
GPU Cluster là gì?
GPU Cluster (cụm các máy chủ GPU) là một nhóm máy tính được trang bị GPU trên từng node. Nhiều GPU cung cấp sức mạnh điện toán tăng tốc cho các tác vụ tính toán cụ thể, chẳng hạn như xử lý hình ảnh và video cũng như đào tạo mạng lưới thần kinh và các thuật toán học máy khác.
Có ba loại cụm GPU chính, mỗi loại có những ưu điểm cụ thể:
- Tính sẵn sàng cao — cụm GPU định tuyến lại các request đến các node khác nhau trong trường hợp xảy ra lỗi
- Hiệu suất cao — cụm GPU sử dụng nhiều node phụ song song để tăng sức mạnh xử lý cho các tác vụ đòi hỏi cao
- Cân bằng tải — cụm GPU trải đều tải xử lý điện toán trên các node phụ để hình thành một tải xử lý lớn
Trong bài viết này:
- Việc sử dụng cụm GPU
- Cách xây dựng cụm máy tính tăng tốc bằng GPU cho nghiên cứu
- Bước 1: Chọn phần cứng
- Bước 2: Phân bổ không gian, nguồn điện và hệ thống làm mát
- Bước 3: Triển khai vật lý
- Triển khai phần mềm cho head node và worker node
- Tùy chọn phần cứng cụm GPU
- Tùy chọn máy chủ GPU
- Cụm GPU có nền tảng quản lý Run:AI
Vấn đề sử dụng cụm GPU
Cụm GPU thường được sử dụng cho:
Việc mở rộng quy mô Deep Learning
Cụm GPU cung cấp sức mạnh tính toán cần thiết để đào tạo các mô hình và bộ dữ liệu lớn trên nhiều node GPU.
Dưới đây là hai cách có thể sử dụng cụm GPU để hỗ trợ các tác vụ deep learning:
- Thị giác máy tính – các kiến trúc thị giác máy tính như ResNet và Inception thường sử dụng hàng trăm hoặc hàng nghìn lớp chập và cần tính toán chuyên sâu để đào tạo. Bằng cách sử dụng cụm GPU, các nhà nghiên cứu có thể tăng tốc thời gian đào tạo và thực hiện suy luận nhanh trên các tập dữ liệu lớn, bao gồm cả dữ liệu video.
- Xử lý ngôn ngữ tự nhiên (NLP) – các mô hình NLP quy mô lớn, chẳng hạn như AI đàm thoại, đòi hỏi một lượng lớn sức mạnh tính toán và đào tạo liên tục. Các cụm GPU có thể sử dụng một lượng lớn dữ liệu huấn luyện, phân chia thành các đơn vị có thể quản lý và huấn luyện mô hình song song.
Edge AI
Các cụm GPU cũng có thể được phân tán, với các node GPU trải rộng trên các thiết bị được triển khai ở biên, thay vì ở một trung tâm dữ liệu tập trung. Việc kết hợp các GPU từ nhiều node phân tán vào một cụm giúp có thể chạy suy luận AI với độ trễ rất thấp. Điều này là do mỗi node có thể tạo dự đoán cục bộ mà không cần phải liên lạc lên đám mây hoặc trung tâm dữ liệu từ xa.
Xây dựng cụm nghiên cứu hỗ trợ bởi GPU
Hãy sử dụng các bước sau để xây dựng cụm được tăng tốc GPU trong trung tâm dữ liệu tại chỗ của bạn.
Bước 1: Chọn phần cứng
Thành phần cơ bản của cụm GPU là một node — một máy vật lý chạy một hoặc nhiều GPU, có thể được sử dụng để chạy tải xử lý. Khi chọn phần cứng cho một node, hãy xem xét các yếu tố sau:
- Bộ xử lý CPU — node yêu cầu có CPU cũng như các GPU. Đối với hầu hết các node GPU, bất kỳ CPU thế hệ mới nào cũng sẽ hỗ trợ.
- RAM — RAM hệ thống càng nhiều thì càng tốt, nhưng hãy đảm bảo bạn có RAM DDR3 tối thiểu 24 GB trên mỗi node.
- Kết nối mạng — mỗi node phải có ít nhất hai cổng mạng khả dụng. Bạn sẽ cần sử dụng Infiniband để kết nối nhanh giữa các GPU.
