Việc bạn có 24GB VRAM trở lên bạn có thể xử lý 1 lượng batch lớn, việc fine-tune mô hình cũng sẽ không bị giới hạn bộ nhớ. Với mức RAM 64GB trở lên thì việc huấn luyện hoặc xử lý các pipeline phức tạp sẽ trở nên mượt mà hơn giúp bạn không phải lo về việc đầy bộ nhớ cộng với việc CPU nhiều nhân cũng sẽ giúp giảm nghẽn khi bạn vừa phải huấn luyện, vừa phải ghi lại kết quả và vừa phải kiểm tra mô hình cùng lúc. Việc bạn sở hữu SSD 1TB trở lên sẽ phù hợp hơn để bạn có thể lưu trữ một lượng lớn dữ liệu huấn luyện, các phiên bản mô hình,…
Sau khi bạn đáp ứng được nhu cầu về hệ thống thì chúng ta tiếp tục với bước tiếp theo nhé.
Tải và huấn luyện mô hình FaceDetect
Ở đây mình sẽ hướng dẫn các bạn chạy mô hình trực tiếp từ notebook facenet.ipynb – nằm trong bộ cv_samples của TAO Toolkit. Thay vì phải tự code từ đầu, chúng ta chỉ cần mở notebook này, chỉnh vài thông số, chạy huấn luyện, là xong!
Lưu ý: Mặc dù chạy notebook giúp đơn giản hoá thao tác, nhưng vẫn sẽ tốn tài nguyên máy – đặc biệt là GPU và RAM, vì toàn bộ quá trình training vẫn đang diễn ra thật ở phía sau.
Bây giờ chúng ta cùng bắt đầu nhé:
Đầu tiên các bạn tải giúp mình công cụ NGC CLI của NVIDIA.
Tải và giải nén:
wget https://ngc.nvidia.com/downloads/ngccli_linux.zip unzip ngccli_linux.zip && cd ngc-cli
Giải nén xong hãy di chuyển đến thư mục, cấp quyền và thêm vào path:
cd ngccli/ngc-cli #Cấp quyền chmod u+x ngc #Thêm vào path export PATH=$PATH:$(pwd)
Xong các bước trên bạn kiểm tra lại bằng lệnh:
ngc --version
Nếu như kết quả trả về giống như ảnh dưới đây thì bạn đã thành công.
![]()
Sau khi cài đặt xong hãy mở Terminal của Ubuntu hoặc bất kì hệ điều hành nào bạn đang sử dụng miễn là đang chạy trên nền Linux.
Chúng ta bắt đầu tải notebook về từ NGC:
ngc registry resource download-version "nvidia/tao/cv_samples:v1.4.1"
Tải xong, bạn hãy sử dụng câu lệnh:
ls
Bạn sẽ thấy thư mục tên cv_samples_vv1.4.1 như ảnh dưới đây.
![]()
Tiếp theo các bạn hãy tạo một môi trường ảo để tránh bị xung đột với hệ thống bằng cách:
python -m venv env37
Với ” env37 ” là tên của môi trường ảo bạn có thể đổi tên tùy thích.
Tạo xong môi trường ảo hãy kích hoạt nó bằng lệnh:
source env37/bin/activate
Lưu ý: bạn phải đứng tại vị trí bạn tạo môi trường ảo ví dụ mình đang đứng tại home/lab như ảnh dưới đây:

Nếu các bạn không biết mình đang đứng ở đâu trong thư mục thì có thể kiểm tra bằng lệnh:
pwd
Còn nếu các bạn không nhớ đã tạo môi trường ảo trong thư mục nào thì có thể tìm bằng lệnh:
find ~ -type f -name "activate" 2>/dev/null | grep "/bin/activate"
Lệnh này sẽ trả về 1 đường dẫn và bạn có thể di chuyển đến thư mục đó ví dụ kết quả trả về là
” /home/lab/env37/bin/activate “
Thì phía trước ” /bin/activate ” đó chính là thư mục cha cũng chính là thư mục môi trường ảo mà bạn đang cần tìm.
