
Trong thế giới điện toán hiệu năng cao (HPC) và Trí tuệ nhân tạo (AI), cuộc đua không chỉ dừng lại ở sức mạnh xử lý của từng GPU riêng lẻ. Nút thắt cổ chai thực sự, hay “uzkoye mesto” như các kỹ sư thường gọi, nằm ở khả năng giao tiếp và trao đổi dữ liệu giữa các nhân xử lý. Khi các mô hình AI ngày càng phình to, chạm ngưỡng hàng nghìn tỷ tham số, việc đảm bảo một kết nối siêu tốc, độ trễ thấp giữa các GPU trở thành yếu tố sống còn.
NVIDIA, với vị thế dẫn đầu trong ngành, đã đưa ra câu trả lời đanh thép cho thách thức này qua việc ra mắt NVLink thế hệ thứ 5, một công nghệ kết nối chuyên dụng hứa hẹn định hình lại kiến trúc của các trung tâm dữ liệu AI trong tương lai.

NVLink 5.0: Phá vỡ mọi giới hạn băng thông
NVLink không phải là một khái niệm mới, nhưng thế hệ thứ 5 thực sự là một cuộc cách mạng. Hãy cùng đi sâu vào các thông số kỹ thuật ấn tượng của nó:
- Băng thông mỗi GPU: 1.8 Terabyte mỗi giây (TB/s), một con số khổng lồ, gấp đôi so với thế hệ thứ 4 (900 GB/s) trên kiến trúc Hopper.
- Số lượng liên kết: Mỗi GPU kiến trúc Blackwell hỗ trợ tới 18 liên kết NVLink, mỗi liên kết cung cấp băng thông hai chiều 100 GB/s.
- Sức mạnh vượt trội so với PCIe: Để dễ hình dung, băng thông 1.8 TB/s của NVLink 5.0 cao hơn tới 14 lần so với chuẩn PCIe 5.0 (x16) và gấp 7 lần so với PCIe 6.0 (x16). Điều này cho thấy PCIe, dù đa dụng, nhưng không còn là giải pháp tối ưu cho giao tiếp GPU-to-GPU trong các cụm AI quy mô lớn.
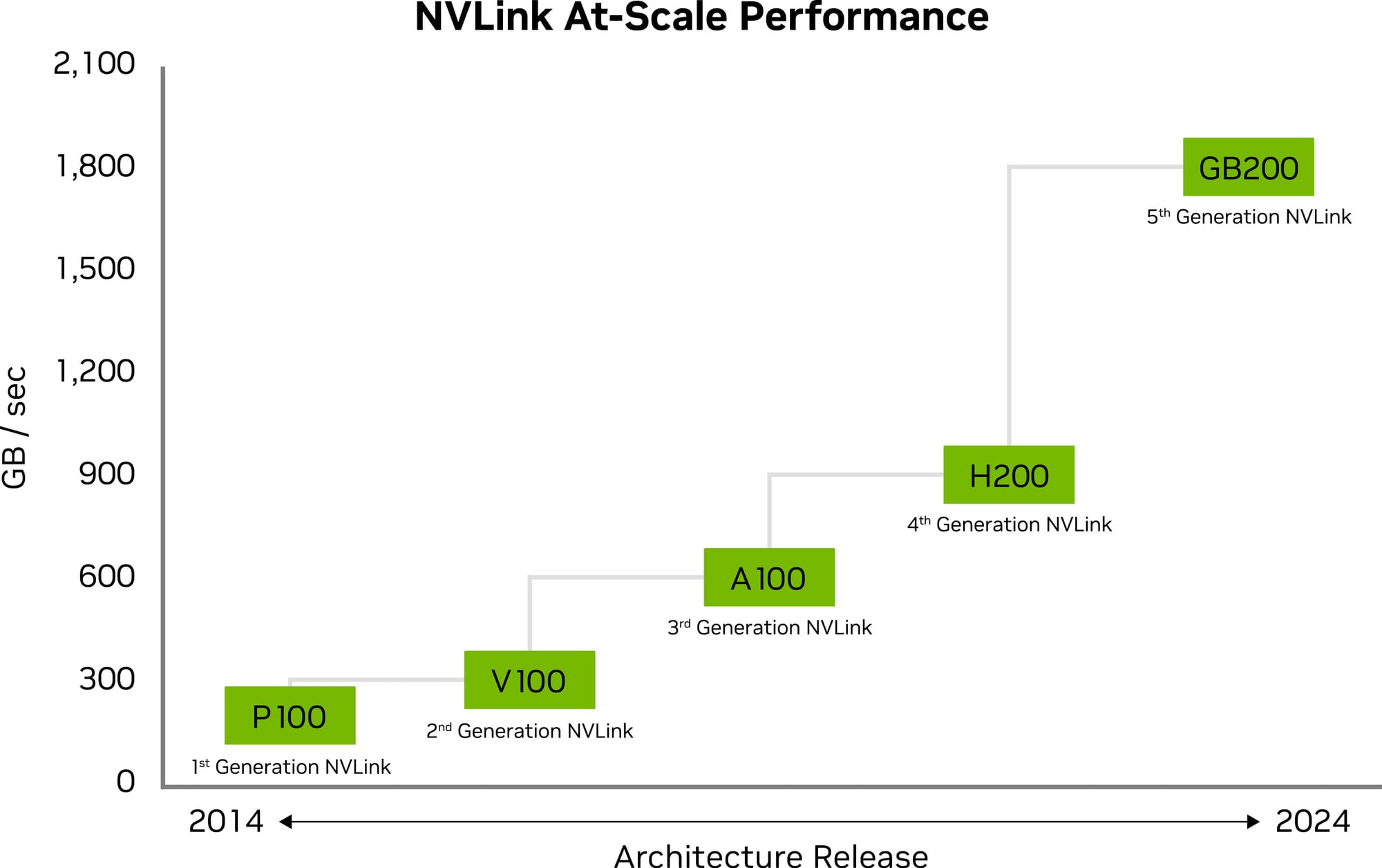
Công nghệ này được thiết kế chuyên biệt để giải quyết các tác vụ yêu cầu giao tiếp liên tục và dữ dội giữa các GPU, chẳng hạn như quá trình huấn luyện các mô hình ngôn ngữ lớn (LLM) hay các mô hình Mixture-of-Experts (MoE) phức tạp.