- Bo mạch chủ — bo mạch chủ phải có kết nối PCI-express (PCIe) cho GPU bạn định sử dụng và cho card Infiniband. Phải đảm bảo bạn có bo mạch GPU với các khe cắm PCIe x16 và khe cắm PCIe x8 được tách biệt về mặt vật lý. Thông thường, bạn sẽ sử dụng các khe x16 cho GPU và các khe x8 cho card mạng.
- Bộ cấp nguồn — GPU cấp trung tâm dữ liệu đặc biệt ngốn rất nhiều điện. Khi tính toán tổng công suất cần thiết, hãy tính đến CPU, tất cả GPU chạy trên node và các thành phần khác.
- Bộ nhớ — ổ SSD sẽ tốt hơn, nhưng SSD có thể chỉ đủ cho một số trường hợp.
- Định dạng GPU — xem xét form-factor GPU phù hợp với phần cứng node của bạn và số lượng GPU bạn muốn chạy trên mỗi node. Các kiểu dáng phổ biến bao gồm nhỏ gọn (SFF), khe đơn, khe kép, làm mát chủ động, làm mát thụ động và làm mát bằng nước.
Bước 2: Phân bổ không gian, nguồn điện và làm mát
GPU có thể yêu cầu cơ sở riêng hoặc có thể được đặt như một phần của trung tâm dữ liệu hiện có. Lập kế hoạch cho các yếu tố sau:
- Không gian vật lý — đảm bảo bạn có tủ rack và không gian vật lý trong trung tâm dữ liệu cho các node bạn định triển khai.
- Làm mát — GPU yêu cầu khả năng làm mát tốt. Hãy tính đến việc GPU của bạn được làm mát chủ động bằng thiết bị tích hợp hay làm mát thụ động và lập kế hoạch cho các yêu cầu làm mát tổng thể của toàn bộ cụm.
- Kết nối mạng — đảm bảo bạn có bộ chuyển mạch Ethernet nhanh để cho phép liên lạc giữa head node của cụm và các worker node.
- Lưu trữ — tùy thuộc vào yêu cầu dữ liệu của bạn, bạn có thể cần một giải pháp lưu trữ trung tâm ngoài lưu trữ cục bộ trên các node.
Bước 3: Triển khai vật lý
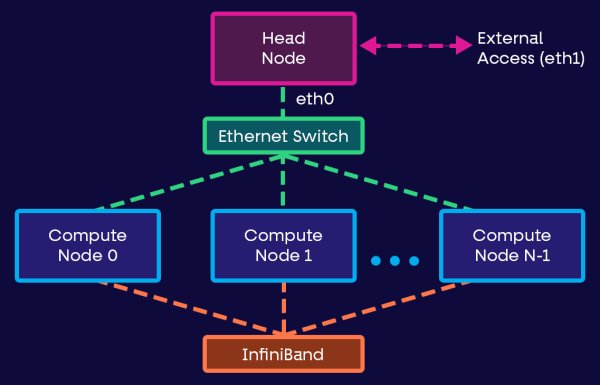
Bây giờ bạn đã có sẵn cơ sở vật chất và thiết bị, bạn sẽ cần triển khai các node một cách vật lý. Bạn sẽ có một head node, một node chuyên dụng điều khiển cụm và nhiều worker node chạy tải xử lý.
Triển khai mạng như sau:
- Head node phải nhận các kết nối và yêu cầu mạng từ bên ngoài cụm và chuyển chúng đến các worker node.
- Các worker node phải được kết nối với head node thông qua kết nối Ethernet nhanh.
Triển khai phần mềm cho head node và các worker node
Khi phần cứng và mạng được triển khai xong, hãy triển khai cài đặt hệ điều hành trên các node của bạn. NVIDIA khuyến nghị sử dụng Rocks Linux mã nguồn mở cho các cụm máy chủ.
Ngoài ra, bạn sẽ cần phần mềm quản lý. Một lựa chọn phổ biến là quản lý các cụm máy chủ bằng Kubernetes. Trong trường hợp này, bạn sẽ cần triển khai trình điều khiển Kubernetes trên head node (tốt nhất là với một head node dự phòng khác để có tính sẵn sàng cao) và triển khai các worker node Kubernetes trên các máy còn lại. Bạn có thể cần triển khai phần mềm bổ sung như bộ lập lịch công việc SLURM.
Tùy chọn phần cứng cụm GPU
Hãy xem xét các tùy chọn phần cứng chính theo ý của bạn khi xây dựng cụm GPU.
Tùy chọn GPU trung tâm dữ liệu
Sau đây là một số GPU cấp trung tâm dữ liệu mạnh nhất thế giới, thường được sử dụng để xây dựng hạ tầng GPU quy mô lớn.
