
Tensor Core trong GPU của NVIDIA là gì?
Theo tên chính thức của dòng Tesla, GPU NVIDIA Tensor Core là dòng GPU tiêu chuẩn vàng cho các phép tính AI nhờ kiến trúc độc đáo được thiết kế riêng để thực hiện các phép tính trong AI và mạng nơ-ron.
Tensor là kiểu dữ liệu cơ bản nhất của AI và là một mảng đa chiều có trọng số được xác định. Để tính toán các mảng này, phép nhân ma trận được thực thi rộng ra để cập nhật trọng số và cho phép mạng nơ-ron học.
Tensor Cores lần đầu tiên được giới thiệu trong Tesla V100. Tuy nhiên, để cải thiện hoạt động tiếp thị đằng sau GPU đầu bảng của mình, trong thế hệ GPU Ampere tiếp theo, NVIDIA đã bỏ tên Tesla để chuyển sang quy ước đặt tên GPU Tensor Core. GPU NVIDIA A100 Tensor Core là GPU hiệu suất cao mang tính cách mạng chuyên dùng để tăng tốc tính toán AI.
Hiện tại đang là năm 2025 và dòng sản phẩm GPU Tensor Core của NVIDIA hiện đã mở rộng. Chúng tôi sẽ đưa ra một bảng so sánh đầy đủ về thông số kỹ thuật của các GPU và các khuyến nghị toàn diện cho việc triển khai GPU mạnh nhất thế giới cho AI. Với mục đích tham khảo, chúng tôi sẽ tập trung vào các phiên bản SXM của từng GPU có thể tìm thấy trong các hệ thống NVIDIA DGX hoặc NVIDIA HGX.
- GPU NVIDIA B200 Tensor Core (Blackwell 2025)
- GPU NVIDIA B100 Tensor Core (Blackwell 2025)
- GPU NVIDIA H200 Tensor Core (Hopper 2024)
- GPU NVIDIA H100 Tensor Core (Hopper 2022)
- GPU NVIDIA A100 Tensor Core (Ampere 2020)
B200 vs B100 vs H200 vs H100 vs A100 SXM
Trước khi đi vào chi tiết, cần lưu ý rằng A100 và H100 tính đến thời điểm hiện tại (7/2025) đều đã hết vòng đời sản phẩm (EOL) và đã được thay thế bằng H200. Các mẫu H100 hiện tại vẫn còn tồn kho đâu đó nhưng H200 sẽ thay thế trong các đơn đặt hàng mới, cùng với NVIDIA B200 và B100. Mặc dù một số GPU đã EOL, nhưng chúng tôi vẫn đưa vào các mẫu NVIDIA A100 và NVIDIA H100 để những ai đã triển khai chúng có thể tham khảo.
| Kiến trúc | Blackwell | Blackwell | Hopper | Hopper | Ampere |
|---|---|---|---|---|---|
| Tên GPU | NVIDIA B200 | NVIDIA B100 | NVIDIA H200 | NVIDIA H100 | NVIDIA A100 |
| FP64 | 40 teraFLOPS | 30 teraFLOPS | 34 teraFLOPS | 34 teraFLOPS | 9.7 teraFLOPS |
| FP64 Tensor Core | 40 teraFLOPS | 30 teraFLOPS | 67 teraFLOPS | 67 teraFLOPS | 19.5 teraFLOPS |
| FP32 | 80 teraFLOPS | 60 teraFLOPS | 67 teraFLOPS | 67 teraFLOPS | 19.5 teraFLOPS |
| FP32 Tensor Core | 2.2 petaFLOPS | 1.8 petaFLOPS | 989 teraFLOPS | 989 teraFLOPS | 312 teraFLOPS |
| FP16/BF16 Tensor Core | 4.5 petaFLOPS | 3.5 petaFLOPS | 1979 teraFLOPS | 1979 teraFLOPS | 624 teraFLOPS |
| INT8 Tensor Core | 9 petaOPs | 7 petaOPs | 3958 teraOPs | 3958 teraOPs | 1248 teraOPs |
| FP8 Tensor Core | 9 petaFLOPS | 7 petaFLOPS | 3958 teraFLOPS | 3958 teraFLOPS | – |
| FP4 Tensor Core | 18 petaFLOPS | 14 petaFLOPS | – | – | – |
| GPU Memory | 192GB HBM3e | 192GB HBM3e | 141GB HBM3e | 80GB HBM3 | 80GB HBM2e |
| Memory Bandwidth | Up to 8TB/s | Up to 8TB/s | 4.8TB/s | 3.2TB/s | 2TB/s |
| Decoders | 7 NVDEC, 7 JPEG | 7 NVDEC, 7 JPEG | 7 NVDEC, 7 JPEG | 7 NVDEC, 7 JPEG | 5 NVDEC, 5 JPEG |
| Multi-Instance GPUs | Up to 7 MIGs @23GB | Up to 7 MIGs @23GB | Up to 7 MIGs @16.5GB | Up to 7 MIGs @16.5GB | Up to 7 MIGs @ 10GB |
| Interconnect | NVLink 1.8TB/s | NVLink 1.8TB/s | NVLink 900GB/s | NVLink 900GB/s | NVLink 600GB/s |
| NVIDIA AI Enterprise | Yes | Yes | Yes | Yes | EOL |
Nhìn vào hiệu suất thô được xác định bởi số phép toán dấu phẩy động được thực hiện mỗi giây ở độ chính xác nhất định, GPU NVIDIA Blackwell hy sinh hiệu suất Tensor Core FP64 để có được hiệu suất tăng mạnh ở FP32 trở xuống. Đào tạo AI không yêu cầu độ chính xác 64 bit tối đa trong các phép tính trọng số và tham số của nó. Bằng cách hy sinh hiệu suất FP64 Tensor Core, NVIDIA sẽ vắt kiệt sức hơn khi tính toán trên độ chính xác 32 bit và 16 bit là chuẩn hơn.