Kiến trúc Blackwell và hệ thống NVIDIA DGX GB200 NVL72: Khi tất cả cùng hợp lực
Sức mạnh của NVLink thế hệ thứ 5 được thể hiện rõ nét nhất khi nó trở thành xương sống cho hệ thống “quái vật” NVIDIA DGX GB200 NVL72. Đây không chỉ là một máy chủ, mà là một giải pháp rack-scale hoàn chỉnh, được làm mát bằng chất lỏng, bao gồm:
- 72 GPU NVIDIA Blackwell Tensor Core: Các GPU này được kết nối với nhau thông qua một miền NVLink duy nhất, hoạt động như một siêu GPU khổng lồ.
- 36 CPU NVIDIA Grace: Cung cấp khả năng xử lý các tác vụ tính toán đa năng và hỗ trợ cho cụm GPU.
- NVLink Switch System: Trái tim của hệ thống kết nối, đảm bảo tổng băng thông lên đến 130 TB/s cho toàn bộ 72 GPU, cho phép chúng giao tiếp với nhau ở tốc độ tối đa.
Hệ thống GB200 NVL72, nhờ vào NVLink 5.0, mang lại hiệu suất inference cho các mô hình nghìn tỷ tham số nhanh hơn gấp 30 lần và huấn luyện nhanh hơn 4 lần so với thế hệ H100 trước đó.
 NVLink Switch tốc độ cao cung cấp 1 PB/s băng thông tổng hợp cho GPU
NVLink Switch tốc độ cao cung cấp 1 PB/s băng thông tổng hợp cho GPU
Tầm nhìn chiến lược: Tương lai của trung tâm dữ liệu AI
Việc ra mắt NVLink thế hệ thứ 5 và kiến trúc Blackwell không chỉ là một bản nâng cấp phần cứng đơn thuần. Nó cho thấy một tầm nhìn chiến lược của NVIDIA về tương lai của các trung tâm dữ liệu:
- Giao tiếp là vua: Sức mạnh xử lý song song chỉ thực sự hiệu quả khi dữ liệu được lưu chuyển không giới hạn. NVIDIA đang đặt cược vào một tương lai nơi kết nối tốc độ cao là nền tảng của mọi hệ thống AI.
- Mở rộng quy mô (Scale-Up) hiệu quả: Thay vì chỉ mở rộng theo chiều ngang (scale-out) qua nhiều máy chủ, NVLink 5.0 cho phép “mở rộng theo chiều dọc” (scale-up) bằng cách tạo ra các cụm GPU cực lớn, hoạt động như một thực thể duy nhất, giảm thiểu độ trễ và tăng hiệu quả huấn luyện.
- Tối ưu hóa năng lượng: Hệ thống làm mát bằng chất lỏng và kết nối hiệu quả của GB200 NVL72 giúp cải thiện hiệu suất trên mỗi watt (performance-per-watt) lên đến 25 lần, một yếu tố cực kỳ quan trọng trong bối cảnh chi phí năng lượng ngày càng tăng.
 Hệ thống chuyển mạch NVLink
Hệ thống chuyển mạch NVLink
Bản so sánh thông số kỹ thuật
| First Generation | Second Generation | Third Generation | NVLink Switch | |
|---|---|---|---|---|
| Number of GPUs with direct connection within a NVLink domain | Up to 8 | Up to 8 | Up to 8 | Up to 576 |
| NVSwitch GPU-to-GPU bandwidth | 300GB/s | 600GB/s | 900GB/s | 1,800GB/s |
| Total aggregate bandwidth | 2.4TB/s | 4.8TB/s | 7.2TB/s | 1PB/s |
| Supported NVIDIA architectures | NVIDIA Volta™ architecture | NVIDIA Ampere architecture | NVIDIA Hopper™ architecture | NVIDIA Blackwell architecture |
Lời kết
NVIDIA NVLink thế hệ thứ 5 không chỉ là một bước tiến về mặt thông số. Nó là một cấu phần cốt lõi trong một hệ sinh thái được thiết kế tỉ mỉ, từ vi kiến trúc GPU Blackwell cho đến hệ thống rack-scale GB200 NVL72. Đây chính là lời khẳng định cho một kỷ nguyên mới của AI, nơi những mô hình phức tạp và đồ sộ nhất có thể được huấn luyện và triển khai ở một quy mô chưa từng có, mở ra những tiềm năng vô hạn cho khoa học và công nghệ.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?