NVIDIA Tesla A100
A100 dựa trên Tensor Cores và tận dụng công nghệ GPU đa phiên bản (MIG). Nó được xây dựng cho các tải xử lý như điện toán hiệu năng cao (HPC), machine learning và phân tích dữ liệu.
Tesla A100 được thiết kế để có khả năng mở rộng (lên tới hàng nghìn đơn vị) và có thể được tách thành bảy phiên bản GPU cho các kích cỡ tải xử lý khác nhau. A100 cung cấp hiệu suất lên tới 624 teraflop (tỷ phép tính dấu phẩy động mỗi giây) và có bộ nhớ 40GB, băng thông 1.555 GB và tốc độ kết nối 600GB/s.
NVIDIA Tesla V100
GPU V100 cũng dựa trên Tensor Cores và được thiết kế cho các ứng dụng như machine learning, deep learning và HPC. Nó sử dụng công nghệ NVIDIA Volta để tăng tốc các hoạt động tensor thông thường trong tải xử lý deep learning. Tesla V100 cung cấp hiệu suất đạt 149 teraflop cũng như bộ nhớ 32GB và bus bộ nhớ 4.096-bit.
NVIDIA Tesla P100
GPU Tesla P100 dựa trên kiến trúc NVIDIA Pascal được thiết kế dành riêng cho HPC và học máy. P100 cung cấp hiệu suất lên tới 21 teraflop, với bộ nhớ 16GB và bus bộ nhớ 4.096-bit.
NVIDIA Tesla K80
GPU K80 sử dụng kiến trúc NVIDIA Kepler, cho phép tăng tốc độ phân tích dữ liệu và tính toán khoa học. Nó tích hợp công nghệ GPU Boost™ và 4.992 nhân NVIDIA CUDA. Tesla K80 cung cấp hiệu suất lên tới 8,73 teraflop, với băng thông bộ nhớ 480GB và bộ nhớ GDDR5 24GB.
Google TPU
Google cung cấp các bộ xử lý tensor (TPU) hơi khác một chút, là các mạch tích hợp dành riêng cho ứng dụng (ASIC) dựa trên chip hoặc đám mây, hỗ trợ học sâu. Những TPU này được thiết kế đặc biệt để sử dụng với TensorFlow và chỉ có thể tìm thấy trên Google Cloud Platform.
Google TPU cung cấp hiệu suất lên tới 420 teraflop với bộ nhớ băng thông cao (HBM) 128 GB. Bạn cũng có thể tìm thấy các phiên bản nhóm cung cấp hiệu suất trên 100 petaflop với mạng lưới hình xuyến 2D và HBM 32TB.
Tùy chọn máy chủ GPU
Máy chủ GPU, còn được gọi là máy trạm GPU, là một hệ thống có khả năng chạy nhiều GPU trong một khung vật lý.
NVIDIA DGX-1 — Máy chủ DGX thế hệ đầu tiên
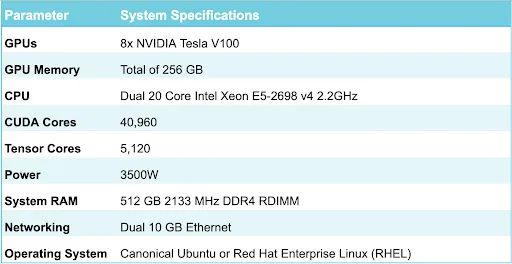
NVIDIA DGX-1 là máy chủ DGX thế hệ đầu tiên. Nó là một máy trạm tích hợp với khả năng tính toán mạnh mẽ phù hợp cho deep learning. Nó cung cấp một petaflop sức mạnh tính toán GPU và cung cấp các tính năng phần cứng sau:
NVIDIA DGX-2
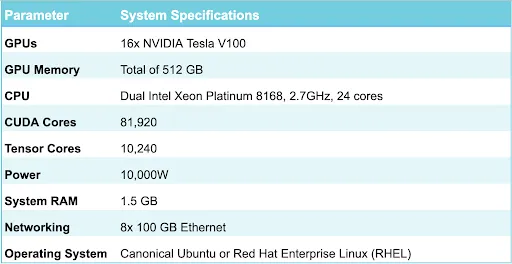
Kiến trúc của DGX-2, máy chủ DGX thế hệ thứ hai, tương tự như DGX-1, nhưng có sức mạnh tính toán cao hơn, đạt tới 2 petaflop khi sử dụng với GPU 16 Tesla V100. NVIDIA giải thích rằng để đào tạo ResNet-50 bằng kiến trúc x86 điển hình, bạn sẽ cần 300 máy chủ được kích hoạt bởi CPU Intel Xeon Gold kép để đạt được tốc độ xử lý tương tự như với DGX-2. Nó cũng sẽ có giá hơn 2,7 triệu USD.