Thông lượng NVIDIA B200 cao hơn 2 lần trong TF32, FP16 và FP8, kết hợp với khả năng tính toán trên FP4. Giờ đây, các phép toán dấu phẩy động có độ chính xác thấp hơn này sẽ không được sử dụng trong toàn bộ phép tính nhưng khi được tích hợp vào tải xử lý Mixed Precision, hiệu suất đạt được là rất lớn.
Bạn có cần nâng cấp không?
“Mới hơn luôn tốt hơn” thường đúng trong phần cứng máy tính. Trong trường hợp của các GPU cấp doanh nghiệp này, chúng tôi muốn coi đó là cơ hội để đẩy mạnh khả năng mở rộng phần cứng, hay nói đúng hơn là mở rộng cơ hội kinh doanh.
Thử xem xét giữa NVIDIA H100 và NVIDIA B200:
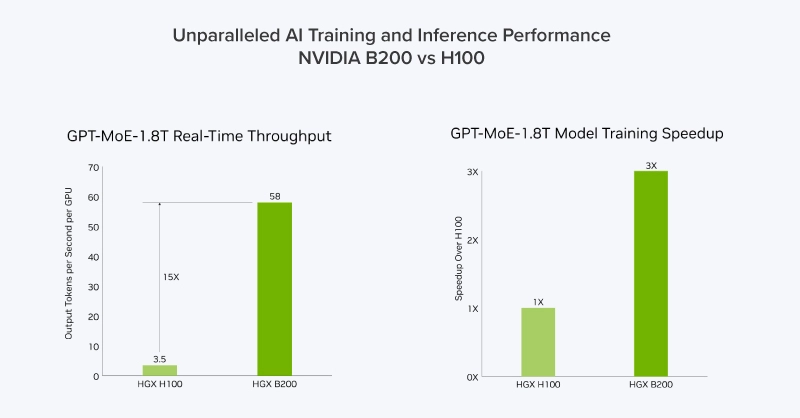
- Nếu tổ chức của bạn đang muốn trang bị một giải pháp triển khai mới như BasePOD hoặc SuperPOD, tiếp tục sử dụng giải pháp triển khai NVIDIA hiện tại nhưng chuyển đổi tải xử lý, Blackwell cực kỳ hiệu quả và mang tính cách mạng về hiệu suất suy luận với tốc độ tăng gấp 15 lần và hiệu suất đào tạo AI được cải thiện.
- Nếu tổ chức của bạn đang tìm cách thay thế H100 hoặc H200, chúng tôi khuyên bạn nên chuyển đổi tải xử lý. Tiếp tục đào tạo trên NVIDIA H100 cũ hơn của bạn và phân bổ hiệu suất suy luận của Blackwell để triển khai và cung cấp mô hình của bạn cho khách hàng nhanh hơn. H100 và H200 cũng có hiệu suất FP64 ngang bằng cho tải xử lý HPC, do đó tải xử lý mô phỏng và phân tích có thể được thực hiện trên Hopper trong khi các tác vụ AI sẽ được phân bổ cho Blackwell.
- Nếu tổ chức của bạn muốn triển khai hạ tầng điện toán cho AI ngay hiện tại, Hopper H200 hiện đã có sẵn và cung cấp hiệu suất đào tạo AI cạnh tranh với chi phí thấp hơn so với Blackwell B200. Bạn có thể tiếp tục xây dựng trung tâm dữ liệu AI của mình khi Blackwell đã sẵn sàng để cung cấp.
Trong khi NVIDIA tiếp tục cải tiến, bạn có thể từ từ chuyển sang phần cứng mới hơn. Cần lưu ý đến lợi tức đầu tư (ROI) khi triển khai các hệ thống này, vì chúng có thể sẽ khá tốn kém. Các hạ tầng quy mô lớn mất nhiều thời gian để phát triển và cần thời gian để nhận ra giá trị của chúng, và ngay cả khi có trong tay thế hệ GPU Tensor Core mới, phần cứng thế hệ trước vẫn có thể mang lại hiệu suất vượt trội.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?