Khi kích hoạt môi trường ảo ở phía đầu của command line của bạn sẽ xuất hiện tên của môi trường ảo:
![]()
Tiếp theo bạn hãy tải jupyter notebook về môi trường ảo:
pip install jupyter notebook
Tùy vào tốc độ mạng của bạn thì notebook sẽ tải nhanh hay chậm, sau khi tải xong bạn có thể mở notebook của cv_samples ở trên bằng cách di chuyển vào thư mục đó và gõ:
jupyter notebook --ip 0.0.0.0 --no-browser --allow-root
Lệnh này sẽ trả về kết quả như ảnh dưới đây:
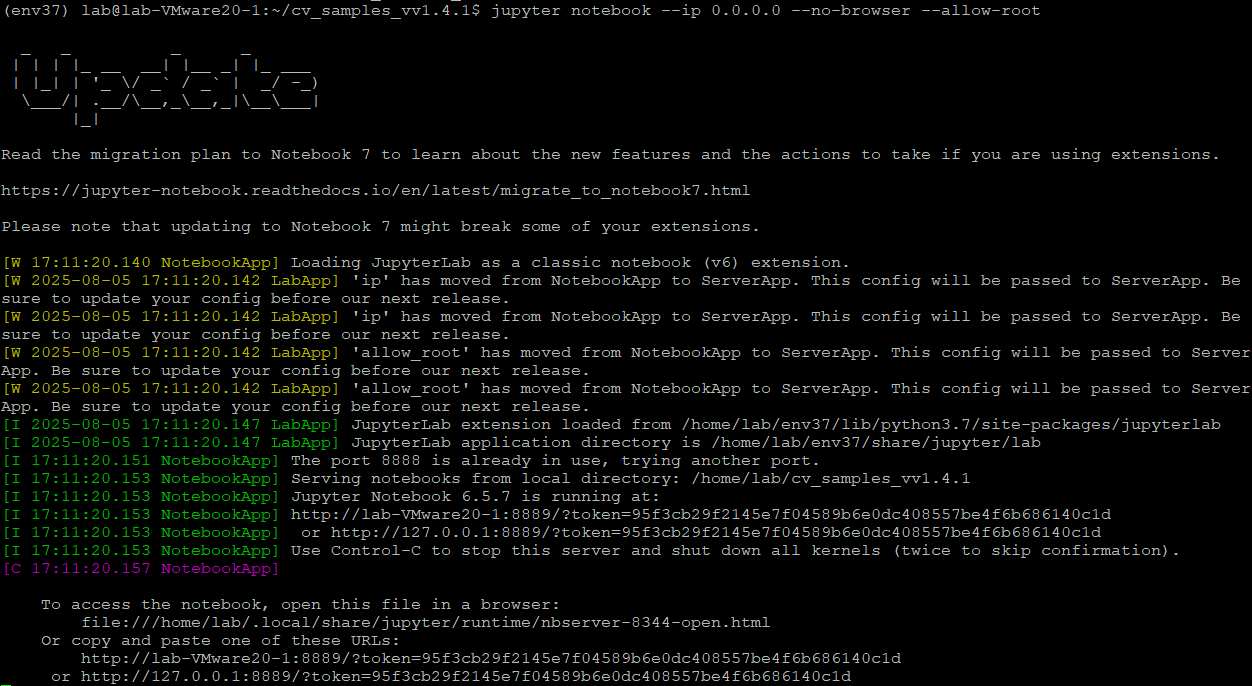
Bạn chỉ cần để ý 2 dòng cuối. Copy một trong hai đường URL được cung cấp và dán vào trình duyệt bất kỳ để mở notebook.. Tuy nhiên bạn cần thay đổi lại về đường dẫn ví dụ như mình sẽ copy url là
" http://127.0.0.1:8889/?token=95f3cb29f2145e7f04589b6e0dc408557be4f6b686140c1d "
thì mình cần phải đổi 127.0.0.1 bằng ip của máy mình thì mới có thể truy cập được, nếu bạn không biết ip máy mình là bao nhiêu thì có thể gõ trong command line của linux
ifconfig
Nhưng bạn có để ý là khi chạy jupyter notebook như vậy bạn đã bị mất command line rồi thì bạn sẽ phải làm như thế nào, rất dễ, bạn có thể chạy jupyter bằng nohup
nohup jupyter notebook --ip 0.0.0.0 --no-browser --allow-root > jupyter.log 2>&1 &
Lệnh này sẽ giúp bạn chạy notebook mà không bị chiếm command line. Nó sẽ chỉ trả về 1 dòng duy nhất như sau:
" [1] 12345 "
Việc chạy nohup vẫn sẽ tiếp diễn kể cả khi bạn đóng terminal, điều này sẽ đặc biệt hữu ích khi chạy notebook từ server hoặc SSH và ” & ” ở cuối câu lệnh sẽ giúp jupyter notebook được chạy nền nên là hãy để ý và dừng nếu bạn không còn sử dụng nhé. Một điểm đáng lưu ý ở đây là ghi chạy nohup bạn sẽ không biết liệu rằng có lỗi gì xuất hiện hay không vì mình đã set chạy nền cho nên ” > jupyter.log ” sẽ lưu trữ lại toàn bộ log của jupyter notebook, nếu bạn muốn xem log bạn có thể mở bằng url và xem hoặc xem trực tiếp trên terminal bằng lệnh:
cat jupyter.log
Vậy để kiểm tra xem notebook nào đang chạy thì như nào? Lại quá dễ bạn chỉ cần vẫn còn ở trong môi trường ảo của bạn và gõ lệnh:
jupyter notebook list
Lệnh sẽ trả về danh sách url notebook đang chạy. Và nếu muốn dừng bạn chỉ cần gõ:
jupyter notebook stop <số port>
Ví dụ port ở trên là 8889, số 8889 chính là cổng mà notebook đang chạy và để dừng thì mình sẽ nhập lệnh là:
" jupyter notebook stop 8889 "
Đợi 1 lát sẽ có dòng thông báo xác nhận notebook đã được dừng.