DGX-2 cung cấp các tính năng phần cứng sau:
NVIDIA DGX A100
Hệ thống AI thế hệ thứ ba của NVIDIA là DGX A100, cung cấp sức mạnh tính toán lên tới 5 petaflop trong một hệ thống.
A100 có hai model với RAM 320 GB hoặc RAM 640 GB. Nó cung cấp các tính năng phần cứng sau:

NVIDIA DGX Station A100 — Máy trạm DGX thế hệ thứ ba
DGX Station là phiên bản nhẹ hơn của DGX A100, dành cho các nhà phát triển hoặc nhóm nhỏ sử dụng. Nó có kiến trúc Tensor Core cho phép GPU A100 tận dụng các hoạt động có độ chính xác hỗn hợp, tích lũy bội số, giúp tăng tốc đáng kể việc đào tạo các mạng lưới thần kinh lớn.
DGX Station có hai model với RAM GPU 160GB hoặc 320GB. Nó cung cấp các tính năng phần cứng sau:

NVIDIA DGX SuperPOD
DGX SuperPOD là nền tảng điện toán nhiều node dành cho tải xử lý toàn ngăn xếp. Nó cung cấp mạng, lưu trữ, điện toán và các công cụ cho quy trình khoa học dữ liệu. NVIDIA cung cấp dịch vụ triển khai để giúp bạn triển khai và duy trì SuperPOD một cách liên tục.
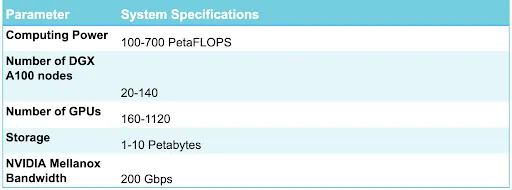
SuperPOD hỗ trợ tích hợp tới 140 hệ thống DGX A100 trong một cụm hạ tầng AI duy nhất. Cụm cung cấp các khả năng sau:
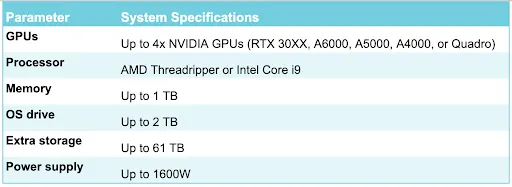
Máy trạm GPU Lambda Labs
Lambda Labs cung cấp các máy trạm GPU tầm trung với 2-4 GPU. Chúng thường được sử dụng bởi các kỹ sư học máy cá nhân hoặc các mô hình đào tạo nhóm nhỏ trong môi trường địa phương. Máy trạm cung cấp các tính năng phần cứng sau:
Quản lý cụm GPU với giải pháp Run:AI
Run:AI tự động hóa việc quản lý và điều phối tài nguyên cho hạ tầng học máy. Với Run:AI, bạn có thể tự động chạy tùy ý các thử nghiệm điện toán chuyên sâu nếu cần.
Dưới đây là một số khả năng bạn có được khi sử dụng Run:AI
- Khả năng kiểm soát nâng cao — tạo ra một kênh chia sẻ tài nguyên hiệu quả bằng cách tổng hợp các tài nguyên tính toán GPU.
- Không còn tắc nghẽn nữa — bạn có thể thiết lập hạn ngạch tài nguyên GPU được đảm bảo để tránh tắc nghẽn và tối ưu hóa việc thanh toán.
- Mức độ kiểm soát cao hơn — Run:AI cho phép bạn thay đổi linh hoạt việc phân bổ tài nguyên, đảm bảo mỗi công việc đều nhận được tài nguyên cần thiết vào bất kỳ thời điểm nào.
Run:AI đơn giản hóa quy trình hạ tầng học máy, giúp các nhà khoa học dữ liệu tăng tốc năng suất và chất lượng mô hình của họ.
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA hiện đang cung cấp những dòng GPU nào?
- Hướng dẫn lựa chọn GPU phù hợp cho AI, Machine Learning
- Cải thiện khả năng làm mát GPU trong hạ tầng AI
- Đánh giá GPU máy trạm: Nvidia RTX 6000 Ada Generation
- Tăng tốc cho hệ thống lưu trữ NAS QNAP với CPU, GPU, NPU và TPU