Sau khi truy cập được vào notebook, ở đó sẽ có vô số mô hình mà bạn có thể lựa chọn:
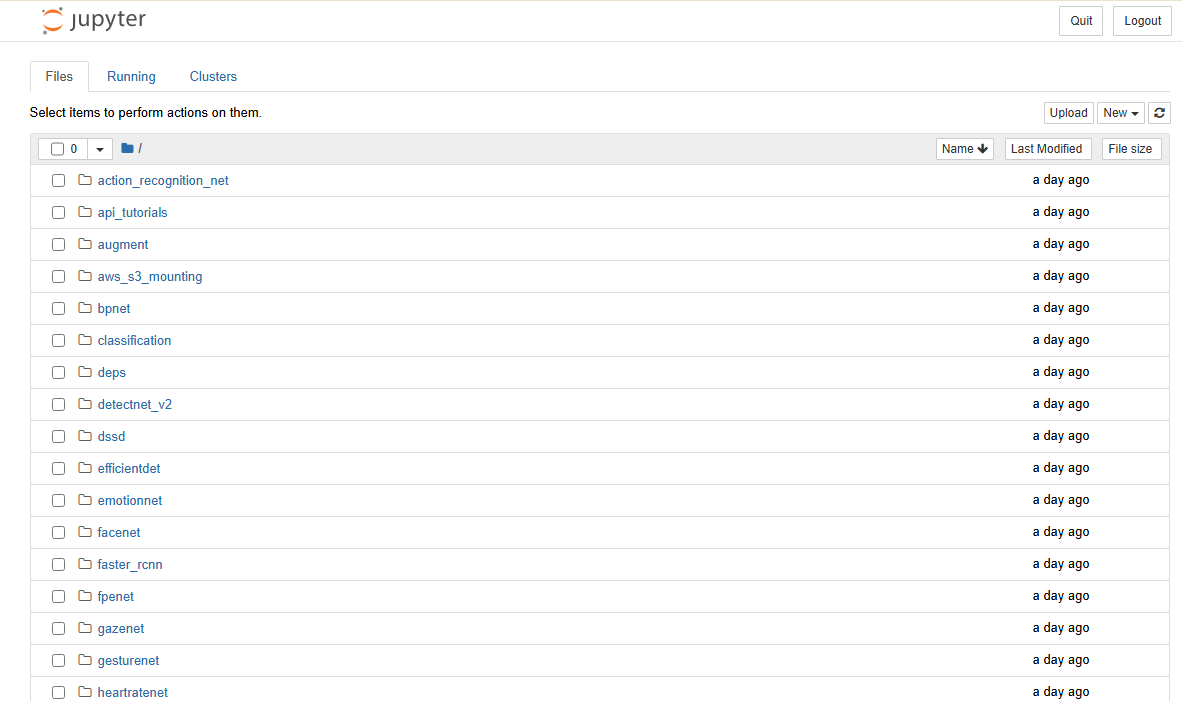
Ở đây mình sẽ chọn mô hình facenet, hãy mở folder facenet và bạn sẽ thấy 1 file facenet.ipynb, đây chính là notebook mà chúng ta tìm, mở nó lên và bạn sẽ thấy hướng dẫn chi tiết từng bước từ yêu cầu về các phần mềm đến cài đặt môi trường và mô hình face detect. Các bạn hãy đọc và làm theo hướng dẫn mà notebook đã đưa ra.
Ở cuối notebook sẽ hướng dẫn các bạn export sang định dạng file của TAO là .etlt tuy nhiên nếu bạn muốn triển khai thực tế thì bạn phải chuyển sang định dạng .engine hoặc .tlt.
Bài hướng dẫn của mình đến đây đã hết rồi. Nếu các bạn muốn tích hợp mô hình sau khi huấn luyện vào ứng dụng thực tế thì đừng bỏ qua bài tiếp theo nhé. Ở bài tới mình cũng sẽ hướng dẫn các bạn cách chuyển định dạng file .etlt sang định dạng .engine để triển khai thực tế. Và bây giờ chúc các bạn thành công với việc huấn luyện mô hình Face Detect.
Mọi thắc mắc có thể liên hệ mình thông qua email: anldb@nhattienchung.vn
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?